AfriSUD: A Dependency Treebank Collection for Evaluating Models on African Languages
Pith reviewed 2026-06-27 09:31 UTC · model grok-4.3
The pith
AfriSUD treebanks for nine African languages reveal a syntax gap in current NLP models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
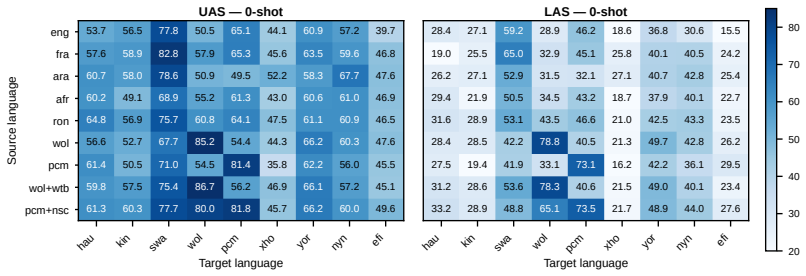
AfriSUD supplies the first large collection of SUD-annotated treebanks for nine typologically diverse African languages, and systematic evaluations on part-of-speech tagging and dependency parsing demonstrate a significant syntax gap in which models fail to capture the structural diversity of African-language syntax.
What carries the argument
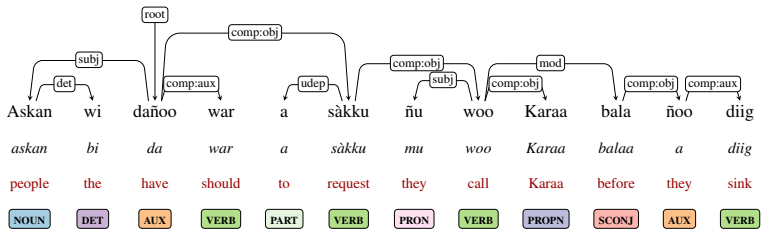
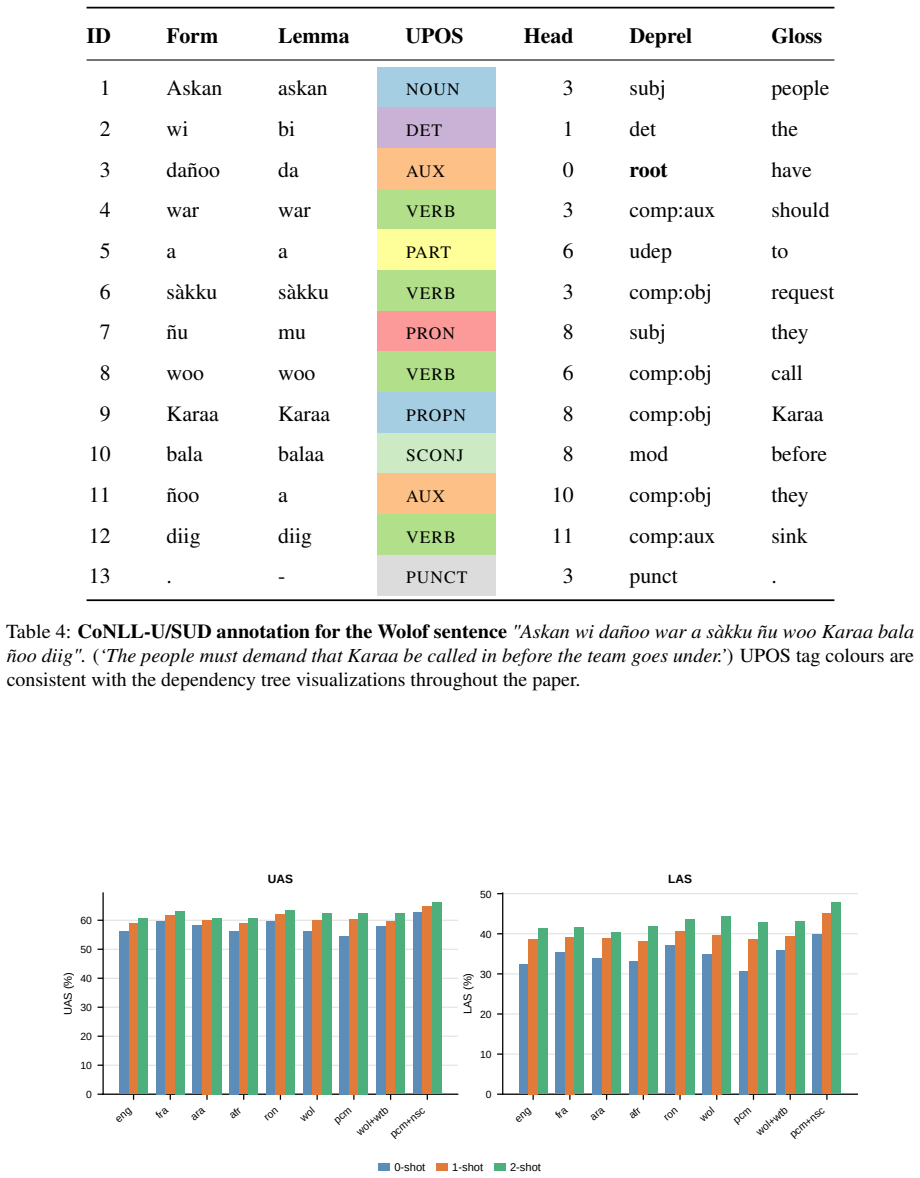
AfriSUD, the collection of Surface-Syntactic Universal Dependencies treebanks for nine African languages that serves as the benchmark for POS tagging and dependency parsing.
