Atlas H&E-TME: Scalable AI-Based Tissue Profiling at Expert Pathologist-Level Accuracy
Pith reviewed 2026-06-27 09:47 UTC · model grok-4.3
The pith
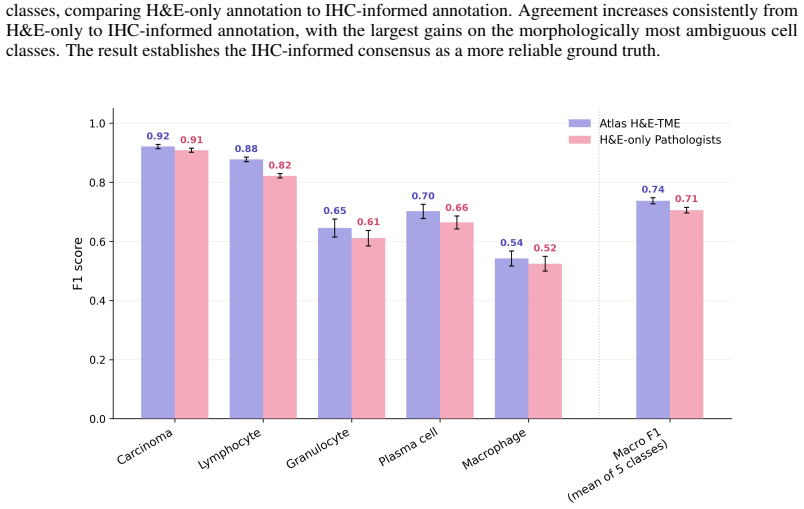
Atlas H&E-TME matches or exceeds pathologists working from H&E alone when measured against an IHC-informed consensus reference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
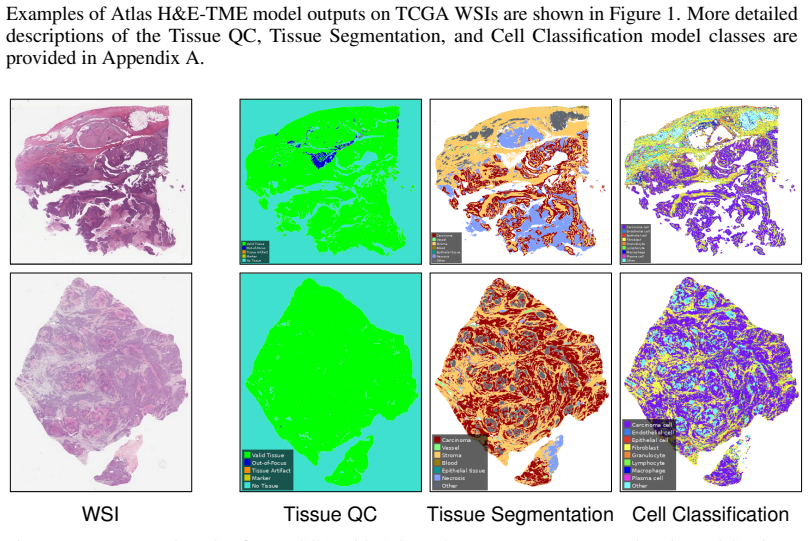
Atlas H&E-TME, built on the Atlas family of pathology foundation models, predicts tissue quality, region, and cell type labels to generate over 4500 quantitative readouts per slide at cell-level resolution. When benchmarked against an IHC-informed multi-pathologist consensus, the system matches or exceeds the performance of pathologists who see only H&E, and it maintains consistent accuracy across more than 200000 annotations from 1500+ cases covering eight cancer types and their common metastatic sites drawn from 25+ sources and 8+ scanner models.
