SAFER-Nav: Enhancing Safety for Visual Robot Navigation via Segmentation-Aware Fine-Tuning
Pith reviewed 2026-06-27 09:57 UTC · model grok-4.3
The pith
Fine-tuning visual navigation policies on segmentation masks for obstacles and free space reduces collisions while preserving goal-reaching performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
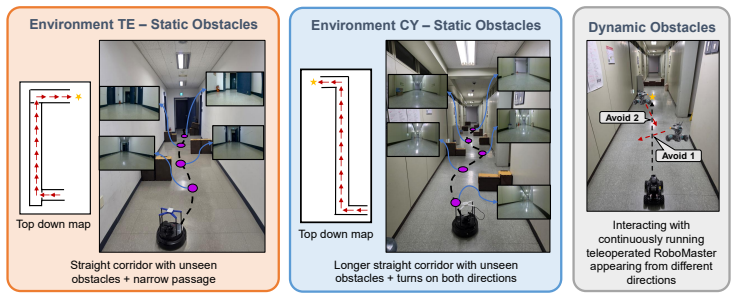
By fine-tuning RGB-based navigation policies with segmentation-derived obstacle boundaries and traversable free-space structure, the resulting policies become safer in deployment environments containing unseen obstacles, reducing collision frequency relative to ViNT, NoMaD, and their CARE-augmented variants while maintaining goal-reaching performance across multiple robot platforms and indoor environments with static and dynamic obstacles.
What carries the argument
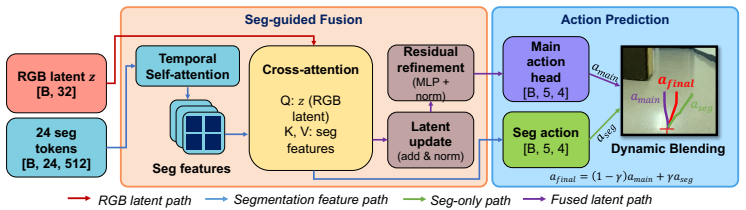
Segmentation-aware fine-tuning that directly embeds obstacle boundaries and free-space structure into the navigation policy.
If this is right
- Collision frequency drops relative to ViNT, NoMaD, and CARE-augmented baselines in both static and dynamic obstacle settings.
- Goal-reaching performance remains comparable across indoor environments and multiple robot platforms.
- The fine-tuning procedure is compatible with diverse existing RGB-based navigation backbones.
- Explicit representation of boundaries and free space occurs inside the policy rather than via post-hoc trajectory correction.
Where Pith is reading between the lines
- Real-time segmentation at deployment time could allow the same structure to guide online policy adaptation.
- The same fine-tuning pattern might transfer to policies that receive depth or point-cloud inputs if analogous free-space masks are supplied.
- If segmentation quality varies, the method may need a fallback that still preserves the safety gain without external modules.
Load-bearing premise
Segmentation-derived obstacle boundaries and free-space structure can be directly incorporated into the policy via fine-tuning without requiring external correction or degrading generalization to shifted conditions.
What would settle it
A test showing higher collision rates or lower goal success when the same fine-tuned policy is deployed in environments whose segmentation masks contain errors or whose visual statistics differ markedly from the fine-tuning data.
Figures



read the original abstract
Vision-based navigation models, particularly foundation models, generate viable trajectories from RGB observations alone. However, even state-of-the-art transformer- and diffusion-based policies struggle to generalize in unfamiliar deployment environments containing unseen obstacles or shifted conditions. The resulting trajectories often remain goal-directed but unsafe. Existing efforts improve safety through external trajectory correction or internal geometric priors, yet the resulting policies are not trained to explicitly represent obstacle boundaries or traversable free-space structure. To address this, we propose a navigation model that incorporates these structures directly into the policy via fine-tuning and is designed to be compatible with diverse RGB-based backbones. Across multiple robot platforms, indoor environments, and static and dynamic obstacle scenarios, our method reduces collision frequency relative to ViNT, NoMaD, and their CARE-augmented variants while maintaining goal-reaching performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAFER-Nav, a method that fine-tunes RGB-based visual navigation policies (compatible with diverse backbones) by incorporating segmentation-derived obstacle boundaries and free-space structure directly into the policy. It reports reduced collision frequency relative to ViNT, NoMaD, and their CARE-augmented variants across multiple robot platforms, indoor environments, and static/dynamic obstacle scenarios, while preserving goal-reaching performance.
