Doc-to-Atom: Learning to Compile and Compose Memory Atoms
Pith reviewed 2026-06-27 09:52 UTC · model grok-4.3
The pith
Doc-to-Atom decomposes each document into independent knowledge atoms compiled as micro-LoRA adapters that a router composes at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
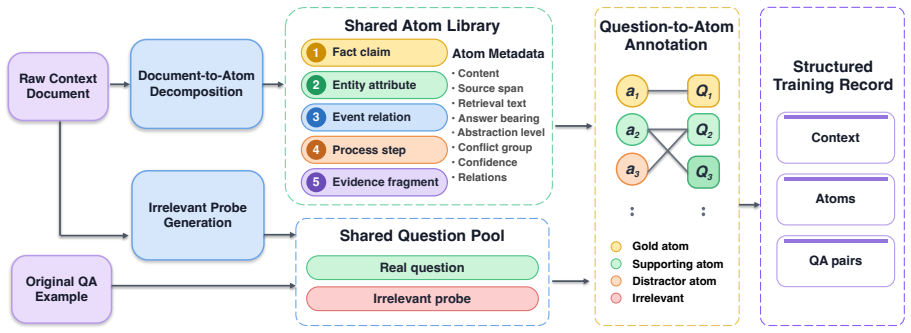
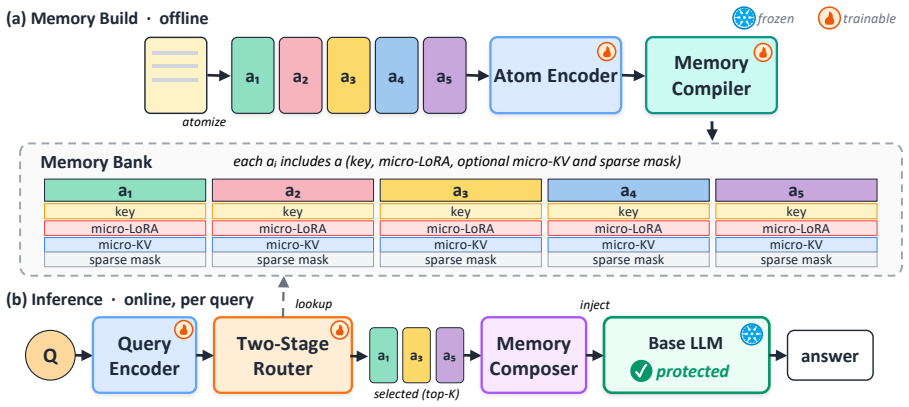
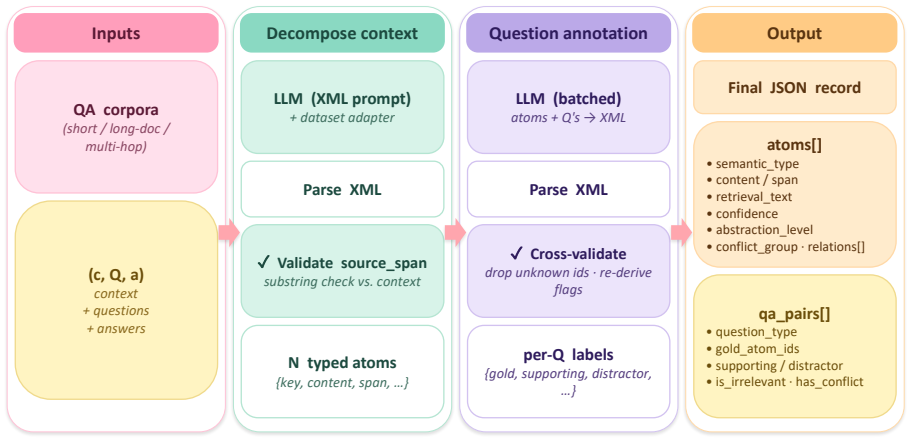
Doc-to-Atom decomposes each document into semantically typed knowledge atoms. Each atom is compiled into an independent micro-LoRA adapter and a provenance retrieval key. At inference a lightweight query router selects and assembles only the relevant atoms into a query-specific adapter, which is injected into a frozen base model. The entire system is trained end-to-end through a multi-objective distillation framework.
