Recognition: no theorem link
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Pith reviewed 2026-05-10 20:12 UTC · model grok-4.3
The pith
Graph of Skills retrieves only dependency-linked skills for agents, raising rewards 43.6% while cutting tokens 37.8%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
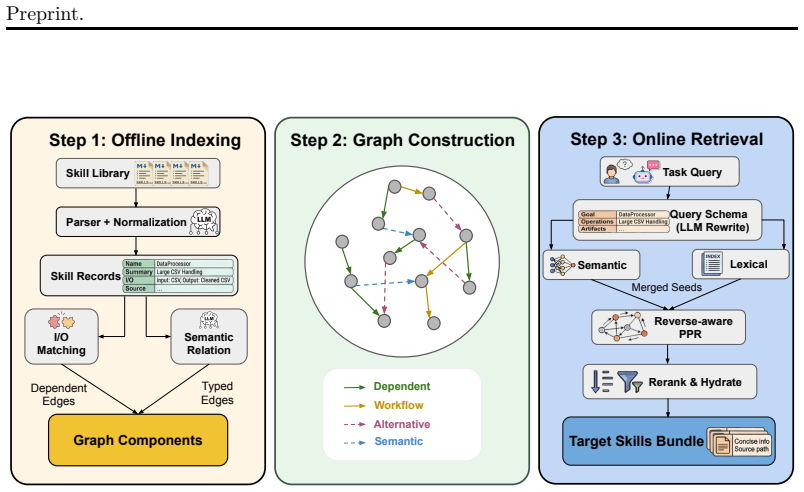
GoS constructs an executable skill graph offline from skill packages, then at inference time retrieves a bounded, dependency-aware skill bundle through hybrid semantic-lexical seeding, reverse-weighted Personalized PageRank, and context-budgeted hydration. On SkillsBench and ALFWorld this yields 43.6% higher average reward and 37.8% fewer input tokens than the vanilla full skill-loading baseline, with the gains holding across Claude Sonnet, GPT-5.2 Codex, and MiniMax.
What carries the argument
The executable skill graph encoding dependencies between skills, which reverse-weighted Personalized PageRank uses to spread relevance from seed matches to connected skills while staying inside a context budget.
Load-bearing premise
The offline skill graph captures every relevant dependency and the hybrid retrieval will not omit any skill actually required to finish the task.
What would settle it
A task that succeeds when all skills are loaded but fails under GoS because a needed skill is either absent from the graph or not selected by the seeding and PageRank steps.
Figures

read the original abstract
Skill usage has become a core component of modern agent systems and can substantially improve agents' ability to complete complex tasks. In real-world settings, where agents must monitor and interact with numerous personal applications, web browsers, and other environment interfaces, skill libraries can scale to thousands of reusable skills. Scaling to larger skill sets introduces two key challenges. First, loading the full skill set saturates the context window, driving up token costs, hallucination, and latency. In this paper, we present Graph of Skills (GoS), an inference-time structural retrieval layer for large skill libraries. GoS constructs an executable skill graph offline from skill packages, then at inference time retrieves a bounded, dependency-aware skill bundle through hybrid semantic-lexical seeding, reverse-weighted Personalized PageRank, and context-budgeted hydration. On SkillsBench and ALFWorld, GoS improves average reward by 43.6% over the vanilla full skill-loading baseline while reducing input tokens by 37.8%, and generalizes across three model families: Claude Sonnet, GPT-5.2 Codex, and MiniMax. Additional ablation studies across skill libraries ranging from 200 to 2,000 skills further demonstrate that GoS consistently outperforms both vanilla skills loading and simple vector retrieval in balancing reward, token efficiency, and runtime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Graph of Skills (GoS), an inference-time structural retrieval layer for large agent skill libraries. It constructs an executable skill graph offline from skill packages and retrieves bounded, dependency-aware bundles at inference via hybrid semantic-lexical seeding, reverse-weighted Personalized PageRank, and context-budgeted hydration. On SkillsBench and ALFWorld, GoS is reported to improve average reward by 43.6% over the full skill-loading baseline while cutting input tokens by 37.8%, with generalization across Claude Sonnet, GPT-5.2 Codex, and MiniMax; ablations on libraries of 200–2000 skills are also presented.
Significance. If the empirical results prove robust, GoS offers a concrete mechanism for scaling skill libraries beyond context-window limits without sacrificing task performance. The explicit incorporation of dependency structure via the offline graph and reverse-weighted PPR distinguishes it from pure vector retrieval and could support more reliable agent behavior in domains with thousands of reusable skills. The cross-model generalization is a modest but useful strength.
major comments (3)
- [§4.1 and Table 1] §4.1 and Table 1: The headline 43.6% reward gain and 37.8% token reduction are stated without error bars, number of evaluation episodes, statistical significance tests, or details on how tasks were sampled and skills were selected for the library; these omissions make it impossible to determine whether the gains are reliable or confounded by benchmark-specific artifacts.
- [§3.1] §3.1: The offline graph is described as being built 'from skill packages,' yet the text provides no procedure for discovering or encoding implicit, state-dependent, or context-sensitive dependencies; if such edges are absent, the reverse-weighted PPR step can return incomplete bundles even when seeding succeeds, directly threatening the central claim that the structural layer reliably surfaces every needed skill.
