Phase Transitions in Attention: A Bayesian Theory of Copy Head Emergence
Pith reviewed 2026-06-27 08:11 UTC · model grok-4.3
The pith
Bayesian theory derives a phase transition that explains abrupt copy head emergence in attention
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
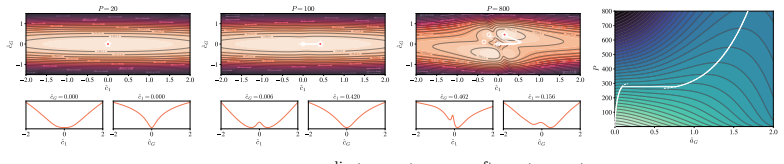
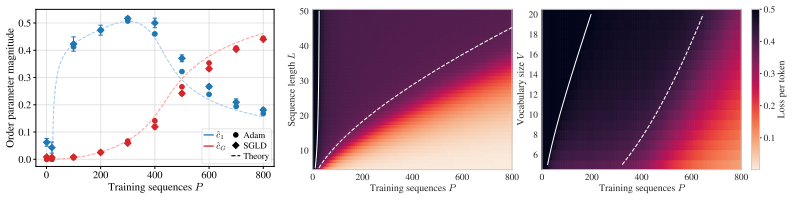
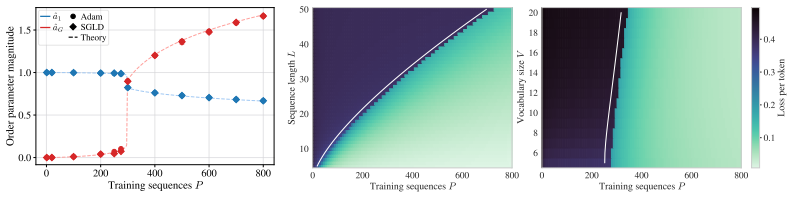
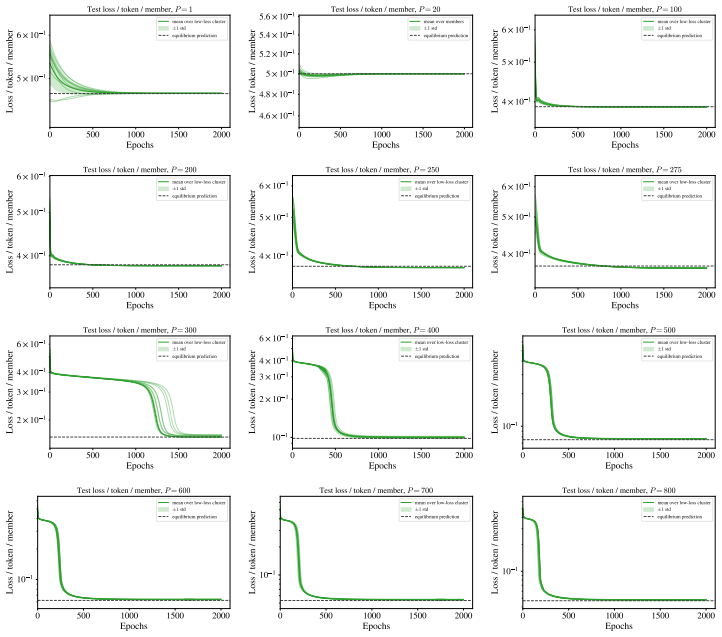
Deriving a closed-form posterior over the attention matrix and reducing it to a low-dimensional order parameter space reveals that softmax attention undergoes a first-order phase transition with respect to the amount of training data, whereas linear attention displays an initial second-order transition followed by a smooth crossover to the structured pattern.
What carries the argument
The low-dimensional order parameter space that results from reducing the closed-form posterior over the attention matrix, which governs the emergence of the copy subcircuit.
Load-bearing premise
The projection of the full attention-matrix posterior onto the low-dimensional order parameters continues to capture the dominant behavior of the copy subcircuit.
What would settle it
If experiments that vary the number of copy-task examples show the attention weights evolving continuously through the predicted critical point instead of jumping, the first-order transition claim would be refuted.
