Skill-Augmented AI Agents for Medical Research Analysis: An Exploratory Multi-Model Human Evaluation in an NSCLC Transcriptomic Biomarker Task
Pith reviewed 2026-06-27 09:53 UTC · model grok-4.3
The pith
Skill-augmented AI agents produce directionally higher expert-rated quality than native AI in a transcriptomic biomarker task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
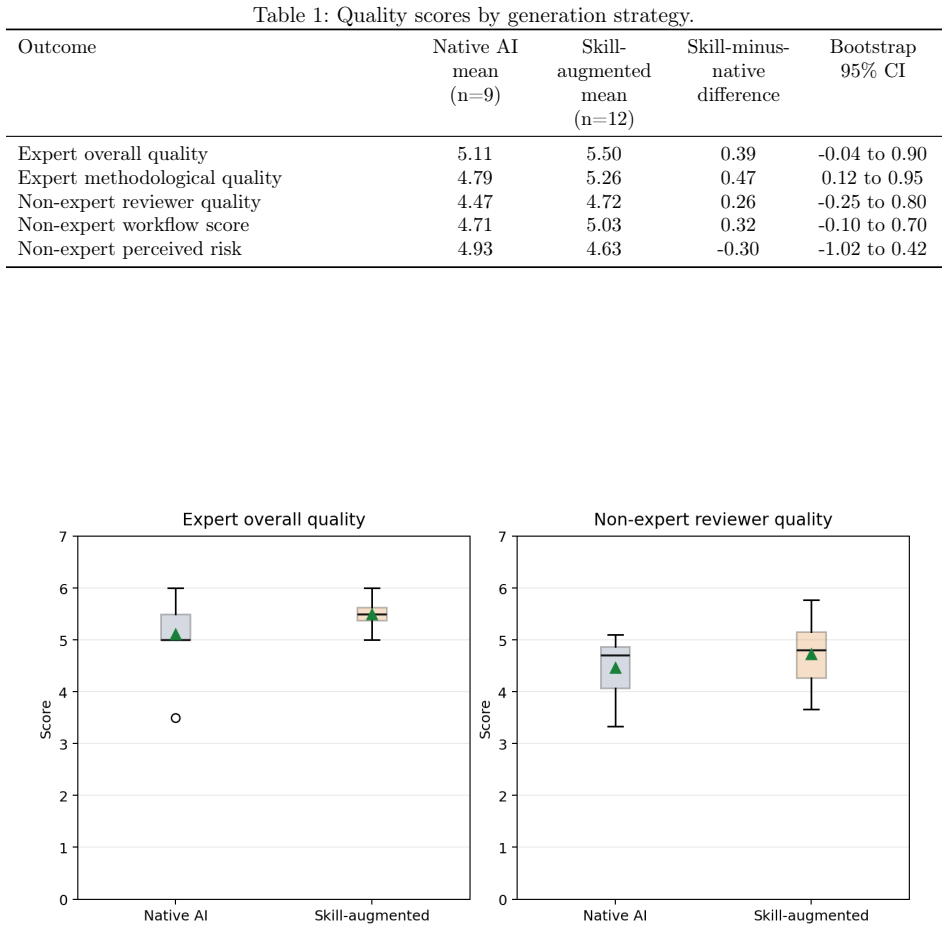
In this exploratory multi-model human evaluation, autonomous access to a medical research skill package was associated with higher mean expert overall quality ratings for skill-augmented outputs (5.50) compared with native-AI outputs (5.11), with a parallel directional effect in non-expert ratings; the differences did not reach statistical significance, expert single-rating agreement was low, and model-specific effects were heterogeneous.
What carries the argument
Autonomous access to a medical research skill package that supplies structured guidance on analytical steps, implemented through an AI agent to generate the outputs.
If this is right
- The directional quality signal holds across both expert and non-expert reviewer groups.
- Skill augmentation can be applied across multiple underlying model backbones.
- Future work must address low expert agreement and add biological-validity checks.
- The current sample size and rating noise prevent treating the result as confirmatory.
- Model-specific effects vary, indicating that benefits may not be uniform across all AI systems.
Where Pith is reading between the lines
- If human ratings track perceived polish more than factual accuracy, skill augmentation may improve presentation without fixing underlying analytical errors.
