Visual Place Recognition in Forests with Depth-Aware Distillation
Pith reviewed 2026-06-27 07:09 UTC · model grok-4.3
The pith
A depth-aware distillation framework adds geometric cues to DINOv2 for more robust visual place recognition in forests while preserving the original descriptor space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
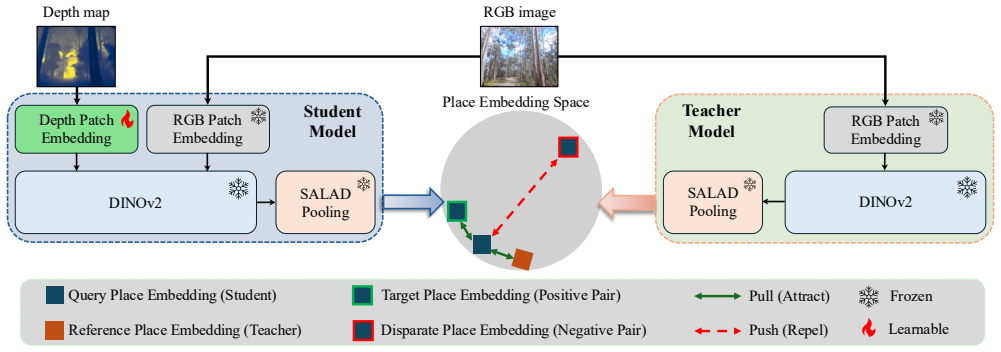
The proposed lightweight depth-aware distillation framework injects geometric cues into a DINOv2-based place recognition model while maintaining its pre-trained descriptor space. Evaluated on the WildCross benchmark, the approach yields gains over an appearance-only counterpart and provides robustness to appearance variations. These results demonstrate the importance of depth as a strong complementary modality for place recognition in natural environments and identify depth-aware distillation as a promising direction for more robust forest perception.
What carries the argument
The depth-aware distillation framework, which transfers geometric cues from depth data into the DINOv2 model without altering its pre-trained descriptor space.
If this is right
- Depth serves as a strong complementary modality to appearance for place recognition in natural environments.
- The distilled model produces measurable gains over appearance-only counterparts on the WildCross benchmark.
- Depth-aware distillation constitutes a promising direction for building more robust forest perception systems.
- The framework keeps the original DINOv2 descriptor space intact while incorporating geometric information.
Where Pith is reading between the lines
- The same distillation pattern could be tested in other high-variation settings such as seasonal urban or agricultural scenes.
- Pairing the method with additional sensor streams might further reduce failure cases in robot navigation through unstructured terrain.
- The approach hints at a general route for adapting large pre-trained vision models to domain-specific geometric signals with low overhead.
Load-bearing premise
Depth information can be distilled into the DINOv2 model as a complementary modality while fully maintaining its pre-trained descriptor space.
What would settle it
A direct comparison on the WildCross benchmark in which the depth-distilled model shows no accuracy gain or a measurable shift in the DINOv2 descriptor space relative to the appearance-only baseline.
Figures




read the original abstract
Visual place recognition in natural forest environments remains challenging due to repetitive vegetation, weak structural cues, and significant appearance variation across traversals. To address this limitation, this paper proposes a lightweight depth-aware distillation framework that injects geometric cues into a DINOv2-based place recognition model, while maintaining its pre-trained descriptor space. Evaluated on the recent WildCross benchmark, the proposed approach yields gains over an appearance-only counterpart, providing robustness to appearance variations. These results demonstrate the importance of depth as a strong complementary modality for place recognition in natural environments and identify depth-aware distillation as a promising direction for more robust forest perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a lightweight depth-aware distillation framework to inject geometric cues from depth into a DINOv2-based visual place recognition model for forest environments, while preserving the pre-trained descriptor space. It claims that this yields performance gains over an appearance-only baseline on the WildCross benchmark and thereby demonstrates robustness to appearance variation in natural scenes.
