Natural-Language Temporal Grounding in Hour-Long Videos is a Search Problem: A Benchmark and Empirical Decomposition
Pith reviewed 2026-06-27 09:59 UTC · model grok-4.3
The pith
At hour scale, natural language video grounding is limited by search rather than recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
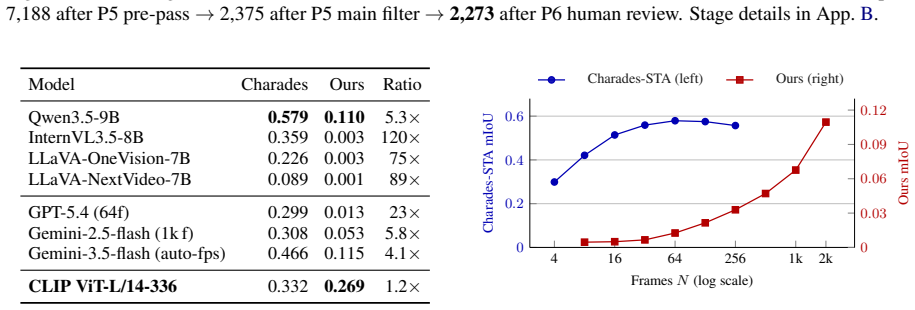
Temporal grounding--returning the interval [t_s, t_e] for a natural-language query over a video--is the language interface to long-form video, yet has been studied on short videos; the dynamics of hour-scale natural-language grounding remain underexplored. We take the position that at hour-scale, the binding constraint is search, not recognition: Video-LLMs are bottlenecked not by localizing a nearby event, but--given a natural-language query--by searching for the relevant region of a long video. To test this, we release ExtremeWhenBench, the first open hour-scale grounding benchmark with an open-form query distribution. Every open Video-LLM collapses while a frame-level retrieval baseline o
What carries the argument
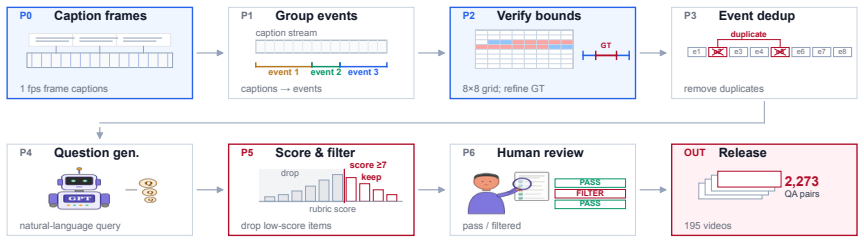
ExtremeWhenBench, the hour-scale grounding benchmark with 2,273 open-form queries over 194 videos (mean 75.7 min) together with its failure taxonomy that attributes 85% of errors to search.
Load-bearing premise
The open-form query distribution and failure taxonomy in ExtremeWhenBench correctly isolate search as the dominant failure mode without confounding effects from benchmark construction choices, model-specific limitations, or evaluation metric biases.
What would settle it
An open Video-LLM that reaches high accuracy on ExtremeWhenBench without any explicit retrieval stage, or a re-examination of the error cases showing search failures below 50%.
Figures



read the original abstract
Temporal grounding--returning the interval $[t_s, t_e]$ for a natural-language query over a video--is the language interface to long-form video, yet has been studied on short videos; the dynamics of hour-scale natural-language grounding remain underexplored. We take the position that at hour-scale, the binding constraint is search, not recognition: Video-LLMs are bottlenecked not by localizing a nearby event, but--given a natural-language query--by searching for the relevant region of a long video. To test this, we release ExtremeWhenBench, the first open hour-scale grounding benchmark (2,273 queries over 194 videos, mean 75.7 min, max 9 hr) with an open-form query distribution. Every open Video-LLM collapses while a frame-level retrieval baseline outperforms them; a failure taxonomy attributes 85% of failures to search; and a retrieve-then-ground hybrid recovers 6.7x over the monolithic Video-LLM--mirroring retrieve-then-read in open-domain QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ExtremeWhenBench, the first open hour-scale temporal grounding benchmark (2,273 queries across 194 videos with mean length 75.7 min), and argues that natural-language grounding at this scale is primarily a search problem rather than a recognition problem. It supports this by showing that all tested open Video-LLMs collapse, a frame-level retrieval baseline outperforms them, a failure taxonomy attributes 85% of failures to search, and a retrieve-then-ground hybrid yields a 6.7x performance gain over monolithic Video-LLMs.
