VICX: Generalizable Robot Manipulation via Video Generation and In-Context Operator Network
Pith reviewed 2026-06-27 09:30 UTC · model grok-4.3
The pith
A frozen video generator and in-context network together let robots handle new tasks on new bodies without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
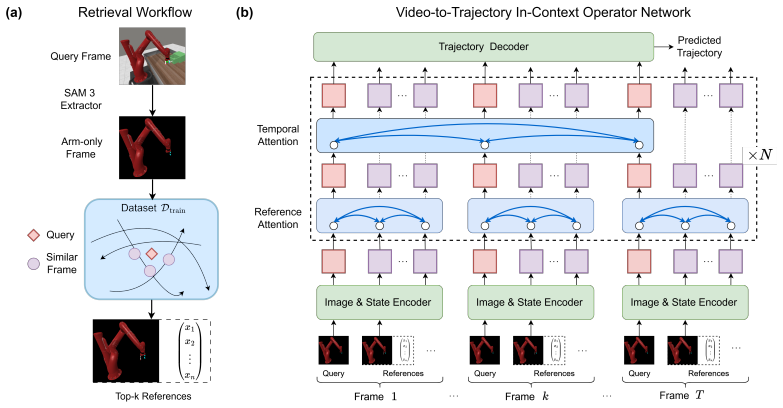
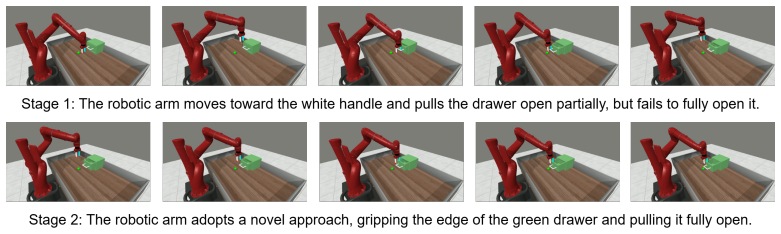
VICX uses a frozen video generation model to produce vision-language-conditioned high-level visual plans while a Video-to-Trajectory In-Context Operator Network (V2T-ICON) grounds the plans into executable trajectories. V2T-ICON works on segmentation-extracted arm-only observations and retrieved image-state pairs as in-context prompts, enabling the visual-to-state mapping at inference without updates. On Meta-World the system demonstrates cross-task generalization, closed-loop self-correction, and cross-embodiment transfer.
What carries the argument
V2T-ICON, the Video-to-Trajectory In-Context Operator Network that maps visual plans to trajectories via retrieved in-context image-state pairs on arm-segmented frames.
If this is right
- Robots can address unseen tasks by relying on video-model plans rather than task-specific policies.
- Closed-loop feedback lets the system detect and correct execution errors during a single rollout.
- The same trained network can be applied to different robot bodies by swapping only the observation and action spaces.
- No task-specific fine-tuning or parameter updates are needed once the video model and retrieval set are fixed.
Where Pith is reading between the lines
- Advances in general video generation could directly improve robot planning without any change to the execution module.
- The same decoupled structure might extend to other sequential control problems where high-level visual forecasts need grounding to low-level actuators.
- Retrieval-based in-context mapping could reduce the data requirements for new robot hardware compared with end-to-end policy learning.
Load-bearing premise
A frozen off-the-shelf video generation model will reliably output visual plans that remain accurately groundable into robot trajectories by the in-context network using only arm observations and example pairs.
What would settle it
Run the system on a held-out task and embodiment; if the generated video plans produce trajectories that fail to reach the goal or prevent self-correction, the claim is falsified.
Figures









read the original abstract
Generalizable robot manipulation requires not only task-level reasoning over unseen scenes, but also reliable grounding of visual plans into embodiment-specific execution. To bridge this gap, we propose VICX (Video generation and In-Context eXecution), a decoupled closed-loop manipulation framework. In VICX, a frozen video generation model produces vision-language-conditioned high-level visual plans, while a Video-to-Trajectory In-Context Operator Network (V2T-ICON) serves as the task-agnostic interface that grounds these plans into executable robot-state trajectories. To improve execution generalization, V2T-ICON operates on segmentation-extracted arm-only frame observations and uses retrieved image-state pairs as in-context prompts, allowing a robust and generalizable visual-to-state mapping at inference time without parameter updates. Experiments on Meta-World show that VICX supports cross-task generalization, closed-loop self-correction, and cross-embodiment transfer, demonstrating dual generalization across both task semantics and robot execution. The project webpage can be found here: https://scaling-group.github.io/vicx/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VICX, a decoupled closed-loop robot manipulation framework. A frozen off-the-shelf video generation model produces high-level visual plans conditioned on vision-language inputs. These plans are grounded into executable robot trajectories by V2T-ICON (Video-to-Trajectory In-Context Operator Network), which operates on segmentation-extracted arm-only observations and uses retrieved image-state pairs as in-context prompts for a task-agnostic visual-to-state mapping at inference time without any parameter updates or fine-tuning. Experiments on Meta-World are reported to demonstrate cross-task generalization, closed-loop self-correction, and cross-embodiment transfer, supporting dual generalization over task semantics and robot execution.
