How Fine-Grained Should a RAG Benchmark Be? A Hierarchical Framework for Synthetic Question Generation
Pith reviewed 2026-06-27 07:10 UTC · model grok-4.3
The pith
A hierarchical framework finds that optimal RAG benchmark granularity varies by dimension rather than staying fixed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
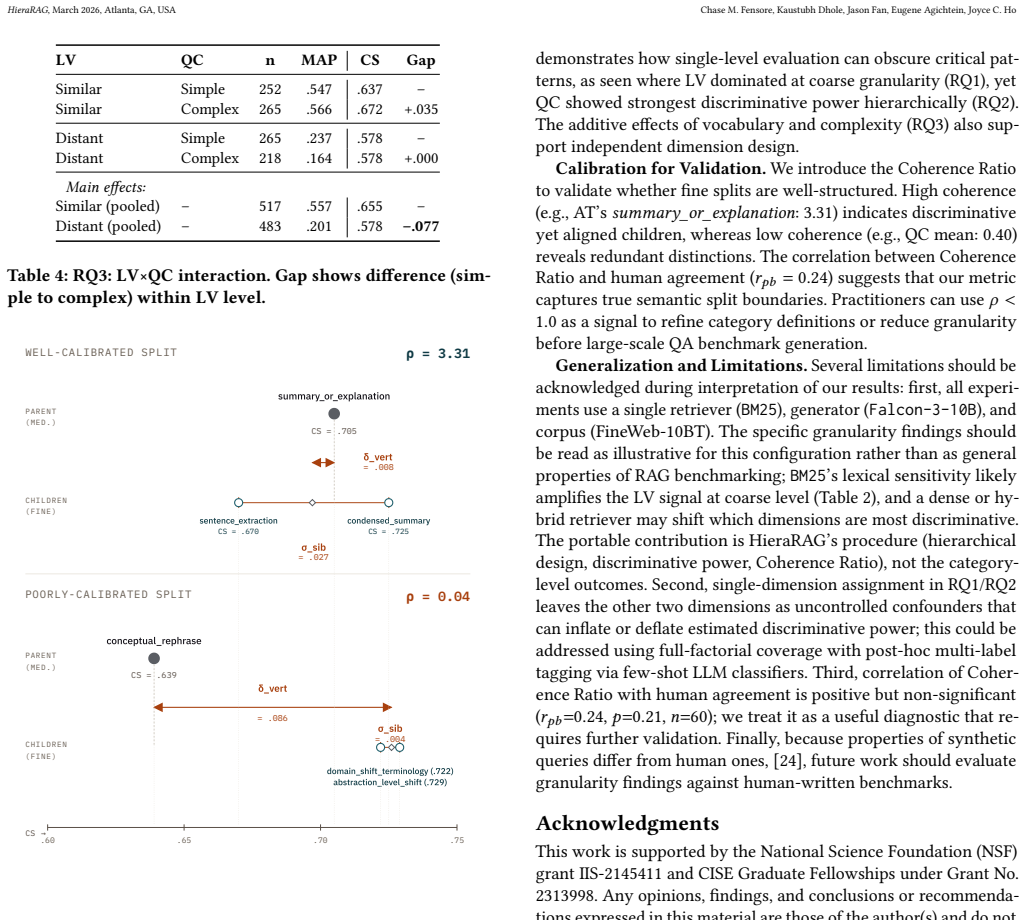
HieraRAG defines optimal granularity as the category count that maximizes the standard deviation of generation quality across categories inside one fixed RAG configuration. On 5,872 synthetic pairs drawn from FineWeb-10BT, question complexity shows peak discriminative power of 0.053 at the eight-category level, whereas answer type and linguistic variation both peak at the four-category level. The introduced Coherence Ratio of 0.40 for complexity versus 1.44 for answer type indicates that fine splits subdivide parent categories cleanly in some dimensions but not others. Human review of 110 stratified pairs supports the quality of the synthetic data.
What carries the argument
HieraRAG, the procedure that generates questions at multiple granularity levels and selects the level maximizing standard deviation of quality scores within a chosen RAG pipeline.
If this is right
- Benchmark designers should test multiple granularity levels per dimension instead of adopting a single fixed split.
- The Coherence Ratio supplies an independent check on whether fine categories form meaningful subdivisions of coarser ones.
- The same generation-plus-scoring loop can be repeated on any new RAG configuration to obtain its own optimal levels.
- Synthetic data at controlled granularity levels makes it possible to isolate the effect of question properties on measured RAG performance.
Where Pith is reading between the lines
- If optimal levels turn out to be strongly configuration-dependent, then shared public benchmarks may need to publish their granularity choices alongside the questions.
- The framework could be applied to additional dimensions such as multi-hop reasoning or domain specificity to test whether the pattern of varying optima generalizes.
- A natural next measurement would be whether the granularity chosen by this method also improves correlation with human preference rankings of RAG outputs.
Load-bearing premise
That the standard deviation of generation quality across categories within one RAG pipeline is the right quantity for deciding which granularity level is optimal.
