Magnifying What Matters: Attention-Guided Adaptive Rendering for Visual Text Comprehension
Pith reviewed 2026-06-27 07:38 UTC · model grok-4.3
The pith
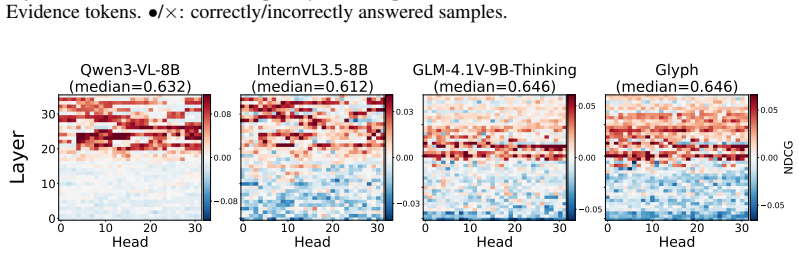
VLMs localize evidence in middle-to-late layers but largely fail to use it, and enlarging those text spans on the page recovers many failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLMs exhibit a localization-without-utilization regime: evidence-localizing attention emerges sharply in the middle-to-late layers and is largely decoupled from answer correctness, yet simply enlarging the localized spans on the rendered page recovers a large fraction of the failures.
What carries the argument
AGAR (Attention-Guided Adaptive Rendering), which uses a VLM's middle-to-late layer attention to select top-K visual patches, maps them to word spans, and re-renders the page with those spans enlarged before re-inference.
If this is right
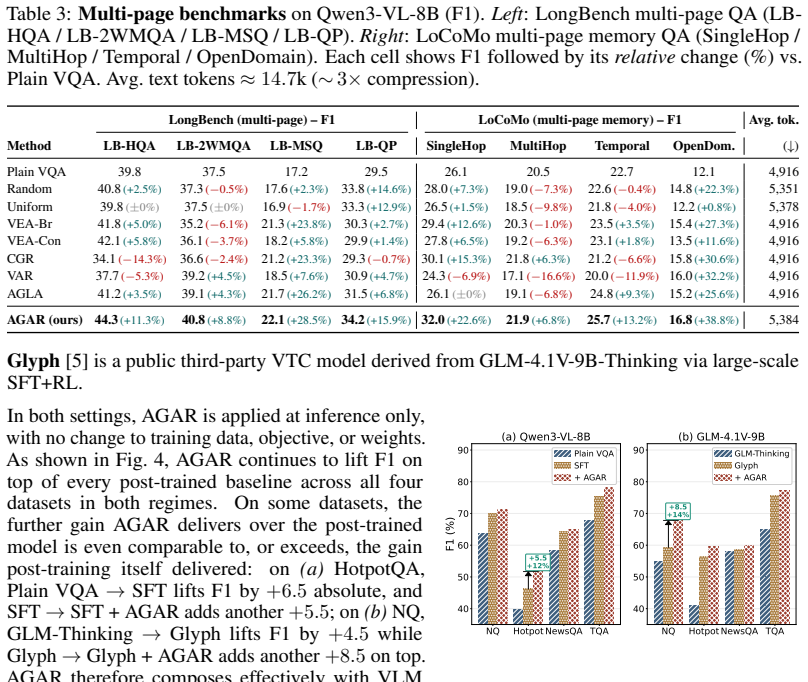
- AGAR improves off-the-shelf VLMs on short-form, long-context, and multi-page memory QA tasks as a plug-and-play addition.
- The method composes with existing VLM post-training to produce additional performance gains.
- Performance remains stable when either the visual or text-side inputs are degraded.
- The approach works across four different VLM backbones without requiring model-specific retraining.
Where Pith is reading between the lines
- The same attention-guided enlargement principle could be tested on other multimodal tasks that convert structured data into images.
- If attention localization proves consistent across tasks, it might enable dynamic page layouts that adapt rendering density to model needs rather than fixed rules.
- Selective re-rendering based on attention could reduce the compute cost of processing long documents by focusing enlargement only on high-value regions.
Load-bearing premise
Attention maps from middle-to-late layers reliably identify word spans whose enlargement will improve answer correctness across models and tasks without negative side effects from re-rendering.
What would settle it
An experiment on VTC QA tasks in which attention-identified spans are enlarged yet answer accuracy shows no improvement over the unmodified rendering baseline.
