Can Open-Source LLM Agents Replace Static Application Security Testing Tools? An Empirical Assessment
Pith reviewed 2026-06-27 09:24 UTC · model grok-4.3
The pith
Open-source LLM agents are currently unsuitable for replacing SAST tools in realistic vulnerability scanning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The study finds that LLM-based agents powered by open-source models do not match the performance of the Bandit SAST tool when evaluated on precision, recall, false positive counts, and a derived composite score under conditions designed to reflect realistic usage.
What carries the argument
The empirical comparison of agent performance metrics against the Bandit baseline on vulnerability detection tasks.
If this is right
- SAST scanning remains a domain where traditional tools outperform current open-source LLM agents.
- Organizations should not rely on general-purpose LLM agents for primary security code analysis.
- The composite scoring method highlights trade-offs in detection accuracy versus alert volume.
Where Pith is reading between the lines
- Hybrid systems combining LLM agents with SAST tools could be explored to leverage strengths of both.
- Scaling up model size or using domain-specific fine-tuning might close the performance gap in future iterations.
- Similar assessments could be applied to other cybersecurity tasks like dynamic analysis or threat modeling.
Load-bearing premise
The test cases, threat models, and evaluation conditions used in the study are representative of realistic SAST usage scenarios in production software.
What would settle it
An open-source LLM agent that achieves a higher composite score than Bandit on the same set of test cases with realistic code samples would falsify the central claim.
Figures

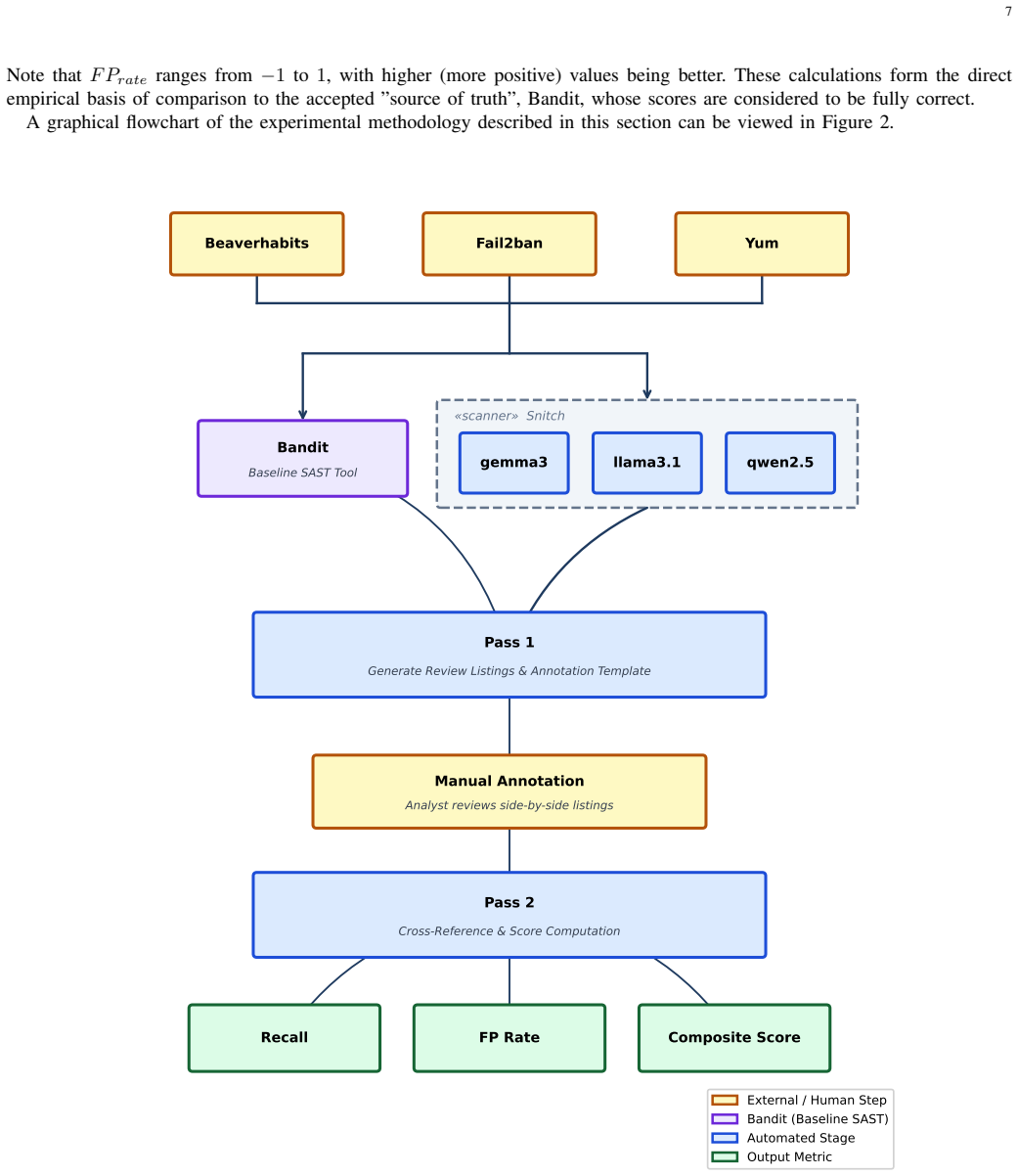
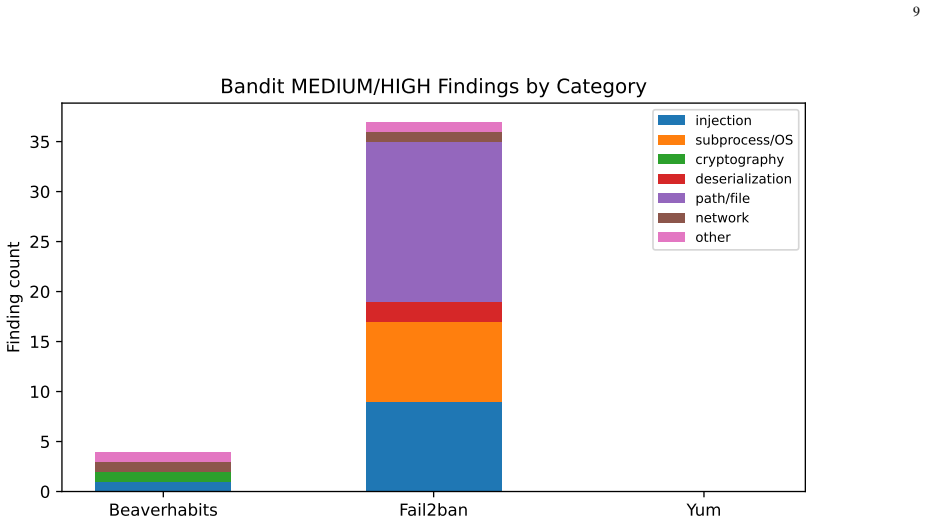
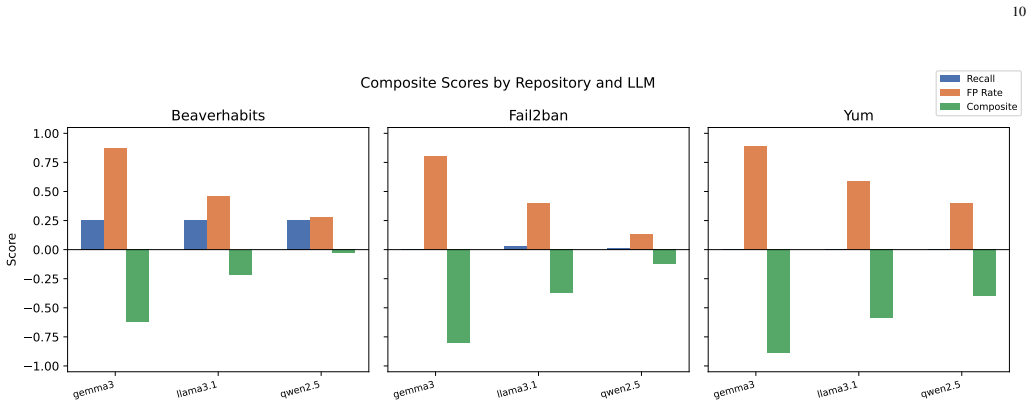
