ReSCom: A Reconfigurable Spiking Neural Network Accelerator Using Stochastic Computing
Pith reviewed 2026-06-27 05:04 UTC · model grok-4.3
The pith
ReSCom applies stochastic computing to multiplications in SNN neuron updates while keeping additions exact to enable low-energy reconfigurable FPGA acceleration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ReSCom is a reconfigurable SNN accelerator that employs stochastic arithmetic for multiplication operations in neuron dynamics while preserving exact fixed-point addition/subtraction operations. This stochastic strategy enables runtime trade-offs between accuracy, latency, and energy consumption. A unified reconfigurable neuron design supports Integrate-and-Fire (IF), Leaky Integrate-and-Fire (LIF), and Synaptic neuron models within a single hardware framework. Experimental results for MNIST inference on a Xilinx Artix-7 FPGA show that ReSCom achieves 92.80 percent classification accuracy while consuming just 0.05 mJ of operational energy per image at 100 MHz, outperforming the energy effici
What carries the argument
The unified reconfigurable neuron design that applies stochastic arithmetic only to multiplications while preserving exact fixed-point addition and subtraction operations.
If this is right
- Explicit dynamic control over accuracy-latency-energy trade-offs by managing stochastic bit-stream length.
- Single hardware framework that implements Integrate-and-Fire, Leaky Integrate-and-Fire, and Synaptic neuron models.
- Measured energy of 0.05 mJ per MNIST image at 100 MHz on Artix-7 FPGA while maintaining 92.80 percent accuracy.
- Outperformance of energy efficiency relative to recent state-of-the-art SNN accelerator implementations.
Where Pith is reading between the lines
- The selective stochastic approach may extend to other recurrent neural hardware where only certain operations tolerate approximation.
- Reconfigurability for multiple neuron models could simplify deployment across edge devices with different power budgets.
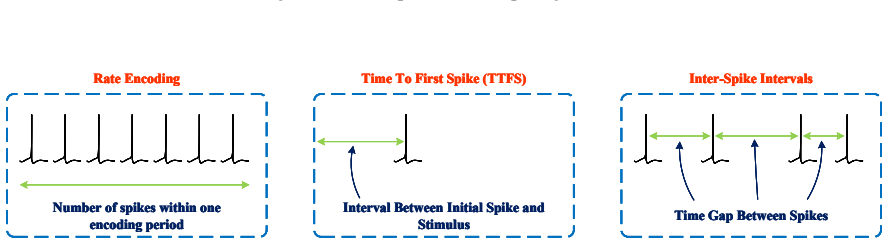
- Stability claims could be tested by measuring state drift over long sequences when bit-stream length changes dynamically.
Load-bearing premise
Stochastic arithmetic applied only to multiplications will keep recurrent state updates stable across the supported neuron models without introducing destabilizing errors when bit-stream length is varied.
What would settle it
A measurable drop in classification accuracy below 90 percent or emergence of unstable firing rates in the LIF model when the stochastic bit-stream length is reduced below the length used for the reported 92.80 percent result.
Figures





read the original abstract
Spiking Neural Networks (SNNs) provide an attractive framework for energy-efficient inference due to their event-driven computation and biologically inspired dynamics. However, efficient hardware realization of SNNs remains challenging because neuronal computations incur significant power and area costs, and uncontrolled approximate arithmetic can destabilize recurrent state updates when precision is not properly managed. To address these challenges, this paper presents ReSCom, a reconfigurable SNN accelerator that leverages stochastic computing to reduce hardware complexity while maintaining stable inference. The proposed architecture employs stochastic arithmetic for multiplication operations in neuron dynamics, while preserving exact fixed-point addition/subtraction operations. This stochastic strategy enables runtime trade-offs between accuracy, latency, and energy consumption. A unified reconfigurable neuron design supports Integrate-and-Fire (IF), Leaky Integrate-and-Fire (LIF), and Synaptic neuron models within a single hardware framework. Experimental results for MNIST inference on a Xilinx Artix-7 FPGA show that ReSCom achieves $92.80\%$ classification accuracy while consuming just $0.05~\mathrm{mJ}$ of operational energy per image at $100~\mathrm{MHz}$, outperforming the energy efficiency of recent state-of-the-art implementations. Furthermore, managing the stochastic bit-stream length allows explicit, dynamic control over accuracy-latency-energy trade-offs to meet target application constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ReSCom, a reconfigurable SNN accelerator on FPGA that applies stochastic computing exclusively to multiplications within neuron dynamics (IF, LIF, and Synaptic models) while retaining exact fixed-point addition/subtraction. A unified hardware neuron supports runtime reconfiguration, and bit-stream length is used to trade accuracy against latency and energy. On MNIST inference at 100 MHz on Xilinx Artix-7, the design is reported to reach 92.80% accuracy at 0.05 mJ per image while outperforming recent SNN accelerators in energy efficiency.