- The same skill-access approach could be tested in other data-heavy biomedical domains such as proteomics or clinical trial design.
- A sample several times larger would be needed to detect a 0.39-point difference with adequate power given the observed rating variability.
- Combining the agent outputs with automated validation against public databases could provide an objective check independent of human ratings.
Load-bearing premise
Human expert and non-expert ratings of output quality are a reliable and representative measure of the actual analytical soundness of the AI-generated transcriptomic research outputs.
What would settle it
A larger study that measures the same outputs against independent biological ground truth, such as known correct biomarker associations from the literature, and finds no quality advantage or a reversal for skill-augmented versions.
Figures


read the original abstract
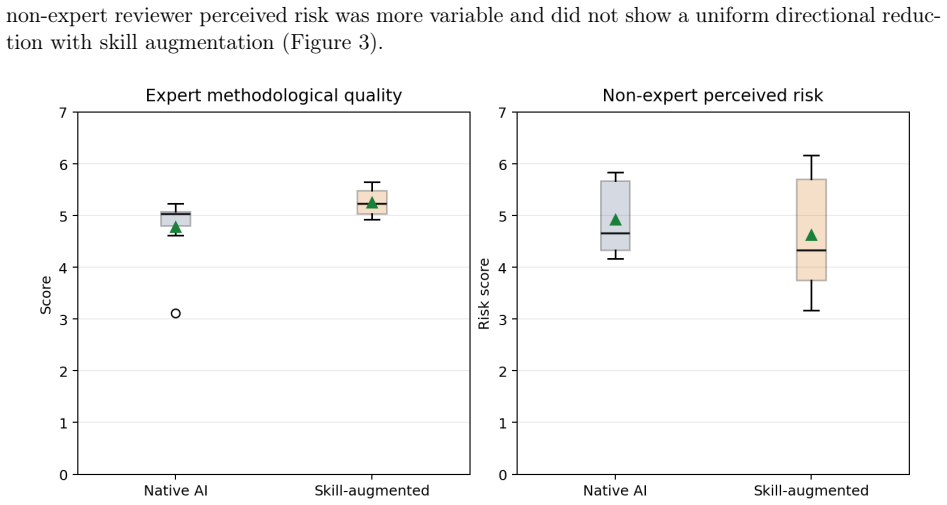
Background. Large language models and AI agents are increasingly used to support biomedical research, but native model outputs may omit key analytical steps, misuse methods, or overstate conclusions. We evaluated whether autonomous access to a medical research skill package was associated with higher-quality AI-generated transcriptomic research-analysis outputs compared with native AI without skills. Methods. We conducted an exploratory multi-model human evaluation using a non-small cell lung cancer immunotherapy biomarker task. Six model backbones were tested. The evaluation included 21 anonymized outputs: 9 native-AI outputs and 12 skill-augmented outputs generated through an AI agent implementation represented by OpenClaw. Four non-expert biomedical reviewers and two blinded experts evaluated each output, with two ratings from each reviewer type. The primary outcome was expert-rated overall quality. Results. Skill-augmented outputs showed directionally higher expert overall quality than native-AI outputs (mean 5.50 vs 5.11; difference=0.39; bootstrap 95\% CI, -0.04 to 0.90; Welch p=0.156). Non-expert reviewer quality showed the same direction (mean 4.72 vs 4.47; difference=0.26; bootstrap 95\% CI, -0.25 to 0.80; Welch p=0.373). Expert agreement was limited (single-rating ICC=-0.15), and model-specific effects were descriptive and heterogeneous. Conclusions. Autonomous skill access showed a directional quality signal in this exploratory sample, but the signal was smaller than expert-rating noise and should not be interpreted as confirmatory evidence. The findings primarily motivate larger evaluations of skill-augmented AI agents with stronger reliability controls, platform replication, and biological-validity assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an exploratory multi-model human evaluation comparing skill-augmented AI agents (OpenClaw implementation) to native AI models on a transcriptomic biomarker analysis task for NSCLC immunotherapy. Across six model backbones and 21 anonymized outputs evaluated by four non-expert and two expert reviewers, it finds a directional but non-significant difference favoring skill-augmented outputs on expert overall quality (means 5.50 vs 5.11; difference 0.39; bootstrap 95% CI -0.04 to 0.90; Welch p=0.156), a similar non-significant direction for non-expert ratings, limited expert agreement (single-rating ICC=-0.15), and heterogeneous model-specific effects. The paper concludes that the directional signal motivates larger evaluations with improved reliability controls rather than constituting confirmatory evidence.
