NavWAM: A Navigation World Action Model for Goal-Conditioned Visual Navigation
Pith reviewed 2026-06-27 06:28 UTC · model grok-4.3
The pith
NavWAM turns navigation world-model foresight into direct closed-loop actions by embedding future observations, goal-progress values, and action chunks in one shared latent sequence inside a diffusion transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NavWAM is a diffusion-transformer policy that represents future observations, goal-progress values, and action chunks in a shared latent sequence. By learning future prediction jointly with the action and value targets that determine closed-loop behavior, it converts navigation world-model foresight into executable control signals without requiring an external planner.
What carries the argument
diffusion-transformer policy whose shared latent sequence jointly encodes future observations, goal-progress values, and action chunks
If this is right
- NavWAM improves success rates over planning-based world-model baselines on both offline benchmarks and closed-loop real-robot deployments.
- The model operates in its default policy mode and does not require CEM-style action search at test time.
- Simulation pretraining followed by real-robot adaptation yields a policy that directly converts visual foresight into control.
- The same architecture applies to image-goal navigation under partial observability.
Where Pith is reading between the lines
- The unified latent sequence may lower the compute needed for real-time decision making compared with separate prediction-plus-planning pipelines.
- The joint training of prediction and value targets could improve robustness when transferring policies across environments with different visual statistics.
- Similar shared-sequence designs might be tested on other partially observable robotics tasks such as manipulation under occlusion.
Load-bearing premise
Jointly embedding future observations, goal-progress values, and action chunks inside one shared latent sequence inside a diffusion transformer produces closed-loop actions that outperform separate planning on top of a world model.
What would settle it
A closed-loop real-robot trial on a new image-goal navigation task in which NavWAM records lower success rate than a planning-based world-model baseline that uses the same visual predictor.
Figures

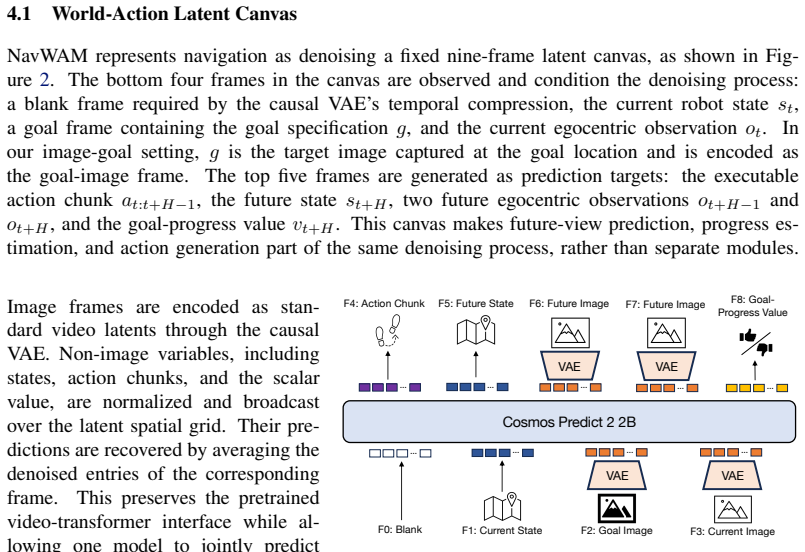



read the original abstract
Goal-conditioned visual navigation requires a robot to act under partial observability by anticipating how its motion will change the future egocentric view and whether that change brings it closer to the goal. Navigation world models provide such visual foresight, but they remain prediction modules that require an external planner to convert predicted futures into closed-loop control. We propose Navigation World Action Model (NavWAM), a diffusion-transformer policy that turns navigation world-model prediction into executable action by representing future observations, goal-progress values, and action chunks in a shared latent sequence. By learning future prediction jointly with the action and value targets that determine closed-loop behavior, NavWAM makes visual foresight directly usable for robot control. We build NavWAM through simulation pretraining and real-robot adaptation, and evaluate it on image-goal navigation against planning-based world models and a representative direct navigation policy. Across offline benchmarks and closed-loop real-robot deployment, NavWAM improves over planning-based world-model baselines in our evaluations while using the default policy mode without CEM-style action search. Project page: https://dachii-azm.github.io/navwam/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NavWAM, a diffusion-transformer policy for goal-conditioned visual navigation that represents future observations, goal-progress values, and action chunks within a single shared latent sequence. By jointly training future prediction with action and value targets, the model converts navigation world-model foresight into direct closed-loop control without external planners such as CEM. The approach involves simulation pretraining followed by real-robot adaptation and is evaluated against planning-based world-model baselines and direct policies on both offline benchmarks and physical robot deployments, reporting performance gains while operating in default policy mode.