read the original abstract
This paper explores the value of agentic AI tools for cybersecurity purposes. We evaluate the efficacy of a general-purpose GenAI Large Language Model- (GenAI-) based agent when powered by three different Ollama-hosted general-purpose open source models. We assess each agent's performance using precision, recall, false positive count, and a calculated composite score based upon the interplay of the captured metrics, against the baseline performance of an existing, vetted Static Application Security Testing (SAST) tool, Bandit. Our findings refute the notion that a modern open-source GenAI LLM-based agent is currently suitable for the specialized task of SAST scanning under realistic conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates three Ollama-hosted open-source LLM agents for static application security testing (SAST) by measuring precision, recall, false-positive counts, and a composite score, then compares these against the Bandit baseline. It concludes that current open-source GenAI LLM agents are not suitable for SAST under realistic conditions.
Significance. A well-supported negative result on LLM-agent suitability for SAST would be useful for the security-tooling community, as it would supply concrete empirical bounds on current open-source models. The manuscript supplies no machine-checked proofs, reproducible artifacts, or parameter-free derivations, so its value rests entirely on the quality and representativeness of the empirical comparison.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): the central refutation claim requires that the test cases, vulnerability types, code complexity, and prompting setup match production SAST usage. No dataset size, source (synthetic vs. real repositories), languages, or operationalization of 'realistic conditions' is supplied, so the negative result cannot be assessed for generalizability.