Figures



read the original abstract
Attention is the key mechanism underlying in-context learning in transformers, and attention patterns have been observed empirically to emerge abruptly during training. We present a Bayesian theory of feature learning in attention; we then focus on how the copy subcircuit in the first layer of an induction head is learned by analyzing a single-layer softmax attention network trained on a copy task. We derive a closed-form posterior over the attention matrix and reduce it to a low-dimensional order parameter space. This reduction reveals a phase transition in the amount of training data, which we verify using both Bayesian sampling and standard training with Adam. We contrast our results with linear attention and find that softmax attention exhibits a \emph{first-order phase transition} while in linear attention an initial \emph{second-order phase transition} is followed by a smooth, continuous evolution toward the structured attention pattern (\emph{crossover}). Our work provides a first-principles theoretical account of the abrupt emergence of the copy subcircuit, reminiscent of the one observed in training large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a Bayesian theory of feature learning in attention mechanisms, focusing on the emergence of the copy subcircuit in a single-layer softmax attention network trained on a copy task. It claims to derive a closed-form posterior over the attention matrix, reduce this posterior to a low-dimensional order-parameter space, and identify a phase transition in the amount of training data. The reduction is used to contrast softmax attention (first-order phase transition) with linear attention (initial second-order transition followed by a smooth crossover). These predictions are verified via Bayesian sampling and Adam optimization.
Significance. If the closed-form posterior and its faithful reduction to order parameters hold, the work would provide a rare first-principles account of abrupt attention-pattern emergence, directly linking data volume to phase-transition order and distinguishing softmax from linear attention. This could inform understanding of in-context learning and induction heads in transformers. The explicit contrast between attention variants and the use of both sampling and gradient-based verification are positive features.
major comments (2)
- [posterior-to-order-parameter reduction (immediately following closed-form posterior statement)] The reduction from the stated closed-form posterior over the attention matrix to the low-dimensional order-parameter space is invoked immediately after the posterior is announced and is load-bearing for the claimed first-order vs. second-order-plus-crossover distinction. No explicit mapping, projection, or closure assumptions are provided in the abstract, and the reader notes the absence of derivation steps, error analysis, or data-model assumptions; without these, it is impossible to confirm that the reduced description preserves the qualitative structure (including transition order) of the original posterior.
- [verification paragraph] Verification is described as 'using both Bayesian sampling and standard training with Adam' but supplies no quantitative metrics (e.g., agreement between sampled posterior modes and Adam trajectories, or error bars on the location of the reported transition). This leaves the empirical support for the phase-transition claims unquantified.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our work. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: The reduction from the stated closed-form posterior over the attention matrix to the low-dimensional order-parameter space is invoked immediately after the posterior is announced and is load-bearing for the claimed first-order vs. second-order-plus-crossover distinction. No explicit mapping, projection, or closure assumptions are provided in the abstract, and the reader notes the absence of derivation steps, error analysis, or data-model assumptions; without these, it is impossible to confirm that the reduced description preserves the qualitative structure (including transition order) of the original posterior.
Authors: We agree that the reduction steps require more explicit presentation. The closed-form posterior appears in Section 2; the subsequent reduction to order parameters (via marginalization and mean-field closure) is invoked without full intermediate steps. In revision we will insert the explicit mapping, projection, closure assumptions, and a brief error analysis immediately after the posterior statement, and we will expand the abstract to reference these elements so that the preservation of transition order can be directly verified. revision: yes
-
Referee: Verification is described as 'using both Bayesian sampling and standard training with Adam' but supplies no quantitative metrics (e.g., agreement between sampled posterior modes and Adam trajectories, or error bars on the location of the reported transition). This leaves the empirical support for the phase-transition claims unquantified.
Authors: We concur that quantitative metrics are needed to strengthen the verification. The revised manuscript will report agreement measures (e.g., mode overlap or Wasserstein distance) between the sampled posterior modes and the Adam trajectories, together with error bars on the reported transition locations obtained from multiple independent runs. These will be added to the verification paragraph and the associated figures. revision: yes
Circularity Check
No circularity; derivation is self-contained from posterior to order parameters.
full rationale
The paper states it derives a closed-form posterior over the attention matrix from the model likelihood and prior, followed by a mathematical reduction to low-dimensional order parameters that is presented as an exact consequence rather than a fit, projection, or ansatz. No equations in the provided text show the reduction being defined in terms of the target phase transition or copy pattern. Verification against both Bayesian sampling and Adam training supplies external checks. No self-citation chains, uniqueness theorems, or renamings of known results are invoked as load-bearing steps. The distinction between first-order (softmax) and second-order-plus-crossover (linear) behavior is reported as an output of the reduced description, not presupposed by it.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott...
