TouchThinker: Scaling Tactile Commonsense Reasoning to the Open World with Large-scale Data and Action-aware Representation
Pith reviewed 2026-06-27 10:13 UTC · model grok-4.3
The pith
TouchThinker scales tactile commonsense reasoning to open-world tasks with a million-scale dataset and action-aware representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TouchThinker shows that a million-scale, multi-source tactile reasoning dataset together with an action-aware modeling mechanism produces representations that support competitive commonsense inference from tactile observations across multiple existing datasets and a new open-world benchmark.
What carries the argument
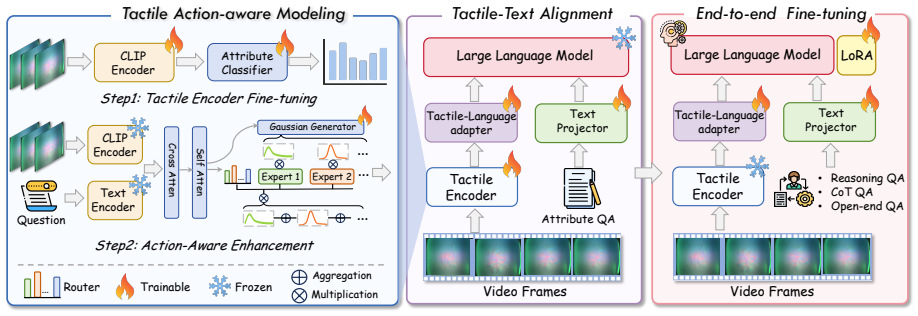
The action-aware modeling mechanism that conditions tactile feature extraction on the producing action to reduce redundancy and increase semantic content, supported by the TouchThinker-1M dataset.
If this is right
- Tactile observations become a reliable input for language-based physical reasoning without heavy reliance on vision.
- Larger and more diverse tactile collections reduce the data bottleneck that currently limits embodied commonsense.
- Action context makes tactile features more efficient and less redundant for downstream inference tasks.
- The new TouchThinker-Bench provides a concrete testbed for measuring progress toward realistic open-world performance.
Where Pith is reading between the lines
- The same scaling recipe could be tested on other under-represented modalities such as proprioception or audio to check whether action-aware modeling generalizes.
- Deployment on physical robots would reveal whether the learned representations survive real sensor noise and embodiment gaps not captured in the collected dataset.
- Combining the tactile stream with existing vision-language models might produce tighter multimodal physical reasoning than either modality alone.
Load-bearing premise
The collected multi-source tactile data will yield representations that transfer to new sensors, objects, and scenarios rather than overfitting to the training distributions.
What would settle it
A sharp drop in accuracy when the model is tested on tactile signals from an eighth sensor type or on object interactions absent from the 415 training objects would falsify the open-world generalization claim.
Figures









read the original abstract
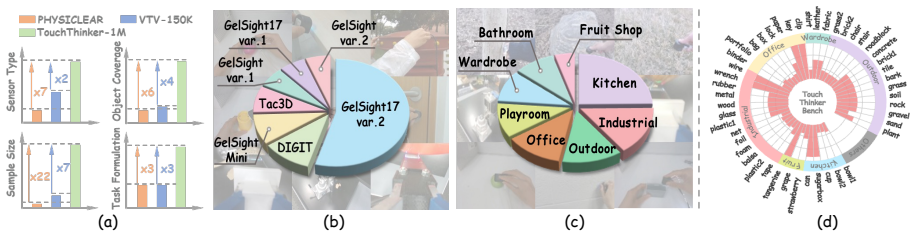
Touch is a key modality for embodied agents to understand the physical world. Although recent work has incorporated tactile signals into language systems for tactile commonsense reasoning, scaling such systems to realistic open-world settings remains challenging due to two key bottlenecks: (1) current tactile reasoning datasets remain limited in format and scale, providing insufficient supervision for reasoning from tactile observations to physical commonsense and hindering the learning of transferable tactile commonsense; (2) Tactile signals are inherently redundant and action-specific, yet existing methods often overlook these properties, resulting in inefficient representations with limited semantic expressiveness. To address these limitations, we propose TouchThinker, a tactile-language framework that scales tactile commonsense reasoning to the open world from both data and representation perspectives. First, we construct TouchThinker-1M, a million-scale, multi-source tactile reasoning dataset covering \textbf{415} objects, \textbf{8} scenarios, and \textbf{7} sensor types, providing a solid data foundation for open-world generalization. We further introduce TouchThinker-Bench, an open-world benchmark with more realistic and diverse tasks. Then, we propose action-aware modeling mechanism to improve tactile representation efficiency and enable efficient reasoning. Experimental results demonstrate that TouchThinker achieves competitive performance against state-of-the-art models across multiple datasets. Our code and dataset will be made available at: https://github.com/lvkailin0118/TouchThinker.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TouchThinker, a tactile-language framework that constructs the million-scale TouchThinker-1M dataset (covering 415 objects, 8 scenarios, and 7 sensor types) and the TouchThinker-Bench benchmark to scale tactile commonsense reasoning to open-world settings. It proposes an action-aware modeling mechanism to address redundancy and action-specificity in tactile signals, claiming competitive performance against state-of-the-art models across multiple datasets.