If this is right
- Models must improve their handling of agglutinative morphology and tone to reach high accuracy on these languages.
- The syntax gap appears across non-transformer baselines, multilingual encoders, and LLMs alike.
- Native-speaker verified SUD annotations can be produced at scale for previously under-resourced languages.
- The new treebanks provide a concrete testbed for measuring progress toward syntax-aware multilingual systems.
Where Pith is reading between the lines
- Similar treebank collections for additional African languages would test whether the syntax gap is widespread.
- Incorporating explicit morphological analyzers during training could reduce the performance difference on agglutinative structures.
- AfriSUD could serve as a long-term benchmark to track whether new pretraining methods close the gap over successive model generations.
Load-bearing premise
The SUD annotations accurately capture the languages' syntactic structures without artifacts that would explain the observed model limitations.
What would settle it
A model that reaches parsing accuracies on the AfriSUD test sets comparable to those achieved on high-resource languages such as English would show that the syntax gap can be closed with existing data.
Figures


read the original abstract
Despite their linguistic diversity and global significance, African languages remain underrepresented in research and resources to support NLP. We aim to bridge this gap by introducing AfriSUD, the first large-scale collection of syntactically annotated treebanks for nine diverse African languages spanning major language families and regions across Sub-Saharan Africa. Using the Surface-Syntactic Universal Dependencies (SUD) framework, our community-led effort provides high-quality, native-speaker verified data that capture typological key features such as agglutination and tone. We evaluate a range of models on AfriSUD for part-of-speech tagging and dependency parsing including non-transformer baselines, multilingual pretrained encoders, and LLMs. Our results reveal a significant syntax gap, where models still show clear limitations across the nine languages, suggesting that existing architectures may not fully capture the structural diversity of African-language syntax.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AfriSUD, the first large-scale collection of Surface-Syntactic Universal Dependencies (SUD) treebanks for nine African languages spanning major families and regions. It describes a community-led annotation effort producing native-speaker verified data that capture typological features such as agglutination and tone, followed by benchmarking of non-transformer baselines, multilingual pretrained encoders, and LLMs on POS tagging and dependency parsing tasks. The central claim is that the results demonstrate a significant syntax gap, indicating that existing architectures may not fully capture the structural diversity of African-language syntax.
Significance. If the quantitative results and controls hold, the resource would be a valuable addition to low-resource NLP, enabling systematic evaluation of syntactic modeling across typologically diverse languages. The use of the SUD framework and community verification process are strengths that could support reproducible follow-up work.
major comments (2)
- [Abstract] Abstract: The claim that results reveal 'existing architectures may not fully capture the structural diversity of African-language syntax' is load-bearing for the paper's interpretation but is not supported by the described evaluation setup. No controls are mentioned for distinguishing syntax-specific limitations from pretraining data scarcity (e.g., matched comparisons to non-African low-resource UD treebanks or tokenization ablations on agglutinative forms).