1901
-
[2]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling Laws for Neural Language Models, January 2020. arXiv:2001.08361 [cs]
Pith/arXiv arXiv 2020
-
[3]
An empirical analysis of compute-optimal large language model training
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Thomas Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aure- lia Guy, Simon Osindero, Kar´en Simonyan, Erich Elsen, Oriol Vinyals, Jack Rae, and Lauren...
2022
-
[4]
Nicholas Lourie, Michael Y . Hu, and Kyunghyun Cho. Scaling Laws Are Unreliable for Down- stream Tasks: A Reality Check, October 2025. arXiv:2507.00885 [cs]
arXiv 2025
-
[5]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent Abilities of Large Lan- guage Models.Transactions on Machine Learning Research, June 2022
2022
-
[6]
Are emergent abilities of large language models a mirage? In A
Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage? In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 55565–55581. Curran Associates, Inc., 2023
2023
-
[7]
Emergent Abilities in Large Language Models: A Survey, March 2025
Leonardo Berti, Flavio Giorgi, and Gjergji Kasneci. Emergent Abilities in Large Language Models: A Survey, March 2025. arXiv:2503.05788 [cs]
arXiv 2025
-
[8]
Anthropic’s responsible scaling policy
Anthropic. Anthropic’s responsible scaling policy. Policy document, Anthropic, September 2023
2023
-
[9]
Hidden progress in deep learning: Sgd learns parities near the computational limit
Boaz Barak, Benjamin Edelman, Surbhi Goel, Sham Kakade, Eran Malach, and Cyril Zhang. Hidden progress in deep learning: Sgd learns parities near the computational limit. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 21750–21764. Curran Associates, Inc., 2022
2022
-
[10]
Information-theoretic progress measures reveal grokking is an emergent phase transition
Kenzo Clauw, Daniele Marinazzo, and Sebastiano Stramaglia. Information-theoretic progress measures reveal grokking is an emergent phase transition. InICML 2024 Workshop on Mech- anistic Interpretability, 2024
2024
-
[11]
Progress mea- sures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress mea- sures for grokking via mechanistic interpretability. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[12]
The mechanistic basis of data dependence and abrupt learning in an in-context classification task
Gautam Reddy. The mechanistic basis of data dependence and abrupt learning in an in-context classification task. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[13]
What can transformers learn in-context? a case study of simple function classes
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes. In S. Koyejo, S. Mohamed, A. Agar- wal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 30583–30598. Curran Associates, Inc., 2022. 11
2022
-
[14]
What learning algorithm is in-context learning? investigations with linear models
Ekin Aky ¨urek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. InThe Eleventh Interna- tional Conference on Learning Representations, 2023
2023
-
[15]
Transformers Learn In-Context by Gradient Descent
Johannes V on Oswald, Eyvind Niklasson, Ettore Randazzo, Joao Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers Learn In-Context by Gradient Descent. InProceedings of the 40th International Conference on Machine Learning, pages 35151–35174. PMLR, July 2023
2023
-
[16]
Lu, Mary Letey, Jacob A
Yue M. Lu, Mary Letey, Jacob A. Zavatone-Veth, Anindita Maiti, and Cengiz Pehlevan. Asymptotic theory of in-context learning by linear attention.Proceedings of the National Academy of Sciences, 122(28):e2502599122, 2025
2025
-
[17]
In-context Learning and Induction Heads, September 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
Pith/arXiv arXiv 2022
-
[18]
Iteration head: A mechanistic study of chain-of-thought
Vivien Cabannes, Charles Arnal, Wassim Bouaziz, Xingyu Alice Yang, Francois Charton, and Julia Kempe. Iteration head: A mechanistic study of chain-of-thought. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[19]
Uncovering mesa-optimization algorithms in Trans- formers, September 2023
Johannes von Oswald, Eyvind Niklasson, Maximilian Schlegel, Seijin Kobayashi, Nicolas Zucchet, Nino Scherrer, Nolan Miller, Mark Sandler, Blaise Ag¨uera y Arcas, Max Vladymyrov, Razvan Pascanu, and Jo ˜ao Sacramento. Uncovering mesa-optimization algorithms in Trans- formers, September 2023. arXiv:2309.05858 [cs]
arXiv 2023
-
[20]
Edelman, eran malach, and Surbhi Goel
Ezra Edelman, Nikolaos Tsilivis, Benjamin L. Edelman, eran malach, and Surbhi Goel. The evolution of statistical induction heads: In-context learning markov chains. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[21]
How Transformers Get Rich: Approximation and Dynamics Analysis, January 2025
Mingze Wang, Ruoxi Yu, Weinan E, and Lei Wu. How Transformers Get Rich: Approximation and Dynamics Analysis, January 2025. arXiv:2410.11474 [cs] version: 3
arXiv 2025
-
[22]
Be- yond induction heads: In-context meta learning induces multi-phase circuit emergence
Gouki Minegishi, Hiroki Furuta, Shohei Taniguchi, Yusuke Iwasawa, and Yutaka Matsuo. Be- yond induction heads: In-context meta learning induces multi-phase circuit emergence. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Confer- e...
