G-Long: Graph-Enhanced Memory Management for Efficient Long-Term Dialogue Agents
Pith reviewed 2026-06-27 07:02 UTC · model grok-4.3
The pith
G-Long stores long dialogue history as a graph of triplets extracted by a small model and scores memories with T5 cross-attention signals to cut costs while raising response quality and retrieval accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
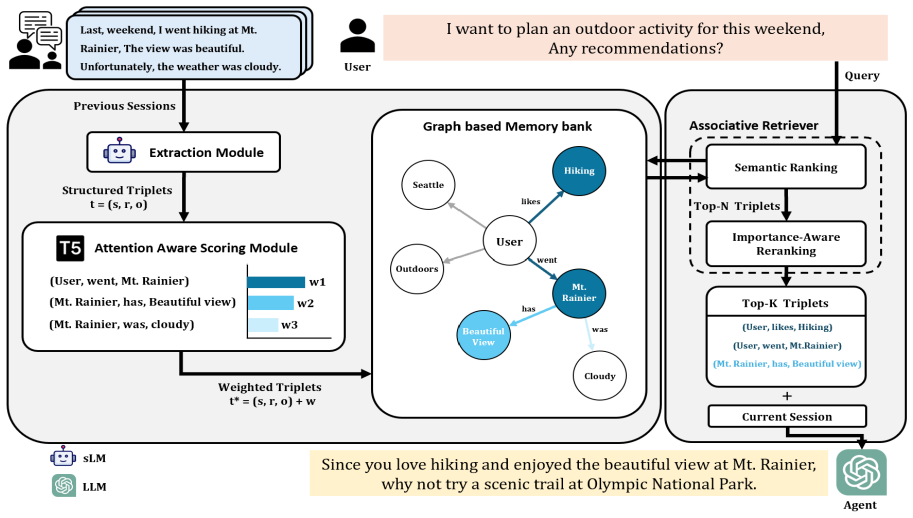
G-Long shows that a graph of triplets extracted by a fine-tuned small language model, retrieved associatively and ranked by T5 cross-attention signals, produces state-of-the-art response generation and memory retrieval while keeping computational overhead low.
What carries the argument
Graph-enhanced memory framework that performs structured triplet extraction with a small language model for associative retrieval and applies attention-aware importance scoring from a T5 summarizer's cross-attention signals.
If this is right
- Structured triplet graphs reduce information loss compared with raw-text memory stores.
- Cross-attention signals inside an existing summarizer can rank memory importance without training an extra model.
- Response quality and retrieval recall both improve on MSC and LME benchmarks.
- Overall compute and latency drop because the system avoids processing full raw context with large models.
- The same pipeline works across multiple dialogue domains without domain-specific retraining.
Where Pith is reading between the lines
- The same triplet-graph plus attention-scoring pattern could be tested on long-document question answering or multi-session reasoning tasks.
- If the small-model extractor is replaced by a larger one, the performance gap to full-context baselines might shrink or reverse.
- The explicit graph edges could support user-facing explanations of why a particular memory was retrieved.
- Extending the graph to include temporal or speaker-identity edges might further improve consistency on very long histories.
Load-bearing premise
The fine-tuned small language model extracts accurate triplets and the T5 cross-attention signals correctly identify salient memories without introducing systematic information loss or retrieval errors across dialogue domains.
What would settle it
A controlled test set in which the small model extracts many incorrect triplets or the attention scores systematically miss key facts, resulting in response quality or retrieval recall falling below the unstructured-memory or full-LLM baselines.