What carries the argument
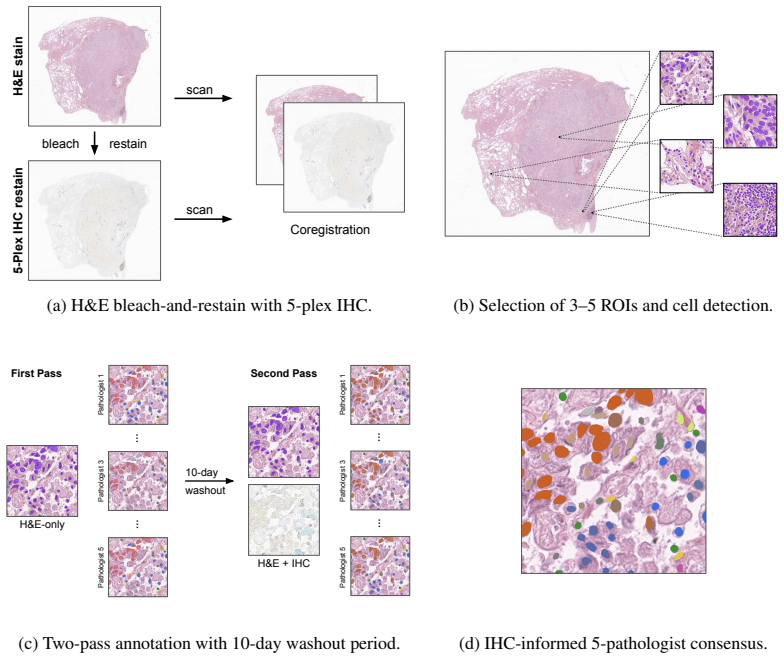
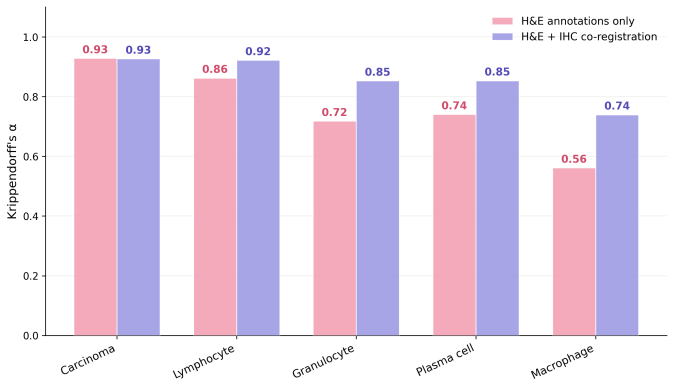
The dual validation framework that pairs an IHC-informed multi-pathologist consensus protocol for reference depth with large-scale H&E-only annotation benchmarking for morphological and technical breadth.
If this is right
- H&E slides become a scalable source of cell-level quantitative data on tumor and microenvironment features across common cancer types.
- The same model architecture can be applied to the majority of clinical cases without retraining for each new scanner or site.
- Tissue-based biomarker development gains a standardized, high-resolution readout layer that works on existing diagnostic slides.
- Routine pathology archives can be re-analyzed retrospectively to extract microenvironment metrics at scale.
Where Pith is reading between the lines
- Existing large H&E archives could be mined for microenvironment patterns that correlate with outcomes without new staining.
- Clinical workflows might reduce reliance on IHC for initial cell-type mapping in high-volume cancer types.
- The approach raises the question of how performance holds for the remaining 10 percent of rarer subtypes not covered in the main benchmarks.
Load-bearing premise
The IHC-informed multi-pathologist consensus provides a substantially more reliable and molecularly grounded reference than conventional H&E-only annotation.
What would settle it
A new set of cases with IHC ground truth where pathologists using only H&E show higher agreement with the consensus than Atlas H&E-TME does.
Figures
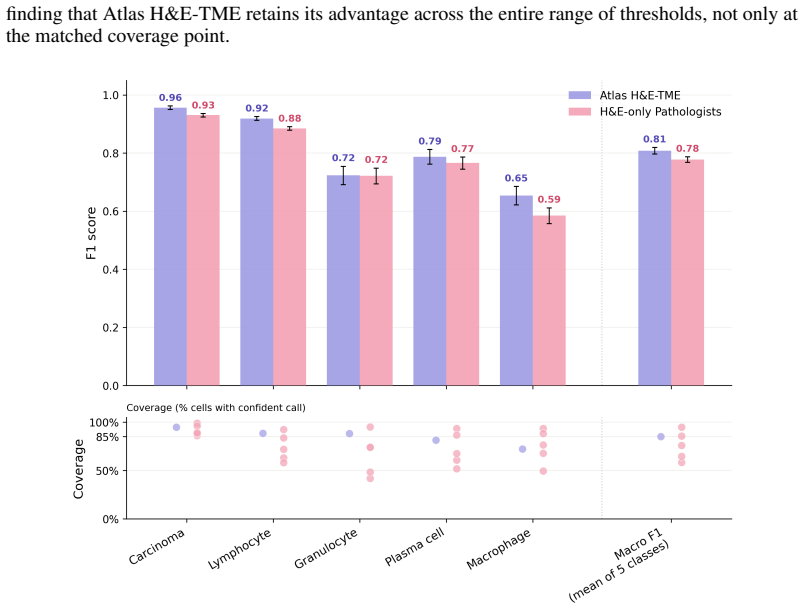
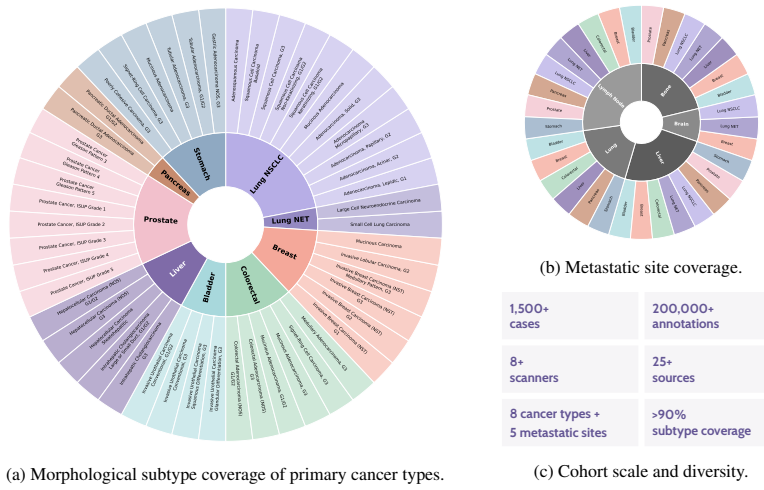
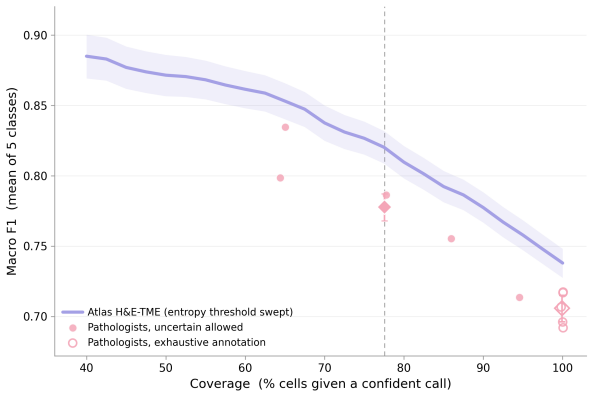

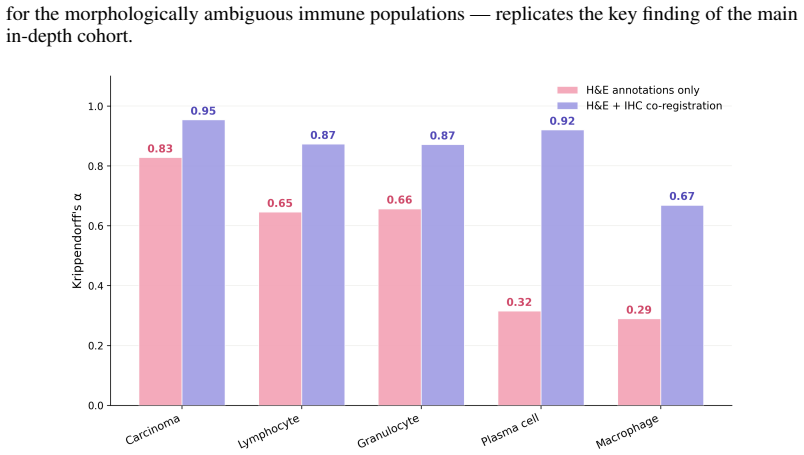

read the original abstract
Hematoxylin and eosin (H&E) staining is the cornerstone of histopathology, yet scalable, quantitative analysis of H&E whole-slide images (WSIs) remains a central challenge in computational pathology. We present Atlas H&E-TME, an AI-based system built on the Atlas family of pathology foundation models that predicts tissue quality, tissue region, and cell type labels across multiple cancer types, yielding over 4,500 quantitative readouts per slide at cell-level resolution. A key challenge to validating such systems is overcoming morphological ambiguity inherent to