Significance. If the experimental claims hold under rigorous validation, the decoupled architecture could meaningfully advance generalizable manipulation by avoiding task-specific fine-tuning of either the video model or the grounding network, instead relying on in-context retrieval and segmentation. This would be a notable contribution to the field if accompanied by reproducible code, clear baselines, and failure-case analysis.
major comments (2)
- [Abstract, §Experiments] Abstract and §Experiments: No quantitative results, baselines, error bars, or failure cases are described. The central claims of cross-task generalization, closed-loop self-correction, and cross-embodiment transfer cannot be assessed without these details, leaving the soundness of the dual-generalization result unverified.
- [Abstract] Abstract: The weakest assumption—that a frozen video model will reliably produce visual plans that V2T-ICON can ground using only arm-segmented observations and retrieved pairs—is stated but not accompanied by any ablation or sensitivity analysis in the visible text, making it impossible to evaluate whether this holds load-bearing for the reported results.
minor comments (1)
- [Abstract] The project webpage URL is provided but no supplementary material or code link is mentioned in the abstract.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major comment below, acknowledging where the current manuscript presentation requires strengthening and outlining the revisions we will make.
read point-by-point responses
-
Referee: [Abstract, §Experiments] Abstract and §Experiments: No quantitative results, baselines, error bars, or failure cases are described. The central claims of cross-task generalization, closed-loop self-correction, and cross-embodiment transfer cannot be assessed without these details, leaving the soundness of the dual-generalization result unverified.
Authors: We agree that the abstract summarizes the experimental outcomes at a high level without numerical details, and that the visible text does not present quantitative success rates, explicit baselines, error bars, or a dedicated failure-case breakdown. This limits independent assessment of the claims. In the revised manuscript we will expand the abstract to report key quantitative metrics (e.g., success rates on held-out Meta-World tasks) and will add a table in §Experiments that includes baseline comparisons, error bars across random seeds, and a failure-mode analysis covering cases of invalid video plans and grounding errors. These additions will directly support evaluation of cross-task generalization, closed-loop correction, and cross-embodiment transfer. revision: yes
-
Referee: [Abstract] Abstract: The weakest assumption—that a frozen video model will reliably produce visual plans that V2T-ICON can ground using only arm-segmented observations and retrieved pairs—is stated but not accompanied by any ablation or sensitivity analysis in the visible text, making it impossible to evaluate whether this holds load-bearing for the reported results.
Authors: We concur that the abstract presents the core assumption without accompanying ablation or sensitivity results, which makes it difficult to judge its robustness. Although the full experiments section demonstrates successful grounding under the stated conditions, an explicit sensitivity study is absent from the current text. We will add a new subsection in the revised manuscript that ablates video-plan quality, retrieval-set size, and segmentation accuracy, reporting their effects on downstream trajectory success. This will clarify whether the assumption is load-bearing. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description describe a decoupled architecture using a frozen off-the-shelf video model for visual plans and V2T-ICON for grounding via in-context retrieval on segmented observations, with no parameter updates. No equations, fitted parameters, predictions, or self-citations are present in the provided text that would reduce any claim to its inputs by construction. The central claims of cross-task generalization and closed-loop execution rest on the external video model and retrieval mechanism, which are independent of the reported results. This is the most common honest finding for papers without internal derivation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frozen video generation model produces reliable vision-language-conditioned high-level visual plans
- domain assumption Segmentation-extracted arm-only observations plus retrieved image-state pairs enable robust visual-to-state mapping without updates
invented entities (1)
-
V2T-ICON (Video-to-Trajectory In-Context Operator Network)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learni...
2025
-
[3]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
-
[4]
URLhttps://proceedings.mlr.press/v305/black25a
PMLR, 27–30 Sep 2025. URLhttps://proceedings.mlr.press/v305/black25a. html
2025
-
[5]
Y . Ma, Z. Song, Y . Zhuang, J. Hao, and I. King. A survey on vision–language–action models for embodied AI.IEEE Transactions on Neural Networks and Learning Systems, pages 1–21,
-
[6]
doi:10.1109/TNNLS.2025.3650584
-
[7]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open X-Embodiment: Robotic learning datasets and RT-X mod- els. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892– 6903, 2024
2024
-
[8]
S. Wang, J. Shi, Z. Fu, X. He, F. Liu, C. Yang, Y . Zhou, Z. Fei, J. Gong, J. Fu, et al. World action models: The next frontier in embodied AI.arXiv preprint arXiv:2605.12090, 2026
Pith/arXiv arXiv 2026
-
[9]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, A. N. Malik, K. Lee, W. Liang, N. R. Arachchige, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, D. Xu, Y . Du, R. Julian, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. Fan, and J. Jang. World actio...
