UR-BERT: Scaling Text Encoders for Massively Multilingual TTS Through Universal Romanization and Speech Token Prediction
Pith reviewed 2026-06-27 10:05 UTC · model grok-4.3
The pith
UR-BERT builds TTS text encoders for 495 languages by unifying scripts through Romanization and adding speech token prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UR-BERT processes Romanized versions of text from 495 languages and is trained with an added objective that predicts speech tokens; TTS systems built on this encoder deliver higher quality than prior text encoders across resource levels and generalize to unseen languages.
What carries the argument
Universal Romanization of input text paired with a speech token prediction training objective that produces speech-aware phonetic representations.
If this is right
- TTS development becomes possible for languages that lack any G2P resources or tools.
- Performance gains hold across both high-resource and low-resource language settings.
- The shared representation supports zero-shot use on languages absent from training data.
- The encoder acquires phonetic knowledge in a data-efficient way through the token prediction task.
Where Pith is reading between the lines
- The same Romanization-plus-prediction pattern could apply to other speech tasks such as recognition where script diversity is a bottleneck.
- Further gains might appear if the method is combined with larger pretrained language models for even lower-resource cases.
- Limits would surface on languages where basic Romanization drops critical features like tone or vowel length.
Load-bearing premise
Romanization of text from any script must keep enough phonetic detail to support accurate pronunciation without large losses across all 495 languages.
What would settle it
A side-by-side pronunciation accuracy test on languages with tones or ambiguous Romanization forms, comparing error rates from UR-BERT TTS against a language-specific G2P baseline.
Figures

read the original abstract
We propose UR-BERT, a Romanized transcription-based text-to-speech (TTS) encoder for massively multilingual TTS systems. Conventional grapheme-to-phoneme (G2P)-based approaches are limited to around 100 languages due to the availability of reliable G2P resources. In contrast, UR-BERT scales to 495 languages by unifying diverse writing systems into a shared Romanization representation. To further enhance phonetic fidelity and text-speech alignment, we introduce a speech token prediction objective during training, which encourages the encoder to learn speech-aware phonetic representations in a data-efficient manner. Experiments show that TTS systems built on UR-BERT consistently outperform recent text encoder baselines across a wide range of languages and resource conditions, and demonstrate strong generalization to unseen languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UR-BERT, a text encoder for TTS that unifies 495 languages via shared Romanization (bypassing language-specific G2P) and adds an auxiliary speech-token prediction objective to encourage phonetic representations. It claims that TTS systems built on this encoder consistently outperform recent text-encoder baselines across languages and resource levels while generalizing to unseen languages.
Significance. If the results hold, the work would meaningfully advance scaling of TTS to hundreds of languages by removing dependence on scarce G2P resources; the combination of Romanization and speech-token prediction could offer a practical route to data-efficient multilingual encoders.
major comments (2)
- [Abstract] Abstract: the central claim of consistent outperformance and generalization across 495 languages is stated without any quantitative metrics, baseline specifications, dataset sizes, or error breakdowns, leaving the empirical support for the headline result invisible even at the summary level.
- [Experiments] The universality claim rests on Romanization preserving sufficient phonetic contrast; no described ablation isolates pronunciation error rates on languages whose orthographies encode features absent from standard Romanization (tones, gemination, vowel harmony), which is load-bearing for whether performance gains are driven by the method or by easier languages.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which highlight opportunities to strengthen the presentation of our empirical results and to more explicitly address potential limitations of Romanization. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent outperformance and generalization across 495 languages is stated without any quantitative metrics, baseline specifications, dataset sizes, or error breakdowns, leaving the empirical support for the headline result invisible even at the summary level.
Authors: We agree that the abstract would be more informative with concrete quantitative support. In the revised manuscript we will expand the abstract to report key metrics, including the number of languages evaluated, average relative improvements over the strongest baselines (with specific baseline names), dataset scale, and a brief note on generalization results to unseen languages. revision: yes
-
Referee: [Experiments] The universality claim rests on Romanization preserving sufficient phonetic contrast; no described ablation isolates pronunciation error rates on languages whose orthographies encode features absent from standard Romanization (tones, gemination, vowel harmony), which is load-bearing for whether performance gains are driven by the method or by easier languages.