H&E-only ground truth and the limited scalability of more informed references drawing on modalities such as immunohistochemistry (IHC). We address this with a dual validation framework combining biologically grounded depth with technical and morphological breadth. For depth, we propose an IHC-informed multi-pathologist consensus protocol that substantially improves inter-rater agreement over conventional H&E-only annotation. This yields a molecularly grounded reference against which we compare Atlas H&E-TME and pathologists working from H&E alone. For breadth, we benchmark Atlas H&E-TME on over 200,000 high-confidence H&E-only pathologist annotations across 1,500+ cases spanning eight cancer types and their most common metastatic sites, with subtypes covering >90% of clinical cases per cancer type, drawn from 25+ sources and 8+ scanner models. Benchmarked against the IHC-informed consensus, Atlas H&E-TME matches or exceeds pathologist H&E-only performance and generalizes consistently and robustly across this broad morphological and technical scope. In doing so, Atlas H&E-TME turns the H&E slide -- the most ubiquitous data in pathology -- into a scalable, quantitative window into the tumor and its microenvironment, laying a foundation for the next generation of tissue-based biomarkers in translational and clinical research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Atlas H&E-TME, an AI system built on the Atlas family of pathology foundation models that predicts tissue quality, tissue region, and cell type labels on H&E whole-slide images across multiple cancer types, producing over 4,500 quantitative readouts per slide at cell-level resolution. Validation employs a dual framework: depth via an IHC-informed multi-pathologist consensus protocol claimed to substantially improve inter-rater agreement over H&E-only annotation, yielding a molecularly grounded reference; and breadth via benchmarking on over 200,000 high-confidence H&E-only pathologist annotations across 1,500+ cases from eight cancer types and common metastatic sites (subtypes covering >90% of clinical cases), drawn from 25+ sources and 8+ scanner models. The central claim is that, against the IHC-informed consensus, Atlas H&E-TME matches or exceeds pathologist H&E-only performance while generalizing robustly across the morphological and technical scope.