Figures




















read the original abstract
Visual Text Comprehension (VTC) renders text into images for a vision-language model (VLM) to read, sidestepping LLM context-window limits and powering applications from long-page OCR to multi-page memory QA. Yet existing VTC pipelines treat rendering and layout as a fixed, content-agnostic preprocessing step and offer little mechanistic understanding of how VLMs internally process visualized text. Through a focused empirical study on VTC QA tasks, we reveal that VLMs exhibit a localization-without-utilization regime: evidence-localizing attention emerges sharply in the middle-to-late layers and is largely decoupled from answer correctness, yet simply enlarging the localized spans on the rendered page recovers a large fraction of the failures. Building on these observations, we propose AGAR (Attention-Guided Adaptive Rendering), a training-free, model-agnostic method that leverages a VLM's own middle-to-late layer attention to identify the top-K important visual patches, maps them back to word spans, and re-renders the page with those spans enlarged before re-inferring the answer. Extensive experiments across nine VTC benchmarks (short-form, long-context, and multi-page memory QA) and four VLM backbones show that AGAR (i)consistently improves off-the-shelf VLMs as a plug-and-play enhancement, (ii)composes with VLM post-training to yield further gains, and (iii)remains robust under both visual- and text-side input degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs processing visualized text in VTC tasks exhibit a localization-without-utilization regime, in which middle-to-late layer attention sharply localizes evidence spans yet remains largely decoupled from answer correctness; simply enlarging those spans on the rendered page recovers a substantial fraction of failures. Building on this, the authors introduce AGAR, a training-free and model-agnostic method that extracts top-K important patches from a VLM's own middle-to-late attention, maps them back to word spans, re-renders the page with those spans enlarged, and re-infers the answer. Experiments across nine VTC benchmarks (short-form, long-context, multi-page memory QA) and four backbones demonstrate consistent plug-and-play gains, composability with post-training, and robustness to input degradation.
Significance. If the empirical findings hold, the work supplies a concrete mechanistic observation about VLM attention dynamics on rendered text together with a practical, zero-parameter enhancement that requires no retraining. The training-free, model-agnostic character of AGAR and its reported composability with existing post-training pipelines are notable strengths; the breadth of evaluation (nine benchmarks, four backbones, degradation tests) further strengthens the case that the localization-without-utilization regime is actionable.
major comments (2)
- [Section 3 / empirical study] The central claim that middle-to-late attention is 'largely decoupled from answer correctness' is load-bearing for both the regime diagnosis and the motivation for AGAR; the manuscript must specify exactly how this decoupling is quantified (e.g., correlation between attention mass on ground-truth spans and final accuracy, or layer-wise accuracy when attention is masked).
- [Section 4 / AGAR method] The mapping from attention patches back to word spans (and the subsequent enlargement) is the operational core of AGAR; the paper should report the precise procedure (thresholding, top-K selection, span merging rules) and any sensitivity analysis, because small changes in this step could alter whether enlargement truly targets evidence or merely increases text size indiscriminately.
minor comments (2)
- [Abstract / results] The abstract states that AGAR 'recovers a large fraction of the failures'; the main text should give the exact recovery percentages per benchmark and backbone so readers can judge the practical magnitude.
- [Section 4] Notation for attention layers and patch-to-span mapping should be introduced once with a clear diagram or pseudocode; repeated informal descriptions make the method harder to re-implement.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The two major comments identify areas where additional precision will strengthen the manuscript; we address each below and will incorporate the requested details in the revised version.
read point-by-point responses
-
Referee: [Section 3 / empirical study] The central claim that middle-to-late attention is 'largely decoupled from answer correctness' is load-bearing for both the regime diagnosis and the motivation for AGAR; the manuscript must specify exactly how this decoupling is quantified (e.g., correlation between attention mass on ground-truth spans and final accuracy, or layer-wise accuracy when attention is masked).
Authors: We agree that an explicit quantitative definition is required. The original manuscript supports the claim via layer-wise attention visualizations and the performance recovery obtained by enlarging the attended spans, but does not report a numeric correlation or masking experiment. In the revision we will add, in Section 3, (i) the Pearson correlation between per-layer attention mass on ground-truth evidence spans and final answer accuracy across the evaluated benchmarks, and (ii) the drop in accuracy when attention to those spans is masked at each layer. These metrics will be presented alongside the existing visualizations. revision: yes
-
Referee: [Section 4 / AGAR method] The mapping from attention patches back to word spans (and the subsequent enlargement) is the operational core of AGAR; the paper should report the precise procedure (thresholding, top-K selection, span merging rules) and any sensitivity analysis, because small changes in this step could alter whether enlargement truly targets evidence or merely increases text size indiscriminately.