Authors: This observation is correct and points to a genuine gap in our current analysis. Our experiments report aggregate TTS performance across the full set of 495 languages (including many with tonal and other non-Roman features) and show strong zero-shot generalization, but we do not provide a targeted ablation that isolates pronunciation error rates on the subset of languages whose orthographies contain features poorly captured by standard Romanization. We will add an explicit limitations paragraph acknowledging this and will include a qualitative discussion of language subsets; however, we do not have the per-feature pronunciation error annotations required for a quantitative ablation at this time. revision: partial
Circularity Check
No circularity detected; claims rest on external empirical comparisons
full rationale
The paper presents UR-BERT as a methodological proposal (Romanization unification plus auxiliary speech-token objective) whose value is asserted via direct experimental outperformance against recent text-encoder baselines on 495 languages and unseen-language generalization. No equations, fitted parameters, or self-citations are shown that would make any reported prediction equivalent to its own inputs by construction. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Romanization can be applied uniformly to 495 languages while maintaining phonetic utility for TTS.
Reference graph
Works this paper leans on
-
[1]
Introduction Neural text-to-speech (TTS) systems have achieved substantial progress across languages and speaking styles. Most recent ap- proaches adopt encoder–decoder architectures, in which the en- coder produces linguistic representations that are transformed into acoustic features or speech waveforms by a decoder. While decoder models have advanced r...
Pith/arXiv arXiv 2026
-
[2]
Related Work To extend monolingual text embeddings to multilingual TTS encoders, recent work has adopted BERT-style pretraining for text representations. An early effort in this direction is multilin- gual PLBERT (m-PLBERT), introduced in the StyleTTS2 [24] framework.2 Following the original PL-BERT [23] design, m-PLBERT pretrains the text encoder on phon...
-
[3]
Architecture Overview The key distinctions of the proposed UR-BERT lie in its lan- guage scalability and training objectives
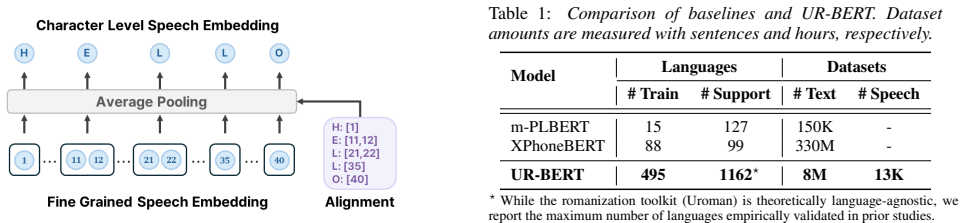
Proposed Method 3.1. Architecture Overview The key distinctions of the proposed UR-BERT lie in its lan- guage scalability and training objectives. UR-BERT adopts Romanization as a unified text representation, enabling scal- able modeling across diverse writing systems without reliance on G2P systems. It is pretrained on speech–text paired data spanning 49...
-
[4]
Experiments 4.1. Pretraining We construct the pretraining corpus by combining three ASR datasets: FLEURS [43], which spans 102 read-speech lan- guages; Common V oice [44], a crowdsourced dataset covering 131 languages; and the Omnilingual ASR corpus [37], which 3https://huggingface.co/facebook/omniASR-W2V-300M Table 1:Comparison of baselines and UR-BERT. ...
-
[5]
Performance on High-Resource Languages Table 2 presents TTS evaluation results on high-resource lan- guages
Results 5.1. Performance on High-Resource Languages Table 2 presents TTS evaluation results on high-resource lan- guages. While VITS achieves strong baseline performance in these settings, incorporating UR-BERT consistently improves both subjective and objective metrics across all evaluated lan- guages. In contrast, m-PLBERT exhibits notable performance d...
-
[6]
Conclusion In this paper, we propose UR-BERT, a multilingual and multi- modal pretrained text encoder for text-to-speech applications. By adopting Romanization as a unified text representation, UR-BERT overcomes the language coverage limitations of conventional G2P pipelines and enables scalable pretraining across 495 languages. To further enhance phoneti...
-
[7]
No generative AI tools were used in the development of research ideas, analytical procedures, or the creation of any substantive scientific content
Generative AI Use Disclosure All co-authors attest that generative AI tools were employed exclusively to refine human-authored text and to support LaTeX formatting of the manuscript, including tables and figures. No generative AI tools were used in the development of research ideas, analytical procedures, or the creation of any substantive scientific cont...