Significance. If the performance claims and reference-standard superiority hold with supporting metrics, the work would be significant for computational pathology. It would demonstrate scalable, cell-resolved quantitative TME profiling from routine H&E slides—the most common data modality—potentially enabling new translational biomarkers. The dual validation strategy (biologically grounded depth plus large-scale breadth) and multi-cancer generalization via foundation models are strengths if the IHC consensus is shown to be meaningfully superior and the quantitative results are reported with appropriate statistics.
major comments (2)
- [Dual validation framework] Dual validation framework (IHC-informed consensus protocol): The description asserts that the protocol 'substantially improves inter-rater agreement' and provides a 'molecularly grounded reference' but supplies no protocol specifics (number of pathologists, IHC markers used, disagreement adjudication rules, or quantitative metrics such as Cohen's kappa deltas). This is load-bearing for the central claim, as the assertion that Atlas H&E-TME matches or exceeds pathologist H&E-only performance rests on the consensus being a substantially more reliable reference than conventional H&E-only annotation; without these details the superiority cannot be verified.
- [Results and performance evaluation] Results and performance claims: The abstract and summary assert performance parity/generalization and 'matches or exceeds' pathologist performance but report no quantitative metrics (accuracy, F1, AUC), confidence intervals, exclusion criteria, or model architecture details. This prevents assessment of the soundness of the 200k-annotation breadth evaluation and the cross-cancer generalization claim.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting areas where additional detail will strengthen the manuscript. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Dual validation framework] Dual validation framework (IHC-informed consensus protocol): The description asserts that the protocol 'substantially improves inter-rater agreement' and provides a 'molecularly grounded reference' but supplies no protocol specifics (number of pathologists, IHC markers used, disagreement adjudication rules, or quantitative metrics such as Cohen's kappa deltas). This is load-bearing for the central claim, as the assertion that Atlas H&E-TME matches or exceeds pathologist H&E-only performance rests on the consensus being a substantially more reliable reference than conventional H&E-only annotation; without these details the superiority cannot be verified.
Authors: We agree that the current description lacks the necessary protocol details for independent verification. In the revised manuscript we will expand the Methods section to specify: the number of pathologists (three board-certified pathologists), the IHC markers employed for each cell-type category, the exact disagreement adjudication rules (majority vote with a fourth pathologist for unresolved cases), and quantitative inter-rater metrics (Cohen's kappa values before and after consensus, showing the reported improvement). These additions will directly support the claim that the IHC-informed reference is meaningfully more reliable than H&E-only annotation. revision: yes
-
Referee: [Results and performance evaluation] Results and performance claims: The abstract and summary assert performance parity/generalization and 'matches or exceeds' pathologist performance but report no quantitative metrics (accuracy, F1, AUC), confidence intervals, exclusion criteria, or model architecture details. This prevents assessment of the soundness of the 200k-annotation breadth evaluation and the cross-cancer generalization claim.