2025
-
[23]
Predicting the Emergence of Induction Heads in Language Model Pretraining, February 2026
Tatsuya Aoyama, Ethan Gotlieb Wilcox, and Nathan Schneider. Predicting the Emergence of Induction Heads in Language Model Pretraining, February 2026. arXiv:2511.16893 [cs]
arXiv 2026
-
[24]
Infinite attention: NNGP and NTK for deep attention networks
Jiri Hron, Yasaman Bahri, Jascha Sohl-Dickstein, and Roman Novak. Infinite attention: NNGP and NTK for deep attention networks. In Hal Daum´e III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 4376–4386. PMLR, 13–18 Jul 2020
2020
-
[25]
Towards Understanding Inductive Bias in Trans- formers: A View From Infinity
Itay Lavie, Guy Gur-Ari, and Zohar Ringel. Towards Understanding Inductive Bias in Trans- formers: A View From Infinity. InProceedings of the 41st International Conference on Ma- chine Learning, pages 26043–26069. PMLR, July 2024
2024
-
[26]
Geometric dynamics of signal propagation predict trainability of transformers.Phys
Aditya Cowsik, Tamra Nebabu, Xiaoliang Qi, and Surya Ganguli. Geometric dynamics of signal propagation predict trainability of transformers.Phys. Rev. E, 112:055301, Nov 2025
2025
-
[27]
The shaped transformer: Attention models in the infinite depth-and-width limit
Lorenzo Noci, Chuning Li, Mufan Li, Bobby He, Thomas Hofmann, Chris Maddison, and Dan Roy. The shaped transformer: Attention models in the infinite depth-and-width limit. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 54250–54281. Curran Associates, Inc., 2023. 12
2023
-
[28]
Infinite limits of multi-head trans- former dynamics
Blake Bordelon, Hamza Chaudhry, and Cengiz Pehlevan. Infinite limits of multi-head trans- former dynamics. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 35824–35878. Curran Associates, Inc., 2024
2024
-
[29]
Separation of scales and a thermodynamic description of feature learning in some CNNs.Nature Communications, 14(1):908, 2023
Inbar Seroussi, Gadi Naveh, and Zohar Ringel. Separation of scales and a thermodynamic description of feature learning in some CNNs.Nature Communications, 14(1):908, 2023
2023
-
[30]
Critical feature learning in deep neural networks
Kirsten Fischer, Javed Lindner, David Dahmen, Zohar Ringel, Michael Kr ¨amer, and Moritz Helias. Critical feature learning in deep neural networks. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, ed- itors,Proceedings of the 41st International Conference on Machine Learning, vol...
2024
-
[31]
From kernels to features: A multi-scale adaptive theory of feature learning
Noa Rubin, Kirsten Fischer, Javed Lindner, Inbar Seroussi, Zohar Ringel, Michael Kr ¨amer, and Moritz Helias. From kernels to features: A multi-scale adaptive theory of feature learning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd Internation...
2025
-
[32]
Grokking as a first order phase transition in two layer networks
Noa Rubin, Inbar Seroussi, and Zohar Ringel. Grokking as a first order phase transition in two layer networks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[33]
Dissecting the interplay of attention paths in a statistical mechanics theory of transformers
Lorenzo Tiberi, Francesca Mignacco, Kazuki Irie, and Haim Sompolinsky. Dissecting the interplay of attention paths in a statistical mechanics theory of transformers. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 72710–72753. Curran Associate...