- [§3 and Table 1] §3 (Methodology) and Table 1: without explicit counts of true positives, false positives, and the exact prompting template used for each model, it is impossible to verify whether the reported composite scores actually support the claim that the agents underperform Bandit.
minor comments (2)
- [Abstract] Abstract: state the exact Ollama model identifiers and versions used.
- [Figure 1] Figure 1: axis labels and legend are too small to read at print size.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which identify important gaps in the presentation of our empirical setup and results. We address each point below and will revise the manuscript to supply the requested details.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the central refutation claim requires that the test cases, vulnerability types, code complexity, and prompting setup match production SAST usage. No dataset size, source (synthetic vs. real repositories), languages, or operationalization of 'realistic conditions' is supplied, so the negative result cannot be assessed for generalizability.
Authors: We agree that these details are necessary to evaluate generalizability. In the revised manuscript we will expand the Evaluation section (and update the abstract if space permits) to report dataset size, source (synthetic or real repositories), languages, vulnerability types, code-complexity metrics, and an explicit operationalization of the 'realistic conditions' under which the agents were tested. This will allow readers to assess the scope of the negative result. revision: yes
-
Referee: [§3 and Table 1] §3 (Methodology) and Table 1: without explicit counts of true positives, false positives, and the exact prompting template used for each model, it is impossible to verify whether the reported composite scores actually support the claim that the agents underperform Bandit.