- [Abstract] Abstract: The assertion that SUD annotations 'capture typological key features such as agglutination and tone' and are 'native-speaker verified' is central to arguing that observed gaps reflect genuine model limitations rather than annotation artifacts, yet the text provides no details on verification procedures, inter-annotator agreement, or how tone is represented in the SUD surface relations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where the abstract's claims require stronger empirical support and where annotation details need to be made more explicit. We address each point below and commit to revisions that improve the paper without overstating our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that results reveal 'existing architectures may not fully capture the structural diversity of African-language syntax' is load-bearing for the paper's interpretation but is not supported by the described evaluation setup. No controls are mentioned for distinguishing syntax-specific limitations from pretraining data scarcity (e.g., matched comparisons to non-African low-resource UD treebanks or tokenization ablations on agglutinative forms).
Authors: We agree that the current evaluation setup does not include explicit controls such as matched comparisons against non-African low-resource UD treebanks or targeted tokenization ablations. Our benchmarking does span non-transformer baselines, multilingual encoders, and LLMs with differing pretraining exposure, and the performance gap is consistent across these regimes. Nevertheless, this does not fully isolate syntax from data scarcity. We will revise the abstract to moderate the claim and add a new subsection with available cross-lingual comparisons plus tokenization analysis for agglutinative languages. This will be a partial revision, as some additional experiments may be needed. revision: partial
-
Referee: [Abstract] Abstract: The assertion that SUD annotations 'capture typological key features such as agglutination and tone' and are 'native-speaker verified' is central to arguing that observed gaps reflect genuine model limitations rather than annotation artifacts, yet the text provides no details on verification procedures, inter-annotator agreement, or how tone is represented in the SUD surface relations.
Authors: The full manuscript contains a dedicated annotation section describing the community-led process and native-speaker verification. However, the abstract is too terse on these points. We will expand the abstract with a concise statement on verification procedures and inter-annotator agreement, and we will add explicit description of how SUD surface relations encode agglutination (via multi-word token handling) and tone (via dedicated dependency labels where surface syntax reflects tonal distinctions). These details will be cross-referenced to the main text. revision: yes
Circularity Check
No circularity: data release and standard benchmarking
full rationale
The paper introduces AfriSUD treebanks for nine African languages under the SUD framework and reports standard POS tagging and dependency parsing benchmarks on existing models. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the abstract or described content. The central claim of a 'syntax gap' is an interpretive summary of benchmark scores rather than a derivation that reduces to its own inputs by construction. This matches the default expectation for resource + evaluation papers with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 20th International Workshop on Treebanks and Linguistic Theories (TLT, SyntaxFest) , pages=
A morph-based and a word-based treebank for Beja , author=. Proceedings of the 20th International Workshop on Treebanks and Linguistic Theories (TLT, SyntaxFest) , pages=
-
[2]
Proceedings of the Eighth International Conference on Dependency Linguistics (Depling, SyntaxFest) , pages=
A morpheme-based treebank for Gbaya, an Ubanguian language of Central Africa , author=. Proceedings of the Eighth International Conference on Dependency Linguistics (Depling, SyntaxFest) , pages=
-
[3]
Proceedings of the sixth international conference on dependency linguistics (depling, syntaxfest 2021) , pages=
Starting a new treebank? Go SUD! , author=. Proceedings of the sixth international conference on dependency linguistics (depling, syntaxfest 2021) , pages=
2021
-
[4]
and McDonald, Ryan and Petrov, Slav and Pyysalo, Sampo and Silveira, Natalia and Tsarfaty, Reut and Zeman, Daniel
Nivre, Joakim and de Marneffe, Marie-Catherine and Ginter, Filip and Goldberg, Yoav and Haji c , Jan and Manning, Christopher D. and McDonald, Ryan and Petrov, Slav and Pyysalo, Sampo and Silveira, Natalia and Tsarfaty, Reut and Zeman, Daniel. U niversal D ependencies v1: A Multilingual Treebank Collection. Proceedings of the Tenth International Conferenc...