Authors: We accept the point. The current text describes the mapping at a high level but omits the exact algorithmic steps and robustness checks. The revised manuscript will state the procedure explicitly: patches are ranked by mean attention score; the top-K (K=5 default) patches whose bounding boxes overlap an OCR word box by IoU > 0.7 are retained; consecutive words are merged into spans; each span is enlarged by a fixed factor of 1.5 while preserving layout. A sensitivity study varying K ∈ {3,5,10} and enlargement factor ∈ {1.2,1.5,2.0} will be added to the appendix, confirming that gains remain stable within this range and that indiscriminate enlargement (random spans) yields substantially smaller improvements. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper conducts an empirical layer-wise attention analysis on VTC QA tasks to identify the localization-without-utilization regime, then defines AGAR as a direct, training-free application of the same middle-to-late attention maps to select and enlarge word spans before re-inference. No equations or steps reduce a claimed prediction or result to a fitted parameter, self-defined quantity, or self-citation chain; the method uses the model's internal attention as an observable input and validates gains via external benchmarks across nine datasets and four backbones. The derivation chain remains self-contained against observable attention behavior and measured performance improvements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mitigating object hallucinations in large vision-language models with assembly of global and local attention
Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, QianYing Wang, Ping Chen, Xiaoqin Zhang, and Shijian Lu. Mitigating object hallucinations in large vision-language models with assembly of global and local attention. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29915–29926, 2025
2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
Pith/arXiv arXiv 2025
-
[3]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
2024
-
[4]
Lvlm-intrepret: An interpretability tool for large vision-language models
Gabriela Ben Melech Stan, Estelle Aflalo, Raanan Yehezkel Rohekar, Anahita Bhiwandiwalla, Shao-Yen Tseng, Matthew Lyle Olson, Yaniv Gurwicz, Chenfei Wu, Nan Duan, and Vasudev Lal. Lvlm-intrepret: An interpretability tool for large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8182–8187, 2024
2024
-
[5]
Glyph: Scaling context windows via visual-text compression
Jiale Cheng, Yusen Liu, Xinyu Zhang, Yulin Fei, Wenyi Hong, Ruiliang Lyu, Weihan Wang, Zhe Su, Xiaotao Gu, Xiao Liu, et al. Glyph: Scaling context windows via visual-text compression. arXiv preprint arXiv:2510.17800, 2025
arXiv 2025
-
[6]
A dataset of information-seeking questions and answers anchored in research papers
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4599–4610, 2021
2021
-
[7]
Lang Feng, Fuchao Yang, Feng Chen, Xin Cheng, Haiyang Xu, Zhenglin Wan, Ming Yan, and Bo An. Agentocr: Reimagining agent history via optical self-compression.arXiv preprint arXiv:2601.04786, 2026
arXiv 2026
-
[8]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
2020
-
[9]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
Pith/arXiv arXiv 2025
-
[10]
Effects of topic headings on text processing: Evidence from adult readers’ eye fixation patterns.Learning and instruction, 14(2):131–152, 2004
Jukka Hyönä and Robert F Lorch. Effects of topic headings on text processing: Evidence from adult readers’ eye fixation patterns.Learning and instruction, 14(2):131–152, 2004
2004
-
[11]
Cumulated gain-based evaluation of ir techniques.ACM Trans
Kalervo Järvelin and Jaana Kekäläinen. Cumulated gain-based evaluation of ir techniques.ACM Trans. Inf. Syst., 20(4):422–446, 2002
2002
-
[12]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1601–1611, 2017
2017
-
[13]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
2019
-
[14]
Qing’an Liu, Juntong Feng, Yuhao Wang, Xinzhe Han, Yujie Cheng, Yue Zhu, Haiwen Diao, Yunzhi Zhuge, and Huchuan Lu. Vista-bench: Do vision-language models really understand visualized text as well as pure text?arXiv preprint arXiv:2602.04802, 2026
Pith/arXiv arXiv 2026
-
[15]
Unveiling the ignorance of mllms: Seeing clearly, answering incorrectly
Yexin Liu, Zhengyang Liang, Yueze Wang, Xianfeng Wu, Feilong Tang, Muyang He, Jian Li, Zheng Liu, Harry Yang, Sernam Lim, et al. Unveiling the ignorance of mllms: Seeing clearly, answering incorrectly. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9087–9097, 2025