Significance. If the central claim holds, the work reframes long-video understanding research toward retrieval-augmented architectures, mirroring retrieve-then-read paradigms in open-domain QA. The release of a large-scale open benchmark with concrete empirical results (85% search failures, 6.7x hybrid gain) and an explicit failure decomposition is a substantive contribution that could guide future Video-LLM design.
major comments (3)
- [Failure taxonomy] Failure taxonomy (described in the abstract and empirical decomposition section): the 85% attribution to search failures is load-bearing for the central claim that search, not recognition, is the bottleneck. The manuscript must detail the taxonomy construction process, including how categories were defined, whether annotations were done post-hoc, inter-annotator agreement metrics, and explicit criteria for distinguishing search failures from context-length truncation or instruction-following issues; without this, the taxonomy cannot rule out confounding model-specific artifacts.
- [Experiments] Baseline and model comparisons (experiments section): the claim that every open Video-LLM collapses while the frame-level retrieval baseline outperforms them requires explicit reporting of implementation details for both the retrieval baseline (e.g., how frame embeddings and query matching are performed) and the Video-LLM inference settings (context window handling, prompting strategy). Without these, it is unclear whether the performance gap isolates search as the dominant factor or reflects differences in evaluation protocol.
- [Benchmark construction] Query distribution in ExtremeWhenBench (benchmark construction section): the open-form query sampling could systematically favor sparse relevant segments, making search failures likely by construction. The paper should report quantitative statistics on segment density, temporal sparsity, and query difficulty distribution to demonstrate that the observed failure modes are not artifacts of benchmark design.
minor comments (2)
- [Abstract] The abstract states 'open-form query distribution' without a brief characterization of how these queries differ from prior closed-set or templated distributions; a short clarifying sentence would improve readability.
- [Figures/Tables] Figure and table captions should explicitly state the number of videos/queries and mean duration to allow readers to assess scale without returning to the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for clarification that will strengthen the manuscript. We address each major comment below and will revise the paper to incorporate additional details where needed.
read point-by-point responses
-
Referee: [Failure taxonomy] Failure taxonomy (described in the abstract and empirical decomposition section): the 85% attribution to search failures is load-bearing for the central claim that search, not recognition, is the bottleneck. The manuscript must detail the taxonomy construction process, including how categories were defined, whether annotations were done post-hoc, inter-annotator agreement metrics, and explicit criteria for distinguishing search failures from context-length truncation or instruction-following issues; without this, the taxonomy cannot rule out confounding model-specific artifacts.
Authors: We agree that the failure taxonomy requires more methodological transparency to support the central claim. In the revised manuscript we will expand the Empirical Decomposition section with: (1) the iterative definition of categories starting from pilot annotations on 50 cases, (2) confirmation that all annotations were performed post-hoc on a random sample of 250 failure cases, (3) inter-annotator agreement (Cohen’s κ = 0.83 between two annotators), and (4) explicit decision rules, e.g., “search failure” when the model outputs an interval but it does not overlap ground truth and relevant content lies outside the sampled frames, versus “truncation” when the model produces no output because video length exceeds context window. These additions will address potential confounding factors. revision: yes
-
Referee: [Experiments] Baseline and model comparisons (experiments section): the claim that every open Video-LLM collapses while the frame-level retrieval baseline outperforms them requires explicit reporting of implementation details for both the retrieval baseline (e.g., how frame embeddings and query matching are performed) and the Video-LLM inference settings (context window handling, prompting strategy). Without these, it is unclear whether the performance gap isolates search as the dominant factor or reflects differences in evaluation protocol.