2026
-
[10]
L. Yang, S. Liu, T. Meng, and S. J. Osher. In-context operator learning with data prompts for differential equation problems.Proceedings of the National Academy of Sciences, 120(39): e2310142120, 2023. 9
2023
-
[11]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[12]
P.-C. Ko, J. Mao, Y . Du, S.-H. Sun, and J. B. Tenenbaum. Learning to act from actionless videos through dense correspondences. InInternational Conference on Learning Representa- tions, volume 2024, pages 40938–40958, 2024
2024
-
[13]
Y . Tian, J. Zhang, G. Huang, B. Wang, P. Wang, J. Pang, and H. Dong. Robokeygen: robot pose and joint angles estimation via diffusion-based 3D keypoint generation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5375–5381. IEEE, 2024
2024
-
[14]
Labb´e, J
Y . Labb´e, J. Carpentier, M. Aubry, and J. Sivic. Single-view robot pose and joint angle estima- tion via render & compare. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1654–1663, 2021
2021
-
[15]
T. E. Lee, J. Tremblay, T. To, J. Cheng, T. Mosier, O. Kroemer, D. Fox, and S. Birchfield. Camera-to-Robot pose estimation from a single image. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 9426–9432. IEEE, 2020
2020
-
[16]
Ausserlechner, D
P. Ausserlechner, D. Haberger, S. Thalhammer, J.-B. Weibel, and M. Vincze. ZS6D: Zero-shot 6D object pose estimation using vision transformers. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 463–469. IEEE, 2024
2024
-
[17]
T. G. Jantos, M. A. Hamdad, W. Granig, S. Weiss, and J. Steinbrener. PoET: Pose estima- tion transformer for single-view, multi-object 6D pose estimation. InConference on Robot Learning, pages 1060–1070. PMLR, 2023
2023
-
[18]
M. Douze, A. Guzhva, C. Deng, J. Johnson, G. Szilvasy, P.-E. Mazar´e, M. Lomeli, L. Hosseini, and H. J´egou. The Faiss library.IEEE Transactions on Big Data, 2026. doi:10.1109/TBDATA. 2025.3618474
-
[19]
McLean, E
R. McLean, E. Chatzaroulas, L. McCutcheon, F. R ¨oder, T. Yu, Z. He, K. Zentner, R. Julian, J. K. Terry, I. Woungang, N. Farsad, and P. S. Castro. Meta-World+: An improved, stan- dardized, RL benchmark. InThe Thirty-ninth Annual Conference on Neural Information Pro- cessing Systems Datasets and Benchmarks Track, 2025. URLhttps://openreview.net/ forum?id=1...
2025
-
[20]
T. Wiedemer, Y . Li, P. Vicol, S. S. Gu, N. Matarese, K. Swersky, B. Kim, P. Jaini, and R. Geirhos. Video models are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328, 2025
Pith/arXiv arXiv 2025
-
[21]
Khachatryan, A
L. Khachatryan, A. Movsisyan, V . Tadevosyan, R. Henschel, Z. Wang, S. Navasardyan, and H. Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15954– 15964, 2023
2023
-
[22]
Team Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[23]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. In2017 IEEE inter- national conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
2017
-
[24]
F. Ebert, C. Finn, S. Dasari, A. Xie, A. Lee, and S. Levine. Visual foresight: Model-based deep reinforcement learning for vision-based robotic control.arXiv preprint arXiv:1812.00568, 2018. 10
Pith/arXiv arXiv 2018
-
[25]
Y . Du, S. Yang, P. Florence, F. Xia, A. Wahid, P. Sermanet, T. Yu, P. Abbeel, J. B. Tenen- baum, L. Kaelbling, et al. Video language planning. InInternational Conference on Learning Representations, volume 2024, pages 31138–31155, 2024
2024
-
[26]
B. Wang, N. Sridhar, C. Feng, M. Van der Merwe, A. Fishman, N. Fazeli, and J. J. Park. This&That: Language-gesture controlled video generation for robot planning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 12842–12849. IEEE, 2025
2025
-
[27]
Liang, R
J. Liang, R. Liu, E. Ozguroglu, S. Sudhakar, A. Dave, P. Tokmakov, S. Song, and C. V ondrick. Dreamitate: Real-world visuomotor policy learning via video generation. InProceedings of The 8th Conference on Robot Learning, volume 270, pages 3943–3960, 06–09 Nov 2025
2025
-
[28]
B. Chen, T. Zhang, H. Geng, C. Zhang, P. Li, K. Song, W. T. Freeman, J. Malik, P. Abbeel, R. Tedrake, et al. Large video planner enables generalizable robot control.arXiv preprint arXiv:2512.15840, 2025
Pith/arXiv arXiv 2025
-
[29]
Mirchandani, F