Significance. If the empirical gains hold under the reported conditions, the work offers a concrete route to making visual world models directly actionable for control in partially observable navigation tasks. The joint embedding of prediction, value, and action targets inside one diffusion transformer is a substantive architectural choice that could reduce the need for separate planning modules. Credit is due for the simulation-to-real pipeline and the closed-loop real-robot results, which provide a stronger test than offline metrics alone.
major comments (2)
- [§4.2] §4.2 (Evaluation on offline benchmarks): the reported improvements over planning-based baselines are stated without accompanying ablation that isolates the contribution of the shared latent sequence versus separate prediction and planning heads; this is load-bearing for the central claim that joint training is what enables direct usability.
- [§3.3] §3.3 (Diffusion transformer architecture): the forward and reverse processes are described for the joint sequence, yet it is not shown how the value and action targets remain consistent with the predicted observations under the same noise schedule; an explicit consistency equation or training objective term would be needed to confirm the joint objective does not introduce contradictions.
minor comments (2)
- [Figure 3] Figure 3 caption: the legend for the real-robot trajectories does not distinguish between NavWAM and the CEM baseline runs; this reduces readability of the qualitative comparison.
- [Related Work] Related work section: the citation to prior diffusion policies for navigation omits the specific year and venue for the most directly comparable method, making the novelty positioning harder to assess.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the value of the simulation-to-real pipeline and closed-loop robot results. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Evaluation on offline benchmarks): the reported improvements over planning-based baselines are stated without accompanying ablation that isolates the contribution of the shared latent sequence versus separate prediction and planning heads; this is load-bearing for the central claim that joint training is what enables direct usability.
Authors: We agree that an explicit ablation isolating the shared latent sequence from separate prediction and planning heads would strengthen support for the central claim. Our current comparisons are against planning-based world-model baselines that use separate modules, but these do not isolate the joint-sequence design. In the revision we will add an ablation that trains variants with separate heads while retaining the same diffusion process and data, directly measuring the contribution of the shared sequence to direct policy usability. revision: yes
-
Referee: [§3.3] §3.3 (Diffusion transformer architecture): the forward and reverse processes are described for the joint sequence, yet it is not shown how the value and action targets remain consistent with the predicted observations under the same noise schedule; an explicit consistency equation or training objective term would be needed to confirm the joint objective does not introduce contradictions.
Authors: The architecture concatenates future observations, goal-progress values, and action chunks into one sequence that undergoes a single forward diffusion process with uniform noise addition; the reverse process denoises the full sequence, after which each component is read out. The training loss is the sum of per-component diffusion losses applied to the same noisy sequence. To address the request we will insert an explicit joint objective equation and a short consistency derivation in §3.3 of the revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes NavWAM as a diffusion-transformer architecture that jointly represents future observations, goal-progress values, and action chunks in one latent sequence, with the claim that this joint training turns world-model foresight into direct closed-loop control. This is presented as an explicit modeling choice and empirical design decision rather than a mathematical derivation. No equations are shown that reduce any prediction or result to a fitted input by construction, no self-citation chains support uniqueness theorems, and no ansatz or renaming of known results is invoked as load-bearing. The evaluation against planning baselines is external and falsifiable, leaving the derivation chain self-contained with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
D. Shah, A. Sridhar, N. Dashora, K. Stachowicz, K. Black, N. Hirose, and S. Levine. ViNT: A foundation model for visual navigation. InProc. Conference on Robot Learning (CoRL),