What carries the argument
The knowledge atom, a semantically typed unit extracted from a document and compiled into an independent micro-LoRA adapter with a retrieval key, which carries the selective composition step.
If this is right
- Memory cost for internalizing documents decreases because only selected atoms are loaded rather than one full adapter per document.
- Irrelevant-query interference is avoided by excluding unrelated atoms from the assembled adapter.
- Compositional recall improves because atoms from different parts of a document or multiple documents can be combined on demand.
- Long-document reasoning scales better since the router can draw from a larger pool of atoms without quadratic attention over the raw text.
Where Pith is reading between the lines
- The same atom decomposition could support incremental knowledge updates by inserting or deleting individual micro-adapters without retraining the router or base model.
- The routing step may reduce reliance on external retrieval systems when the atoms already capture the necessary facts.
- The approach could extend to non-QA tasks that benefit from selective parameter composition, such as multi-step planning or tool use.
Load-bearing premise
The query router can reliably identify and compose only the relevant atoms without introducing interference or missing key information.
What would settle it
Running the six QA benchmarks and observing that Doc2Atom performs no better than Doc-to-LoRA baselines or uses equal or greater memory would falsify the claimed advantage.
Figures




read the original abstract
Long input sequences are central to document understanding and multi-step reasoning in Large Language Models, yet the quadratic cost of attention makes inference both memory-intensive and slow. Context distillation mitigates this by compressing contextual information into model parameters, and recent work such as Doc-to-LoRA amortizes context distillation into a single forward pass that generates one LoRA adapter per document. However, producing a single monolithic adapter for all queries leads to irrelevant-query interference, limited compositional recall, and poor scalability to long-document reasoning. To address these challenges, we propose Doc-to-Atom (Doc2Atom), a compositional parametric memory framework that decomposes each document into semantically typed knowledge atoms. Each atom is compiled into an independent micro-LoRA adapter and a provenance retrieval key. At inference time, a lightweight query router selects and assembles only the relevant atoms into a query-specific adapter, which is then injected into a frozen base model. The entire system is trained end-to-end through a multi-objective distillation framework. Experiments on six diverse QA benchmarks demonstrate that Doc2Atom outperforms Doc-to-LoRA baselines while reducing the memory cost of document internalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Doc-to-Atom (Doc2Atom), a compositional parametric memory method that decomposes each document into semantically typed knowledge atoms. Each atom is compiled into an independent micro-LoRA adapter plus provenance key; at inference a lightweight query router selects and assembles only the relevant atoms into a query-specific adapter that is injected into a frozen base model. The system is trained end-to-end via multi-objective distillation. Experiments on six diverse QA benchmarks are reported to show outperformance over Doc-to-LoRA baselines together with reduced memory cost for document internalization.
Significance. If the central claims hold, the work would demonstrate a practical route to compositional, interference-resistant parametric memory that scales better than monolithic adapters for long-document reasoning. The combination of atom-level compilation, learned routing, and joint distillation could reduce both memory footprint and query-specific interference, addressing a recognized bottleneck in context-distillation approaches.
major comments (2)
- [§3, §4] §3 (Method) and §4 (Experiments): the headline outperformance claim rests on the query router reliably selecting and composing only relevant atoms without interference or omission, yet the manuscript supplies neither router accuracy metrics nor ablation results that isolate the effect of routing errors on end-task performance. Without these, it is impossible to confirm that the reported gains derive from the compositional mechanism rather than other factors.
- [§3.2] §3.2 (Multi-objective distillation): the joint training objective is described at a high level but the loss formulations, weighting coefficients, and convergence diagnostics for the atom-compilation and routing sub-tasks are not provided. Because the central claim requires successful end-to-end optimization of both components, the absence of these details leaves the training success unverified.
minor comments (2)
- Notation for the provenance retrieval key and the micro-LoRA rank are introduced without explicit definitions or comparison to the monolithic Doc-to-LoRA baseline rank; a short table or paragraph clarifying these choices would improve reproducibility.