Authors: We acknowledge that raw counts and prompting templates must be provided for verification. The revised version will add explicit true-positive and false-positive counts for each LLM agent and the Bandit baseline, together with the exact prompting templates, either by expanding Table 1 or by adding a supplementary table in an appendix. revision: yes
Circularity Check
Pure empirical comparison; no circularity in derivation chain
full rationale
The paper conducts an empirical evaluation of LLM agents against the external Bandit SAST baseline using precision, recall, and composite scores. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the provided abstract or described methodology. The central claim rests on direct performance measurements rather than any reduction to inputs by construction. Representativeness of test cases is a validity concern outside the scope of circularity analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
U. K. Durrani, M. Akpinar, M. Fatih Adak, A. Talha Kabakus, M. Maruf ¨Ozt¨urk, and M. Saleh, “A Decade of Progress: A Systematic Literature Review on the Integration of AI in Software Engineering Phases and Activities (2013-2023),”IEEE Access, vol. 12, pp. 171 185–171 204, 2024. [Online]. Available: https://ieeexplore.ieee.org/document/10740293
arXiv 2013
-
[2]
Taking the Chat out of Chatbot? Collecting User Reviews with Chatbots and Web Forms
A. Sachdeva, A. Kim, and A. R. Dennis, “Taking the Chat out of Chatbot? Collecting User Reviews with Chatbots and Web Forms.”Journal of Management Information Systems, vol. 41, no. 1, pp. 146–177, Jan. 2024. [Online]. Available: https://research.ebsco.com/linkprocessor/plink?id=f395235d-d38c-3208-8bb3-f687fc941564
2024
-
[3]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inProceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY , USA: Curran Associates Inc., 2017, p. 6000–6010
2017
-
[4]
ImageNet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,”Communications of the ACM, vol. 60, no. 6, pp. 84–90, May 2017. [Online]. Available: https://dl.acm.org/doi/10.1145/3065386
-
[5]
The Conditions of Artificial General Intelligence: Logic, Autonomy, Resilience, Integrity, Morality, Emotion, Embodiment, and Embeddedness,
Y . Maruyama, “The Conditions of Artificial General Intelligence: Logic, Autonomy, Resilience, Integrity, Morality, Emotion, Embodiment, and Embeddedness,” inArtificial General Intelligence, B. Goertzel, A. I. Panov, A. Potapov, and R. Yampolskiy, Eds. Cham: Springer International Publishing, 2020, pp. 242–251
2020
-
[6]
R. Aguilar-L ´opez, A. J. S ´anchez-Garc´ıa, J. C. P´erez-Arriaga, and X. Lim ´on, “The Impact of Generative Artificial Intelligence on Software Development Teams During the Construction Phase: Systematic Mapping Study,” in2025 13th International Conference in Software Engineering Research and Innovation (CONISOFT), Oct. 2025, pp. 316–324. [Online]. Avail...
arXiv 2025
-
[7]
On the use of agentic coding manifests: An empirical study of claude code,
W. Chatlatanagulchai, K. Thonglek, B. Reid, Y . Kashiwa, P. Leelaprute, A. Rungsawang, B. Manaskasemsak, and H. Iida, “On the use of agentic coding manifests: An empirical study of claude code,” inProduct-Focused Software Process Improvement: 26th International Conference, PROFES 2025, Salerno, Italy, December 1–3, 2025, Proceedings. Berlin, Heidelberg: S...
2025
-
[8]
Decoding the configuration of ai coding agents: Insights from claude code projects,
H. V . F. d. Santos, V . Costa, J. a. E. Montandon, and M. T. Valente, “Decoding the configuration of ai coding agents: Insights from claude code projects,” inProceedings of the 2026 International Workshop on Agentic Engineering, ser. AGENT ’26. New York, NY , USA: Association for Computing Machinery, 2026, p. 63–67
2026
-
[9]
Building and Hosting AI Locally with Ollama, Open WebUI, and Stable Diffusion,
A. Srinivas, V . Hegde, A. G. S, A. Singh, and Fayaz, “Building and Hosting AI Locally with Ollama, Open WebUI, and Stable Diffusion,” in2025 9th International Conference on Computational System and Information Technology for Sustainable Solutions (CSITSS), Nov. 2025, pp. 1–6, iSSN: 2767-1097. [Online]. Available: https://ieeexplore.ieee.org/document/11295791
arXiv 2025
-
[10]
Ollama’s documentation
“Ollama’s documentation.” [Online]. Available: https://docs.ollama.com
-
[11]
Comparative Analysis of Open-Source Tools for Conducting Static Code Analysis
K. Kuszczy ´nski and M. Walkowski, “Comparative Analysis of Open-Source Tools for Conducting Static Code Analysis.”Sensors (14248220), vol. 23, no. 18, p. 7978, Sep. 2023. [Online]. Available: https://research.ebsco.com/linkprocessor/plink?id=c1ee9410-d3d1-3b0a-afd6-cf5ef0eded31
2023
-
[12]
G. Bennett, T. Hall, S. Counsell, E. Winter, and T. Shippey, “Do Developers Use Static Application Security Testing (SAST) Tools Straight Out of the Box? A large-scale Empirical Study,” inProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, ser. ACM Conferences, Oct. 2024, pp. 454–460. [Online]. Avail...