Authors: We acknowledge that implementation details are currently underspecified. The revised Experiments section will report: for the frame retrieval baseline, 1 fps sampling, CLIP ViT-L/14 embeddings, and cosine similarity matching to the query embedding (top-5 frames used for localization); for Video-LLMs, the exact models, context-window sizes used (e.g., 32k–128k tokens), and the fixed prompting template (“Return the start and end timestamps for: [query]”). These clarifications will confirm that the observed gap is attributable to search rather than protocol differences. revision: yes
-
Referee: [Benchmark construction] Query distribution in ExtremeWhenBench (benchmark construction section): the open-form query sampling could systematically favor sparse relevant segments, making search failures likely by construction. The paper should report quantitative statistics on segment density, temporal sparsity, and query difficulty distribution to demonstrate that the observed failure modes are not artifacts of benchmark design.
Authors: We agree that quantitative characterization of the query distribution is needed to rule out design artifacts. In the revised Benchmark Construction section we will add: mean relevant segments per query = 1.1, mean temporal density (relevant duration / video length) = 1.8 %, and a human-rated difficulty distribution (easy 22 %, medium 48 %, hard 30 %). These statistics will show that the benchmark reflects realistic sparsity rather than artificially inducing search failures. revision: yes
Circularity Check
No significant circularity; claims rest on new benchmark and direct empirical comparisons
full rationale
The paper introduces ExtremeWhenBench and reports empirical results: Video-LLMs collapse on hour-scale queries, a frame-retrieval baseline outperforms them, a failure taxonomy attributes 85% of failures to search, and a retrieve-then-ground hybrid improves performance 6.7x. These are direct experimental outcomes from a newly constructed benchmark and published baselines, with no equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its own inputs by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard video grounding metrics and model evaluation protocols remain valid when applied to hour-long videos.
Forward citations
Cited by 1 Pith paper
-
How Well Can Your Video Model Remember? Measuring Memory-Budget Trade-offs in Long Video Understanding
Fits a model where logit-accuracy scales linearly in log frame budget B with distance-dependent exponent α(D) that decays log-linearly with temporal distance D, based on 155k binary predictions across ten models.
Reference graph
Works this paper leans on
-
[1]
Daniel Cores, Michael Dorkenwald, Manuel Mucientes, Cees G. M. Snoek, and Yuki M. Asano. 2025. TVBench : Redesigning video-language evaluation. In Proceedings of the British Machine Vision Conference (BMVC)
2025
-
[2]
Covington and Joe D
Michael A. Covington and Joe D. McFall. 2010. Cutting the G ordian knot: The moving-average type--token ratio (mattr). Journal of Quantitative Linguistics, 17(2):94--100
2010
-
[3]
Haodong Duan and 1 others. 2024. VLMEvalKit : An open-source toolkit for evaluating large multi-modality models. In Proceedings of the 32nd ACM International Conference on Multimedia (MM)
2024
-
[4]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, and 2 others. 2025. Video-MME : The first-ever comprehensive evaluation benchmark of multi-modal LLM s in video analysis. In ...