2016
-
[5]
and Pyysalo, Sampo and Schuster, Sebastian and Tyers, Francis and Zeman, Daniel
Nivre, Joakim and de Marneffe, Marie-Catherine and Ginter, Filip and Haji c , Jan and Manning, Christopher D. and Pyysalo, Sampo and Schuster, Sebastian and Tyers, Francis and Zeman, Daniel. U niversal D ependencies v2: An Evergrowing Multilingual Treebank Collection. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[6]
and Adelani, David Ifeoluwa and Klakow, Dietrich
Alabi, Jesujoba Oluwadara and Hedderich, Michael A. and Adelani, David Ifeoluwa and Klakow, Dietrich. Charting the Landscape of A frican NLP : Mapping Progress and Shaping the Road Ahead. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1414
-
[7]
Adelani, David Ifeoluwa and Alabi, Jesujoba Oluwadara and Fan, Angela and Kreutzer, Julia and Shen, Xiaoyu and Reid, Machel and Ruiter, Dana and Klakow, Dietrich and Nabende, Peter and Chang, Ernie and Gwadabe, Tajuddeen and Sackey, Freshia and Dossou, Bonaventure F. P. and Emezue, Chris and Leong, Colin and Beukman, Michael and Muhammad, Shamsuddeen H. a...
-
[8]
Adelani, David Ifeoluwa and Neubig, Graham and Ruder, Sebastian and Rijhwani, Shruti and Beukman, Michael and Palen-Michel, Chester and Lignos, Constantine and Alabi, Jesujoba O. and Muhammad, Shamsuddeen H. and Nabende, Peter and Dione, Cheikh M. Bamba and Bukula, Andiswa and Mabuya, Rooweither and Dossou, Bonaventure F. P. and Sibanda, Blessing and Buza...
-
[9]
Dione, Cheikh M. Bamba and Adelani, David Ifeoluwa and Nabende, Peter and Alabi, Jesujoba and Sindane, Thapelo and Buzaaba, Happy and Muhammad, Shamsuddeen Hassan and Emezue, Chris Chinenye and Ogayo, Perez and Aremu, Anuoluwapo and Gitau, Catherine and Mbaye, Derguene and Mukiibi, Jonathan and Sibanda, Blessing and Dossou, Bonaventure F. P. and Bukula, A...
-
[10]
Proceedings of the Third Workshop on Universal Dependencies (UDW, SyntaxFest 2019) , pages=
Developing universal dependencies for wolof , author=. Proceedings of the Third Workshop on Universal Dependencies (UDW, SyntaxFest 2019) , pages=
2019
-
[11]
Y or \`u b \'a Dependency Treebank ( YTB )
Ishola, Ol \'a j \'i d \'e and Zeman, Daniel. Y or \`u b \'a Dependency Treebank ( YTB ). Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[12]
Towards a dependency-annotated treebank for B ambara
Aplonova, Ekaterina and Tyers, Francis M. Towards a dependency-annotated treebank for B ambara. Proceedings of the 16th International Workshop on Treebanks and Linguistic Theories. 2017
2017
-
[13]
U niversal D ependencies for A mharic
Seyoum, Binyam Ephrem and Miyao, Yusuke and Mekonnen, Baye Yimam. U niversal D ependencies for A mharic. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[14]
A Surface-Syntactic UD Treebank for N aija
Caron, Bernard and Courtin, Marine and Gerdes, Kim and Kahane, Sylvain. A Surface-Syntactic UD Treebank for N aija. Proceedings of the 18th International Workshop on Treebanks and Linguistic Theories (TLT, SyntaxFest 2019). 2019. doi:10.18653/v1/W19-7803
-
[15]
arXiv preprint arXiv:2003.11529 , year=
Masakhane--machine translation for Africa , author=. arXiv preprint arXiv:2003.11529 , year=
arXiv 2003
-
[16]
SUD or Surface-Syntactic U niversal D ependencies: An annotation scheme near-isomorphic to UD
Gerdes, Kim and Guillaume, Bruno and Kahane, Sylvain and Perrier, Guy. SUD or Surface-Syntactic U niversal D ependencies: An annotation scheme near-isomorphic to UD. Proceedings of the Second Workshop on Universal Dependencies ( UDW 2018). 2018. doi:10.18653/v1/W18-6008
-
[17]
The Bantu Languages , pages=
Towards a historical classification of the Bantu languages , author=. The Bantu Languages , pages=. 2003 , publisher=
2003
-
[18]
2006 , publisher=
Archaeology, language, and the African past , author=. 2006 , publisher=
2006
-
[19]
Journal of African Languages and Linguistics , volume=
Noun classes and grammatical gender in Wolof , author=. Journal of African Languages and Linguistics , volume=. 2016 , publisher=
2016
-
[20]
The bantu languages , volume=
Bantu nominal morphology , author=. The bantu languages , volume=
-
[21]
Adelani, David Ifeoluwa and Abbott, Jade and Neubig, Graham and D ' souza, Daniel and Kreutzer, Julia and Lignos, Constantine and Palen-Michel, Chester and Buzaaba, Happy and Rijhwani, Shruti and Ruder, Sebastian and Mayhew, Stephen and Azime, Israel Abebe and Muhammad, Shamsuddeen H. and Emezue, Chris Chinenye and Nakatumba-Nabende, Joyce and Ogayo, Pere...