-
[8]
Acknowledgement This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government Ministry of Science and ICT (MSIT) (RS-2026-25468664)
2026
-
[9]
Tacotron: Towards end-to-end speech synthesis,
Y . Wanget al., “Tacotron: Towards end-to-end speech synthesis,” inProc. INTERSPEECH, 2017, pp. 4006–4010
2017
-
[10]
FastSpeech 2: Fast and high-quality end-to-end text to speech,
Y . Renet al., “FastSpeech 2: Fast and high-quality end-to-end text to speech,” inProceedings of the International Conference on Learning Representations, 2021
2021
-
[11]
Glow-TTS: A generative flow for text-to-speech via monotonic alignment search,
J. Kim, S. Kim, J. Kong, and S. Yoon, “Glow-TTS: A generative flow for text-to-speech via monotonic alignment search,” inAd- vances in Neural Information Processing Systems, vol. 33, 2020, pp. 8067–8077
2020
-
[12]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inPro- ceedings of the International Conference on Machine Learning. PMLR, 2021, pp. 5530–5540
2021
-
[13]
Grad-TTS: A diffusion probabilistic model for text-to- speech,
V . Popov, I. V ovk, V . Gogoryan, T. Sadekova, and M. Kudi- nov, “Grad-TTS: A diffusion probabilistic model for text-to- speech,” inProceedings of the International Conference on Ma- chine Learning. PMLR, 2021, pp. 8599–8608
2021
-
[14]
Diff- TTS: A denoising diffusion model for text-to-speech,
M. Jeong, H. Kim, S. J. Cheon, B. J. Choi, and N. S. Kim, “Diff- TTS: A denoising diffusion model for text-to-speech,” inProc. INTERSPEECH, 2021, pp. 3605–3609
2021
-
[15]
Matcha-TTS: A fast tts architecture with conditional flow match- ing,
S. Mehta, R. Tu, J. Beskow, ´E. Sz ´ekely, and G. E. Henter, “Matcha-TTS: A fast tts architecture with conditional flow match- ing,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 11 341–11 345
2024
-
[16]
F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chenet al., “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the Annual Meet- ing of the Association for Computational Linguistics (ACL), 2025, pp. 6255–6271
2025
-
[17]
Neural codec language models are zero-shot text to speech synthesizers,
C. Wanget al., “Neural codec language models are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
Pith/arXiv arXiv 2023
-
[18]
Speak, read and prompt: High-fidelity text- to-speech with minimal supervision,
E. Kharitonovet al., “Speak, read and prompt: High-fidelity text- to-speech with minimal supervision,”Transactions of the Associa- tion for Computational Linguistics, vol. 11, pp. 1703–1718, 2023
2023
-
[19]
BERT: Pre- training of deep bidirectional transformers for language under- standing,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language under- standing,” inProceedings of the Conference of the North Amer- ican Chapter of the Association for Computational Linguistics (NAACL), 2019, pp. 4171–4186
2019
-
[20]
ALBERT: A lite bert for self-supervised learning of language representations,
Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Sori- cut, “ALBERT: A lite bert for self-supervised learning of language representations,” inProceedings of the International Conference on Learning Representations, 2020
2020
-
[21]
A robustly optimized BERT pre-training approach with post-training,
L. Zhuang, L. Wayne, S. Ya, and Z. Jun, “A robustly optimized BERT pre-training approach with post-training,” inProceedings of the 20th Chinese National Conference on Computational Lin- guistics. Huhhot, China: Chinese Information Processing Soci- ety of China, Aug. 2021, pp. 1218–1227
2021
-
[22]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 12 449–12 460
2020
-
[23]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhut- dinov, and A. Mohamed, “HuBERT: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 29, pp. 3451–3460, 2021
2021
-
[24]
WavLM: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[25]
Pre-trained text embeddings for enhanced text-to- speech synthesis,
T. Hayashi, S. Watanabe, T. Toda, K. Takeda, S. Toshniwal, and K. Livescu, “Pre-trained text embeddings for enhanced text-to- speech synthesis,” inProc. INTERSPEECH, 2019, pp. 4430– 4434
2019
-
[26]
Improving the prosody of RNN-based English text-to-speech synthesis by incorporating a BERT model,
T. Kenter, M. Sharma, and R. Clark, “Improving the prosody of RNN-based English text-to-speech synthesis by incorporating a BERT model,” inProc. INTERSPEECH, 2020, pp. 4412–4416
2020
-
[27]
Improving prosody with linguistic and BERT derived features in multi-speaker based Mandarin Chinese neural TTS,
