Mahalanobis-Guided Latent OOD Detection for Hybrid ES-DRL Control in Time-Varying Systems
Pith reviewed 2026-06-27 13:41 UTC · model grok-4.3
The pith
Mahalanobis distance in the latent space of a VAE trained on normal beam profiles detects when time-varying magnet motion produces unseen observations and triggers a switch from RL to extremum-seeking control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
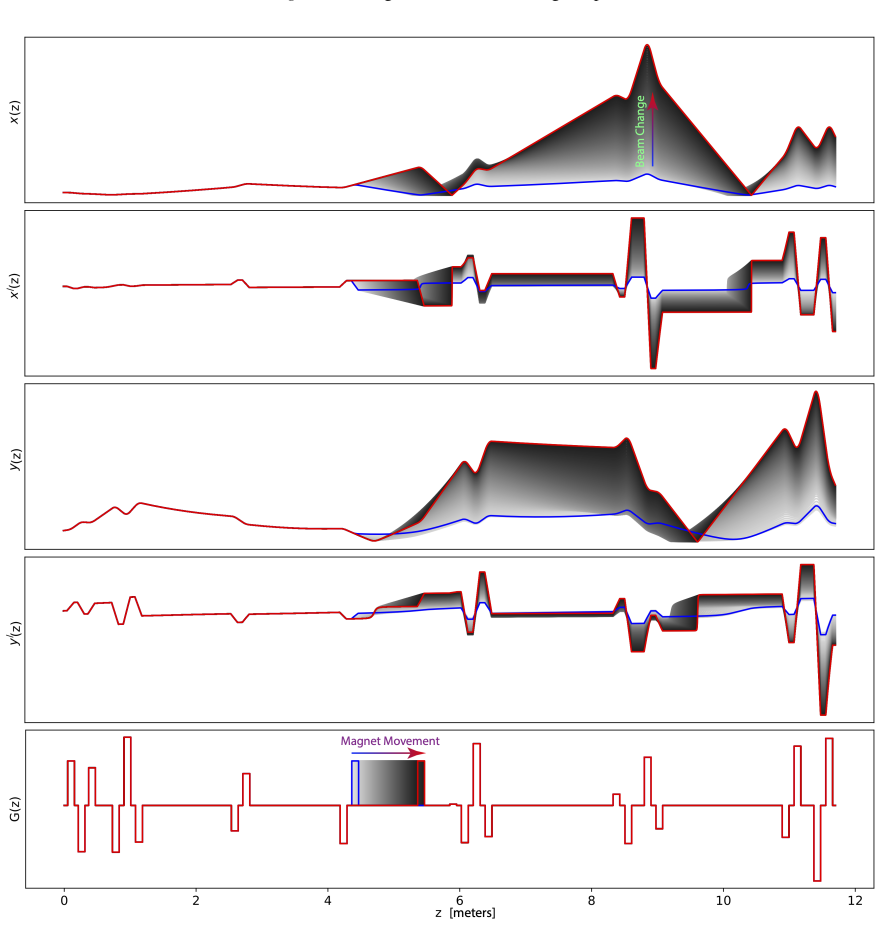
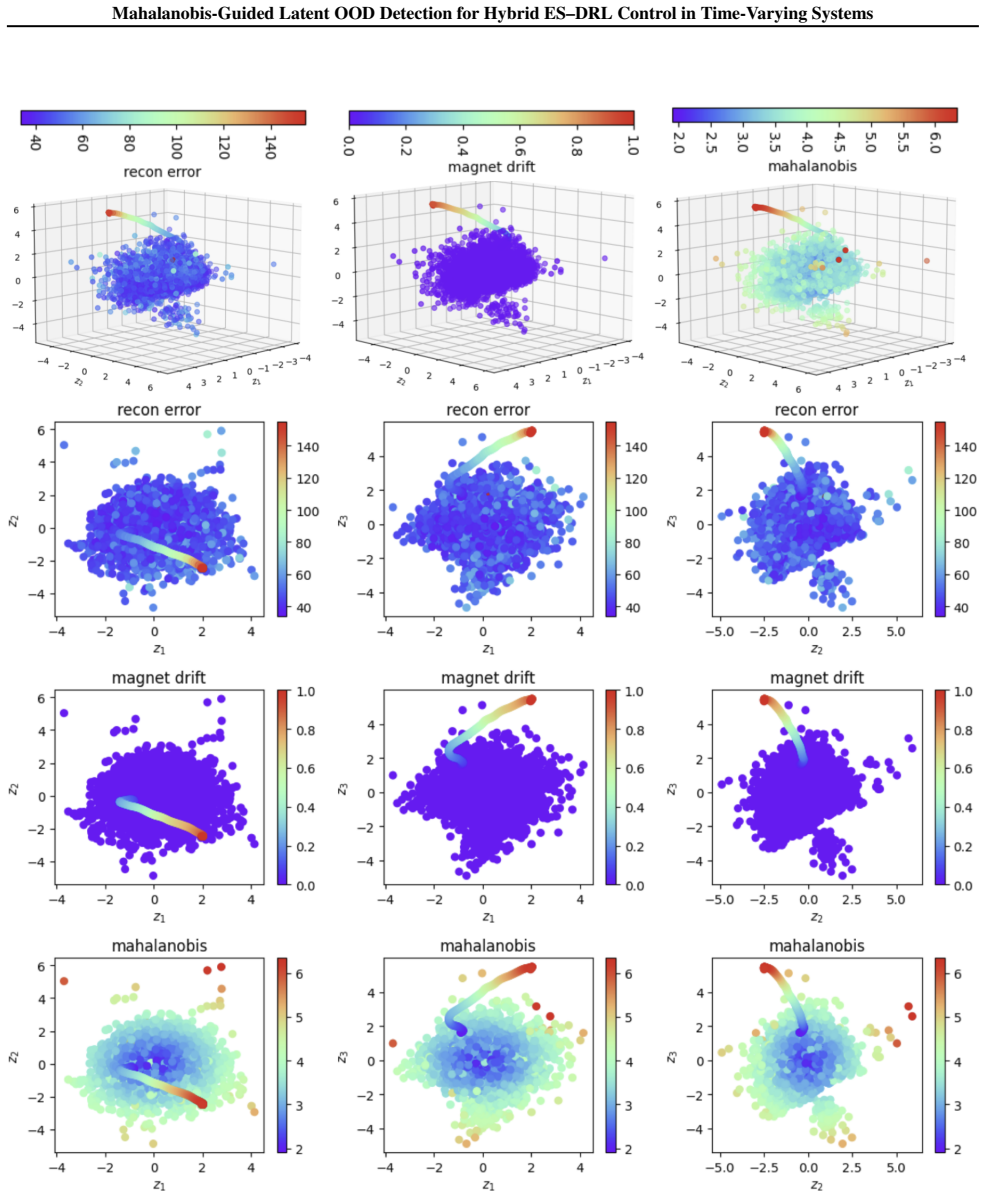
The central claim is that Mahalanobis distance computed on the latent representations of a VAE trained exclusively on in-distribution beam profiles reliably identifies out-of-distribution beam profiles caused by time-varying magnet motion. This OOD signal sets the binary switch that selects either the RL controller or the ES controller in the combined system. Visualization of the VAE latent space confirms that the proposed distance separates the OOD cases and supplies an interpretable signal for the switching decision in safety-critical accelerator operation.
What carries the argument
Mahalanobis distance in the VAE latent space, which quantifies deviation of a new observation's latent code from the distribution of training latents and thereby controls the binary switch between the RL and ES controllers.
If this is right
- The RL controller can supply fast actions while observations stay inside the training distribution.
- The ES controller supplies bounded, model-independent actions once OOD profiles are flagged.
- The combined controller maintains operation in particle accelerators despite spatial magnet motion that creates new beam profiles.
- Latent-space visualization gives a direct visual check on whether the switch decision is being made correctly.
Where Pith is reading between the lines
- The same latent-distance approach could be tested on other sources of distribution shift besides magnet motion, such as changes in beam energy or target materials.
- If the separation holds, the method supplies one concrete way to combine data-driven speed with model-free robustness in any time-varying plant where full retraining is impractical.
- The binary switch could be replaced by a continuous blending weight whose value is a function of the same Mahalanobis distance.
Load-bearing premise
Mahalanobis distance calculated in the latent space of a VAE trained only on in-distribution beam profiles will reliably flag OOD profiles that arise from time-varying magnet motion.
What would settle it
A test or latent-space plot in which beam profiles produced by magnet motion show Mahalanobis distances that remain inside the in-distribution range or fail to separate from training points would show the detection method does not work as claimed.