Authors: We acknowledge that the abstract and high-level summary do not include numerical performance metrics. The full manuscript contains detailed results tables and figures reporting accuracy, F1, AUC, and 95% confidence intervals for both the IHC-consensus depth evaluation and the 200k-annotation breadth evaluation, along with exclusion criteria and architecture details. To address the concern, we will add a concise summary table of key metrics (with CIs) to the abstract and ensure all generalization claims are explicitly tied to these numbers in the revised version. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical AI system for H&E tissue profiling validated against an external IHC-informed multi-pathologist consensus reference and a large independent set of >200k H&E annotations across diverse cases. No equations, fitted parameters, or derivation steps are presented that reduce reported performance metrics to the model's own inputs or training data by construction. The dual validation framework relies on separate external references rather than self-referential definitions or self-citation chains for its central claims. This is the expected non-finding for a methods/validation paper without mathematical derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-class cell detection using spatial context representation
Shahira Abousamra, David Belinsky, John Van Arnam, Felicia Allard, Eric Yee, Rajarsi Gupta, Tahsin Kurc, Dimitris Samaras, Joel Saltz, and Chao Chen. Multi-class cell detection using spatial context representation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3985–3994, 2021
2021
-
[2]
Gartrell, Julia Sarin Pradhan, Emanuelle Marie Rizk, Bonnie Gould Rothberg, Yvonne M
Balazs Acs, Fahad Shabbir Ahmed, Shilpa Gupta, Pok Fai Wong, Robyn D. Gartrell, Julia Sarin Pradhan, Emanuelle Marie Rizk, Bonnie Gould Rothberg, Yvonne M. Saenger, and 12 David L. Rimm. An open source automated tumor infiltrating lymphocyte algorithm for prognosis in melanoma.Nature Communications, 10:5440, 2019
2019
-
[3]
Towards comprehensive cellular characterisation of H&E slides.arXiv preprint arXiv:2508.09926, 2025
Benjamin Adjadj, Pierre-Antoine Bannier, Guillaume Horent, Sebastien Mandela, Aurore Lyon, Kathryn Schutte, Ulysse Marteau, Valentin Gaury, Laura Dumont, Thomas Mathieu, Reda Belbahri, Benoît Schmauch, Eric Durand, Katharina V on Loga, and Lucie Gillet. Towards comprehensive cellular characterisation of H&E slides.arXiv preprint arXiv:2508.09926, 2025
arXiv 2025
-
[4]
Atlas 2 – foundation models for clinical deployment.arXiv preprint arXiv:2601.05148, 2026
Maximilian Alber, Timo Milbich, Alexandra Carpen-Amarie, Stephan Tietz, Jonas Dippel, Lukas Muttenthaler, Beatriz Perez Cancer, Alessandro Benetti, Panos Korfiatis, Elias Eulig, Jérôme Lüscher, Jiasen Wu, Sayed Abid Hashimi, Gabriel Dernbach, Simon Schallenberg, Neelay Shah, Moritz Krügener, Aniruddh Jammoria, Jake Matras, Patrick Duffy, Matt Red- lon, Ph...
arXiv 2026
-
[5]
Maximilian Alber, Stephan Tietz, Jonas Dippel, Timo Milbich, Timothée Lesort, Panos Korfiatis, Moritz Krügener, Beatriz Perez Cancer, Neelay Shah, Alexander Möllers, Philipp Seegerer, Alexandra Carpen-Amarie, Kai Standvoss, Gabriel Dernbach, Edwin de Jong, Simon Schal- lenberg, Andreas Kunft, Helmut Hoffer von Ankershoffen, Gavin Schaeferle, Patrick Duffy...
arXiv 2025
-
[6]
Atteya, Hagar Hussein, Kareem Hosny Mohammed, Ehab Hafiz, Maha A
Mohamed Amgad, Lamees A. Atteya, Hagar Hussein, Kareem Hosny Mohammed, Ehab Hafiz, Maha A. T. Elsebaie, Ahmed M. Alhusseiny, Mohamed Atef AlMoslemany, Abdelmagid M. Elmatboly, Philip A. Pappalardo, Rokia Adel Sakr, Pooya Mobadersany, Ahmad Rachid, Anas M. Saad, Ahmad M. Alkashash, Inas A. Ruhban, Anas Alrefai, Nada M. Elgazar, Ali Abdulkarim, Abo-Alela Fa...
2022
-
[7]
Kerner, Carsten Denkert, Yinyin Yuan, Khalid AbdulJabbar, Stephan Wienert, Peter Savas, Leonie V oorwerk, Andrew H
Mohamed Amgad, Elisabeth Specht Stovgaard, Eva Balslev, Jeppe Thagaard, Weijie Chen, Sarah Dudgeon, Ashish Sharma, Jennifer K. Kerner, Carsten Denkert, Yinyin Yuan, Khalid AbdulJabbar, Stephan Wienert, Peter Savas, Leonie V oorwerk, Andrew H. Beck, Anant Madab- hushi, Johan Hartman, Manu M. Sebastian, Hugo M. Horlings, Jan Hudecek, Francesco Ciompi, David...
2020
-
[8]
Abu Bakr Azam, Felicia Wee, Juha P. Väyrynen, Willa Wen-You Yim, Yue Zhen Xue, Bok Leong Chua, Jeffrey Chun Tatt Lim, Aditya Chidambaram Somasundaram, Daniel Shao Weng Tan, Angela Takano, Chun Yuen Chow, Li Yan Khor, Tony Kiat Hon Lim, Joe Yeong, Mai Chan Lau, and Yiyu Cai. Training immunophenotyping deep learning models with the same-section ground truth...
2024
-
[9]
Nagtegaal, Maria Ro- driguez Martinez, and Inti Zlobec
Elias Baumann, Bastian Dislich, Josef Lorenz Rumberger, Iris D. Nagtegaal, Maria Ro- driguez Martinez, and Inti Zlobec. HoVer-NeXt: A fast nuclei segmentation and classification pipeline for next generation histopathology. InProceedings of the 7th International Conference on Medical Imaging with Deep Learning (MIDL), volume 250 ofProceedings of Machine Le...