-
[22]
Ogueji, Kelechi and Zhu, Yuxin and Lin, Jimmy. Small Data? No Problem! Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages. Proceedings of the 1st Workshop on Multilingual Representation Learning. 2021. doi:10.18653/v1/2021.mrl-1.11
-
[23]
Towards Afrocentric NLP for A frican Languages: Where We Are and Where We Can Go
Adebara, Ife and Abdul-Mageed, Muhammad. Towards Afrocentric NLP for A frican Languages: Where We Are and Where We Can Go. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.265
-
[24]
A Universal Part-of-Speech Tagset
Petrov, Slav and Das, Dipanjan and McDonald, Ryan. A Universal Part-of-Speech Tagset. Proceedings of the Eighth International Conference on Language Resources and Evaluation ( LREC '12). 2012
2012
-
[25]
Proceedings of the second international conference on dependency linguistics (DepLing 2013) , pages=
Collaborative dependency annotation , author=. Proceedings of the second international conference on dependency linguistics (DepLing 2013) , pages=
2013
-
[26]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[27]
Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm \'a n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin. Unsupervised Cross-lingual Representation Learning at Scale. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. ...
-
[28]
International Conference on Learning Representations , year=
Rethinking Embedding Coupling in Pre-trained Language Models , author=. International Conference on Learning Representations , year=
-
[29]
and Adelani, David Ifeoluwa and Mosbach, Marius and Klakow, Dietrich
Alabi, Jesujoba O. and Adelani, David Ifeoluwa and Mosbach, Marius and Klakow, Dietrich. Adapting Pre-trained Language Models to A frican Languages via Multilingual Adaptive Fine-Tuning. Proceedings of the 29th International Conference on Computational Linguistics. 2022
2022
-
[30]
ArXiv , year=
AfroLM: A Self-Active Learning-based Multilingual Pretrained Language Model for 23 African Languages , author=. ArXiv , year=
-
[31]
Zero-shot Dependency Parsing with Pre-trained Multilingual Sentence Representations
Tran, Ke and Bisazza, Arianna. Zero-shot Dependency Parsing with Pre-trained Multilingual Sentence Representations. Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019). 2019. doi:10.18653/v1/D19-6132
-
[32]
Cross-Lingual Parser Selection for Low-Resource Languages
Agi \'c , Z eljko. Cross-Lingual Parser Selection for Low-Resource Languages. Proceedings of the N o D a L i D a 2017 Workshop on Universal Dependencies ( UDW 2017). 2017
2017
-
[33]
Cross-lingual Transfer for Unsupervised Dependency Parsing Without Parallel Data
Duong, Long and Cohn, Trevor and Bird, Steven and Cook, Paul. Cross-lingual Transfer for Unsupervised Dependency Parsing Without Parallel Data. Proceedings of the Nineteenth Conference on Computational Natural Language Learning. 2015. doi:10.18653/v1/K15-1012
-
[34]
Towards Instance-Level Parser Selection for Cross-Lingual Transfer of Dependency Parsers
Litschko, Robert and Vuli \'c , Ivan and Agi \'c , Z eljko and Glava s , Goran. Towards Instance-Level Parser Selection for Cross-Lingual Transfer of Dependency Parsers. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.345
-
[35]
Working Hard or Hardly Working: Challenges of Integrating Typology into Neural Dependency Parsers
Fisch, Adam and Guo, Jiang and Barzilay, Regina. Working Hard or Hardly Working: Challenges of Integrating Typology into Neural Dependency Parsers. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1574
-
[36]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[37]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[38]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[39]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[40]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[41]
arXiv preprint arXiv:1611.01734 , year=
Deep biaffine attention for neural dependency parsing , author=. arXiv preprint arXiv:1611.01734 , year=
-
[42]
and Lin, Ke and Kairis, Katherine and Turner, Carlisle and Levin, Lori
Littell, Patrick and Mortensen, David R. and Lin, Ke and Kairis, Katherine and Turner, Carlisle and Levin, Lori. URIEL and lang2vec: Representing languages as typological, geographical, and phylogenetic vectors. Proceedings of the 15th Conference of the E uropean Chapter of the Association for Computational Linguistics: Volume 2, Short Papers. 2017
2017
-
[43]
Choosing Transfer Languages for Cross-Lingual Learning
Lin, Yu-Hsiang and Chen, Chian-Yu and Lee, Jean and Li, Zirui and Zhang, Yuyan and Xia, Mengzhou and Rijhwani, Shruti and He, Junxian and Zhang, Zhisong and Ma, Xuezhe and Anastasopoulos, Antonios and Littell, Patrick and Neubig, Graham. Choosing Transfer Languages for Cross-Lingual Learning. Proceedings of the 57th Annual Meeting of the Association for C...
