EWAM: An Enhanced World Action Model for Closed-Loop Online Adaptation in Embodied Intelligence
Pith reviewed 2026-06-27 09:21 UTC · model grok-4.3
The pith
Adding four lightweight neural layers to a frozen pretrained world model allows closed-loop online adaptation to new tasks without any fine-tuning or extra demonstration data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
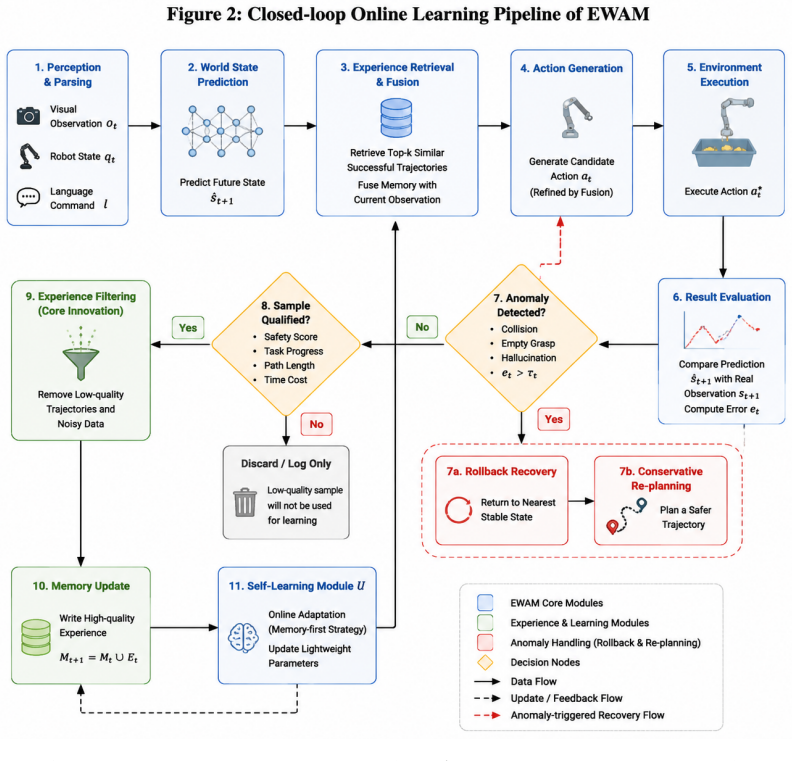
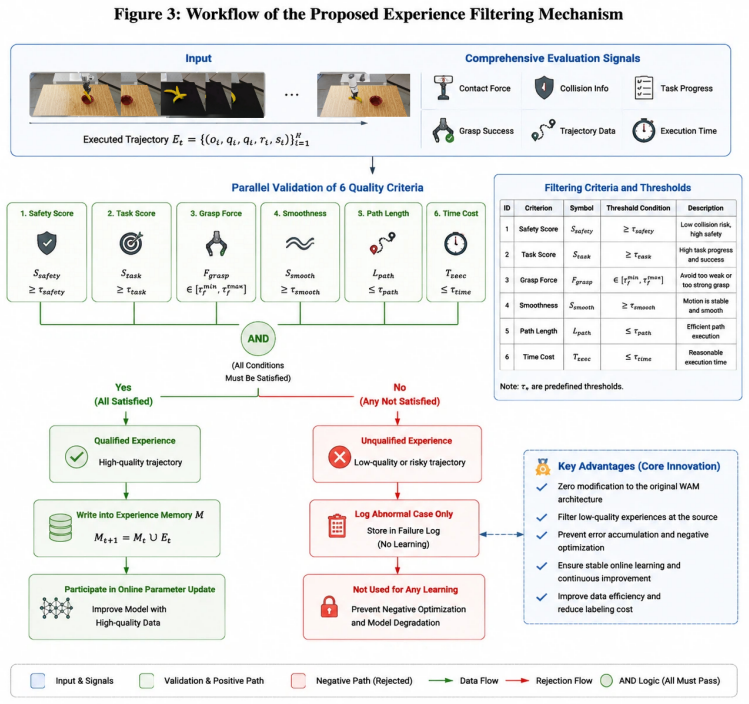
EWAM achieves closed-loop online adaptation by inserting four lightweight neural layers into the Cosmos3 backbone: a Neural Experience Memory Layer in the DiT for task context, a Neural Anomaly Detection Layer to monitor state divergences, a Neural Policy Routing Layer to choose execution modes, and a Neural Action Correction Layer to refine actions. These are integrated differentiably into the forward path except for the discrete routing decision, and all gains are obtained under zero-shot conditions with no task-specific data or backbone updates.
What carries the argument
The inference-time co-reasoning mechanism of four lightweight neural layers deeply integrated into the diffusion transformer's forward path.
If this is right
- New task layouts can be handled without collecting task-specific demonstration sets.