-
[13]
Comparison and Evaluation on Static Application Security Testing (SAST) Tools for Java,
K. Li, S. Chen, L. Fan, R. Feng, H. Liu, C. Liu, Y . Liu, and Y . Chen, “Comparison and Evaluation on Static Application Security Testing (SAST) Tools for Java,” inProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ser. ACM Conferences, Nov. 2023, pp. 921–933. [Online]. Avai...
-
[14]
Security Best Practices and Tools for the Software Development Lifecycle,
A.-M. Stanciu, “Security Best Practices and Tools for the Software Development Lifecycle,” in2025 5th International Conference on Electrical, Computer and Energy Technologies (ICECET), Jul. 2025, pp. 1–6. [Online]. Available: https://ieeexplore.ieee.org/document/11472566
arXiv 2025
-
[15]
Agentic AI: Autonomous Intelligence for Complex Goals—A Comprehensive Survey,
D. B. Acharya, K. Kuppan, and B. Divya, “Agentic AI: Autonomous Intelligence for Complex Goals—A Comprehensive Survey,”IEEE Access, vol. 13, pp. 18 912–18 936, 2025. [Online]. Available: https://ieeexplore.ieee.org/document/10849561
arXiv 2025
-
[16]
Agentic AI: A Comprehensive Survey of Technologies, Applications, and Societal Implications,
A. K. Pati, “Agentic AI: A Comprehensive Survey of Technologies, Applications, and Societal Implications,”IEEE Access, vol. 13, pp. 151 824–151 837,
-
[17]
Available: https://ieeexplore.ieee.org/document/11071266
[Online]. Available: https://ieeexplore.ieee.org/document/11071266
-
[18]
The Evolution of Generative AI: Trends and Applications,
M. Trigka and E. Dritsas, “The Evolution of Generative AI: Trends and Applications,”IEEE Access, vol. 13, pp. 98 504–98 529, 2025. [Online]. Available: https://ieeexplore.ieee.org/document/11016906
arXiv 2025
-
[19]
K. Ahi and S. Valizadeh, “Large Language Models (LLMs) and Generative AI in Cybersecurity and Privacy: A Survey of Dual-Use Risks, AI-Generated Malware, Explainability, and Defensive Strategies,” in2025 Silicon Valley Cybersecurity Conference (SVCC), Jun. 2025, pp. 1–8. [Online]. Available: https://ieeexplore.ieee.org/document/11133642/
arXiv 2025
-
[20]
Cyber Attack Prediction: From Traditional Machine Learning to Generative Artificial Intelligence,
S. Ankalaki, A. R. Atmakuri, M. Pallavi, G. S. Hukkeri, T. Jan, and G. R. Naik, “Cyber Attack Prediction: From Traditional Machine Learning to Generative Artificial Intelligence,”IEEE Access, vol. 13, pp. 44 662–44 706, 2025. [Online]. Available: https://ieeexplore.ieee.org/document/10909100
arXiv 2025
-
[21]
The Significance of Machine Learning and Deep Learning Techniques in Cybersecurity: A Comprehensive Review,
M. Mijwil, I. Salem, and M. Ismaeel, “The Significance of Machine Learning and Deep Learning Techniques in Cybersecurity: A Comprehensive Review,” Iraqi Journal for Computer Science and Mathematics, vol. 4, no. 1, Jan. 2023. [Online]. Available: https://ijcsm.researchcommons.org/ijcsm/vol4/iss1/10
2023
-
[22]
Machine Learning for Cybersecurity Issues : A systematic Review,