S. Mirchandani, F. Xia, P. Florence, B. Ichter, D. Driess, M. G. Arenas, K. Rao, D. Sadigh, and A. Zeng. Large language models as general pattern machines. In7th Annual Conference on Robot Learning, 2023. URLhttps://openreview.net/forum?id=RcZMI8MSyE
2023
-
[30]
N. D. Palo and E. Johns. Keypoint Action Tokens Enable In-Context Imitation Learning in Robotics. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024. doi:10.15607/RSS.2024.XX.096
-
[31]
V osylius and E
V . V osylius and E. Johns. Instant policy: In-Context imitation learning via graph diffusion. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps: //openreview.net/forum?id=je3GZissZc
2025
-
[32]
K. Chen, C. Li, C. Tu, J. Pan, Y . Ma, W. Chen, Z. Zhou, X. Xu, S. James, C.-W. Fu, et al. A retrieval-augmented framework enabling VLM spatial awareness for object-centric robot manipulation.Science Robotics, 11(113):eaea2092, 2026
2026
-
[33]
Radosavovic, T
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath. Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
2024
-
[34]
Eschmann, D
J. Eschmann, D. Albani, and G. Loianno. Raptor: A foundation policy for quadrotor control. Science Robotics, 11(114):eaec1481, 2026
2026
-
[35]
M. Liu, D. Pathak, and A. Agarwal. LocoFormer: Generalist locomotion via long-context adaptation. In9th Annual Conference on Robot Learning, 2025. URLhttps://openreview. net/forum?id=VqmAvBkFhw
2025
-
[36]
L. Fu, H. Huang, G. Datta, L. Y . Chen, W. C.-H. Panitch, F. Liu, H. Li, and K. Goldberg. In-context imitation learning via next-token prediction. InNeurIPS 2024 Workshop on Open- World Agents, 2024. URLhttps://openreview.net/forum?id=2R3q4FyPlH
2024
-
[37]
Sridhar, S
K. Sridhar, S. Dutta, D. Jayaraman, and I. Lee. RICL: Adding in-context adaptability to pre- trained vision-language-action models. In9th Annual Conference on Robot Learning, 2025. URLhttps://openreview.net/forum?id=6AASPlloSt
2025
-
[38]
Y . Yoo, J. Hu, Y . Zhu, B. Liu, Q. Liu, R. Mart ´ın-Mart´ın, and P. Stone. RoboSSM: Scalable in-context imitation learning via state-space models. InCoRL 2025 Workshop RemembeRL,
2025
-
[39]
URLhttps://openreview.net/forum?id=JG8p1yGI6U
-
[40]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. HAZIZA, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without 1...
2024
-
[41]
corrective
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024. 12 Appendix A Experimental Training Details A.1 Tasks and Training Datasets We conduct simulation experiments in Meta-World, a Sawyer-manipulation benchmark with 50 robotic control tasks [17]. The suite cover...
2024
-
[42]
Begin motion in the first frame. Keep the gripper’s initial finger spacing fixed, with no opening, closing, pulsing, or aperture change, and move immediately to a position directly above the middle of the white handle using a short, direct approach, without circling or hovering
-
[43]
The white handle must be clearly centered in the empty gap between the two fingers, and the end effector must complete the full down- ward insertion before the drawer starts moving
Descend vertically all the way to the lowest contact position before any out- ward pull begins. The white handle must be clearly centered in the empty gap between the two fingers, and the end effector must complete the full down- ward insertion before the drawer starts moving
-
[44]
The fingers may straddle the handle, but they must never open, close, overlap, merge with, or pass through the handle geometry
Establish a solid, non-penetrating hooked contact from behind the handle while preserving the same fixed finger gap. The fingers may straddle the handle, but they must never open, close, overlap, merge with, or pass through the handle geometry. The wrist, palm, and gripper body must stay outside the drawer front and must not enter the drawer cavity
-
[45]
out-of-distribution
Only after that completed downward contact is achieved, pull the drawer straight outward in a pure translational motion while preserving that clean contact geometry. The drawer must slide horizontally along its rails without any tilting, dropping, rotating, or sideways slip, then stop once it is substan- tially open and stable. Figure 7: Full Wan task pro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.