Significance. If the directional quality signal were replicated in larger studies with reliable expert ratings and biological validity checks, the work would provide initial empirical support for the benefit of autonomous skill packages in AI agents for biomedical research tasks. In its current form, however, the exploratory design, small sample, non-significant tests, and measurement issues limit the contribution to motivating future research rather than establishing efficacy of skill augmentation.
major comments (2)
- [Results] Results (expert overall quality comparison): The primary outcome is expert-rated overall quality, yet the reported single-rating ICC of -0.15 between the two blinded experts indicates agreement worse than chance. This directly undermines attribution of the observed 0.39-point difference to differences in analytical soundness of the transcriptomic outputs, as the signal is smaller than rater noise; the bootstrap CI and p-value are computed on an unreliable measure.
- [Methods] Methods (rater design): With only two experts and negative ICC, the evaluation lacks a reliable primary outcome measure. The manuscript should address whether additional expert raters, consensus procedures, or alternative validity anchors (e.g., biological accuracy checks) are feasible within the exploratory scope, as this measurement problem is more fundamental than sample size or the non-significant p-value.
minor comments (1)
- [Abstract] Abstract and Conclusions: The cautious framing ('should not be interpreted as confirmatory evidence') is appropriate but could be strengthened by explicitly linking the ICC value to the size of the observed difference in the abstract.
Simulated Author's Rebuttal
We thank the referee for highlighting the critical issue of inter-rater reliability in our exploratory evaluation. We agree that the negative ICC represents a fundamental measurement limitation that prevents strong attribution of the directional signal to skill augmentation. The manuscript is already framed as non-confirmatory and primarily motivational for future work; we will revise to address the comments explicitly while preserving the exploratory scope.
read point-by-point responses
-
Referee: [Results] Results (expert overall quality comparison): The primary outcome is expert-rated overall quality, yet the reported single-rating ICC of -0.15 between the two blinded experts indicates agreement worse than chance. This directly undermines attribution of the observed 0.39-point difference to differences in analytical soundness of the transcriptomic outputs, as the signal is smaller than rater noise; the bootstrap CI and p-value are computed on an unreliable measure.
Authors: We agree that an ICC of -0.15 indicates agreement worse than chance and that this measurement unreliability is a core limitation. The observed 0.39-point difference is indeed smaller than the rater noise, which is why the manuscript already states that the findings 'should not be interpreted as confirmatory evidence' and that the signal 'was smaller than expert-rating noise.' We will revise the Results and Discussion sections to more explicitly note that the directional difference cannot be reliably attributed to skill augmentation given the ICC, and we will strengthen the language that the bootstrap CI and p-value are computed on an unreliable measure. This revision will be made without altering the reported statistics or the exploratory conclusion. revision: yes
-
Referee: [Methods] Methods (rater design): With only two experts and negative ICC, the evaluation lacks a reliable primary outcome measure. The manuscript should address whether additional expert raters, consensus procedures, or alternative validity anchors (e.g., biological accuracy checks) are feasible within the exploratory scope, as this measurement problem is more fundamental than sample size or the non-significant p-value.