Figures





read the original abstract
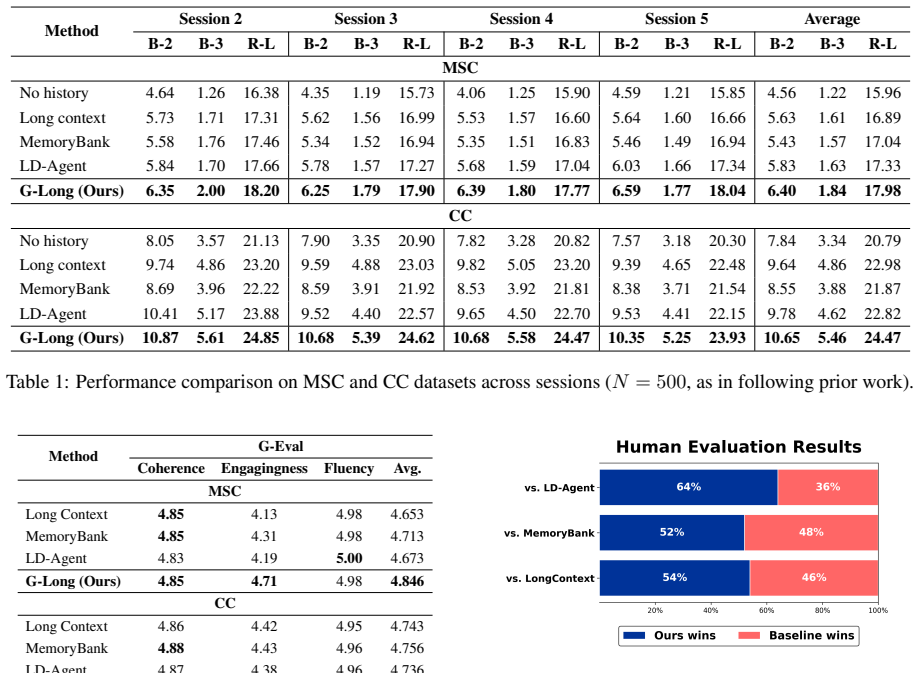
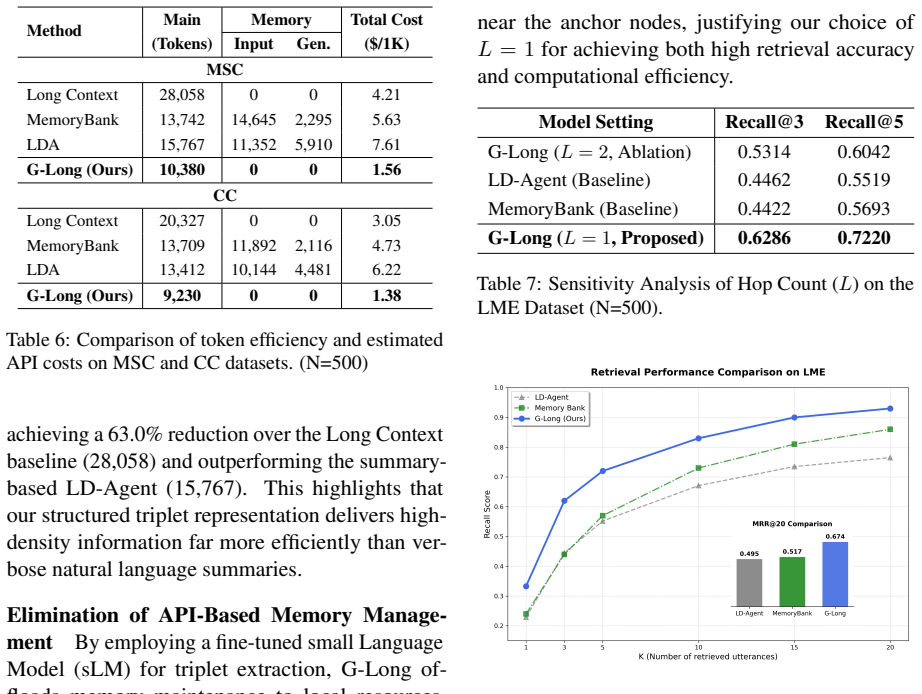
While Large Language Models (LLMs) have advanced open-domain dialogue systems, maintaining long-term consistency remains a challenge due to inherent limitations in long-context reasoning and the inefficiency of processing extensive raw text. Existing approaches typically rely on either unstructured memory storage, which is prone to information loss, or computationally expensive LLMs that incur high latency. To address these limitations, we propose G-Long, a graph-enhanced framework that utilizes a fine-tuned small Language Model (sLM) for structured triplet extraction and associative retrieval, significantly reducing operational costs. Furthermore, we introduce the novel attention-aware importance scoring mechanism that leverages the intrinsic cross-attention signals of a T5 summarizer to identify salient memories. Extensive experiments across diverse benchmarks demonstrate that G-Long achieves state-of-the-art performance in both response generation and memory retrieval, yielding performance gains of up to 9.8% in response quality on MSC and 40.8% in retrieval recall on LME, while significantly minimizing computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes G-Long, a graph-enhanced framework for long-term dialogue agents. It uses a fine-tuned small language model (sLM) to extract structured triplets from dialogues for associative retrieval and introduces an attention-aware importance scoring mechanism that leverages cross-attention signals from a T5 summarizer to identify salient memories. The approach aims to address limitations in long-context reasoning and computational inefficiency of existing methods. Extensive experiments on benchmarks are claimed to show SOTA performance in response generation and memory retrieval, with gains of up to 9.8% in response quality on MSC and 40.8% in retrieval recall on LME, while reducing overhead.