Significance. If the numerical stability of recurrent state updates holds under the stochastic-multiplication regime, the work supplies a concrete hardware mechanism for controllable accuracy-energy trade-offs in event-driven networks and demonstrates a compact reconfigurable neuron primitive. The explicit separation of stochastic multiplies from exact adds is a clean architectural choice that could be reusable beyond the reported FPGA prototype.
major comments (2)
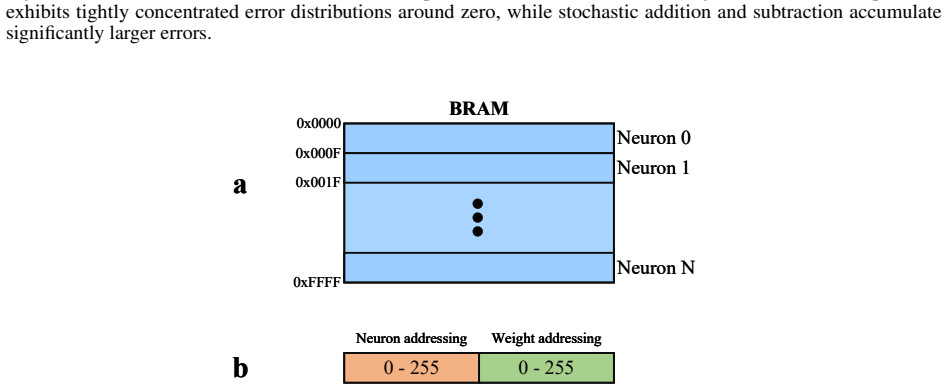
- [Abstract / Experimental Results] Abstract and § on experimental results: the central performance claim (92.80% MNIST accuracy, 0.05 mJ/image) rests on the unverified premise that stochastic errors in multiplications of leak factors or synaptic weights do not accumulate to shift spike timing or firing rates in LIF and Synaptic models. No error-propagation bound, membrane-potential variance analysis, or ablation of accuracy versus bit-stream length for recurrent cases is supplied.
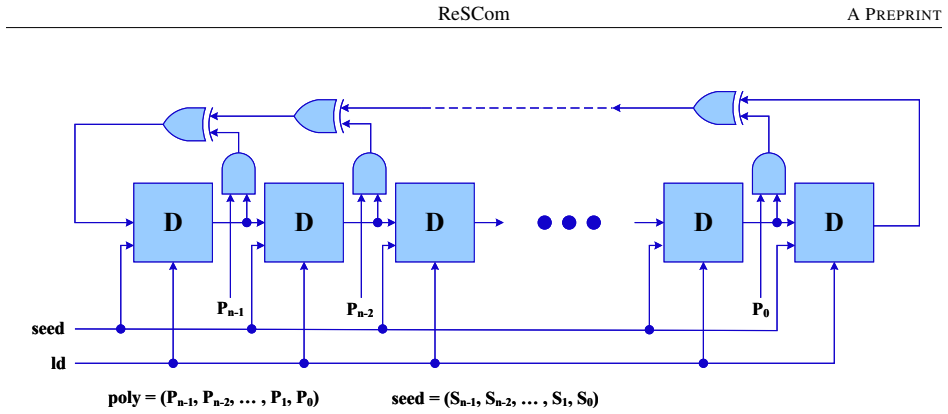
- [Architecture / Neuron Design] Architecture section describing the unified neuron: although additions remain exact, the leak term in LIF dynamics is a multiplication; repeated application over timesteps can amplify small stochastic variances into timing jitter. The manuscript provides no simulation or analytic bound quantifying this effect when bit-stream length is varied, leaving the stability assumption load-bearing for the reported accuracy.
minor comments (2)
- [Abstract] The abstract states that ReSCom outperforms recent state-of-the-art implementations but supplies neither the list of baselines nor a comparison table with their reported energy or accuracy figures.
- [Experimental Results] Dataset split details, number of runs, and error bars on the 92.80% accuracy figure are absent from the experimental description, making reproducibility and statistical significance difficult to assess.
Simulated Author's Rebuttal
We thank the referee for the constructive comments emphasizing the need to substantiate numerical stability under stochastic multiplications in recurrent neuron dynamics. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and § on experimental results: the central performance claim (92.80% MNIST accuracy, 0.05 mJ/image) rests on the unverified premise that stochastic errors in multiplications of leak factors or synaptic weights do not accumulate to shift spike timing or firing rates in LIF and Synaptic models. No error-propagation bound, membrane-potential variance analysis, or ablation of accuracy versus bit-stream length for recurrent cases is supplied.