2024
-
[10]
Epithelium segmentation using deep learning in H&E-stained prostate specimens with immunohistochemistry as reference standard.Scientific Reports, 9:864, 2019
Wouter Bulten, Péter Bándi, Jeffrey Hoven, Rob van de Loo, Johannes Lotz, Nick Weiss, Jeroen van der Laak, Bram van Ginneken, Christina Hulsbergen-van de Kaa, and Geert Lit- jens. Epithelium segmentation using deep learning in H&E-stained prostate specimens with immunohistochemistry as reference standard.Scientific Reports, 9:864, 2019
2019
-
[11]
Chen, Tong Ding, Ming Y
Richard J. Chen, Tong Ding, Ming Y . Lu, Drew F. K. Williamson, Guillaume Jaume, Andrew H. Song, Bowen Chen, Andrew Zhang, Daniel Shao, Muhammad Shaban, Mane Williams, Lukas Oldenburg, Luca L. Weishaupt, Judy J. Wang, Anurag Vaidya, Long Phi Le, Georg Gerber, Sharifa Sahai, Walt Williams, and Faisal Mahmood. Towards a general-purpose foundation model for ...
2024
-
[12]
Human-interpretable image features derived from densely mapped cancer pathology slides predict diverse molecular phenotypes.Nature communications, 12(1):1613, 2021
James A Diao, Jason K Wang, Wan Fung Chui, Victoria Mountain, Sai Chowdary Gullapally, Ramprakash Srinivasan, Richard N Mitchell, Benjamin Glass, Sara Hoffman, Sudha K Rao, et al. Human-interpretable image features derived from densely mapped cancer pathology slides predict diverse molecular phenotypes.Nature communications, 12(1):1613, 2021
2021
-
[13]
RudolfV: A Foundation Model by Pathologists for Pathologists.arXiv preprint arXiv:2401.04079, 2024
Jonas Dippel, Barbara Feulner, Tobias Winterhoff, Timo Milbich, Stephan Tietz, Simon Schal- lenberg, Gabriel Dernbach, Andreas Kunft, Simon Heinke, Marie-Lisa Eich, Julika Ribbat-Idel, Rosemarie Krupar, Philipp Anders, Niklas Prenißl, Philipp Jurmeister, David Horst, Lukas Ruff, Klaus-Robert Müller, Frederick Klauschen, and Maximilian Alber. RudolfV: A Fo...
arXiv 2024
-
[14]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[15]
On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(5), 2010
Ran El-Yaniv et al. On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(5), 2010
2010
-
[16]
Elmore, Gary M
Joann G. Elmore, Gary M. Longton, Patricia A. Carney, Berta M. Geller, Tracy Onega, Anna N. A. Tosteson, Heidi D. Nelson, Margaret S. Pepe, Kimberly H. Allison, Stuart J. Schnitt, Frances P. O’Malley, and Donald L. Weaver. Diagnostic concordance among pathologists interpreting breast biopsy specimens.JAMA, 313(11):1122–1132, 2015
2015
-
[17]
The immune contexture in cancer prognosis and treatment.Nature Reviews Clinical Oncology, 14(12):717–734, 2017
Wolf Herman Fridman, Laurence Zitvogel, Catherine Sautès-Fridman, and Guido Kroemer. The immune contexture in cancer prognosis and treatment.Nature Reviews Clinical Oncology, 14(12):717–734, 2017
2017
-
[18]
OpenTME: An open dataset of ai-powered h&e tumor microenvironment profiles from tcga, 2026
Maaike Galama, Nina Kozar-Gillan, Christina Embacher, Todd Dembo, Cornelius Böhm, Evelyn Ramberger, Julika Ribbat-Idel, Rosemarie Krupar, Verena Aumiller, Miriam Hägele, Kai Standvoss, Gerrit Erdmann, Blanca Pablos, Ari Angelo, Simon Schallenberg, Andrew Norgan, Viktor Matyas, Klaus-Robert Müller, Maximilian Alber, Lukas Ruff, and Frederick Klauschen. Ope...