Authors: We acknowledge that two experts yield insufficient reliability for a primary outcome and that this issue is more fundamental than sample size. Within the resource constraints of this exploratory study, additional expert raters or real-time consensus procedures were not feasible during data collection. We will revise the Methods and Discussion to explicitly address feasibility by (1) stating the practical limits of the current design, (2) outlining that future studies could incorporate consensus rating or more raters, and (3) proposing biological validity anchors such as cross-checking outputs against established NSCLC biomarker literature. These additions will clarify the exploratory scope without claiming the current data overcome the reliability problem. revision: partial
Circularity Check
No circularity: purely empirical human-evaluation study
full rationale
The paper reports an exploratory multi-model human evaluation of AI-generated transcriptomic outputs. Primary outcomes are direct mean comparisons of expert and non-expert quality ratings (5.50 vs 5.11; 4.72 vs 4.47) with bootstrap CIs, Welch p-values, and single-rating ICC. No equations, fitted parameters, predictive models, or derivation chains appear in the abstract or described methods. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The central claim is a directional empirical signal whose validity rests on the rating data themselves rather than any reduction to prior inputs. This matches the default non-circular case for an observational evaluation study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human expert and non-expert ratings provide a valid and generalizable measure of AI output quality in biomedical research analysis
Reference graph
Works this paper leans on
-
[1]
Singhal, K., Azizi, S., Tu, T., et al. (2023). Large language models encode clinical knowledge. Nature, 620, 172-180. https://www.nature.com/articles/s41586-023-06291-2
2023
-
[2]
Moor, M., Banerjee, O., Abad, Z. S. H., et al. (2023). Foundation models for generalist medical artificial intelligence.Nature, 616, 259-265. https://www.nature.com/articles/ s41586-023-05881-4
2023
-
[3]
Li, M., Song, F., Yu, B., et al. (2023). API-Bank: A comprehensive benchmark for tool- augmented LLMs.arXiv. https://arxiv.org/abs/2304.08244
Pith/arXiv arXiv 2023
-
[4]
G., Zhang, T., Wang, X., & Gonzalez, J
Patil, S. G., Zhang, T., Wang, X., & Gonzalez, J. E. (2023). Gorilla: Large language model connected with massive APIs.arXiv. https://arxiv.org/abs/2305.15334
Pith/arXiv arXiv 2023
-
[5]
Qin, Y., Liang, S., Ye, Y., et al. (2023). ToolLLM: Facilitating large language models to master 16000+ real-world APIs.arXiv. https://arxiv.org/abs/2307.16789
Pith/arXiv arXiv 2023
-
[6]
Shen, Y., Song, K., Tan, X., et al. (2023). TaskBench: Benchmarking large language models for task automation.arXiv. https://arxiv.org/abs/2311.18760
arXiv 2023
-
[7]
https: //arxiv.org/abs/2603.02176
Li,H.,Mu,C.,Chen,J.,Ren,S.,Cui,Z.,Zhang,Y.,Bai,L.,Hu,S.,etal.(2026).AgentSkillOS: Organizing, orchestrating, and benchmarking agent skills at ecosystem scale.arXiv. https: //arxiv.org/abs/2603.02176
arXiv 2026
-
[8]
Zheng, Y., Zhang, Z., Ma, C., Yu, Y., Zhu, J., Dong, B., & Zhu, H. (2026). SkillRouter: Skill routing for LLM agents at scale.arXiv. https://arxiv.org/abs/2603.22455
arXiv 2026
-
[9]
Li, D., Li, Z., Du, H., Wu, X., Gui, S., Kuang, Y., & Sun, L. (2026). Graph of Skills: Dependency-aware structural retrieval for massive agent skills.arXiv. https://arxiv.org/abs/ 2604.05333
Pith/arXiv arXiv 2026
-
[10]
Wang, J., Ming, Y., Ke, Z., Joty, S., Albarghouthi, A., & Sala, F. (2026). SkillOrchestra: Learning to route agents via skill transfer.arXiv. https://arxiv.org/abs/2602.19672
arXiv 2026
-
[11]
Li, X., Chen, W., Liu, Y., Zheng, S., Chen, X., He, Y., Li, Y., You, B., Shen, H., Sun, J., Wang, S., Zeng, Q., Wang, D., Zhao, X., Wang, Y., Ben Chaim, R., Di, Z., Gao, Y., He, J., et al. (2026). SkillsBench: Benchmarking how well agent skills work across diverse tasks.arXiv. https://arxiv.org/abs/2602.12670
Pith/arXiv arXiv 2026
-
[12]
Li, F., Tagkopoulos, P., & Tagkopoulos, I. (2025). SkillFlow: Scalable and efficient agent skill retrieval system.arXiv. https://arxiv.org/abs/2504.06188 13 A Supplementary Reproducibility Information This supplement provides reproducibility details that are not fully expanded in the main text, including the exact task prompt, output inclusion rules, eval...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.