A. Alshuaibi, M. Almaayah, and A. Ali, “Machine Learning for Cybersecurity Issues : A systematic Review,”Journal of Cyber Security and Risk Auditing, vol. 2025, no. 1, pp. 36–46, Feb. 2025. [Online]. Available: https://jcsra.thestap.com/archives/volume-2025-1/4 14
2025
-
[23]
Towards Artificial Intelligence-Based Cybersecurity: The Practices and ChatGPT Generated Ways to Combat Cybercrime,
M. Mijwil and M. Aljanabi, “Towards Artificial Intelligence-Based Cybersecurity: The Practices and ChatGPT Generated Ways to Combat Cybercrime,” Iraqi Journal for Computer Science and Mathematics, vol. 4, no. 1, Jan. 2023. [Online]. Available: https://ijcsm.researchcommons.org/ijcsm/vol4/iss1/8
2023
-
[24]
The Future of AI-Driven Software Engineering,
V . Terragni, A. Vella, P. Roop, and K. Blincoe, “The Future of AI-Driven Software Engineering,”ACM Trans. Softw. Eng. Methodol., vol. 34, no. 5, pp. 120:1–120:20, May 2025. [Online]. Available: https://dl.acm.org/doi/10.1145/3715003
-
[25]
Cybersecurity and AI-generated programming code,
W. DImitrov, D. Tsecov, V . Ruzhenov, A. Kirkov, Y . Hadzhiyska, and S. Syarova, “Cybersecurity and AI-generated programming code,” in 2025 International Conference on Big Data, Knowledge and Control Systems Engineering (BdKCSE), Nov. 2025, pp. 1–5. [Online]. Available: https://ieeexplore.ieee.org/document/11300524/
arXiv 2025
-
[26]
Cyber Security Threats of Using Generative Artificial Intelligence in Source Code Management,
S. Nethala, S. Kampa, and S. R. Kosna, “Cyber Security Threats of Using Generative Artificial Intelligence in Source Code Management,”Journal of Informatics and Web Engineering, vol. 4, no. 2, pp. 114–124, Jun. 2025. [Online]. Available: https://journals.mmupress.com/index.php/jiwe/article/view/1568
2025
-
[27]
Prompting techniques for secure code generation: A systematic investigation,
C. Tony, N. E. D ´ıaz Ferreyra, M. Mutas, S. Dhif, and R. Scandariato, “Prompting techniques for secure code generation: A systematic investigation,” ACM Trans. Softw. Eng. Methodol., vol. 34, no. 8, Oct. 2025
2025
-
[28]
AI-driven cybersecurity framework for software development based on the ANN-ISM paradigm,
H. U. Khan, R. A. Khan, H. S. Alwageed, A. O. Almagrabi, S. Ayouni, and M. Maddeh, “AI-driven cybersecurity framework for software development based on the ANN-ISM paradigm,”Scientific Reports, vol. 15, no. 1, pp. 1–45, Apr. 2025. [Online]. Available: https://research.ebsco.com/linkprocessor/plink?id=29ce6798-9dd7-3580-9a24-455ea1e9adb3
2025
-
[29]
G. Siewruk and M. Berej, “Transformation of Vulnerability Management Through Artificial Intelligence: An Overview of Generative and Learning Models,”IEEE Access, vol. 14, pp. 24 732–24 752, 2026. [Online]. Available: https://ieeexplore.ieee.org/document/11393471
arXiv 2026
-
[30]
Multi-Agent Systems: A Survey,
A. Dorri, S. S. Kanhere, and R. Jurdak, “Multi-Agent Systems: A Survey,”IEEE Access, vol. 6, pp. 28 573–28 593, 2018. [Online]. Available: https://ieeexplore.ieee.org/document/8352646
arXiv 2018
-
[31]
Software Security Analysis in 2030 and Beyond: A Research Roadmap,