-
[44]
Lauscher, Anne and Ravishankar, Vinit and Vuli \'c , Ivan and Glava s , Goran. From Zero to Hero: O n the Limitations of Zero-Shot Language Transfer with Multilingual T ransformers. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.363
-
[45]
doi: 10.18653/v1/2020.emnlp-demos.6
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[46]
Qi, Peng and Zhang, Yuhao and Zhang, Yuhui and Bolton, Jason and Manning, Christopher D. S tanza: A Python Natural Language Processing Toolkit for Many Human Languages. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2020. doi:10.18653/v1/2020.acl-demos.14
-
[47]
biometrics , pages=
The measurement of observer agreement for categorical data , author=. biometrics , pages=. 1977 , publisher=
1977
-
[48]
Ammar, Waleed and Mulcaire, George and Ballesteros, Miguel and Dyer, Chris and Smith, Noah A. Many Languages, One Parser. Transactions of the Association for Computational Linguistics. 2016. doi:10.1162/tacl_a_00109
-
[49]
An Improved Neural Network Model for Joint POS Tagging and Dependency Parsing
Nguyen, Dat Quoc and Verspoor, Karin. An Improved Neural Network Model for Joint POS Tagging and Dependency Parsing. Proceedings of the C o NLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies. 2018. doi:10.18653/v1/K18-2008
-
[50]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
CSSL: Contrastive Self-Supervised Learning for Dependency Parsing on Relatively Free-Word-Ordered and Morphologically-Rich Low-Resource Languages , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
2024
-
[51]
Ibom NLP : A Step Toward Inclusive Natural Language Processing for N igeria ' s Minority Languages
Kalejaiye, Oluwadara and Beyene, Luel Hagos and Adelani, David Ifeoluwa and Edet, Mmekut-mfon Gabriel and Akpan, Aniefon Daniel and Urua, Eno-Abasi and Andy, Anietie. Ibom NLP : A Step Toward Inclusive Natural Language Processing for N igeria ' s Minority Languages. Proceedings of the 14th International Joint Conference on Natural Language Processing and ...
-
[52]
Many-to- E nglish Machine Translation Tools, Data, and Pretrained Models
Gowda, Thamme and Zhang, Zhao and Mattmann, Chris and May, Jonathan. Many-to- E nglish Machine Translation Tools, Data, and Pretrained Models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations. 2021. doi:10.18653/v1/2021....
-
[53]
3rd Workshop on African Natural Language Processing , year=
Machine translation for african languages: Community creation of datasets and models in uganda , author=. 3rd Workshop on African Natural Language Processing , year=
-
[54]
Proceedings of the 18th International Workshop on Treebanks and Linguistic Theories (TLT, SyntaxFest 2019) , pages=
A surface-syntactic UD treebank for Naija , author=. Proceedings of the 18th International Workshop on Treebanks and Linguistic Theories (TLT, SyntaxFest 2019) , pages=
2019
-
[55]
U niversal D ependencies Treebank for K hoekhoe ( KDT )
Tulchynska, Kira and Job, Sylvanus and Witzlack-Makarevich, Alena. U niversal D ependencies Treebank for K hoekhoe ( KDT ). Proceedings of the Eighth Workshop on Universal Dependencies (UDW, SyntaxFest 2025). 2025
2025
-
[56]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Syntax-aware data augmentation for neural machine translation , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2023 , publisher=
2023
-
[57]
arXiv preprint arXiv:2305.17698 , year=
Neural machine translation with dynamic graph convolutional decoder , author=. arXiv preprint arXiv:2305.17698 , year=
-
[58]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Dependency Parsing-Based Syntactic Enhancement of Relation Extraction in Scientific Texts , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[59]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Constructing code-mixed universal dependency forest for unbiased cross-lingual relation extraction , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[60]
I roko B ench: A New Benchmark for A frican Languages in the Age of Large Language Models
Adelani, David Ifeoluwa and Ojo, Jessica and Azime, Israel Abebe and Zhuang, Jian Yun and Alabi, Jesujoba Oluwadara and He, Xuanli and Ochieng, Millicent and Hooker, Sara and Bukula, Andiswa and Lee, En-Shiun Annie and Chukwuneke, Chiamaka Ijeoma and Buzaaba, Happy and Sibanda, Blessing Kudzaishe and Kalipe, Godson Koffi and Mukiibi, Jonathan and Kabongo ...