Y . Xiao, L. He, H. Ming, and F. K. Soong, “Improving prosody with linguistic and BERT derived features in multi-speaker based Mandarin Chinese neural TTS,” inProceedings of the IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 6704–6708
2020
-
[28]
Im- proving prosody modelling with cross-utterance bert embeddings for end-to-end speech synthesis,
G. Xu, W. Song, Z. Zhang, C. Zhang, X. He, and B. Zhou, “Im- proving prosody modelling with cross-utterance bert embeddings for end-to-end speech synthesis,” inProceedings of the IEEE In- ternational Conference on Acoustics, Speech and Signal Process- ing (ICASSP), 2021, pp. 6079–6083
2021
-
[29]
PnG BERT: Aug- mented BERT on phonemes and graphemes for neural TTS,
Y . Jia, H. Zen, J. Shen, Y . Zhang, and Y . Wu, “PnG BERT: Aug- mented BERT on phonemes and graphemes for neural TTS,” in Proc. INTERSPEECH, 2021, pp. 151–155
2021
-
[30]
Mixed-Phoneme BERT: Improving BERT with mixed phoneme and sup-phoneme representations for text to speech,
G. Zhanget al., “Mixed-Phoneme BERT: Improving BERT with mixed phoneme and sup-phoneme representations for text to speech,” inProc. INTERSPEECH, 2022, pp. 456–460
2022
-
[31]
Phoneme-level BERT for enhanced prosody of text-to-speech with grapheme pre- dictions,
Y . A. Li, C. Han, X. Jiang, and N. Mesgarani, “Phoneme-level BERT for enhanced prosody of text-to-speech with grapheme pre- dictions,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1– 5
2023
-
[32]
StyleTTS 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,
Y . A. Li, C. Han, V . Raghavan, G. Mischler, and N. Mesgarani, “StyleTTS 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models,” inAdvances in Neural Information Processing Systems, vol. 36, 2023, pp. 19 594–19 621
2023
-
[33]
XPhoneBERT: A pre-trained multilingual model for phoneme representations for text-to-speech,
L. The Nguyen, T. Pham, and D. Q. Nguyen, “XPhoneBERT: A pre-trained multilingual model for phoneme representations for text-to-speech,” inProc. INTERSPEECH, 2023, pp. 5506–5510
2023
-
[34]
Phonemizer: Text to phones transcrip- tion for multiple languages in python,
M. Bernard and H. Titeux, “Phonemizer: Text to phones transcrip- tion for multiple languages in python,”Journal of Open Source Software, vol. 6, no. 68, p. 3958, 2021
2021
-
[35]
ByT5 model for massively multilingual grapheme-to-phoneme conversion,
J. Zhu, C. Zhang, and D. Jurgens, “ByT5 model for massively multilingual grapheme-to-phoneme conversion,” inProc. INTER- SPEECH, 2022, pp. 446–450
2022
-
[36]
Attention is all you need,
A. Vaswaniet al., “Attention is all you need,” inAdvances in Neu- ral Information Processing Systems, vol. 30, 2017
2017
-
[37]
Out-of-the-box universal Romanization tool uroman,
U. Hermjakob, J. May, and K. Knight, “Out-of-the-box universal Romanization tool uroman,” inProceedings of the Annual Meet- ing of the Association for Computational Linguistics (ACL), Sys- tem Demonstrations, 2018, pp. 13–18
2018
-
[38]
XTTS: a massively multilingual zero-shot text-to-speech model,
E. Casanovaet al., “XTTS: a massively multilingual zero-shot text-to-speech model,” inProc. INTERSPEECH, 2024, pp. 4978– 4982
2024
-
[39]
Scaling speech technology to 1,000+ languages,
V . Pratap, A. Tjandra, B. Shi, P. Tomasello, A. Babu, S. Kundu, A. Elkahky, Z. Ni, A. Vyas, M. Fazel-Zarandiet al., “Scaling speech technology to 1,000+ languages,”Journal of Machine Learning Research, vol. 25, no. 97, pp. 1–52, 2024
2024
-
[40]
LAMA-UT: Language agnostic multilingual ASR through orthography unification and language-specific transliteration,
S. Lee, W. Chung, and H.-G. Kang, “LAMA-UT: Language agnostic multilingual ASR through orthography unification and language-specific transliteration,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 23, 2025, pp. 24 393–24 401
2025
-
[41]
Cambridge University Press, 1999
International Phonetic Association,Handbook of the Interna- tional Phonetic Association: A guide to the use of the Interna- tional Phonetic Alphabet. Cambridge University Press, 1999
1999
-
[42]
Unsupervised cross-lingual representation learning for speech recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Unsupervised cross-lingual representation learning for speech recognition,” inProc. INTERSPEECH, 2021, pp. 2426–2430
2021
-
[43]
XLS-R: Self-supervised cross-lingual speech rep- resentation learning at scale,
A. Babuet al., “XLS-R: Self-supervised cross-lingual speech rep- resentation learning at scale,” inProc. INTERSPEECH, 2022, pp. 2278–2282
2022
-
[44]
Towards robust speech representation learning for thousands of languages,