- [§4.3] §4.3: The library-size ablations (200–2000 skills) compare GoS only against vanilla loading and simple vector retrieval; they do not include a stress test that injects tasks requiring implicit dependencies absent from the static graph, leaving the robustness of the hybrid retrieval unexamined on the failure mode highlighted by the weakest assumption.
minor comments (2)
- [§3.2] The notation for 'reverse-weighted Personalized PageRank' is introduced in §3.2 without an equation or reference to the standard PPR formulation; a short formal definition would improve reproducibility.
- [Figure 2] Figure 2 (skill-graph visualization) lacks a legend clarifying edge weights and node colors; this reduces clarity when readers attempt to verify the dependency structure.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below, agreeing where revisions are needed to improve clarity and rigor, and providing explanations where our approach aligns with the paper's scope.
read point-by-point responses
-
Referee: [§4.1 and Table 1] §4.1 and Table 1: The headline 43.6% reward gain and 37.8% token reduction are stated without error bars, number of evaluation episodes, statistical significance tests, or details on how tasks were sampled and skills were selected for the library; these omissions make it impossible to determine whether the gains are reliable or confounded by benchmark-specific artifacts.
Authors: We agree that these statistical and methodological details are essential for evaluating result reliability. In the revised manuscript, we will add error bars (standard deviations across runs), specify the number of evaluation episodes, report results from statistical significance tests, and provide full details on task sampling from SkillsBench and ALFWorld along with the skill library construction and selection process. These changes will directly address the concern about potential confounding factors. revision: yes
-
Referee: [§3.1] §3.1: The offline graph is described as being built 'from skill packages,' yet the text provides no procedure for discovering or encoding implicit, state-dependent, or context-sensitive dependencies; if such edges are absent, the reverse-weighted PPR step can return incomplete bundles even when seeding succeeds, directly threatening the central claim that the structural layer reliably surfaces every needed skill.
Authors: Skill packages in our framework include explicit dependency declarations that are parsed to construct the directed graph edges used by reverse-weighted PPR. The current method does not automatically discover implicit or state-dependent dependencies, which is a deliberate scope choice focused on leveraging provided structural information rather than inference. We will revise §3.1 to explicitly describe the parsing procedure for explicit dependencies and add a limitations discussion noting that missing implicit edges could result in incomplete bundles, while highlighting how hybrid seeding offers robustness in practice. revision: partial
-
Referee: [§4.3] §4.3: The library-size ablations (200–2000 skills) compare GoS only against vanilla loading and simple vector retrieval; they do not include a stress test that injects tasks requiring implicit dependencies absent from the static graph, leaving the robustness of the hybrid retrieval unexamined on the failure mode highlighted by the weakest assumption.
Authors: We will expand the ablations in §4.3 to include a targeted stress test that removes select dependency edges from the graph for certain tasks and evaluates the resulting performance of GoS versus baselines. This addition will directly examine the hybrid retrieval's behavior under incomplete graph conditions and better substantiate the claims about robustness. revision: yes
Circularity Check
No significant circularity; empirical method with benchmark measurements
full rationale
The paper describes an offline-constructed skill graph from skill packages, followed by inference-time hybrid retrieval (semantic-lexical seeding, reverse-weighted Personalized PageRank, context-budgeted hydration). The central claims are direct empirical measurements: 43.6% average reward improvement and 37.8% token reduction on SkillsBench and ALFWorld, plus generalization across three model families and ablations on library sizes 200-2000. No equations, derivations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The approach uses standard graph algorithms and retrieval methods without reducing to its own inputs by construction or importing uniqueness results from author prior work.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
SkillOps: Managing LLM Agent Skill Libraries as Self-Maintaining Software Ecosystems
SkillOps maintains LLM skill libraries via Skill Contracts and ecosystem graphs, raising ALFWorld task success to 79.5% as a standalone agent and improving retrieval baselines by up to 2.9 points with near-zero librar...
-
RS-Claw: Progressive Active Tool Exploration via Hierarchical Skill Trees for Remote Sensing Agents
RS-Claw enables remote sensing agents to actively explore tools via hierarchical skill trees, achieving up to 86% token compression and outperforming flat registration and RAG baselines on Earth-Bench.
-
SkillRAE: Agent Skill-Based Context Compilation for Retrieval-Augmented Execution
SkillRAE organizes skills into a graph and compiles compact, grounded contexts for LLM agents, yielding 11.7% gains on SkillsBench over prior RAE methods.
-
Group of Skills: Group-Structured Skill Retrieval for Agent Skill Libraries
GoSkills converts flat skill lists into role-labeled execution contexts via anchor-centered groups and graph expansion, preserving coverage and improving rewards on SkillsBench and ALFWorld under small skill budgets.
Reference graph
Works this paper leans on
-
[1]
Extract exactly one skill node from the document
-
[2]
Infer only retrieval-critical fields: capability, inputs, outputs, domain_tags, tooling, example_tasks
-
[3]
If uncertain, leave a field empty
Use high precision. If uncertain, leave a field empty
-
[4]
goal + artifact/format + operation/API + verifier-critical constraint
Do not invent relationships. Return an empty ‘edges‘ list. This excerpt illustrates the central design principle of the internal extraction prompt: GoS uses the LLM as a constrained semantic normalizer, not as an unconstrained graph author. For the appendix, the important point is not merely that an LLM appears in the pipeline, but that the allowable outp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.