What would settle it
Re-running the full generation and scoring pipeline on the same questions but with a different retriever or generator and checking whether the category count that maximizes the standard deviation stays the same or shifts.
Figures

read the original abstract
Evaluating retrieval-augmented generation (RAG) systems requires benchmarks that capture diverse question characteristics, yet practitioners lack empirical guidance on which dimensions to vary and at what granularity. We present HieraRAG, a hierarchical framework for studying granularity in RAG benchmark construction, defining optimal granularity as the level that maximizes discriminative power (the standard deviation of generation quality across categories) within a given RAG configuration. As a case study, we generate 5,872 synthetic question-answer (QA) pairs from FineWeb-10BT across 3 dimensions (Question Complexity, Answer Type, Linguistic Variation) at 3 granularity levels (2, 4, and 8 categories). With a BM25+Falcon-3-10B pipeline, optimal granularity varies by dimension: complexity benefits from fine-grained distinctions (discriminative power: 0.053) while answer type and linguistic variation peak at medium granularity. We introduce a Coherence Ratio metric to quantify whether fine-grained splits cleanly subdivide parent categories, revealing structural differences across dimensions (Question Complexity: 0.40 vs. Answer Type: 1.44). Human evaluation of 110 stratified QA pairs confirms synthetic quality. While these specific findings reflect a single configuration, HieraRAG provides a portable procedure and validation metric for practitioners to determine evaluation granularity within their own RAG settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HieraRAG, a hierarchical framework for studying granularity in RAG benchmark construction. It defines optimal granularity as the level maximizing discriminative power, measured as the standard deviation of RAG generation quality across categories within a configuration. As a case study, it generates 5,872 synthetic QA pairs from FineWeb-10BT across three dimensions (Question Complexity, Answer Type, Linguistic Variation) at three granularity levels (2/4/8 categories), evaluates them with a BM25+Falcon-3-10B pipeline, reports dimension-specific optima (fine-grained for complexity with discriminative power 0.053; medium for the other two), introduces a Coherence Ratio metric (values 0.40 vs. 1.44), and validates synthetic quality via human evaluation of 110 stratified pairs.
Significance. If the central empirical claim holds after correction, the work supplies a portable, replicable procedure and an auxiliary Coherence Ratio for practitioners to select evaluation granularity in their own RAG settings. The dimension-specific pattern, if robust, would be a useful empirical observation for benchmark design; the human validation and scale of the synthetic corpus are positive features.
major comments (1)
- [Definition of discriminative power (abstract and case-study metric)] Definition of discriminative power (abstract and the case-study section describing the metric): optimal granularity is selected by maximizing the raw standard deviation of generation quality across categories, yet the number of categories differs across levels (2 vs. 4 vs. 8). No normalization (e.g., division by sqrt(k), by the observed range, or by a null-model expectation) is described. Consequently the reported 0.053 value favoring the 8-category level for Question Complexity, and the medium-level peaks for the other dimensions, may be artifacts of unequal sample sizes rather than structural differences; this directly undermines the central claim that optimal granularity varies by dimension.
minor comments (2)
- The abstract states 5,872 pairs but the methods description should explicitly report any data exclusion criteria, per-category counts after filtering, and whether error bars or confidence intervals accompany the reported discriminative-power and Coherence Ratio values.
- Table or figure presenting the per-dimension, per-level quality scores and standard deviations would improve readability and allow readers to verify the unnormalized comparison.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a substantive methodological concern with the discriminative power metric. We agree that the lack of normalization for differing numbers of categories is a limitation that requires correction to support the central claim.
read point-by-point responses
-
Referee: [Definition of discriminative power (abstract and case-study metric)] Definition of discriminative power (abstract and the case-study section describing the metric): optimal granularity is selected by maximizing the raw standard deviation of generation quality across categories, yet the number of categories differs across levels (2 vs. 4 vs 8). No normalization (e.g., division by sqrt(k), by the observed range, or by a null-model expectation) is described. Consequently the reported 0.053 value favoring the 8-category level for Question Complexity, and the medium-level peaks for the other dimensions, may be artifacts of unequal sample sizes rather than structural differences; this directly undermines the central claim that optimal granularity varies by dimension.
Authors: We acknowledge the validity of this observation. The manuscript defines discriminative power strictly as the raw standard deviation without any adjustment for the number of categories (k=2,4,8), which can indeed inflate values for finer partitions even under a null model. In the revision we will (1) introduce a normalized variant of the metric (standard deviation divided by sqrt(k), with an alternative using the observed range also reported), (2) recompute all optimal-granularity conclusions under the normalized metric, and (3) present both the original and normalized results side-by-side with a brief discussion of when each may be appropriate. This change will be reflected in the abstract, the metric definition section, the case-study results, and the conclusions. revision: yes
Circularity Check
No circularity: empirical definition of optimality via direct std-dev computation on generated data
full rationale
The paper explicitly defines 'optimal granularity' as the level maximizing 'discriminative power' (standard deviation of generation quality across categories) and reports the argmax per dimension after generating 5,872 QA pairs. This is a straightforward empirical procedure with no equations that reduce the reported optimum to a fitted parameter defined in terms of itself, no self-citation load-bearing premises, and no ansatz or uniqueness claims imported from prior work. The Coherence Ratio is introduced as a new metric without circular reduction. The approach is self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (2)
- granularity levels
- synthetic QA count =
5872
axioms (1)
- domain assumption Discriminative power defined as standard deviation of generation quality across categories is the correct measure of optimal granularity.