Significance. If the empirical results hold under rigorous validation, the work could contribute to more efficient memory management in dialogue systems by combining graph structures with attention-based salience scoring, potentially offering advantages over unstructured memory or full LLM-based approaches. The use of smaller models for structured extraction is a positive direction for scalability. No machine-checked proofs, parameter-free derivations, or reproducible code artifacts are mentioned.
major comments (2)
- [Abstract] Abstract: The SOTA claims with specific gains (9.8% response quality on MSC, 40.8% retrieval recall on LME) are presented without any information on experimental controls, chosen baselines, statistical significance testing, or safeguards against post-hoc selection; this directly affects the verifiability of the central performance claims.
- [Experiments] Experiments section (inferred from abstract claims): No extraction F1 scores, human validation of triplet accuracy, or ablation studies isolating the sLM triplet extraction and T5 cross-attention salience scoring from the graph structure are reported; these components are load-bearing for attributing any gains to the proposed graph-enhanced framework rather than to unvalidated preprocessing steps.
minor comments (1)
- [Abstract] The abstract could more explicitly name the evaluation metrics (e.g., which response quality metric yields the 9.8% figure) and the full set of baselines compared.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and verifiability of our work. We address each major comment below, proposing targeted revisions where they strengthen the manuscript without misrepresenting the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The SOTA claims with specific gains (9.8% response quality on MSC, 40.8% retrieval recall on LME) are presented without any information on experimental controls, chosen baselines, statistical significance testing, or safeguards against post-hoc selection; this directly affects the verifiability of the central performance claims.
Authors: We agree that the abstract would benefit from additional context to support verifiability of the claims. The Experiments section provides full details on the chosen baselines (unstructured memory stores and full-context LLM approaches), evaluation protocols, dataset splits, and statistical significance testing via paired t-tests on the reported metrics. To address the concern directly, we will revise the abstract to briefly reference the primary baselines and direct readers to the Experiments section for controls and safeguards. This change preserves the reported gains while improving transparency. revision: yes
-
Referee: [Experiments] Experiments section (inferred from abstract claims): No extraction F1 scores, human validation of triplet accuracy, or ablation studies isolating the sLM triplet extraction and T5 cross-attention salience scoring from the graph structure are reported; these components are load-bearing for attributing any gains to the proposed graph-enhanced framework rather than to unvalidated preprocessing steps.
Authors: The current manuscript prioritizes end-to-end results on response quality and retrieval recall. We acknowledge that explicit extraction F1 scores and human validation of triplet accuracy are not reported. We will add ablation studies in the revised Experiments section to isolate the contributions of the sLM-based triplet extraction and the T5 attention-aware scoring from the graph structure itself. Human validation of triplets was not conducted in the original experiments; we maintain that downstream task improvements provide indirect validation, but we can expand the discussion of triplet quality through automatic metrics if space permits. revision: partial
Circularity Check
No circularity: empirical framework with no derivation chain
full rationale
The paper presents an engineering framework (sLM triplet extraction + T5 cross-attention salience + graph memory) evaluated on MSC and LME benchmarks. No equations, first-principles derivations, or predictions are claimed; all performance numbers (9.8% response quality, 40.8% recall) are direct experimental outcomes. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the provided text. The central claims rest on external benchmark results rather than any reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hello Again! LLM -powered Personalized Agent for Long-term Dialogue
Li, Hao and Yang, Chenghao and Zhang, An and Deng, Yang and Wang, Xiang and Chua, Tat-Seng. Hello Again! LLM -powered Personalized Agent for Long-term Dialogue. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/...