2026
-
[19]
PanNuke: An open pan-cancer histology dataset for nuclei instance segmentation and classifica- tion
Jevgenij Gamper, Navid Alemi Koohbanani, Ksenija Benet, Ali Khuram, and Nasir Rajpoot. PanNuke: An open pan-cancer histology dataset for nuclei instance segmentation and classifica- tion. InEuropean Congress on Digital Pathology, volume 11435 ofLecture Notes in Computer Science, pages 11–19. Springer, 2019
2019
-
[20]
PanNuke dataset extension, insights and baselines.arXiv preprint arXiv:2003.10778, 2020
Jevgenij Gamper, Navid Alemi Koohbanani, Simon Graham, Mostafa Jahanifar, Syed Ali Khurram, Ayesha Azam, Katherine Hewitt, and Nasir Rajpoot. PanNuke dataset extension, insights and baselines.arXiv preprint arXiv:2003.10778, 2020
arXiv 2003
-
[21]
Selective classification for deep neural networks.Advances in neural information processing systems, 30, 2017
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks.Advances in neural information processing systems, 30, 2017
2017
-
[22]
Hollmann, and Saad Nadeem
Parmida Ghahremani, Yanyun Li, Arie Kaufman, Rami Vanguri, Noah Greenwald, Michael An- gelo, Travis J. Hollmann, and Saad Nadeem. Deep learning-inferred multiplex immunofluores- cence for immunohistochemical image quantification.Nature Machine Intelligence, 4:401–412, 2022. 14
2022
-
[23]
Lizard: A large-scale dataset for colonic nuclear instance segmentation and classification
Simon Graham, Mostafa Jahanifar, Ayesha Azam, Mohammed Nimir, Yee-Wah Tsang, Kather- ine Dodd, Emily Hero, Harvir Sahota, Atisha Tank, Ksenija Benes, Noorul Wahab, Fayyaz Minhas, Shan E Ahmed Raza, Hesham El Daly, Kishore Gopalakrishnan, David Snead, and Nasir Rajpoot. Lizard: A large-scale dataset for colonic nuclear instance segmentation and classificat...
2021
-
[24]
Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images.Medical Image Analysis, 58:101563, 2019
Simon Graham, Quoc Dang Vu, Shan E Ahmed Raza, Ayesha Azam, Yee Wah Tsang, Jin Tae Kwak, and Nasir Rajpoot. Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images.Medical Image Analysis, 58:101563, 2019
2019
-
[25]
Fabian Hörst, Moritz Rempe, Helmut Becker, Lukas Heine, Julius Keyl, and Jens Kleesiek. CellViT++: Energy-efficient and adaptive cell segmentation and classification using foundation models.arXiv preprint arXiv:2501.05269, 2025
arXiv 2025
-
[26]
CellViT: Vi- sion Transformers for precise cell segmentation and classification.Medical Image Analysis, 94:103143, 2024
Fabian Hörst, Moritz Rempe, Lukas Heine, Constantin Seibold, Julius Keyl, Giulia Baldini, Selma Ugurel, Jens Siveke, Barbara Grünwald, Jan Egger, and Jens Kleesiek. CellViT: Vi- sion Transformers for precise cell segmentation and classification.Medical Image Analysis, 94:103143, 2024
2024
-
[27]
Variability matters: Evaluating inter-rater variability in histopathology for robust cell detection
Cholmin Kang, Chunggi Lee, Heon Song, Minuk Ma, and Sérgio Pereira. Variability matters: Evaluating inter-rater variability in histopathology for robust cell detection. InEuropean Con- ference on Computer Vision (ECCV) Workshops, volume 13803 ofLecture Notes in Computer Science, pages 552–565. Springer, 2022
2022
-
[28]
Nora Koreuber, Jannik Franzen, Felix Hartmann Reith, Christoph Winklmayr, Jérôme Lüscher, and Dagmar Kainmueller. PhenoBench: A comprehensive benchmark for cell phenotyping on H&E histopathology images.arXiv preprint arXiv:2507.03532, 2025
arXiv 2025
-
[29]
SAGE Publications, Thousand Oaks, CA, 2018
Klaus Krippendorff.Content Analysis: An Introduction to Its Methodology. SAGE Publications, Thousand Oaks, CA, 2018
2018
-
[30]
Automated cell annotation and classification on histopathology for spatial biomarker discovery.Nature Communications, 16:6240, 2025
Zhe Li, Seyed Hossein Mirjahanmardi, Rasoul Sali, Feyisope Eweje, Matthew Gopaulchan, Leon Kloker, Xiaoming Zhang, Guoxin Li, Yuming Jiang, and Ruijiang Li. Automated cell annotation and classification on histopathology for spatial biomarker discovery.Nature Communications, 16:6240, 2025
2025
-
[31]
Thomas Mrowiec, Sharon Ruane, Simon Schallenberg, Gabriel Dernbach, Rumyana Todorova, Cornelius Boehm, Walter de Back, Blanca Pablos, Roman Schulte-Sasse, Ivana Trajanovska, et al. Immunohistochemistry-informed ai systems for improved characterization of tumor- microenvironment in clinical non-small cell lung cancer h&e samples.Cancer Research, 82(12_Supp...
2022
-
[32]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[33]
Sehhoon Park, Chan-Young Ock, Hyojin Kim, Sergio Pereira, Seonwook Park, Minuk Ma, Sangjoon Choi, Seokhwi Kim, Seunghwan Shin, Brian J. Aum, Kyunghyun Paeng, Donggeun Yoo, Hoon Cha, Sungyoung Park, Koung Jin Suh, Hyun Ae Jung, Se Hyun Kim, Yu Jung Kim, Jong-Mu Sun, Joo-Hang Chung, Jin Seok Ahn, Myung-Ju Ahn, Jong Seok Lee, Keunchil Park, Sang Yong Song, Y...