Figures


read the original abstract
In this paper, we study Mahalanobis-guided latent out-of-distribution (OOD) detection for test-time RL controller switching in nonlinear time-varying systems. RL controllers can quickly control high-dimensional systems within the training distribution, but their performance can degrade when time-varying dynamics produce unseen observations. We consider a combined ES--DRL controller, where RL provides fast in-distribution actions and bounded extremum seeking (ES) provides robust model-independent control under OOD operation. The key challenge is deciding when to switch. We train a variational autoencoder (VAE) on in-distribution beam-profile observations and use Mahalanobis distance in the VAE latent space to detect OOD beam profiles at test time. This OOD decision sets a binary switch that selects either the RL controller or the ES controller. We evaluate the approach in safety-critical particle accelerator control. In this setting, spatial magnet motion creates OOD beam profiles that were not seen during RL training. Visualization of the VAE latent space shows that the proposed method identifies this OOD scenario and provides an interpretable signal for switching between RL and ES in the combined controller.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Mahalanobis distance computed in the latent space of a VAE (trained only on in-distribution beam profiles) as an OOD detector to produce a binary switch signal between a fast RL controller and a robust ES controller in nonlinear time-varying systems. The approach is motivated and illustrated in a particle-accelerator beam-control setting where spatial magnet motion produces previously unseen profiles; the sole reported evidence is a visualization of the VAE latent space.
Significance. A reliable, interpretable OOD switch would be valuable for deploying RL policies in safety-critical time-varying plants. The latent-space Mahalanobis construction itself is a standard technique, but the manuscript supplies no quantitative detection performance, threshold calibration, or baseline comparisons, so the practical significance cannot yet be assessed.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the claim that the method 'identifies this OOD scenario and provides an interpretable signal for switching' rests exclusively on a latent-space visualization. No AUROC, FPR, TPR, threshold-selection procedure, or statistical comparison of ID versus OOD Mahalanobis distributions is reported, leaving the reliability of the binary switch unverified.
- [Method] Method section: the covariance matrix used for the Mahalanobis distance, the exact decision threshold, and any validation of that threshold against held-out OOD data are not described, so the switch logic cannot be reproduced or stress-tested.
minor comments (1)
- [Abstract] The abstract refers to 'bounded extremum seeking' without stating how the bounds are chosen or enforced when the ES controller is active.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We agree that quantitative metrics and methodological details are needed to strengthen the evaluation of the OOD detector and will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the claim that the method 'identifies this OOD scenario and provides an interpretable signal for switching' rests exclusively on a latent-space visualization. No AUROC, FPR, TPR, threshold-selection procedure, or statistical comparison of ID versus OOD Mahalanobis distributions is reported, leaving the reliability of the binary switch unverified.
Authors: We acknowledge that the present manuscript demonstrates the approach via latent-space visualization only. To verify the reliability of the binary switch, the revised version will add AUROC, FPR, TPR at selected operating points, an explicit threshold-selection procedure, and a statistical comparison (e.g., mean and variance) of Mahalanobis distances on ID versus OOD samples. revision: yes
-
Referee: [Method] Method section: the covariance matrix used for the Mahalanobis distance, the exact decision threshold, and any validation of that threshold against held-out OOD data are not described, so the switch logic cannot be reproduced or stress-tested.
Authors: We will expand the Method section to specify that the covariance is the empirical covariance of the VAE latent codes computed on the training (ID) set, to state the exact threshold rule (e.g., a quantile of the ID Mahalanobis distances), and to report validation of that threshold on held-out OOD beam profiles from the accelerator experiments. revision: yes
Circularity Check
No significant circularity; standard VAE+Mahalanobis pipeline applied without self-referential reduction
full rationale
The paper describes training a VAE exclusively on in-distribution beam profiles and then computing Mahalanobis distance in the resulting latent space to flag OOD profiles at test time. This is a conventional two-stage procedure (representation learning followed by distance-based detection) with no equations or fitted parameters shown that define the OOD decision in terms of itself. No self-citations are invoked to justify uniqueness or to smuggle in an ansatz, and the switch logic is presented as an application of the detector rather than a derived quantity forced by prior results from the same authors. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2017 IEEE international conference on robotics and automation (ICRA) , pages=
Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates , author=. 2017 IEEE international conference on robotics and automation (ICRA) , pages=. 2017 , organization=