-
[2]
Memorybank: Enhancing large language models with long-term memory
MemoryBank: Enhancing Large Language Models with Long-Term Memory , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2024 , month=. doi:10.1609/aaai.v38i17.29946 , abstractNote=
-
[3]
2025 , eprint=
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents , author=. 2025 , eprint=
2025
-
[4]
PAED : Zero-Shot Persona Attribute Extraction in Dialogues
Zhu, Luyao and Li, Wei and Mao, Rui and Pandelea, Vlad and Cambria, Erik. PAED : Zero-Shot Persona Attribute Extraction in Dialogues. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.544
-
[5]
Beyond Goldfish Memory: Long-Term Open-Domain Conversation
Xu, Jing and Szlam, Arthur and Weston, Jason. Beyond Goldfish Memory: Long-Term Open-Domain Conversation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.356
-
[6]
Jang, Jihyoung and Boo, Minseong and Kim, Hyounghun. Conversation Chronicles: Towards Diverse Temporal and Relational Dynamics in Multi-Session Conversations. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.838
-
[7]
2025 , eprint=
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , author=. 2025 , eprint=
2025
-
[8]
Dense Passage Retrieval for Open-Domain Question Answering
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau. Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.550
-
[9]
Flexibly Utilize Memory for Long-Term Conversation via a Fragment-then-Compose Framework
Ke, Cai and Du, Yiming and Liang, Bin and Xiang, Yifan and Gui, Lin and Li, Zhongyang and Wang, Baojun and Yu, Yue and Wang, Hui and Wong, Kam-Fai and Xu, Ruifeng. Flexibly Utilize Memory for Long-Term Conversation via a Fragment-then-Compose Framework. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18...
-
[10]
2022 , eprint=
Keep Me Updated! Memory Management in Long-term Conversations , author=. 2022 , eprint=
2022
-
[11]
2025 , eprint=
Towards Lifelong Dialogue Agents via Timeline-based Memory Management , author=. 2025 , eprint=
2025
-
[12]
2023 , eprint=
Mind the Gap Between Conversations for Improved Long-Term Dialogue Generation , author=. 2023 , eprint=
2023
-
[13]
2023 , eprint=
Lost in the Middle: How Language Models Use Long Contexts , author=. 2023 , eprint=
2023
-
[14]
2023 , eprint=
Zero- and Few-Shots Knowledge Graph Triplet Extraction with Large Language Models , author=. 2023 , eprint=
2023
-
[15]
2024 , eprint=
Extracting triples from dialogues for conversational social agents , author=. 2024 , eprint=
2024
-
[16]
Extracting and Inferring Personal Attributes from Dialogue
Wang, Zhilin and Zhou, Xuhui and Koncel-Kedziorski, Rik and Marin, Alex and Xia, Fei. Extracting and Inferring Personal Attributes from Dialogue. Proceedings of the 4th Workshop on NLP for Conversational AI. 2022. doi:10.18653/v1/2022.nlp4convai-1.6
-
[17]
Getting To Know You: User Attribute Extraction from Dialogues
Wu, Chien-Sheng and Madotto, Andrea and Lin, Zhaojiang and Xu, Peng and Fung, Pascale. Getting To Know You: User Attribute Extraction from Dialogues. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[18]
2024 , eprint=
Empirical Analysis of Dialogue Relation Extraction with Large Language Models , author=. 2024 , eprint=
2024
-
[19]
Haitao Wang and Yuanzhao Guo and Xiaotong Han and Yuan Tian , keywords =. Dialogue Relation Extraction Enhanced with Trigger: A Multi-Feature Filtering and Fusion Model , journal =. 2025 , issn =. doi:https://doi.org/10.32604/cmc.2025.060534 , url =
-
[20]
SAMS um Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization
Gliwa, Bogdan and Mochol, Iwona and Biesek, Maciej and Wawer, Aleksander. SAMS um Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization. Proceedings of the 2nd Workshop on New Frontiers in Summarization. 2019. doi:10.18653/v1/D19-5409
-
[21]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[22]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Wang, Wenhui and Wei, Furu and Dong, Li and Bao, Hangbo and Yang, Nan and Zhou, Ming , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[23]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[24]