- No fine-tuning of the backbone network is required for adaptation.
- Real-time anomaly monitoring enables dynamic selection between direct execution, replanning, or rollback.
- Action chunks are refined using execution diagnostics during inference.
Where Pith is reading between the lines
- Similar lightweight modules could be tested on other pretrained world models beyond the given backbone.
- The differentiable integration might allow end-to-end optimization of the adaptation layers if some training were permitted in future work.
- This could reduce the data barrier for deploying embodied agents in varied real-world settings.
Load-bearing premise
The four lightweight layers integrate differentiably into the forward path to produce effective real-time adaptation to new layouts without task-specific training.
What would settle it
An experiment showing no performance improvement over the frozen backbone alone when the four layers are added but their integration is made non-differentiable or when anomaly detection is disabled.
Figures



read the original abstract
In this paper, we propose the Enhanced World Action Model (EWAM), a closed-loop online adaptation architecture built upon a pretrained and fully frozen Cosmos3 backbone network. Evaluated entirely under a zero-shot task protocol, EWAM is centrally focused on reducing the amount of additional deployment data required to adapt to new task layouts. Notably, no extra task-specific demonstration sets were introduced in any of the evaluations, and no fine-tuning was performed on the backbone network. Its performance gains stem entirely from an inference-time co-reasoning mechanism composed of four inserted lightweight neural layers: the Neural Experience Memory Layer located in the intermediate layers of the Diffusion Transformer (DiT) provides task-relevant execution context; the Neural Anomaly Detection Layer after the state prediction head monitors the divergence between predicted and actual states in real time; the Neural Policy Routing Layer dynamically selects direct execution, conservative replanning, or rollback recovery based on the anomaly severity; and the Neural Action Correction Layer refines the generated action chunks using execution diagnostics. Unlike naive feature fusion, the memory, anomaly detection, and correction modules are deeply integrated into the Cosmos3 forward path in a differentiable manner, with only the final routing decision being a discrete supervised one.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Enhanced World Action Model (EWAM), a closed-loop online adaptation architecture built on a pretrained and fully frozen Cosmos3 backbone. It inserts four lightweight neural layers—an Neural Experience Memory Layer in the DiT intermediate layers, a Neural Anomaly Detection Layer after the state prediction head, a Neural Policy Routing Layer, and a Neural Action Correction Layer—to enable inference-time co-reasoning. The work claims performance gains under a zero-shot task protocol with no extra task-specific demonstration sets and no backbone fine-tuning, attributing all gains to these layers, which are deeply integrated differentiably except for the final discrete supervised routing decision.
Significance. If the central claims hold after addressing the noted tension, the result would be significant for embodied AI by showing how lightweight, online modules can reduce deployment data needs for new task layouts without retraining the backbone. The differentiable integration of memory, anomaly, and correction modules into the forward path is a potentially valuable technical contribution, though the absence of any reported quantitative results, baselines, or error bars prevents gauging the magnitude of the advance.
major comments (1)
- [Abstract] Abstract: The assertion that 'no extra task-specific demonstration sets were introduced in any of the evaluations' and that gains occur under a zero-shot protocol is in direct tension with the requirement that the Neural Policy Routing Layer uses a 'discrete supervised' decision. No internal mechanism is described for generating the necessary supervision labels from the anomaly or memory modules alone, nor is it stated that the routing layer is frozen or heuristic; this undermines the load-bearing claim that adaptation requires neither task-specific data nor backbone updates.
minor comments (1)
- [Abstract] Abstract: The text states that performance gains are achieved but supplies no quantitative metrics, baselines, ablation results, or experimental protocol details, making it impossible to evaluate the strength of the empirical support.
Simulated Author's Rebuttal
We thank the referee for identifying this important tension in the abstract regarding the zero-shot protocol and the supervised routing decision. We address the comment directly below and will revise the manuscript to resolve the inconsistency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'no extra task-specific demonstration sets were introduced in any of the evaluations' and that gains occur under a zero-shot protocol is in direct tension with the requirement that the Neural Policy Routing Layer uses a 'discrete supervised' decision. No internal mechanism is described for generating the necessary supervision labels from the anomaly or memory modules alone, nor is it stated that the routing layer is frozen or heuristic; this undermines the load-bearing claim that adaptation requires neither task-specific data nor backbone updates.