Significance. If the generalization claims are validated through appropriate transfer experiments, the work would be significant for embodied AI by releasing a large multi-source tactile dataset and benchmark that directly tackle data-scale limitations in the field. The commitment to public code and dataset release is a clear strength that could enable follow-on research.
major comments (2)
- [Abstract and §1] Abstract and §1: The central claim of open-world generalization via the million-scale dataset and action-aware representation rests on untested transfer; the manuscript reports no hold-one-sensor-type-out or hold-one-scenario-out experiments despite using exactly the same 7 sensor types and 8 scenarios for both TouchThinker-1M construction and TouchThinker-Bench, so in-distribution pattern matching cannot be ruled out as an alternative explanation for the competitive results.
- [Experimental results section] Experimental results section: No quantitative metrics, ablation studies on the action-aware component, error bars, or implementation details (e.g., how action awareness is encoded in the representation) are supplied to support the performance claims, making it impossible to evaluate whether the reported competitiveness is attributable to the proposed mechanisms.
minor comments (2)
- [Abstract] Abstract: The statement of 'competitive performance' would be strengthened by including at least one key quantitative result or comparison table reference.
- [Dataset description] Dataset description: Clarify whether TouchThinker-1M includes any explicit train/test splits that enforce sensor or scenario separation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the open-world generalization claims require stronger validation and that the experimental section lacks necessary details. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The central claim of open-world generalization via the million-scale dataset and action-aware representation rests on untested transfer; the manuscript reports no hold-one-sensor-type-out or hold-one-scenario-out experiments despite using exactly the same 7 sensor types and 8 scenarios for both TouchThinker-1M construction and TouchThinker-Bench, so in-distribution pattern matching cannot be ruled out as an alternative explanation for the competitive results.
Authors: We acknowledge the validity of this observation. While TouchThinker-Bench incorporates more realistic and diverse tasks across the multi-source data to approximate open-world conditions, the manuscript does not include explicit hold-one-sensor-type-out or hold-one-scenario-out transfer experiments. To strengthen the generalization claims, we will add these experiments and report the results in the revised version. revision: yes
-
Referee: [Experimental results section] Experimental results section: No quantitative metrics, ablation studies on the action-aware component, error bars, or implementation details (e.g., how action awareness is encoded in the representation) are supplied to support the performance claims, making it impossible to evaluate whether the reported competitiveness is attributable to the proposed mechanisms.
Authors: We agree that the experimental reporting is insufficient. The revised manuscript will include quantitative performance metrics with error bars, dedicated ablation studies isolating the action-aware modeling component, and explicit implementation details on how action awareness is encoded in the tactile representation. revision: yes
Circularity Check
No circularity; empirical claims rest on independent experimental evaluation
full rationale
The paper constructs a new million-scale dataset (TouchThinker-1M) covering 415 objects, 8 scenarios and 7 sensor types, introduces an action-aware modeling mechanism, and reports competitive performance on TouchThinker-Bench plus other datasets. No equations, derivations, fitted-parameter predictions, or self-citation chains appear in the abstract or described content that would reduce any central claim to its own inputs by construction. The results are presented as empirical outcomes on held-out tasks, satisfying the criterion for a self-contained, externally falsifiable evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tactile signals contain sufficient information for commonsense physical reasoning when paired with language models and appropriate scale of data.
Reference graph
Works this paper leans on
-
[1]
Australasian journal of philosophy , volume=
The sense of touch , author=. Australasian journal of philosophy , volume=. 1989 , publisher=
1989
-
[2]
The international journal of medical robotics and computer assisted surgery , volume=
Human tactile perception as a standard for artificial tactile sensing—a review , author=. The international journal of medical robotics and computer assisted surgery , volume=. 2004 , publisher=
2004
-
[3]
Robotics and Computer-Integrated Manufacturing , volume=
A comprehensive review of robot intelligent grasping based on tactile perception , author=. Robotics and Computer-Integrated Manufacturing , volume=. 2024 , publisher=
2024
-
[4]
arXiv preprint arXiv:2405.02794 , year=
Octopi: Object property reasoning with large tactile-language models , author=. arXiv preprint arXiv:2405.02794 , year=
-
[5]
arXiv preprint arXiv:2507.09985 , year=
Demonstrating the octopi-1.5 visual-tactile-language model , author=. arXiv preprint arXiv:2507.09985 , year=
-
[6]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[7]
Advances in Neural Information Processing Systems , volume=
Universal visuo-tactile video understanding for embodied interaction , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Advances in neural information processing systems , volume=
Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training , author=. Advances in neural information processing systems , volume=
-
[9]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[10]
International journal of computer vision , volume=