- [3]
-
[4]
A. Sridhar, D. Shah, C. Glossop, and S. Levine. NoMaD: Goal masked diffusion policies for navigation and exploration. InProc. IEEE International Conference on Robotics and Automa- tion (ICRA), 2024. URLhttps://arxiv.org/abs/2310.07896
-
[5]
Hirose, C
N. Hirose, C. Glossop, A. Sridhar, D. Shah, O. Mees, and S. Levine. LeLaN: Learning a language-conditioned navigation policy from in-the-wild video. InProc. Conference on Robot Learning (CoRL), 2024
2024
-
[6]
Hirose, C
N. Hirose, C. Glossop, D. Shah, and S. Levine. OmniVLA: An omni-modal vision-language- action model for robot navigation. InProc. IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[7]
J. Y . Koh, H. Lee, Y . Yang, J. Baldridge, and P. Anderson. Pathdreamer: A world model for indoor navigation. InProc. IEEE/CVF International Conference on Computer Vision (ICCV), pages 14738–14748, October 2021
2021
-
[8]
Navdreamer: Video models as zero-shot 3d navigators, 2026.https://arxiv.org/abs/2602.09765
X. Huang, W. Gai, T. Wu, C. Wang, Z. Liu, X. Zhou, Y . Wu, and F. Gao. NavDreamer: Video models as zero-shot 3d navigators, 2026. URLhttps://arxiv.org/abs/2602.09765
- [9]
-
[10]
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun. Navigation world models. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15791– 15801, June 2025
2025
-
[11]
Y . Du, M. Yang, B. Dai, H. Dai, O. Nachum, J. B. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Informa- tion Processing Systems, 2023
2023
-
[12]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large- scale video generative pre-training for visual robot manipulation. InInternational Conference on Learning Representations, 2024
2024
-
[13]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Cosmos-predict2: World simulation model for physical ai, 2025
NVIDIA. Cosmos-predict2: World simulation model for physical ai, 2025. URLhttps: //github.com/nvidia-cosmos/cosmos-predict2
2025
-
[15]
Batra, A
D. Batra, A. Gokaslan, A. Kembhavi, O. Maksymets, R. Mottaghi, M. Savva, A. Toshev, and E. Wijmans. Objectnav revisited: On evaluation of embodied agents navigating to objects,
- [16]
-
[17]
D. S. Chaplot, D. P. Gandhi, A. Gupta, and R. R. Salakhutdinov. Object goal navigation using goal-oriented semantic exploration. InProc. Annual Conference on Neural Information Processing Systems (NeurIPS), volume 33, pages 4247–4258,
-
[18]
URLhttps://proceedings.neurips.cc/paper_files/paper/2020/file/ 2c75cf2681788adaca63aa95ae028b22-Paper.pdf. 9
2020
-
[19]
S. Y . Gadre, M. Wortsman, G. Ilharco, L. Schmidt, and S. Song. CoWs on pasture: Base- lines and benchmarks for language-driven zero-shot object navigation. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23171–23181, June 2023
2023
-
[20]
Majumdar, G
A. Majumdar, G. Aggarwal, B. Devnani, J. Hoffman, and D. Batra. Zson: Zero-shot object- goal navigation using multimodal goal embeddings. InProc. Annual Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[21]
Gervet, S
T. Gervet, S. Chintala, D. Batra, J. Malik, and D. S. Chaplot. Navigating to objects in the real world.Science Robotics, 8(79):eadf6991, 2023
2023
-
[22]
Hirose, F
N. Hirose, F. Xia, R. Mart ´ın-Mart´ın, A. Sadeghian, and S. Savarese. Deep visual mpc-policy learning for navigation.IEEE Robotics and Automation Letters (RA-L), 4(4):3184–3191, 2019
2019
-
[23]
A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Batra. Embodied Question Answering. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[24]
Wijmans, S
E. Wijmans, S. Datta, O. Maksymets, A. Das, G. Gkioxari, S. Lee, I. Essa, D. Parikh, and D. Batra. Embodied Question Answering in Photorealistic Environments with Point Cloud Perception. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[25]
Sakamoto, D
K. Sakamoto, D. Azuma, T. Miyanishi, S. Kurita, and M. Kawanabe. Map-based modular approach for zero-shot embodied question answering. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
2024
-
[26]
Saxena, B
S. Saxena, B. Buchanan, C. Paxton, P. Liu, B. Chen, N. Vaskevicius, L. Palmieri, J. Francis, and O. Kroemer. Grapheqa: Using 3d semantic scene graphs for real-time embodied question answering. InConference on Robot Learning (CoRL), 2025
2025
-
[27]
Gupta, J
S. Gupta, J. Davidson, S. Levine, R. Sukthankar, and J. Malik. Cognitive mapping and plan- ning for visual navigation. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
2017
-
[28]
D. S. Chaplot, D. Gandhi, S. Gupta, A. Gupta, and R. Salakhutdinov. Learning to explore using active neural slam. InProc. International Conference on Learning Representations (ICLR),
- [29]
-
[30]