2024
-
[34]
Chan, and Andrew M Saxe
Aaditya K Singh, Ted Moskovitz, Felix Hill, Stephanie C.Y . Chan, and Andrew M Saxe. What needs to go right for an induction head? A mechanistic study of in-context learning circuits and their formation. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the ...
2024
-
[35]
Eshaan Nichani, Alex Damian, and Jason D. Lee. How transformers learn causal structure with gradient descent. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learnin...
2024
-
[36]
Unveiling induction heads: Provable training dynamics and feature learning in transformers
Siyu Chen, Heejune Sheen, Tianhao Wang, and Zhuoran Yang. Unveiling induction heads: Provable training dynamics and feature learning in transformers. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Infor- mation Processing Systems, volume 37, pages 66479–66567. Curran Associates, Inc., 2024
2024
-
[37]
Birth of a transformer: A memory viewpoint
Alberto Bietti, Vivien Cabannes, Diane Bouchacourt, Herve Jegou, and Leon Bottou. Birth of a transformer: A memory viewpoint. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 1560–1588. Curran Associates, Inc., 2023
2023
-
[38]
On the Emergence of Induction Heads for In-Context Learning, January
Tiberiu Musat, Tiago Pimentel, Lorenzo Noci, Alessandro Stolfo, Mrinmaya Sachan, and Thomas Hofmann. On the Emergence of Induction Heads for In-Context Learning, January
-
[39]
arXiv:2511.01033 [cs]
-
[40]
Scan and snap: Understanding training dynamics and token composition in 1-layer transformer
Yuandong Tian, Yiping Wang, Beidi Chen, and Simon Du. Scan and snap: Understanding training dynamics and token composition in 1-layer transformer. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 71911–71947. Curran Associates, Inc., 2023. 13
2023
-
[41]
Latham, and Andrew M Saxe
Yedi Zhang, Aaditya K Singh, Peter E. Latham, and Andrew M Saxe. Training dynamics of in- context learning in linear attention. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste- Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceeding...
2025
-
[42]
Linear attention is (maybe) all you need (to understand transformer optimization)
Kwangjun Ahn, Xiang Cheng, Minhak Song, Chulhee Yun, Ali Jadbabaie, and Suvrit Sra. Linear attention is (maybe) all you need (to understand transformer optimization). InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[43]
Applications of statis- tical field theory in deep learning.arXiv:2502.18553, 2025
Zohar Ringel, Noa Rubin, Edo Mor, Moritz Helias, and Inbar Seroussi. Applications of statis- tical field theory in deep learning.arXiv:2502.18553, 2025
arXiv 2025
-
[44]
Tuning large neural networks via zero-shot hyperparameter transfer
Ge Yang, Edward Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tuning large neural networks via zero-shot hyperparameter transfer. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pa...
2021
-
[45]
B. W. Silverman. Spline smoothing: The equivalent variable kernel method.The Annals of Statistics, 12(3):898–916, 1984
1984
-
[46]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations (ICLR), 2015
2015
-
[47]
Bayesian learning via stochastic gradient langevin dynamics
Max Welling and Yee Whye Teh. Bayesian learning via stochastic gradient langevin dynamics. InProceedings of the 28th International Conference on International Conference on Machine Learning, ICML’11, page 681–688, Madison, WI, USA, 2011. Omnipress
2011
-
[48]
Predicting the outputs of finite deep neural networks trained with noisy gradients.Phys
Gadi Naveh, Oded Ben David, Haim Sompolinsky, and Zohar Ringel. Predicting the outputs of finite deep neural networks trained with noisy gradients.Phys. Rev. E, 104:064301, Dec 2021
2021
-
[49]
Cambridge University Press, Cambridge, 2007
Mehran Kardar.Statistical Physics of Fields. Cambridge University Press, Cambridge, 2007
2007
-
[50]
Max Hennick and Guillaume Corlouer. From density matrices to phase transitions in deep learning: Spectral early warnings and interpretability.arXiv:2603.29805, 2026
arXiv 2026
-
[51]
E. Gardner. The space of interactions in neural network models.Journal of Physics A: Math- ematical and General, 21(1):257, January 1988