Significance. If substantiated with quantitative evidence, the result would establish depth as a useful complementary cue for VPR under repetitive vegetation and seasonal change, supporting more reliable forest robotics perception; the distillation approach itself could be reusable for other geometric modalities.
major comments (2)
- [Abstract] Abstract: the central claim that the method 'yields gains over an appearance-only counterpart' on WildCross is stated without any numerical results, tables, error bars, or statistical tests. Because the manuscript supplies neither the magnitude of improvement nor implementation details, the empirical contribution cannot be evaluated and is therefore load-bearing for acceptance.
- [Evaluation (implied)] No evaluation section, tables, or figures are referenced in the supplied text that would allow verification of the claimed robustness or comparison against the appearance-only DINOv2 baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the need for quantitative evidence and clear evaluation details. We address each point below and will revise the manuscript to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'yields gains over an appearance-only counterpart' on WildCross is stated without any numerical results, tables, error bars, or statistical tests. Because the manuscript supplies neither the magnitude of improvement nor implementation details, the empirical contribution cannot be evaluated and is therefore load-bearing for acceptance.
Authors: We agree that the abstract should include concrete numerical results to support the claim of gains. The full manuscript contains an evaluation section with tables reporting specific metrics (e.g., recall@1 and recall@5) on the WildCross benchmark, including direct comparisons to the appearance-only DINOv2 baseline with the observed improvements. In the revision we will update the abstract to cite these key quantitative findings and reference the relevant tables. revision: yes
-
Referee: [Evaluation (implied)] No evaluation section, tables, or figures are referenced in the supplied text that would allow verification of the claimed robustness or comparison against the appearance-only DINOv2 baseline.
Authors: The complete manuscript includes a dedicated evaluation section with tables and figures that present the WildCross benchmark results and comparisons against the appearance-only DINOv2 baseline. We will revise the abstract and introduction to explicitly reference these sections, tables, and figures so that the empirical evidence is immediately visible. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical lightweight depth-aware distillation framework for injecting geometric cues into a DINOv2-based model and reports performance gains on the WildCross benchmark relative to an appearance-only counterpart. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text; the central claim is a benchmark comparison rather than a reduction of any result to its own inputs by construction. The approach is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Depth cues can be injected via distillation without altering the pre-trained DINOv2 descriptor space
Reference graph
Works this paper leans on
-
[1]
Knights, Joshua and Reid, Joseph and Roy, Kaushik and Hall, David and Cox, Mark and Moghadam, Peyman , booktitle=
-
[2]
Hausler, Stephen and Moghadam, Peyman , journal=
-
[3]
Knights, Joshua and Vidanapathirana, Kavisha and Ramezani, Milad and Sridharan, Sridha and Fookes, Clinton and Moghadam, Peyman , booktitle=
-
[4]
arXiv preprint arXiv:2309.09668 , year=
Dformer: Rethinking rgbd representation learning for semantic segmentation , author=. arXiv preprint arXiv:2309.09668 , year=
-
[5]
arXiv preprint arXiv:2601.17895 , year=
Masked Depth Modeling for Spatial Perception , author=. arXiv preprint arXiv:2601.17895 , year=
-
[6]
IEEE/CVF CVPR , pages=
Optimal transport aggregation for visual place recognition , author=. IEEE/CVF CVPR , pages=
-
[7]
arXiv preprint arXiv:2304.07193 , year=
DinoV2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
-
[8]
NeurIPS , volume=
Depth anything v2 , author=. NeurIPS , volume=
-
[9]
IEEE/CVF CVPR , pages=
NetVLAD: CNN architecture for weakly supervised place recognition , author=. IEEE/CVF CVPR , pages=
-
[10]
IEEE/CVF CVPR , pages=
Rethinking visual geo-localization for large-scale applications , author=. IEEE/CVF CVPR , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.