Authors: We agree that the manuscript does not supply a formal error-propagation bound or membrane-potential variance analysis. The reported accuracy of 92.80% is obtained from end-to-end FPGA execution of the LIF and Synaptic models on MNIST, which inherently involves repeated application of the leak and weight multiplications over multiple timesteps. This empirical outcome indicates that stochastic errors remain tolerable for the evaluated bit-stream lengths and network configurations. In the revised manuscript we will add an ablation plot of classification accuracy versus bit-stream length specifically for the recurrent models to make this evidence explicit. revision: yes
-
Referee: [Architecture / Neuron Design] Architecture section describing the unified neuron: although additions remain exact, the leak term in LIF dynamics is a multiplication; repeated application over timesteps can amplify small stochastic variances into timing jitter. The manuscript provides no simulation or analytic bound quantifying this effect when bit-stream length is varied, leaving the stability assumption load-bearing for the reported accuracy.
Authors: The design deliberately confines stochastic arithmetic to multiplications while keeping all additions and subtractions exact; this architectural separation bounds error growth to the multiplicative factors only. Although no analytic variance bound is derived, the FPGA prototype successfully executes the full recurrent dynamics at the reported accuracy, demonstrating that any resulting timing jitter does not prevent correct inference. We will incorporate additional simulation results that quantify firing-rate deviation as a function of bit-stream length in the revised version. revision: yes
Circularity Check
No circularity: experimental hardware claims rest on FPGA measurements, not self-referential derivations
full rationale
The paper describes a reconfigurable SNN accelerator architecture that applies stochastic arithmetic selectively to multiplications while keeping additions exact, then reports measured accuracy and energy on a Xilinx Artix-7 FPGA for MNIST. No equations, fitted parameters, or derivation steps are presented that reduce the reported 92.80% accuracy or 0.05 mJ/image figures to quantities defined by the design itself. The central claims are grounded in physical implementation and direct measurement rather than any self-definitional, fitted-input, or self-citation load-bearing chain. The architecture description and experimental results are therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, "Deep learning,"Nature, vol. 521, no. 7553, pp. 436–444, May 2015
2015
-
[2]
Towards spike-based machine intelligence with neuromorphic computing,
K. Roy, A. Jaiswal, and P. Panda, "Towards spike-based machine intelligence with neuromorphic computing," Nature, vol. 575, pp. 607–617, Nov. 2019
2019
-
[3]
A million spiking-neuron integrated circuit with a scalable communication network and interface,
P. A. Merollaet al., "A million spiking-neuron integrated circuit with a scalable communication network and interface,"Science, vol. 345, no. 6197, pp. 668–673, Aug. 2014
2014
-
[4]
Memory and information processing in neuromorphic systems,
G. Indiveri and S.-C. Liu, "Memory and information processing in neuromorphic systems,"Proc. IEEE, vol. 103, no. 8, pp. 1379–1397, Aug. 2015
2015
-
[5]
Efficient processing of deep neural networks: A tutorial and survey,
V . Sze, Y .-H. Chen, T.-J. Yang, and J. S. Emer, "Efficient processing of deep neural networks: A tutorial and survey,"Proc. IEEE, vol. 105, no. 12, pp. 2295–2329, Dec. 2017
2017
-
[6]
A new golden age for computer architecture,
J. L. Hennessy and D. A. Patterson, "A new golden age for computer architecture,"Commun. ACM, vol. 62, no. 2, pp. 48–60, Feb. 2018
2018
-
[7]
Survey of stochastic computing,
A. Alaghi and J. P. Hayes, "Survey of stochastic computing,"ACM Trans. Embed. Comput. Syst., vol. 12, no. 2s, Article 92, 2013
2013
-
[8]
VLSI implementation of deep neural network using integral stochastic computing,
A. Ardakaniet al., "VLSI implementation of deep neural network using integral stochastic computing,"IEEE Trans. VLSI Syst., vol. 25, no. 10, pp. 2688–2699, Oct. 2017