2025
-
[16]
Zhining Liu, Rana Ali Amjad, Ravinarayana Adkathimar, Tianxin Wei, and Hanghang Tong. Selfelicit: Your language model secretly knows where is the relevant evidence.arXiv preprint arXiv:2502.08767, 2025
arXiv 2025
-
[17]
Zhining Liu, Ziyi Chen, Hui Liu, Chen Luo, Xianfeng Tang, Suhang Wang, Joy Zeng, Zhenwei Dai, Zhan Shi, Tianxin Wei, et al. Seeing but not believing: Probing the disconnect between visual attention and answer correctness in vlms.arXiv preprint arXiv:2510.17771, 2025
arXiv 2025
-
[18]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13851–13870, 2024
2024
-
[19]
In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
Pith/arXiv arXiv 2022
-
[20]
When text-as-vision meets semantic ids in generative recommendation: An empirical study
Shutong Qiao, Wei Yuan, Tong Chen, Xiangyu Zhao, Quoc Viet Hung Nguyen, and Hongzhi Yin. When text-as-vision meets semantic ids in generative recommendation: An empirical study. arXiv preprint arXiv:2601.14697, 2026
arXiv 2026
-
[21]
Eye movements in reading and information processing: 20 years of research
Keith Rayner. Eye movements in reading and information processing: 20 years of research. Psychological bulletin, 124(3):372, 1998
1998
-
[22]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE international conference on computer vision, pages 618–626, 2017
2017
-
[23]
Yaorui Shi, Shugui Liu, Yu Yang, Wenyu Mao, Yuxin Chen, Qi Gu, Hui Su, Xunliang Cai, Xiang Wang, and An Zhang. Memocr: Layout-aware visual memory for efficient long-horizon reasoning.arXiv preprint arXiv:2601.21468, 2026
Pith/arXiv arXiv 2026
-
[24]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[25]
Newsqa: A machine comprehension dataset
Adam Trischler, Tong Wang, Xingdi Yuan, Justin Harris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. Newsqa: A machine comprehension dataset. InProceedings of the 2nd Workshop on Representation Learning for NLP, pages 191–200, 2017
2017
-
[26]
Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[27]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[28]
Vtc-r1: Vision-text compression for efficient long-context reasoning
Yibo Wang, Yongcheng Jing, Shunyu Liu, Hao Guan, Rong-cheng Tu, Chengyu Wang, Jun Huang, and Dacheng Tao. Vtc-r1: Vision-text compression for efficient long-context reasoning. arXiv preprint arXiv:2601.22069, 2026
arXiv 2026
-
[29]
Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025. 11
Pith/arXiv arXiv 2025
-
[30]
Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552, 2026
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552, 2026
arXiv 2026
-
[31]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
-
[32]
Shenglai Zeng, Pengfei He, Kai Guo, Tianqi Zheng, Hanqing Lu, Yue Xing, and Hui Liu. Towards context-robust llms: A gated representation fine-tuning approach.arXiv preprint arXiv:2502.14100, 2025
arXiv 2025
-
[33]
Towards knowledge checking in retrieval-augmented generation: A representation perspective
Shenglai Zeng, Jiankun Zhang, Bingheng Li, Yuping Lin, Tianqi Zheng, Dante Everaert, Hanqing Lu, Hui Liu, Yue Xing, Monica Xiao Cheng, et al. Towards knowledge checking in retrieval-augmented generation: A representation perspective. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistic...
2025
-
[34]
Shenglai Zeng, Tianqi Zheng, Chuan Tian, Dante Everaert, Yau-Shian Wang, Yupin Huang, Michael J Morais, Rohit Patki, Jinjin Tian, Xinnan Dai, et al. Attn-gs: Attention-guided context compression for efficient personalized llms.arXiv preprint arXiv:2602.07778, 2026
arXiv 2026
-
[35]
Hongbo Zhao, Meng Wang, Fei Zhu, Wenzhuo Liu, Bolin Ni, Fanhu Zeng, Gaofeng Meng, and Zhaoxiang Zhang. Vtcbench: Can vision-language models understand long context with vision-text compression?arXiv preprint arXiv:2512.15649, 2025
arXiv 2025
-
[36]
VEA and Baselines Implementation Details
Jianping Zhong, Guochang Li, Chen Zhi, Junxiao Han, Zhen Qin, Xinkui Zhao, Nan Wang, Shuiguang Deng, and Jianwei Yin. Can vision-language models handle long-context code? an empirical study on visual compression.arXiv preprint arXiv:2602.00746, 2026. 12 APPENDIX (§A) Full(k, α)Sensitivity Sweep . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
arXiv 2026
-
[37]
Justification: Not applicable
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.