1988
-
[52]
Gardner and B
E. Gardner and B. Derrida. Optimal storage properties of neural network models.Journal of Physics A: Mathematical and General, 21(1):271, January 1988
1988
-
[53]
Springer International Publishing, Cham, 2020
Moritz Helias and David Dahmen.Statistical Field Theory for Neural Networks, volume 970 ofLecture Notes in Physics. Springer International Publishing, Cham, 2020
2020
-
[54]
Schoenholz, Jascha Sohl- Dickstein, and Surya Ganguli
Yasaman Bahri, Jonathan Kadmon, Jeffrey Pennington, Sam S. Schoenholz, Jascha Sohl- Dickstein, and Surya Ganguli. Statistical Mechanics of Deep Learning.Annual Review of Condensed Matter Physics, 11(V olume 11, 2020):501–528, March 2020
2020
-
[55]
High-dimensional learning of narrow neural networks.Journal of Statistical Me- chanics: Theory and Experiment, 2025(2):023402, February 2025
Hugo Cui. High-dimensional learning of narrow neural networks.Journal of Statistical Me- chanics: Theory and Experiment, 2025(2):023402, February 2025
2025
-
[56]
The large deviation approach to statistical mechanics.Physics Reports, 478(1):1–69, 2009
Hugo Touchette. The large deviation approach to statistical mechanics.Physics Reports, 478(1):1–69, 2009
2009
-
[57]
Coding schemes in neural networks learning classification tasks.Nature Communications, 16:3354, 2025
Alexander van Meegen and Haim Sompolinsky. Coding schemes in neural networks learning classification tasks.Nature Communications, 16:3354, 2025
2025
-
[58]
Bauer, Kirsten Fischer, Moritz Helias, and Agostina Palmigiano
Jan P. Bauer, Kirsten Fischer, Moritz Helias, and Agostina Palmigiano. A unified theory of feature learning in rnns and dnns.arXiv:2602.15593, 2026
arXiv 2026
-
[59]
Neal.Bayesian Learning for Neural Networks, volume 118 ofLecture Notes in Statistics
Radford M. Neal.Bayesian Learning for Neural Networks, volume 118 ofLecture Notes in Statistics. Springer, 1996. 14
1996
-
[60]
Deep neural networks as gaussian processes
Jaehoon Lee, Jascha Sohl-dickstein, Jeffrey Pennington, Roman Novak, Sam Schoenholz, and Yasaman Bahri. Deep neural networks as gaussian processes. InInternational Conference on Learning Representations, 2018
2018
-
[61]
Heejune Sheen, Siyu Chen, Tianhao Wang, and Harrison H. Zhou. Implicit Regularization of Gradient Flow on One-Layer Softmax Attention, March 2024. arXiv:2403.08699 [cs] version: 1
arXiv 2024
-
[62]
Trans- formers as Support Vector Machines, February 2024
Davoud Ataee Tarzanagh, Yingcong Li, Christos Thrampoulidis, and Samet Oymak. Trans- formers as Support Vector Machines, February 2024. arXiv:2308.16898 [cs, math]
arXiv 2024
-
[63]
Springer Berlin Heidelberg, Berlin, Heidelberg, 1996
Hannes Risken.Fokker-Planck Equation, pages 63–95. Springer Berlin Heidelberg, Berlin, Heidelberg, 1996
1996
-
[64]
A simple weight decay can improve generalization
Anders Krogh and John Hertz. A simple weight decay can improve generalization. In J. Moody, S. Hanson, and R.P. Lippmann, editors,Advances in Neural Information Processing Systems, volume 4. Morgan-Kaufmann, 1991. 15 Appendix A A short introduction to Landau Theory and Phase Transitions This appendix gives a self-contained statistical physics background f...
1991
-
[65]
∞X n=1 1 n gQgK L2dmodel ¯˜GT ¯˜G n# = dk 2 gQgK L2dmodel Tr h ¯˜GT ¯˜G i +O Tr
≈exp[−Λ (S(m ⋆ 1)−S(m ⋆ 2))].(44) For largeΛ, even a small difference in action is exponentially amplified. Therefore, when the two action values cross, the dominant saddle switches abruptly. The corresponding free energy is controlled by the lower of the two saddle values: F=−logZ≃Λ min{S(m ⋆ 1), S(m⋆ 2)}+subleading terms.(45) At the crossing point, this...
-
[66]
ln(gOPˆc2 G/L+σ 2)arises from theδ bd part ofC (xx) acting on directions that are constant in the data indexαbut traceless in the copy indexa. G Mapping the Posterior Through the Softmax We derive here the one-dimensional posterior for softmax attention theory, withsoftmaxexplicitly defined as softmaxa(x) = exa PL a=1 exa .(261) The starting point is the ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.