- [§4] The six QA benchmarks are named only in the abstract; listing them with dataset statistics and evaluation metrics in §4 would strengthen the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate additional details and experiments where needed to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [§3, §4] §3 (Method) and §4 (Experiments): the headline outperformance claim rests on the query router reliably selecting and composing only relevant atoms without interference or omission, yet the manuscript supplies neither router accuracy metrics nor ablation results that isolate the effect of routing errors on end-task performance. Without these, it is impossible to confirm that the reported gains derive from the compositional mechanism rather than other factors.
Authors: We agree that router accuracy metrics and ablations isolating routing errors would provide more direct evidence that performance gains stem from the compositional routing mechanism rather than other factors. The current results establish overall outperformance versus Doc-to-LoRA baselines on six QA benchmarks, which use monolithic adapters and therefore cannot exploit atom-level selection. To address the concern rigorously, we will add router accuracy evaluations (e.g., precision/recall of atom selection) and controlled ablations that measure end-task degradation under simulated routing errors in the revised manuscript. revision: yes
-
Referee: [§3.2] §3.2 (Multi-objective distillation): the joint training objective is described at a high level but the loss formulations, weighting coefficients, and convergence diagnostics for the atom-compilation and routing sub-tasks are not provided. Because the central claim requires successful end-to-end optimization of both components, the absence of these details leaves the training success unverified.
Authors: We acknowledge that the loss formulations, weighting coefficients, and convergence diagnostics are necessary to verify successful joint optimization of atom compilation and routing. The manuscript currently summarizes the multi-objective distillation at a high level. In the revision we will expand §3.2 with the exact loss equations for each sub-task, the specific weighting coefficients employed, and training curves or convergence diagnostics demonstrating stable end-to-end optimization. revision: yes
Circularity Check
No circularity: claims rest on external benchmark evaluation
full rationale
The paper introduces Doc2Atom as a compositional memory framework using document decomposition into atoms, micro-LoRA compilation, query routing, and multi-objective end-to-end distillation. The headline result is empirical outperformance on six QA benchmarks plus memory reduction, with no equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs by construction. Evaluation is described as direct comparison against Doc-to-LoRA baselines on external tasks, making the derivation self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2602.15902 , year=
Doc-to-LoRA: Learning to Instantly Internalize Contexts , author=. arXiv preprint arXiv:2602.15902 , year=
-
[2]
Conference on Empirical Methods in Natural Language Processing , year=
Squad: 100,000+ questions for machine comprehension of text , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[3]
Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year=
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs , author=. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year=
-
[4]
2nd Workshop on Machine Reading for Question Answering , year=
Reasoning over paragraph effects in situations , author=. 2nd Workshop on Machine Reading for Question Answering , year=
-
[5]
International Conference on Computational Linguistics , year=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. International Conference on Computational Linguistics , year=
-
[6]
Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year=
A dataset of information-seeking questions and answers anchored in research papers , author=. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year=
-
[7]
Annual Meeting of the Association for Computational Linguistics , year=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[8]
doi:10.57967/hf/2497 , publisher =
Lozhkov, Anton and Ben Allal, Loubna and von Werra, Leandro and Wolf, Thomas , title =. doi:10.57967/hf/2497 , publisher =
-
[9]
Conference on Empirical Methods in Natural Language Processing , year=
Adapting language models to compress contexts , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[10]
International Conference on Machine Learning , year=
Text-to-LoRA: Instant transformer adaptation , author=. International Conference on Machine Learning , year=
-
[11]
Advances in Neural Information Processing Systems , year=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , year=
-
[12]
Transactions of the Association for Computational Linguistics , year=