Significance. If the results hold under rigorous evaluation, the approach could meaningfully advance safe visual navigation by embedding explicit geometric safety cues internally during fine-tuning rather than relying on post-hoc correction. Multi-platform testing and compatibility claims are strengths that, if substantiated with ablations and statistical reporting, would support broader adoption of segmentation-aware training for foundation-model policies.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of collision reduction is stated without accompanying quantitative values, standard deviations, number of trials, or statistical tests; this prevents assessment of whether the reported gains are load-bearing or sensitive to evaluation choices.
- [§3] §3 (Method): the description of how segmentation masks are converted into training signals (e.g., auxiliary loss, input channels, or reward shaping) is insufficient to verify that the policy learns explicit boundary representation rather than simply overfitting to the segmentation model’s outputs.
minor comments (2)
- [Abstract] Abstract: the phrase “maintaining goal-reaching performance” should be accompanied by the specific success-rate deltas or p-values to allow direct comparison with baselines.
- [Figures/Tables] Figure captions and tables: axis labels, legend entries, and environment identifiers are occasionally abbreviated without a key, reducing readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and rigor as indicated.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of collision reduction is stated without accompanying quantitative values, standard deviations, number of trials, or statistical tests; this prevents assessment of whether the reported gains are load-bearing or sensitive to evaluation choices.
Authors: We agree that the current presentation lacks sufficient quantitative detail. In the revised version we will add explicit values for collision reduction (with standard deviations), the number of trials per scenario, and statistical test results to both the abstract and §4, enabling readers to evaluate robustness directly. revision: yes
-
Referee: [§3] §3 (Method): the description of how segmentation masks are converted into training signals (e.g., auxiliary loss, input channels, or reward shaping) is insufficient to verify that the policy learns explicit boundary representation rather than simply overfitting to the segmentation model’s outputs.
Authors: We acknowledge the description in §3 is currently too brief. We will expand it to specify the exact mechanism by which segmentation masks are converted into training signals and will add discussion (supported by our ablation results) addressing why the approach encourages explicit boundary learning rather than overfitting. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical fine-tuning approach that incorporates segmentation-derived obstacle boundaries into RGB navigation policies and validates it through comparative experiments on multiple platforms and scenarios. No derivation chain, equations, or self-referential definitions are present in the provided abstract or description; performance claims rest on external benchmarks (ViNT, NoMaD, CARE variants) rather than reducing to fitted inputs renamed as predictions or self-citation load-bearing premises. The method is presented as compatible with diverse backbones without invoking uniqueness theorems or ansatzes from prior author work as forcing functions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Song, Chan Hee and Wu, Jiaman and Washington, Clayton and Sadler, Brian M and Chao, Wei-Lun and Su, Yu , booktitle=
-
[2]
Zhou, Gengze and Hong, Yicong and Wu, Qi , booktitle=
-
[3]
Guan, Tianrui and Kothandaraman, Divya and Chandra, Rohan and Sathyamoorthy, Adarsh Jagan and Weerakoon, Kasun and Manocha, Dinesh , journal=
-
[4]
Electronics , volume=
Multi-scale fully convolutional network-based semantic segmentation for mobile robot navigation , author=. Electronics , volume=
-
[5]
Kim, Joonkyung and Sim, Joonyeol and Kim, Woojun and Sycara, Katia and Nam, Changjoo , booktitle=