Authors: We agree that the current wording creates an unresolved tension. The manuscript states that the routing decision is 'discrete supervised' without describing any internal mechanism (e.g., labels derived solely from the anomaly detection or memory modules) or clarifying whether the routing layer remains frozen at inference. Because no such mechanism is provided in the paper, the zero-shot claim cannot be fully substantiated as written. We will revise the abstract to remove or qualify the 'discrete supervised' phrasing, add an explicit statement that the routing layer is frozen after initial training and operates heuristically or via anomaly signals at deployment, and include a short methods paragraph detailing the absence of task-specific supervision during evaluation. This revision will be made in the next version. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical architecture proposal inserting four lightweight layers into a frozen pretrained backbone for zero-shot closed-loop adaptation. No mathematical derivation chain, equations, or first-principles results are described that reduce to inputs by construction. The abstract's reference to a 'discrete supervised' routing decision does not match any enumerated circularity pattern such as self-definitional equivalence, fitted inputs renamed as predictions, or self-citation load-bearing, as no specific fitting process, data reduction, or renaming is exhibited. The claims remain self-contained as an engineering description without the required evidence of circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
World models.arXiv preprint arXiv:1803.10122, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
Pith/arXiv arXiv 2018
-
[2]
Mastering atari with discrete world models, 2020
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models, 2020
2020
-
[3]
Dreamerv3: Mastering diverse domains through world models, 2023
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Dreamerv3: Mastering diverse domains through world models, 2023
2023
-
[4]
World action models are zero-shot policies, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, et al. World action models are zero-shot policies, 2026
2026
-
[5]
Fast-wam: Do world action models need test-time future imagination?, 2026
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?, 2026
2026
-
[6]
Gigaworld- policy: An efficient action-centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, et al. Gigaworld- policy: An efficient action-centered world–action model, 2026
2026
-
[7]
Cosmos 3: Omnimodal world models for physical ai, 2026
Aditi, Niket Agarwal, Arslan Ali, Jon Allen, et al. Cosmos 3: Omnimodal world models for physical ai, 2026
2026
-
[8]
Dreamdojo: A generalist robot world model from large-scale human videos, 2026
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, et al. Dreamdojo: A generalist robot world model from large-scale human videos, 2026
2026
-
[9]
Causal world modeling for robot control, 2026
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, et al. Causal world modeling for robot control, 2026
2026
-
[10]
Motus: A unified latent action world model, 2025
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, et al. Motus: A unified latent action world model, 2025
2025
-
[11]
Do as i can, not as i say: Grounding language in robotic affordances
Anthony Brohan, Yevgen Chebotar, Chelsea Finn, et al. Do as i can, not as i say: Grounding language in robotic affordances. InConference on Robot Learning, 2023
2023
-
[12]
RT-1: Robotics transformer for real-world control at scale
Anthony Brohan, Noah Brown, Justice Carbajal, et al. RT-1: Robotics transformer for real-world control at scale. InRobotics: Science and Systems, 2023
2023
-
[13]
Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023
2023
-
[14]
Openvla: An open-source vision- language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, et al. Openvla: An open-source vision- language-action model, 2024
2024
-
[15]
Kevin Black, Noah Brown, Danny Driess, et al.π0: A vision-language-action flow model for general robot control, 2024
2024
-
[16]
Physical Intelligence Team.π0.5: A vision-language-action model with open-world generalization, 2025
2025
-
[17]
ABot-M0: VLA foundation model for robotic manipulation with action manifold learning, 2026
Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, et al. ABot-M0: VLA foundation model for robotic manipulation with action manifold learning, 2026
2026
-
[18]
Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation, 2024
Chi-Lam Cheang, Guodong Chen, Yuhang Jing, et al. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation, 2024. 22
2024
-
[19]
Diffusion policy: Visuomotor policy learning via action diffusion, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, et al. Diffusion policy: Visuomotor policy learning via action diffusion, 2023
2023
-
[20]
Planning with diffusion for flexible behavior synthesis
Michael Janner, Yilun Du, Joshua Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InInternational Conference on Machine Learning, 2022
2022
-
[21]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InInternational Conference on Machine Learning, 2023
2023
-
[22]
Learning universal policies via text-guided video generation
Yilun Du, Sherry Yang, Bo Dai, et al. Learning universal policies via text-guided video generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[23]
Video prediction policy: A generalist robot policy with predictive visual representations, 2024
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, et al. Video prediction policy: A generalist robot policy with predictive visual representations, 2024
2024
-
[24]
Robolab: A high-fidelity simulation benchmark for analysis of task generalist policies
Xuning Yang, Rishit Dagli, Alex Zook, Hugo Hadfield, Ankit Goyal, Stan Birchfield, Fabio Ramos, and Jonathan Tremblay. Robolab: A high-fidelity simulation benchmark for analysis of task generalist policies. InRobotics: Science and Systems, 2026
2026
-
[25]
Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, et al. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023
2023
-
[26]
What matters in learning from offline human demonstrations for robot manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, et al. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning, 2021
2021
-
[27]
Wan: Open and advanced large-scale video generative models, 2025
Wan Team. Wan: Open and advanced large-scale video generative models, 2025. 23 A Reproducibility Protocol This appendix records implementation and evaluation details for replication. All settings follow the same experimental boundary as the main text: zero-shot RoboLab manipulation with a frozen Cosmos3-Nano--Policy-DROID policy backbone and trainable EWA...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.