M. B ¨ohme, E. Bodden, T. Bultan, C. Cadar, Y . Liu, and G. Scanniello, “Software Security Analysis in 2030 and Beyond: A Research Roadmap,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 5, pp. 1–26, May 2025. [Online]. Available: https://dl.acm.org/doi/10.1145/3708533
-
[32]
Security Framework for Agentic Home AI in Preventive Healthcare: Cyber Threats Worth Noting,
C. P. Obeng, N. M. Narasinghe, R. Striker, and E. A. Vazquez, “Security Framework for Agentic Home AI in Preventive Healthcare: Cyber Threats Worth Noting,” in2025 Cyber Awareness and Research Symposium (CARS), Oct. 2025, pp. 1–5. [Online]. Available: https://ieeexplore.ieee.org/document/11337832
arXiv 2025
-
[33]
H. Xu, S. Wang, N. Li, K. Wang, Y . Zhao, K. Chen, T. Yu, Y . Liu, and H. Wang, “Large Language Models for Cyber Security: A Systematic Literature Review,”ACM Transactions on Software Engineering and Methodology, p. 3769676, Sep. 2025. [Online]. Available: https://dl.acm.org/doi/10.1145/3769676
-
[34]
Navigating the Complexity of Generative AI Adoption in Software Engineering,
D. Russo, “Navigating the Complexity of Generative AI Adoption in Software Engineering,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 5, pp. 1–50, Jun. 2024. [Online]. Available: https://dl.acm.org/doi/10.1145/3652154
-
[35]
Enhanced Web Testing with LLMs: A Research Roadmap,
W. Wang, Z. Guo, Q. Yan, Z. Yang, Y . Zhang, G. Xu, X. Li, and B. Wu, “Enhanced Web Testing with LLMs: A Research Roadmap,”ACM Transactions on Software Engineering and Methodology, vol. 0, no. ja, Feb. 2026. [Online]. Available: https://dl.acm.org/doi/10.1145/3795887
-
[36]
Optimising Vulnerability Triage in DAST with Deep Learning,
S. Millar, D. Podgurskii, D. Kuykendall, J. Mart ´ınez del Rinc ´on, and P. Miller, “Optimising Vulnerability Triage in DAST with Deep Learning,” in Proceedings of the 15th ACM Workshop on Artificial Intelligence and Security, ser. ACM Conferences, Nov. 2022, pp. 137–147. [Online]. Available: https://dl.acm.org/doi/10.1145/3560830.3563724
-
[37]
D. Xu, I. Gondal, X. Yi, T. Susnjak, and T. McIntosh, “Seek and You Shall SOC: Blending Human Expertise with Multimodal Generative AI for Scalable Threat Prevention,”ACM Transactions on Internet Technology, vol. 0, no. ja, Feb. 2026. [Online]. Available: https://dl.acm.org/doi/10.1145/3799420
-
[38]
Llms in software security: A survey of vulnerability detection techniques and insights,
Z. Sheng, Z. Chen, S. Gu, H. Huang, G. Gu, and J. Huang, “LLMs in Software Security: A Survey of Vulnerability Detection Techniques and Insights,”ACM Computing Surveys, vol. 58, no. 5, pp. 1–35, Nov. 2025. [Online]. Available: https://dl.acm.org/doi/10.1145/3769082
-
[39]
Using AI Assistants in Software Development: A Qualitative Study on Security Practices and Concerns,
J. H. Klemmer, S. A. Horstmann, N. Patnaik, C. Ludden, C. Burton, C. Powers, F. Massacci, A. Rahman, D. V otipka, H. R. Lipford, A. Rashid, A. Naiakshina, and S. Fahl, “Using AI Assistants in Software Development: A Qualitative Study on Security Practices and Concerns,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Secu...