Reference graph
Works this paper leans on
-
[1]
Bruce Croft, and Mark Sanderson
Valeriia Bolotova, Vladislav Blinov, Falk Scholer, W. Bruce Croft, and Mark Sanderson. 2022. A Non-Factoid Question-Answering Taxonomy. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 1196–1207. doi:10.1145/3477495.3531926
-
[2]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. 2024. Benchmarking large language models in retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 17754–17762
2024
-
[3]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. RAGAs: Automated Evaluation of Retrieval Augmented Generation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. 150–158
2024
-
[4]
Simone Filice, Guy Horowitz, David Carmel, Zohar Karnin, Liane Lewin-Eytan, and Yoelle Maarek. 2025. Generating Diverse Q&A Benchmarks for RAG Evalua- tion with DataMorgana. arXiv:2501.12789 [cs] doi:10.48550/arXiv.2501.12789
-
[5]
Manish Gupta and Michael Bendersky. 2015. Information Retrieval with Verbose Queries.Foundations and Trends in Information Retrieval9, 3-4 (2015), 209–354. 5 HieraRAG, March 2026, Atlanta, GA, USA Chase M. Fensore, Kaustubh Dhole, Jason Fan, Eugene Agichtein, Joyce C. Ho
2015
-
[6]
Jeffrey Ip and Kritin Vongthongsri. 2025. deepeval. https://github.com/confident- ai/deepeval original-date: 2023-08-10T05:35:04Z
2025
-
[7]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research.Tr...
-
[8]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[9]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. InText summarization branches out. 74–81
2004
-
[10]
Wanlong Liu, Junying Chen, Ke Ji, Li Zhou, Wenyu Chen, and Benyou Wang
-
[11]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Rag-instruct: Boosting llms with diverse retrieval-augmented instructions. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 3865–3888
2025
-
[12]
Craig Macdonald, Nicola Tonellotto, Sean MacAvaney, and Iadh Ounis. 2021. PyTerrier: Declarative experimentation in Python from BM25 to dense retrieval. InProceedings of the 30th acm international conference on information & knowledge management. 4526–4533
2021
-
[13]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
2002
-
[14]
Guilherme Penedo, Hynek Kydlíček, Anton Lozhkov, Margaret Mitchell, Colin A Raffel, Leandro Von Werra, Thomas Wolf, et al . 2024. The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems37 (2024), 30811–30849
2024
-
[15]
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, Vassilis Plachouras, Tim Rocktäschel, and Sebastian Riedel. 2021. KILT: a Bench- mark for Knowledge Intensive Language Tasks. doi:10.48550/arXiv.2009.02252 arXiv:2009.02252 [cs]
-
[16]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, 3982
2019
-
[17]
Peter J Rousseeuw. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics 20 (1987), 53–65
1987
-
[18]
Falcon-LLM Team. 2024. The Falcon 3 Family of Open Models. https: //huggingface.co/blog/falcon3
2024
-
[19]
Nguyen Xuan Vinh, Julien Epps, and James Bailey. 2010. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance.Journal of Machine Learning Research11 (2010), 2837–2854
2010
-
[20]
Voorhees and D
Ellen M. Voorhees and D. M. Tice. 2000. The TREC-8 Question Answering Track Evaluation.NIST3 (May 2000). https://www.nist.gov/publications/trec- 8-question-answering-track-evaluation Last Modified: 2017-02-17T13:34-05:00 Publisher: Ellen M. Voorhees, D M. Tice
2000
-
[21]
QianYing Wang, Clifford Nass, and Jiang Hu. 2005. Natural language query vs. keyword search: Effects of task complexity on search performance, participant perceptions, and preferences. InIFIP Conference on Human-Computer Interaction. Springer, 106–116
2005
-
[22]
Zhichao Wang, Bin Bi, Yanqi Luo, Sitaram Asur, and Claire Na Cheng. 2025. Diversity Enhances an LLM’s Performance in RAG and Long-context Task.arXiv preprint arXiv:2502.09017(2025)
arXiv 2025
-
[23]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. doi:10.48550/arXiv.1809. 09600 arXiv:1809.09600 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1809 2018
-
[24]
Gal Yona, Roee Aharoni, and Mor Geva. 2024. Narrowing the Knowledge Evalu- ation Gap: Open-Domain Question Answering with Multi-Granularity Answers. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguisti...
-
[25]
Oleg Zendel, Sara Fahad Dawood Al Lawati, Lida Rashidi, Falk Scholer, and Mark Sanderson. 2025. A Comparative Analysis of Linguistic and Retrieval Diversity in LLM-Generated Search Queries. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 4014–4023. 6
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.