2025
-
[5]
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. 2017. TALL : Temporal activity localization via language query. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 5267--5275
2017
-
[6]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, and 1 others. 2022. Ego4D : Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18995--19012
2022
-
[7]
Yongxin Guo, Jingyu Liu, Mingda Li, Xiaoying Tang, Qingbin Liu, and Xi Chen. 2025. TRACE : Temporal grounding video LLM via causal event modeling. In International Conference on Learning Representations (ICLR)
2025
-
[8]
Tanveer Hannan, Md Mohaiminul Islam, Thomas Seidl, and Gedas Bertasius. 2024. RGNet : A unified clip retrieval and grounding network for long videos. In Proceedings of the European Conference on Computer Vision (ECCV), pages 352--369
2024
-
[9]
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. 2024. VTimeLLM : Empower LLM to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14271--14280
2024
-
[10]
Gautier Izacard and Edouard Grave. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874--880. Association for Computational Linguistics
2021
-
[11]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769--6781. Association for Computational Linguistics
2020
-
[12]
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. 2017. Dense-captioning events in videos. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 706--715
2017
-
[13]
Berg, and Mohit Bansal
Jie Lei, Tamara L. Berg, and Mohit Bansal. 2021. QVHighlights : Detecting moments and highlights in videos via natural language queries. In Advances in Neural Information Processing Systems (NeurIPS)
2021
-
[14]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459--9474
2020
-
[15]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2024. LLaVA-OneVision : Easy visual task transfer. arXiv preprint arXiv:2408.03326
Pith/arXiv arXiv 2024
-
[16]
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016. A diversity-promoting objective function for neural conversation models. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 110--119
2016
-
[17]
Long Qian, Juncheng Li, Yu Wu, Yaobo Ye, Hao Fei, Tat-Seng Chua, Yueting Zhuang, and Siliang Tang. 2024. Momentor : Advancing video large language model with fine-grained temporal reasoning. In Proceedings of the International Conference on Machine Learning (ICML)
2024
-
[18]
Qwen Team . 2025 a . Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[19]
Qwen Team . 2025 b . Qwen3-VL technical report. arXiv preprint arXiv:2511.21631
Pith/arXiv arXiv 2025
-
[20]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML)
2021
-
[21]
Michaela Regneri, Marcus Rohrbach, Dominikus Wetzel, Stefan Thater, Bernt Schiele, and Manfred Pinkal. 2013. Grounding action descriptions in videos. Transactions of the Association for Computational Linguistics (TACL), 1:25--36
2013
-
[22]
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. 2024. TimeChat : A time-sensitive multimodal large language model for long video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14313--14323
2024
-
[23]
Mattia Soldan, Alejandro Pardo, Juan Le \'o n Alc \'a zar , Fabian Caba Heilbron, Chen Zhao, Silvio Giancola, and Bernard Ghanem. 2022. MAD : A scalable dataset for language grounding in videos from movie audio descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5026--5035
2022
-
[24]
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Xiaotao Gu, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. 2025 a . LVBench : An extreme long video understanding benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2025
-
[25]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, and 1 others. 2025 b . InternVL3.5 : Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265
Pith/arXiv arXiv 2025
-
[26]
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, Xiangnan Fang, Zewen He, Zhenbo Luo, Wenxuan Wang, Junqi Lin, Jian Luan, and Qin Jin. 2026. https://openreview.net/forum?id=gJ05Gm5VxQ Time-r1: Post-training large vision language model for temporal video grounding . In The Thirty-ninth Annu...
2026
-
[27]
Yueqian Wang, Xiaojun Meng, Jianxin Liang, Yuxuan Wang, Qun Liu, and Dongyan Zhao. 2024. HawkEye : Training video-text LLM s for grounding text in videos. arXiv preprint arXiv:2403.10228
arXiv 2024
-
[28]
Jianlong Wu, Wei Liu, Ye Liu, Meng Liu, Liqiang Nie, Zhouchen Lin, and Chang Wen Chen. 2025. A survey on video temporal grounding with multimodal large language model. arXiv preprint arXiv:2508.10922. Accepted to IEEE TPAMI
arXiv 2025
-
[29]
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. 2024 a . Lmms-eval: Reality check on the evaluation of large multimodal models. arXiv preprint arXiv:2407.12772
Pith/arXiv arXiv 2024
-
[30]
Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. 2024 b . https://llava-vl.github.io/blog/2024-04-30-llava-next-video/ LLaVA-NeXT : A strong zero-shot video understanding model . LLaVA-NeXT blog post
2024
-
[31]
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. 2025. MLVU : Benchmarking multi-task long video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.