-
[61]
INJONGO : A Multicultural Intent Detection and Slot-filling Dataset for 16 A frican Languages
Yu, Hao and Alabi, Jesujoba Oluwadara and Bukula, Andiswa and Zhuang, Jian Yun and Lee, En-Shiun Annie and Guge, Tadesse Kebede and Azime, Israel Abebe and Buzaaba, Happy and Sibanda, Blessing Kudzaishe and Kalipe, Godson Koffi and Mukiibi, Jonathan and Kabongo Kabenamualu, Salomon and Setaka, Mmasibidi and Ndolela, Lolwethu and Odu, Nkiruka and Mabuya, R...
-
[62]
arXiv preprint arXiv:2504.06536 , year=
Lugha-Llama: Adapting Large Language Models for African Languages , author=. arXiv preprint arXiv:2504.06536 , year=
-
[63]
arXiv preprint arXiv:2601.06395 , year=
AfriqueLLM: How Data Mixing and Model Architecture Impact Continued Pre-training for African Languages , author=. arXiv preprint arXiv:2601.06395 , year=
-
[64]
When Collaborative Treebank Curation Meets Graph Grammars
Guibon, Ga. When Collaborative Treebank Curation Meets Graph Grammars. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[65]
2020 , type =
Guiller, Kirian , title =. 2020 , type =
2020
-
[66]
and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie
Adelani, David Ifeoluwa and Liu, Hannah and Shen, Xiaoyu and Vassilyev, Nikita and Alabi, Jesujoba O. and Mao, Yanke and Gao, Haonan and Lee, En-Shiun Annie. SIB -200: A Simple, Inclusive, and Big Evaluation Dataset for Topic Classification in 200+ Languages and Dialects. Proceedings of the 18th Conference of the European Chapter of the Association for Co...
-
[67]
Learning Word Vectors for 157 Languages
Grave, Edouard and Bojanowski, Piotr and Gupta, Prakhar and Joulin, Armand and Mikolov, Tomas. Learning Word Vectors for 157 Languages. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[68]
2026 , month =
Gemini 3.1 Pro: Technical Report and Model Card , institution =. 2026 , month =
2026
-
[69]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[70]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[71]
Cross-Lingual Dependency Parsing by POS -Guided Word Reordering
Liu, Lu and Zhou, Yi and Xu, Jianhan and Zheng, Xiaoqing and Chang, Kai-Wei and Huang, Xuanjing. Cross-Lingual Dependency Parsing by POS -Guided Word Reordering. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.265
-
[72]
Typological Features for Multilingual Delexicalised Dependency Parsing
Scholivet, Manon and Dary, Franck and Nasr, Alexis and Favre, Benoit and Ramisch, Carlos. Typological Features for Multilingual Delexicalised Dependency Parsing. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.186...
-
[73]
and Adebonojo, Damilola and Ayeni, Adesina and Adeyemi, Mofe and Awokoya, Ayodele Esther and Espa \ n a-Bonet, Cristina
Adelani, David Ifeoluwa and Ruiter, Dana and Alabi, Jesujoba O. and Adebonojo, Damilola and Ayeni, Adesina and Adeyemi, Mofe and Awokoya, Ayodele Esther and Espa \ n a-Bonet, Cristina. The Effect of Domain and Diacritics in Y oruba -- E nglish Neural Machine Translation. Proceedings of Machine Translation Summit XVIII: Research Track. 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.