2017
-
[9]
The promise and challenge of stochastic computing,
A. Alaghi, W. Qian, and J. P. Hayes, "The promise and challenge of stochastic computing,"IEEE Trans. Comput.- Aided Des. Integr. Circuits Syst., vol. 37, no. 8, pp. 1515–1531, Aug. 2018
2018
-
[10]
Dynamic energy-accuracy trade-off using stochastic computing in deep neural networks,
K. Kim, J. Lee, and K. Choi, "Dynamic energy-accuracy trade-off using stochastic computing in deep neural networks," inProc. 53rd Annu. Design Autom. Conf. (DAC), 2016, pp. 1–6
2016
-
[11]
The synthesis of XNOR recurrent neural networks with stochastic logic,
A. Ardakaniet al., "The synthesis of XNOR recurrent neural networks with stochastic logic," inProc. 33rd Conf. Neural Inf. Process. Syst. (NeurIPS), 2019, pp. 8442–8452
2019
-
[12]
Energy Efficient Analog Spiking Temporal Encoder with Verification and Recovery Scheme for Neuromorphic Computing Systems,
C. Zhao, J. Li, H. An, and Y . Yi, "Energy Efficient Analog Spiking Temporal Encoder with Verification and Recovery Scheme for Neuromorphic Computing Systems,"Proc. 18th Int’l Symp. Quality Electronic Design (ISQED), pp. 138–143, Mar. 2017
2017
-
[13]
Exploring Spiking Neural Networks: A Comprehen- sive Analysis of Mathematical Models and Applications,
Sanaullah, S., Koravuna, S., Rückert, U., and Jungeblut, T., "Exploring Spiking Neural Networks: A Comprehen- sive Analysis of Mathematical Models and Applications,"Front. Comput. Neurosci., vol. 17, pp. 1215824, Aug. 2023
2023
-
[14]
A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input,
A. N. Burkitt, "A review of the integrate-and-fire neuron model: I. Homogeneous synaptic input,"Biol. Cybern., vol. 95, pp. 1–19, Apr. 2006
2006
-
[15]
Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition,
W. Gerstner, W. M. Kistler, R. Naud, and L. Paninski, "Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition,"Cambridge University Press, Chapter 1, Oct. 2013
2013
-
[16]
An Investigation on Spiking Neural Networks Based on the Izhikevich Neuronal Model: Spiking Processing and Hardware Approach,
A. S. Alkabaa, O. Taylan, M. T. Yilmaz, E. Nazemi, and E. M. Kalmoun, "An Investigation on Spiking Neural Networks Based on the Izhikevich Neuronal Model: Spiking Processing and Hardware Approach,"Mathematics, vol. 10, no. 612, pp. 1–16, Feb. 2022
2022
-
[17]
Neural Coding in Spiking Neural Networks: A Comparative Study for Robust Neuromorphic Systems,
W. Guo, M. E. Fouda, A. M. Eltawil, and K. N. Salama, "Neural Coding in Spiking Neural Networks: A Comparative Study for Robust Neuromorphic Systems,"Front. Neurosci., vol. 15, Art. 638474, pp. 1–17, Mar. 2021
2021
-
[18]
Spiking Neural Networks Hardware Implementations and Challenges: A Survey,
M. Bouvier, A. Valentian, T. Mesquida, F. Rummens, M. Reyboz, E. Vianello, and E. Beigne, "Spiking Neural Networks Hardware Implementations and Challenges: A Survey,"J. Emerg. Technol. Comput. Syst., vol. 15, no. 2, Art. 22, pp. 1–35, Apr. 2019. 12 ReSComA PREPRINT
2019
-
[19]
Speed of processing in the human visual system,
S. Thorpe, D. Fize, and C. Marlot, "Speed of processing in the human visual system,"Nature, vol. 381, no. 6582, pp. 520–522, June 1996
1996
-
[20]
Conversion of analog to spiking neural networks using sparse temporal coding,
B. Rueckauer and S.-C. Liu, "Conversion of analog to spiking neural networks using sparse temporal coding," Proc. Int. Symp. Circuits and Systems (ISCAS), pp. 1–5, 2018
2018
-
[21]
Spike-based dynamic computing with asynchronous sensing-computing neuromorphic chip,
M. Yaoet al., "Spike-based dynamic computing with asynchronous sensing-computing neuromorphic chip,"Nat. Commun., vol. 15, Art. no. 4464, 2024
2024
-
[22]
Opportunities for neuromorphic computing algorithms and applications,
C. D. Schumanet al., "Opportunities for neuromorphic computing algorithms and applications,"Nat. Comput. Sci., vol. 2, pp. 10–19, Jan. 2022
2022
-
[23]
Embodied neuromorphic intelligence,
C. Bartolozzi, G. Indiveri, and E. Donati, "Embodied neuromorphic intelligence,"Nat. Commun., vol. 13, Art. no. 1024, Feb. 2022