2017
-
[2]
Proceedings of the 2013 International Particle Accelerator Conference, Shanghai, China , pages=
Model independent beam tuning , author=. Proceedings of the 2013 International Particle Accelerator Conference, Shanghai, China , pages=
2013
-
[3]
Advances in Neural Information Processing Systems , volume=
Safe reinforcement learning by imagining the near future , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
arXiv preprint arXiv:2403.03187 , year=
Reliable, adaptable, and attributable language models with retrieval , author=. arXiv preprint arXiv:2403.03187 , year=
-
[5]
arXiv preprint arXiv:2503.12932 , year=
Efficient action-constrained reinforcement learning via acceptance-rejection method and augmented mdps , author=. arXiv preprint arXiv:2503.12932 , year=
-
[6]
Journal of Artificial Intelligence Research , volume=
Automated reinforcement learning (autorl): A survey and open problems , author=. Journal of Artificial Intelligence Research , volume=
-
[7]
arXiv preprint arXiv:2510.02490 , year=
Improved Robustness of Deep Reinforcement Learning for Control of Time-Varying Systems by Bounded Extremum Seeking , author=. arXiv preprint arXiv:2510.02490 , year=
-
[8]
arXiv preprint arXiv:2604.01142 , year=
Deep Reinforcement Learning for Robotic Manipulation under Distribution Shift with Bounded Extremum Seeking , author=. arXiv preprint arXiv:2604.01142 , year=
-
[9]
Transactions on Machine Learning Research , year=
A Distance-based Anomaly Detection Framework for Deep Reinforcement Learning , author=. Transactions on Machine Learning Research , year=
-
[10]
Advances in Neural Information Processing Systems , year=
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , author=. Advances in Neural Information Processing Systems , year=
-
[11]
arXiv preprint arXiv:2003.00402 , year=
Why is the Mahalanobis Distance Effective for Anomaly Detection? , author=. arXiv preprint arXiv:2003.00402 , year=
-
[12]
International Conference on Learning Representations , year=
Auto-Encoding Variational Bayes , author=. International Conference on Learning Representations , year=
-
[13]
arXiv preprint arXiv:2107.04982 , year=
Out-of-Distribution Dynamics Detection: RL-Relevant Benchmarks and Results , author=. arXiv preprint arXiv:2107.04982 , year=
-
[14]
Proceedings of the 22nd International Conference on Autonomous Agents and Multiagent Systems , pages=
Out-of-Distribution Detection for Reinforcement Learning Agents with Probabilistic Dynamics Models , author=. Proceedings of the 22nd International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[15]
arXiv preprint arXiv:2404.07099 , year=
Rethinking Out-of-Distribution Detection for Reinforcement Learning: Advancing Methods for Evaluation and Detection , author=. arXiv preprint arXiv:2404.07099 , year=
-
[16]
Artificial Neural Networks and Machine Learning -- ICANN 2020 , pages=
Policy Entropy for Out-of-Distribution Classification , author=. Artificial Neural Networks and Machine Learning -- ICANN 2020 , pages=. 2020 , publisher=
2020
-
[17]
Proceedings of the 12th International Conference on Agents and Artificial Intelligence , pages=
Uncertainty-Based Out-of-Distribution Classification in Deep Reinforcement Learning , author=. Proceedings of the 12th International Conference on Agents and Artificial Intelligence , pages=
-
[18]
Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems , pages=
Towards Anomaly Detection in Reinforcement Learning , author=. Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[19]
IEEE Transactions on Robotics , volume=
Actor--Critic Model Predictive Control: Differentiable Optimization Meets Reinforcement Learning for Agile Flight , author=. IEEE Transactions on Robotics , volume=. 2025 , publisher=
2025
-
[20]
2021 60th IEEE Conference on Decision and Control , pages=
Online Policies for Real-Time Control Using MRAC-RL , author=. 2021 60th IEEE Conference on Decision and Control , pages=. 2021 , organization=
2021
-
[21]
arXiv preprint arXiv:2011.10562 , year=
MRAC-RL: A Framework for On-Line Policy Adaptation Under Parametric Model Uncertainty , author=. arXiv preprint arXiv:2011.10562 , year=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Safe Reinforcement Learning via Shielding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
- [23]
-
[24]
Advances in Neural Information Processing Systems , year=
Dynamic Model Predictive Shielding for Provably Safe Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[25]
arXiv preprint arXiv:2310.04288 , year=
Searching for Optimal Runtime Assurance via Reachability and Reinforcement Learning , author=. arXiv preprint arXiv:2310.04288 , year=
-
[26]
Automatica , volume=
Bounded extremum seeking with discontinuous dithers , author=. Automatica , volume=. 2016 , publisher=
2016
-
[27]
IEEE Transactions on Control Systems Technology , volume=
Extremum seeking-based control system for particle accelerator beam loss minimization , author=. IEEE Transactions on Control Systems Technology , volume=. 2021 , publisher=
2021
-
[28]
Proceedings of the International Conference on High Energy Accelerators and Instrumentation , volume=
Limitations of proton beam current in a strong focusing linear accelerator associated with the beam space charge , author=. Proceedings of the International Conference on High Energy Accelerators and Instrumentation , volume=. 1959 , organization=
1959
-
[29]
2020 , month=sep # " 15", publisher=
Continuous control with deep reinforcement learning , author=. 2020 , month=sep # " 15", publisher=
2020
-
[30]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.