The pascal visual object classes (voc) challenge , author=. International journal of computer vision , volume=. 2010 , publisher=
2010
-
[11]
Information Fusion , volume=
From image to language: A critical analysis of visual question answering (vqa) approaches, challenges, and opportunities , author=. Information Fusion , volume=. 2024 , publisher=
2024
-
[12]
Measurement , volume=
Tactile sensors: A review , author=. Measurement , volume=. 2024 , publisher=
2024
-
[13]
IEEE Sensors Journal , year=
Classification of vision-based tactile sensors: A review , author=. IEEE Sensors Journal , year=
-
[14]
IEEE Sensors Journal , volume=
Visuotactile sensors with emphasis on gelsight sensor: A review , author=. IEEE Sensors Journal , volume=. 2020 , publisher=
2020
-
[15]
arXiv preprint arXiv:2603.19201 , year=
Omnivta: Visuo-tactile world modeling for contact-rich robotic manipulation , author=. arXiv preprint arXiv:2603.19201 , year=
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
TouchFormer: A Robust Transformer-based Framework for Multimodal Material Perception , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
Science Bulletin , volume=
Recent progress in tactile sensors and their applications in intelligent systems , author=. Science Bulletin , volume=. 2020 , publisher=
2020
-
[18]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Binding touch to everything: Learning unified multimodal tactile representations , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[19]
arXiv preprint arXiv:2406.13640 , year=
Transferable tactile transformers for representation learning across diverse sensors and tasks , author=. arXiv preprint arXiv:2406.13640 , year=
-
[20]
IEEE Robotics and Automation Letters , year=
UniT: Data efficient tactile representation with generalization to unseen objects , author=. IEEE Robotics and Automation Letters , year=
-
[21]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Taming transformers for high-resolution image synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[22]
arXiv preprint arXiv:2502.12191 , year=
Anytouch: Learning unified static-dynamic representation across multiple visuo-tactile sensors , author=. arXiv preprint arXiv:2502.12191 , year=
-
[23]
arXiv preprint arXiv:2409.18991 , year=
Surveying the mllm landscape: A meta-review of current surveys , author=. arXiv preprint arXiv:2409.18991 , year=
-
[24]
National Science Review , volume=
A survey on multimodal large language models , author=. National Science Review , volume=. 2024 , publisher=
2024
-
[25]
arXiv preprint arXiv:2202.10936 , year=
A survey of vision-language pre-trained models , author=. arXiv preprint arXiv:2202.10936 , year=
-
[26]
IEEE transactions on pattern analysis and machine intelligence , volume=
Vision-language models for vision tasks: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2024 , publisher=
2024
-
[27]
IEEE/CAA Journal of Automatica Sinica , volume=
Exploring DeepSeek: A survey on advances, applications, challenges and future directions , author=. IEEE/CAA Journal of Automatica Sinica , volume=. 2025 , publisher=
2025
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
STOLA: Self-Adaptive Touch-Language Framework for Tactile Commonsense Reasoning in Open-Ended Scenarios , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[29]
arXiv preprint arXiv:2211.12498 , year=
Touch and go: Learning from human-collected vision and touch , author=. arXiv preprint arXiv:2211.12498 , year=
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
The objectfolder benchmark: Multisensory learning with neural and real objects , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[31]
Conference on Robot Learning , pages=
Midastouch: Monte-carlo inference over distributions across sliding touch , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[32]
arXiv preprint arXiv:2410.24090 , year=
Sparsh: Self-supervised touch representations for vision-based tactile sensing , author=. arXiv preprint arXiv:2410.24090 , year=
-
[33]
Science Robotics , volume=
NeuralFeels with neural fields: Visuotactile perception for in-hand manipulation , author=. Science Robotics , volume=. 2024 , publisher=
2024
-
[34]
2014 IEEE haptics symposium (HAPTICS) , pages=
One hundred data-driven haptic texture models and open-source methods for rendering on 3D objects , author=. 2014 IEEE haptics symposium (HAPTICS) , pages=. 2014 , organization=
2014
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
IEEE Transactions on Multimedia , year=
Moe-llava: Mixture of experts for large vision-language models , author=. IEEE Transactions on Multimedia , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Mova: Adapting mixture of vision experts to multimodal context , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[39]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[40]
arXiv preprint arXiv:2508.02324 , year=
Qwen-image technical report , author=. arXiv preprint arXiv:2508.02324 , year=
-
[41]
Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments , author=. Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
-
[42]
Brain Science Advances , volume=
Embodied tactile perception and learning , author=. Brain Science Advances , volume=. 2020 , publisher=
2020
-
[43]
Advances in Neural Information Processing Systems , volume=
Multitrust: A comprehensive benchmark towards trustworthy multimodal large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Industrial Robot: An International Journal , volume=
Tactile sensing in intelligent robotic manipulation--a review , author=. Industrial Robot: An International Journal , volume=. 2005 , publisher=
2005
-
[45]
Nature Communications , volume=
Behavioral biometric optical tactile sensor for instantaneous decoupling of dynamic touch signals in real time , author=. Nature Communications , volume=. 2024 , publisher=
2024
-
[46]
arXiv preprint arXiv:2601.03267 , year=
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
-
[47]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author =
-
[48]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.