1916
-
[34]
Salgado, C
R. Salgado, C. Denkert, S. Demaria, N. Sirtaine, F. Klauschen, G. Pruneri, S. Wienert, G. Van den Eynden, F. L. Baehner, F. Penault-Llorca, E. A. Perez, E. A. Thompson, W. F. Symmans, A. L. Richardson, J. Brock, C. Criscitiello, H. Bailey, M. Ignatiadis, G. Floris, 15 J. Sparano, Z. Kos, T. Nielsen, D. L. Rimm, K. H. Allison, J. S. Reis-Filho, S. Loibl, C...
2014
-
[35]
Shroyer, Tianhao Zhao, Rebecca Batiste, John Van Arnam, The Cancer Genome Atlas Research Network, Ilya Shmulevich, Arvind U
Joel Saltz, Rajarsi Gupta, Le Hou, Tahsin Kurc, Pankaj Singh, Vu Nguyen, Dimitris Samaras, Kenneth R. Shroyer, Tianhao Zhao, Rebecca Batiste, John Van Arnam, The Cancer Genome Atlas Research Network, Ilya Shmulevich, Arvind U. K. Rao, Alexander J. Lazar, Ashish Sharma, and Vésteinn Thorsson. Spatial organization and molecular correlation of tumor- infiltr...
2018
-
[36]
Cell detection with star-convex polygons
Uwe Schmidt, Martin Weigert, Coleman Broaddus, and Gene Myers. Cell detection with star-convex polygons. InInternational conference on medical image computing and computer- assisted intervention, pages 265–273. Springer, 2018
2018
-
[37]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
Pith/arXiv arXiv 2025
-
[38]
Learning to detect lymphocytes in immunohistochemistry with deep learning.Medical Image Analysis, 58:101547, 2019
Zaneta Swiderska-Chadaj, Hans Pinckaers, Mart van Rijthoven, Maschenka Balkenhol, Mar- garita Melnikova, Oscar Geessink, Quirine Manson, Mark Sherman, António Polónia, Jeremy Parry, Mustapha Abubakar, Geert Litjens, Jeroen van der Laak, and Francesco Ciompi. Learning to detect lymphocytes in immunohistochemistry with deep learning.Medical Image Analysis, ...
2019
-
[39]
Vanguri, Jia Luo, Andrew T
Rami S. Vanguri, Jia Luo, Andrew T. Aukerman, Jacklynn V . Egger, Christopher J. Fong, Natally Horvat, Andrew Pagano, Jose de Arimateia Batista Araujo-Filho, Luke Geneslaw, Hira Rizvi, Ramon Sosa, Kevin M. Boehm, Shao-Hui Eric Yang, Francis M. Bodd, Katia Ventura, Travis J. Hollmann, Michelle S. Ginsberg, Jianjiong Gao, Poornima Vanguri, Matthew D. Hellma...
2024
-
[40]
Ahmed Raza, Nasir Rajpoot, Xiyi Wu, Hao Chen, Yifan Huang, Lingyun Wang, Hyun Jung, G
Ruchika Verma, Neeraj Kumar, Abhijeet Patil, Nikhil Cherian Kurian, Swapnil Rane, Simon Graham, Quoc Dang Vu, Mieke Zwager, Shan E. Ahmed Raza, Nasir Rajpoot, Xiyi Wu, Hao Chen, Yifan Huang, Lingyun Wang, Hyun Jung, G. Thomas Brown, Yixin Liu, Shuyue Liu, Seyed Alireza Fatemi Jahromi, Ali Asghar Khani, Ehsan Montahaei, Mahdieh Soleymani Baghshah, Hamid Be...
2021
-
[41]
Kunz, Matthew C
Eugene V orontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Kristen Severson, Eric Zimmermann, James Hall, Neil Tenenholtz, Nicolo Fusi, Ellen Yang, Philippe Mathieu, Alexander van Eck, Donghun Lee, Julian Viret, Eric Robert, Yi Kan Wang, Jeremy D. Kunz, Matthew C. H. Lee, Jan H. Bernhard, Ran A. Godrich, Gerard Oakley, Ewan Mil...
2024
-
[42]
Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Sheng Wang, and Hoifung Poon
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier González, Yu Gu, Yanbo Xu, Mu Wei, Wenhui Wang, Shuming Ma, Furu Wei, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Jaylen Rosemon, Tucker 16 Bower, Soohee Lee, Roshanthi Weerasinghe, Bill J. Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, S...
2024
-
[43]
uncertain
Antonia Zapf, Stefanie Castell, Lars Morawietz, and André Karch. Measuring inter-rater reliability for nominal data – which coefficients and confidence intervals are appropriate?BMC Medical Research Methodology, 16(1):93, 2016. 17 A Atlas H&E-TME: Description of Model Classes The following Tables 4, 5, and 6 describe the classes of the Tissue QC, Tissue S...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.