D. S. Chaplot, R. Salakhutdinov, A. Gupta, and S. Gupta. Neural topological SLAM for visual navigation. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[31]
X. Yu, S. Zhang, X. Song, X. Qin, and S. Jiang. Trajectory diffusion for objectgoal navigation. InProc. Annual Conference on Neural Information Processing Systems (NeurIPS), volume 37, pages 110388–110411, 2024. URLhttps://proceedings.neurips.cc/paper_files/ paper/2024/file/c72861451d6fa9dfa64831102b9bb71a-Paper-Conference.pdf
2024
-
[32]
K.-H. Zeng, Z. Zhang, K. Ehsani, R. Hendrix, J. Salvador, A. Herrasti, R. Girshick, A. Kem- bhavi, and L. Weihs. PoliFormer: Scaling on-policy rl with transformers results in masterful navigators. InProc. Conference on Robot Learning (CoRL), volume 270, pages 408–432, 2025
2025
-
[33]
Cheng, Y
A.-C. Cheng, Y . Ji, Z. Yang, Z. Gongye, X. Zou, J. Kautz, E. Biyik, H. Yin, S. Liu, and X. Wang. NaVILA: Legged robot vision-language-action model for navigation. InRobotics: Science and Systems (RSS), 2025
2025
-
[34]
Zhang, K
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang. NaVid: Video-based VLM plans the next step for vision-and-language navigation. InRobotics: Science and Systems (RSS), 2024. 10
2024
-
[35]
Zhang, K
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang. Uni- navid: A video-based vision-language-action model for unifying embodied navigation tasks. InRobotics: Science and Systems (RSS), 2025
2025
- [36]
-
[37]
Georgakis, B
G. Georgakis, B. Bucher, K. Schmeckpeper, S. Singh, and K. Daniilidis. Learning to map for active semantic goal navigation. InProc. International Conference on Learning Representa- tions (ICLR), 2022. URLhttps://openreview.net/forum?id=swrMQttr6wN
2022
-
[38]
Zhang, X
S. Zhang, X. Yu, X. Song, X. Wang, and S. Jiang. Imagine before go: Self-supervised gener- ative map for object goal navigation. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16414–16425, June 2024
2024
-
[39]
H. Shah, J. Xing, N. Messikommer, B. Sun, M. Pollefeys, and D. Scaramuzza. ForesightNav: Learning scene imagination for efficient exploration. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 5275–5284, June 2025
2025
-
[40]
A. J. Zhai and S. Wang. PEANUT: Predicting and navigating to unseen targets. InProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[41]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems, 2023
2023
-
[42]
Liang, R
J. Liang, R. Liu, E. Ozguroglu, S. Sudhakar, A. Dave, P. Tokmakov, S. Song, and C. V on- drick. Dreamitate: Real-world visuomotor policy learning via video generation. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 3943–3960. PMLR, 2025
2025
-
[43]
Wan Team, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, J. Wang, J. Zhang, J. Zhou, J. Wang, J. Chen, K. Zhu, K. Zhao, K. Yan, L. Huang, M. Feng, N. Zhang, P. Li, P. Wu, R. Chu, R. Feng, S. Zhang, S. Sun, T. Fang, T. Wang, T. Gui, T. Weng, T. Shen, W. Lin, W. Wang, W. Wang, W. Zhou, W. Wang, W. Shen, W. Yu, X. Shi, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, October 2023
2023
-
[45]
J. W. Bae, J. Kim, J. Yun, C. Kang, J. Choi, C. Kim, J. Lee, J. Choi, and J. W. Choi. Sit dataset: Socially interactive pedestrian trajectory dataset for social navigation robots. InAdvances in Neural Information Processing Systems (NeurIPS), pages 24552–24563, 2023
2023
-
[46]
L. Liu, T. Ma, B. Li, Z. Chen, J. Liu, G. Li, S. Zhou, Q. He, and X. Wu. Phantom: Subject- consistent video generation via cross-modal alignment. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 14951–14961, October 2025
2025
-
[47]
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. M. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang, M. Savva, Y . Zhao, and D. Batra. Habitat-matterport 3d dataset (HM3d): 1000 large-scale 3d environments for embodied AI. In Proc. Annual Conference on Neural Information Processing Systems (NeurIPS), 2021. URL https://ar...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
D. Shah, B. Eysenbach, N. Rhinehart, and S. Levine. Rapid Exploration for Open-World Navigation with Latent Goal Models. InProc. Conference on Robot Learning (CoRL), 2021. URLhttps://openreview.net/forum?id=d_SWJhyKfVw
2021
-
[49]
Hirose, D
N. Hirose, D. Shah, A. Sridhar, and S. Levine. SACSoN: Scalable autonomous control for social navigation.IEEE Robotics and Automation Letters (RA-L), 9(1):49–56, 2024
2024
-
[50]
H. Karnan, A. Nair, X. Xiao, G. Warnell, S. Pirk, A. Toshev, J. Hart, J. Biswas, and P. Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters (RA-L), 7(4):11807–11814, 2022. 12 Appendix A Method Details The main paper specifies NavW AM at the level of a shar...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.