W. Chenet al., “Towards robust speech representation learning for thousands of languages,” inProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024, pp. 10 205–10 224
2024
-
[45]
Omnilingual ASR: Open-source multilin- gual speech recognition for 1600+ languages,
G. Kerenet al., “Omnilingual ASR: Open-source multilin- gual speech recognition for 1600+ languages,”arXiv preprint arXiv:2511.09690, 2025
arXiv 2025
-
[46]
Layer-wise analysis of a self-supervised speech representation model,
A. Pasad, J.-C. Chou, and K. Livescu, “Layer-wise analysis of a self-supervised speech representation model,” in2021 IEEE Auto- matic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 914–921
2021
-
[47]
Comparative layer-wise analy- sis of self-supervised speech models,
A. Pasad, B. Shi, and K. Livescu, “Comparative layer-wise analy- sis of self-supervised speech models,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2023, pp. 1–5
2023
-
[48]
SELM: Speech enhancement using discrete to- kens and language models,
Z. Wanget al., “SELM: Speech enhancement using discrete to- kens and language models,” inProceedings of the IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 11 561–11 565
2024
-
[49]
Differentiable K-means for fully-optimized discrete token-based asr,
K. Onda, Y . Kashiwagi, E. Tsunoo, H. Futami, and S. Watanabe, “Differentiable K-means for fully-optimized discrete token-based asr,” inProc. INTERSPEECH, 2025, pp. 1223–1227
2025
-
[50]
Geometric constraints on human speech sound inventories,
E. Dunbar and E. Dupoux, “Geometric constraints on human speech sound inventories,”Frontiers in Psychology, vol. 7, p. 1061, 2016
2016
-
[51]
FLEURS: Few-shot learning evaluation of universal representations of speech,
A. Conneauet al., “FLEURS: Few-shot learning evaluation of universal representations of speech,” inProceedings of the IEEE Spoken Language Technology Workshop (SLT), 2022, pp. 798– 805
2022
-
[52]
Common V oice: A massively-multilingual speech corpus,
R. Ardilaet al., “Common V oice: A massively-multilingual speech corpus,” inProceedings of the Language Resources and Evaluation Conference (LREC), 2020, pp. 4218–4222
2020
-
[53]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inProceedings of the International Conference on Learning Representations, 2019
2019
-
[54]
data2vec: A general framework for self-supervised learning in speech, vision and language,
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “data2vec: A general framework for self-supervised learning in speech, vision and language,” inProceedings of the International Conference on Machine Learning, vol. 162, 2022, pp. 1298–1312
2022
-
[55]
The LJ Speech Dataset,
K. Ito and L. Johnson, “The LJ Speech Dataset,” https://keithito. com/LJ-Speech-Dataset/, 2017
2017
-
[56]
T. M ¨uller and D. Kreutz, “Thorsten-V oice Dataset 2022.10,” Nov. 2022. [Online]. Available: https://doi.org/10.5281/zenodo. 7265581
-
[57]
AISHELL-3: A multi- speaker Mandarin TTS corpus and the baselines,
Y . Shi, H. Bu, X. Xu, S. Zhang, and M. Li, “AISHELL-3: A multi- speaker Mandarin TTS corpus and the baselines,”arXiv preprint arXiv:2010.11567, 2020
arXiv 2010
-
[58]
A step-by-step process for building TTS voices using open source data and framework for Bangla, Ja- vanese, Khmer, Nepali, Sinhala, and Sundanese,
K. Sodimanaet al., “A step-by-step process for building TTS voices using open source data and framework for Bangla, Ja- vanese, Khmer, Nepali, Sinhala, and Sundanese,” inProceedings of the International Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU), 2018, pp. 66–70
2018
-
[59]
High-quality sinhalese multi-speaker TTS corpus,
Google, Inc., “High-quality sinhalese multi-speaker TTS corpus,” https://www.openslr.org/30/, 2016
2016
-
[60]
Rapid development of TTS corpora for four South African languages,
D. van Niekerket al., “Rapid development of TTS corpora for four South African languages,” inProc. INTERSPEECH, 2017, pp. 2178–2182
2017
-
[61]
The V oiceMOS Challenge 2024: Beyond speech quality prediction,
W.-C. Huanget al., “The V oiceMOS Challenge 2024: Beyond speech quality prediction,” inProceedings of the IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 803–810
2024
-
[62]
The T05 system for the V oiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,
K. Baba, W. Nakata, Y . Saito, and H. Saruwatari, “The T05 system for the V oiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,” inProceedings of the IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 818–824. Appendix (a) Instructions provided to the participants. (b)...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.