-
[40]
Imagining Design Workflows in Agentic AI Futures,
S. Wadinambiarachchi, J. Waycott, Y . Rogers, and G. Wadley, “Imagining Design Workflows in Agentic AI Futures,” inProceedings of the 37th Australian Conference on Human-Computer Interaction, ser. ACM Other conferences, Nov. 2025, pp. 19–35. [Online]. Available: https://dl.acm.org/doi/10.1145/3764687.3764719
-
[41]
Agent-Based AI Approach to Security in IoT Systems Leveraging Genai,
N. Petrovic, D. Krstic, S. Suljovic, S. Hanczewski, and M. Glabowski, “Agent-Based AI Approach to Security in IoT Systems Leveraging Genai,” in 2025 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Sep. 2025, pp. 1–5, iSSN: 1847-358X. [Online]. Available: https://ieeexplore.ieee.org/document/11197348
arXiv 2025
-
[42]
AI-Driven XSS Vulnerability Scanner with Context-Aware Remediation for Web Application Security,
M. K. Ming’ate and Y . K, “AI-Driven XSS Vulnerability Scanner with Context-Aware Remediation for Web Application Security,” in2025 4th International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Sep. 2025, pp. 1839–1845. [Online]. Available: https://ieeexplore.ieee.org/document/11200538
arXiv 2025
-
[43]
ZT-ICAS: A Zero-Trust Integrity-Constrained Framework for Agentic Vulnerability Scanning,
J. P. Pendyala and S. Jeswani, “ZT-ICAS: A Zero-Trust Integrity-Constrained Framework for Agentic Vulnerability Scanning,” in2026 IEEE 5th International Conference on AI in Cybersecurity (ICAIC), Feb. 2026, pp. 1–7. [Online]. Available: https://ieeexplore.ieee.org/document/11395688
arXiv 2026
-
[44]
KNighter: Transforming Static Analysis with LLM-Synthesized Checkers,
C. Yang, Z. Zhao, Z. Xie, H. Li, and L. Zhang, “KNighter: Transforming Static Analysis with LLM-Synthesized Checkers,” inProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, ser. ACM Conferences, Oct. 2025, pp. 655–669. [Online]. Available: https://dl.acm.org/doi/10.1145/3731569.3764827
-
[45]
An evaluation of commonly used Kubernetes security scanning tools,
I. A. Kapetanidou, A. Nizamis, and K. V otis, “An evaluation of commonly used Kubernetes security scanning tools,” inProceedings of the 2nd International Workshop on MetaOS for the Cloud-Edge-IoT Continuum, ser. ACM Conferences, Mar. 2025, pp. 20–25. [Online]. Available: https://dl.acm.org/doi/10.1145/3721889.3721924
-
[46]
H. Al-Shammare, R. Alraddadi, F. Al-Abdulwahhab, M. Niazi, and M. Humayun, “Evaluating the Effectiveness of SAST Tools: A Comparative Study on Vulnerability Detection, Reporting, and Usability,” inProceedings of the 2025 29th International Conference on Evaluation and Assessment in Software Engineering Companion, ser. ACM Other conferences, Jun. 2025, pp....
-
[47]
PyCQA/bandit,
“PyCQA/bandit,” Apr. 2026, original-date: 2018-04-26T09:08:12Z. [Online]. Available: https://github.com/PyCQA/bandit
2026
-
[48]
MITRE-Cyber-Security-CVE-Database/mitre-cve-database,
“MITRE-Cyber-Security-CVE-Database/mitre-cve-database,” Apr. 2026, original-date: 2025-04-16T05:02:38Z. [Online]. Available: https://github.com/MITRE-Cyber-Security-CVE-Database/mitre-cve-database
2026
-
[49]
rpm-software-management/yum,
“rpm-software-management/yum,” Mar. 2026, original-date: 2015-03-04T15:08:35Z. [Online]. Available: https://github.com/rpm-software- management/yum
2026
-
[50]
daya0576/beaverhabits,
H. Zhu, “daya0576/beaverhabits,” Apr. 2026, original-date: 2024-03-11T14:54:02Z. [Online]. Available: https://github.com/daya0576/beaverhabits
2026
-
[51]
dyohn/snitch,
D. Yohn and M. Islam, “dyohn/snitch,” Apr. 2026, original-date: 2026-03-16T23:22:02Z. [Online]. Available: https://github.com/dyohn/snitch
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.