2022
-
[24]
Brain-inspired computing needs a master plan,
A. Mehonic and A. J. Kenyon, "Brain-inspired computing needs a master plan,"Nature, vol. 604, pp. 255–260, Apr. 2022
2022
-
[25]
ImageNet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, "ImageNet classification with deep convolutional neural networks," inProc. Adv. Neural Inf. Process. Syst., vol. 25, pp. 1097–1105, 2012
2012
-
[26]
Stochastic neural computation. I. Computational elements,
B. D. Brown and H. C. Card, "Stochastic neural computation. I. Computational elements,"IEEE Trans. Comput., vol. 50, no. 9, pp. 891–905, Sep. 2001
2001
-
[27]
Stochastic neural computation. II. Soft competitive learning,
B. D. Brown and H. C. Card, "Stochastic neural computation. II. Soft competitive learning,"IEEE Trans. Comput., vol. 50, no. 9, pp. 906–920, Sep. 2001
2001
-
[28]
Introduction to stochastic computing and its challenges,
J. P. Hayes, "Introduction to stochastic computing and its challenges," inProc. Design Autom. Conf. (DAC), 2015, p. 59
2015
-
[29]
Dimension reduction in statistical simulation of digital circuits,
A. Alaghi and J. P. Hayes, "Dimension reduction in statistical simulation of digital circuits," inProc. Symp. Theory Modeling Simulation, DEVS Integrative M&S Symp., 2015, pp. 1–8
2015
-
[30]
G. B. Orr and K.-R. Müller,Neural Networks: Tricks of the Trade. Berlin, Germany: Springer-Verlag, 2003
2003
-
[31]
Optimal stochastic computing randomization,
C. F. Frasser, M. Roca, and J. L. Rossello, "Optimal stochastic computing randomization,"Electronics, vol. 10, no. 23, p. 2985, 2021
2021
-
[32]
Design of an efficient parallel random number generator using a single LFSR for stochastic computing,
D. Lee, H. Seo, and Y . Kim, "Design of an efficient parallel random number generator using a single LFSR for stochastic computing," in2024 International Conference on Artificial Intelligence in Information and Communi- cation (ICAIIC), pp. 775–777, 2024
2024
-
[33]
Hardware-efficient quantized stochastic computing with reduced precision stochastic number generator and LFSR-based counter,
D. Lee and Y . Kim, "Hardware-efficient quantized stochastic computing with reduced precision stochastic number generator and LFSR-based counter,"International Journal of Circuit Theory and Applications, vol. 53, no. 12, pp. 7281–7294, 2025
2025
-
[34]
The MNIST database of handwritten digits,
Y . LeCun and C. Cortes, "The MNIST database of handwritten digits," 1998. [Online]. Available: http://yann.lecun.com/exdb/mnist/. Accessed: May 2026
1998
-
[35]
Training Spiking Neural Networks Using Lessons From Deep Learning,
J. K. Eshraghianet al., "Training Spiking Neural Networks Using Lessons From Deep Learning,"Proc. IEEE, vol. 111, no. 9, pp. 1016–1054, Sept. 2023
2023
-
[36]
Minitaur, an Event-Driven FPGA-Based Spiking Network Accelerator,
D. Neil and S.-C. Liu, "Minitaur, an Event-Driven FPGA-Based Spiking Network Accelerator,"IEEE Trans. VLSI Syst., vol. 22, no. 12, pp. 2621–2628, Dec. 2014
2014
-
[37]
Energy Efficient Parallel Neuromorphic Architectures with Approximate Arithmetic on FPGA,
Q. Wanget al., "Energy Efficient Parallel Neuromorphic Architectures with Approximate Arithmetic on FPGA," Neurocomputing, vol. 221, pp. 146–158, Jan. 2017
2017
-
[38]
Darwin: A Neuromorphic Hardware Co-Processor Based on Spiking Neural Networks,
D. Maet al., "Darwin: A Neuromorphic Hardware Co-Processor Based on Spiking Neural Networks,"J. Syst. Archit., vol. 77, pp. 43–51, Jan. 2017
2017
-
[39]
A Fast and Energy-Efficient SNN Processor With Adaptive Clock/Event-Driven Computation Scheme and Online Learning,
S. Liet al., "A Fast and Energy-Efficient SNN Processor With Adaptive Clock/Event-Driven Computation Scheme and Online Learning,"IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 68, no. 4, pp. 1543–1552, Apr. 2021
2021
-
[40]
Spiker: an FPGA-Optimized Hardware Accelerator for Spiking Neural Networks,
A. Carpegna, A. Savino, and S. Di Carlo, "Spiker: an FPGA-Optimized Hardware Accelerator for Spiking Neural Networks," inProc. IEEE Comput. Soc. Annu. Symp. VLSI (ISVLSI), 2022, pp. 14–19. 13
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.