B leu: a Method for Automatic Evaluation of Machine Translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , title =. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics , pages =. 2002 , publisher =. doi:10.3115/1073083.1073135 , abstract =
-
[25]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[26]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[27]
2023 , eprint=
Generative Agents: Interactive Simulacra of Human Behavior , author=. 2023 , eprint=
2023
-
[28]
2025 , eprint=
From Local to Global: A Graph RAG Approach to Query-Focused Summarization , author=. 2025 , eprint=
2025
-
[29]
2023 , eprint=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. 2023 , eprint=
2023
-
[30]
2024 , eprint=
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools , author=. 2024 , eprint=
2024
-
[31]
arxiv , year =
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , title =. arxiv , year =
-
[32]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[33]
2025 , eprint=
LinearRAG: Linear Graph Retrieval Augmented Generation on Large-scale Corpora , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
SGMem: Sentence Graph Memory for Long-Term Conversational Agents , author=. 2025 , eprint=
2025
-
[35]
2023 , eprint=
Augmenting Language Models with Long-Term Memory , author=. 2023 , eprint=
2023
-
[36]
2022 , eprint=
Long Time No See! Open-Domain Conversation with Long-Term Persona Memory , author=. 2022 , eprint=
2022
-
[37]
2022 , eprint=
Building a Role Specified Open-Domain Dialogue System Leveraging Large-Scale Language Models , author=. 2022 , eprint=
2022
-
[38]
2023 , eprint=
MemoChat: Tuning LLMs to Use Memos for Consistent Long-Range Open-Domain Conversation , author=. 2023 , eprint=
2023
-
[39]
Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations
Chen, Nuo and Li, Hongguang and Chang, Jianhui and Huang, Juhua and Wang, Baoyuan and Li, Jia. Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[40]
Neural Relation Extraction for Knowledge Base Enrichment
Trisedya, Bayu Distiawan and Weikum, Gerhard and Qi, Jianzhong and Zhang, Rui. Neural Relation Extraction for Knowledge Base Enrichment. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1023
-
[41]
2024 , eprint=
Information Extraction in Low-Resource Scenarios: Survey and Perspective , author=. 2024 , eprint=
2024
-
[42]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[43]
What Does BERT Look at? An Analysis of BERT ' s Attention
Clark, Kevin and Khandelwal, Urvashi and Levy, Omer and Manning, Christopher D. What Does BERT Look at? An Analysis of BERT ' s Attention. Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. 2019. doi:10.18653/v1/W19-4828
-
[44]
Analyzing the Structure of Attention in a Transformer Language Model
Vig, Jesse and Belinkov, Yonatan. Analyzing the Structure of Attention in a Transformer Language Model. Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. 2019. doi:10.18653/v1/W19-4808
-
[45]
Quantifying Attention Flow in Transformers
Abnar, Samira and Zuidema, Willem. Quantifying Attention Flow in Transformers. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.385
-
[46]
H2O: heavy-hitter oracle for efficient generative inference of large language models , year =
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R\'. H2O: heavy-hitter oracle for efficient generative inference of large language models , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[47]
2024 , eprint=
Efficient Streaming Language Models with Attention Sinks , author=. 2024 , eprint=
2024
-
[48]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[49]
GNN - RAG : Graph Neural Retrieval for Efficient Large Language Model Reasoning on Knowledge Graphs
Mavromatis, Costas and Karypis, George. GNN - RAG : Graph Neural Retrieval for Efficient Large Language Model Reasoning on Knowledge Graphs. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.856
-
[50]
GRAG : Graph Retrieval-Augmented Generation
Hu, Yuntong and Lei, Zhihan and Zhang, Zheng and Pan, Bo and Ling, Chen and Zhao, Liang. GRAG : Graph Retrieval-Augmented Generation. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.232
-
[51]
2023 , eprint=
H _2 O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models , author=. 2023 , eprint=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.