-
[6]
Shah, Dhruv and Sridhar, Ajay and Bhorkar, Arjun and Hirose, Noriaki and Levine, Sergey , booktitle=
-
[7]
Shah, Dhruv and Sridhar, Ajay and Dashora, Nitish and Stachowicz, Kyle and Black, Kevin and Hirose, Noriaki and Levine, Sergey , booktitle=
-
[8]
Proceedings of IEEE International Conference on Robotics and Automation , pages=
Nomad: Goal masked diffusion policies for navigation and exploration , author=. Proceedings of IEEE International Conference on Robotics and Automation , pages=
-
[10]
Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Flownav: Combining flow matching and depth priors for efficient navigation , author=. Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
-
[11]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Unidepthv2: Universal monocular metric depth estimation made simpler , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[12]
IEEE Robotics and Automation Letters , volume=
Safe-vln: Collision avoidance for vision-and-language navigation of autonomous robots operating in continuous environments , author=. IEEE Robotics and Automation Letters , volume=
-
[13]
Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Oneformer: One transformer to rule universal image segmentation , author=. Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[14]
Proceedings of International Conference on Machine Learning , pages=
Efficientnet: Rethinking model scaling for convolutional neural networks , author=. Proceedings of International Conference on Machine Learning , pages=
-
[15]
Scene parsing through
Zhou, Bolei and Zhao, Hang and Puig, Xavier and Fidler, Sanja and Barriuso, Adela and Torralba, Antonio , booktitle=. Scene parsing through
-
[16]
Hirose, Noriaki and Shah, Dhruv and Sridhar, Ajay and Levine, Sergey , journal=
-
[17]
D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine. GNM : A general navigation model to drive any robot. In Proceedings of IEEE International Conference on Robotics and Automation, pages 7226--7233, 2023 a
2023
-
[18]
D. Shah, A. Sridhar, N. Dashora, K. Stachowicz, K. Black, N. Hirose, and S. Levine. ViNT : A foundation model for visual navigation. In Conference on Robot Learning, pages 711--733, 2023 b
2023
-
[19]
Sridhar, D
A. Sridhar, D. Shah, C. Glossop, and S. Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In Proceedings of IEEE International Conference on Robotics and Automation, pages 63--70, 2024
2024
-
[20]
M. Guerrier, K. Soma, J. Pavlasek, and G. Beltrame. Can vision foundation models navigate? zero-shot real-world evaluation and lessons learned. arXiv preprint arXiv:2603.25937, 2026
Pith/arXiv arXiv 2026
-
[21]
J. Kim, J. Sim, W. Kim, K. Sycara, and C. Nam. CARE : Enhancing safety of visual navigation through collision avoidance via repulsive estimation. In Proceedings of IEEE International Conference on Robotics and Automation, 2025
2025
-
[22]
S. Gode, A. Nayak, D. N. Oliveira, M. Krawez, C. Schmid, and W. Burgard. Flownav: Combining flow matching and depth priors for efficient navigation. In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 17762--17768, 2025
2025
-
[23]
Piccinelli, C
L. Piccinelli, C. Sakaridis, Y.-H. Yang, M. Segu, S. Li, W. Abbeloos, and L. Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[24]
J. Jain, J. Li, M. T. Chiu, A. Hassani, N. Orlov, and H. Shi. Oneformer: One transformer to rule universal image segmentation. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2989--2998, 2023
2023
-
[25]
B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba. Scene parsing through ADE 20k dataset. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pages 633--641, 2017
2017
-
[26]
Tan and Q
M. Tan and Q. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of International Conference on Machine Learning, pages 6105--6114, 2019
2019
-
[27]
Hirose, D
N. Hirose, D. Shah, A. Sridhar, and S. Levine. SACSoN : Scalable autonomous control for social navigation. IEEE Robotics and Automation Letters, 9 0 (1): 0 49--56, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.