Lost in the middle: How language models use long contexts , author=. Transactions of the Association for Computational Linguistics , year=
-
[13]
arXiv preprint arXiv:2308.10792 , year=
Instruction tuning for large language models: A survey , author=. arXiv preprint arXiv:2308.10792 , year=
-
[14]
arXiv preprint arXiv:1609.09106 , year=
Hypernetworks , author=. arXiv preprint arXiv:1609.09106 , year=
-
[15]
International Conference on Learning Representations , year=
LoRA: Low-rank adaptation of large language models , author=. International Conference on Learning Representations , year=
-
[16]
arXiv preprint arXiv:2112.00861 , year=
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
-
[17]
arXiv preprint arXiv:2209.15189 , year=
Learning by distilling context , author=. arXiv preprint arXiv:2209.15189 , year=
-
[18]
ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , year=
Model compression , author=. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , year=
-
[19]
arXiv preprint arXiv:1503.02531 , year=
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[20]
International Conference on Machine Learning , year=
Perceiver: General perception with iterative attention , author=. International Conference on Machine Learning , year=
-
[21]
Annual Meeting of the Association for Computational Linguistics , year=
Prefix-tuning: Optimizing continuous prompts for generation , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[22]
arXiv preprint arXiv:2404.06654 , year=
RULER: What's the real context size of your long-context language models? , author=. arXiv preprint arXiv:2404.06654 , year=
-
[23]
Findings of the Association for Computational Linguistics: EMNLP 2022 , year=
Hyperdecoders: Instance-specific decoders for multi-task nlp , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , year=
2022
-
[24]
Annual Meeting of the Association for Computational Linguistics , year=
Hint: Hypernetwork instruction tuning for efficient zero-and few-shot generalisation , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[25]
International Conference on Learning Representations , year=
MEND: Meta demonstration distillation for efficient and effective in-context learning , author=. International Conference on Learning Representations , year=
-
[26]
Advances in Neural Information Processing Systems , year=
Learning to compress prompts with gist tokens , author=. Advances in Neural Information Processing Systems , year=
-
[27]
arXiv preprint arXiv:2506.06266 , year=
Cartridges: Lightweight and general-purpose long context representations via self-study , author=. arXiv preprint arXiv:2506.06266 , year=
-
[28]
International Conference on Learning Representations , year=
Generative adapter: Contextualizing language models in parameters with a single forward pass , author=. International Conference on Learning Representations , year=
-
[29]
International Conference on Learning Representations , year=
Alphaedit: Null-space constrained model editing for language models , author=. International Conference on Learning Representations , year=
-
[30]
arXiv preprint arXiv:2510.15103 , year=
Continual learning via sparse memory finetuning , author=. arXiv preprint arXiv:2510.15103 , year=
-
[31]
Findings of the Association for Computational Linguistics: ACL 2024 , year=
HyperLoRA: Efficient cross-task generalization via constrained low-rank adapters generation , author=. Findings of the Association for Computational Linguistics: ACL 2024 , year=
2024
-
[32]
Second Conference on Language Modeling , year=
Training plug-and-play knowledge modules with deep context distillation , author=. Second Conference on Language Modeling , year=
-
[33]
Findings of the Association for Computational Linguistics: ACL 2024 , year=
LLMLingua-2: Data distillation for efficient and faithful task-agnostic prompt compression , author=. Findings of the Association for Computational Linguistics: ACL 2024 , year=
2024
-
[34]
International Conference on Learning Representations , year=
Differential transformer , author=. International Conference on Learning Representations , year=
-
[35]
International Conference on Learning Representations , year=
Long context compression with activation beacon , author=. International Conference on Learning Representations , year=
-
[36]
Findings of the Association for Computational Linguistics: ACL 2025 , year=
Infiniteicl: Breaking the limit of context window size via long short-term memory transformation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , year=
2025
-
[37]
Proceedings of the National Academy of Sciences , year=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , year=
-
[38]
International Conference on Learning Representations , year=
Continual learning with hypernetworks , author=. International Conference on Learning Representations , year=
-
[39]
MiniMax-M2.5 , year = 2026, url =
2026
-
[40]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[41]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.