Differentially Private Hierarchical Heavy Hitters
Pith reviewed 2026-06-27 06:12 UTC · model grok-4.3
The pith
The relative error for residual counts in hierarchical heavy hitters stays independent of hierarchy height and heavy hitter count, while streaming frequency error is independent of space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The relative error in estimating the residual count for any prefix is independent of the height of the hierarchy and the number of heavy hitters in the stream. Meanwhile, in the streaming setting, the absolute error for estimating frequencies is independent of the available space, even as the approximation functions have global sensitivity linear in space.
What carries the argument
Sensitivity analysis of differentially private mechanisms for hierarchical heavy hitters that decouples error from hierarchy depth and space.
If this is right
- Private release of HHH is possible with error that does not scale with hierarchy height.
- Streaming HHH privacy maintains fixed absolute error irrespective of memory allocation.
- Residual count estimates retain relative accuracy without dependence on heavy hitter numbers.
Where Pith is reading between the lines
- These independence properties could extend to other hierarchical data summaries under privacy constraints.
- Network traffic analysis or web log processing might adopt private HHH with predictable error.
Load-bearing premise
The approximations used in the streaming setting, despite having global sensitivity linear in the available space, still support an absolute error bound that does not depend on that space.
What would settle it
Finding a hierarchy where the relative residual error grows proportionally with its height under the proposed private mechanism, or observing streaming frequency error that increases with allocated space.
Figures

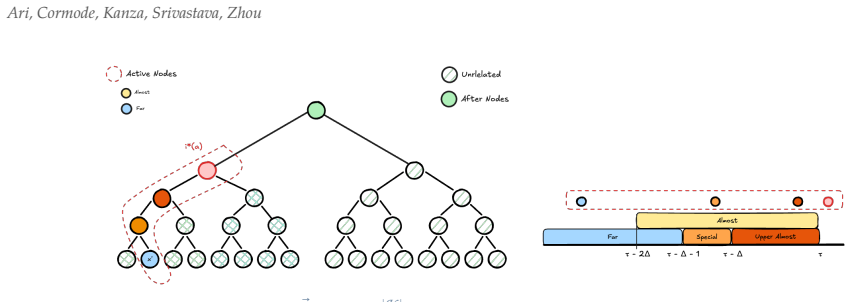
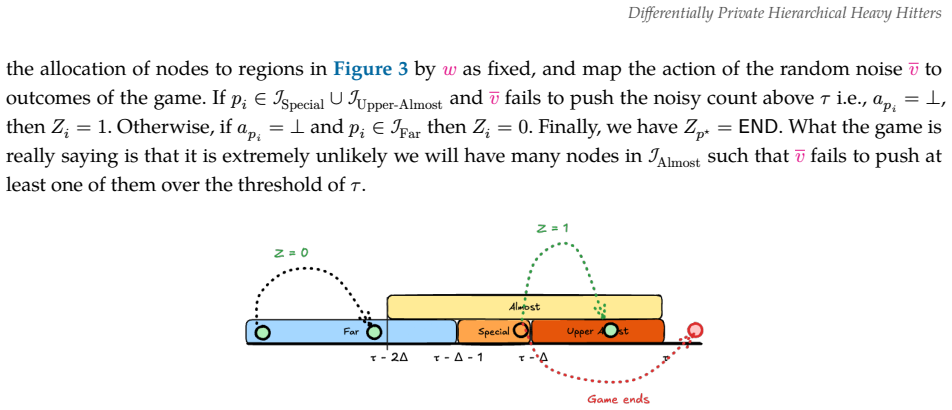

read the original abstract
The task of finding _Hierarchical_ Heavy Hitters (HHH) was introduced by Cormode et al. [VLDB 2003] as a generalisation of the heavy hitter problem. While finding HHH in data streams has been studied extensively, the question of releasing HHH when the underlying data is private remains unexplored. In this paper, we study differentially private HHH release in both the streaming and non-streaming setting. In the non-streaming setting, we show the surprising result that the relative error in estimating the residual count for any prefix is independent of the height of the hierarchy and the number of heavy hitters in the stream. Meanwhile, in the streaming setting, although the exact version of HHH has low global sensitivity (as counting queries are 1-sensitive), the approximation functions due to streaming have high global sensitivity, linear in the available space. Despite this obstacle, we show that the absolute error for estimating frequencies in the steaming setting is independent of the available space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies differentially private release of Hierarchical Heavy Hitters (HHH) in both non-streaming and streaming settings. It claims that in the non-streaming case the relative error when estimating the residual count for any prefix is independent of hierarchy height and the number of heavy hitters. In the streaming case it claims that, although the streaming approximations have global sensitivity linear in the available space, the absolute error when estimating frequencies remains independent of that space.
Significance. If the independence claims are rigorously established without hidden parameter dependence, the results would be notable for enabling DP HHH release whose error does not degrade with hierarchy depth or space budget. The non-streaming result in particular would be a useful addition to the literature on sensitivity analysis for hierarchical queries.
major comments (1)
- [Streaming Setting (sensitivity and error analysis)] The streaming independence claim (absolute error independent of space) is load-bearing for the paper's main contribution yet rests on an error analysis that must cancel or avoid the linear-in-space noise term arising from the stated global sensitivity. The manuscript must exhibit the concrete mechanism, post-processing step, or redefined sensitivity that produces this cancellation; without it the claim is at risk of circularity with the space parameter.
minor comments (2)
- [Abstract] The abstract and introduction should explicitly state the privacy parameter ε used in all bounds and whether the independence holds for fixed ε or scales with it.
- [Preliminaries] Notation for residual count and prefix should be defined once in a preliminary section before the claims are stated.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for highlighting the importance of a clear exposition of the streaming error analysis. We address the single major comment below.
read point-by-point responses
-
Referee: [Streaming Setting (sensitivity and error analysis)] The streaming independence claim (absolute error independent of space) is load-bearing for the paper's main contribution yet rests on an error analysis that must cancel or avoid the linear-in-space noise term arising from the stated global sensitivity. The manuscript must exhibit the concrete mechanism, post-processing step, or redefined sensitivity that produces this cancellation; without it the claim is at risk of circularity with the space parameter.
Authors: The manuscript derives the claimed independence in the streaming analysis by first adding noise scaled to the (space-linear) global sensitivity of the approximation functions and then applying a post-processing step that reconstructs frequency estimates from the noisy hierarchical counts. The absolute-error bound is obtained by combining the DP noise term with the additive approximation guarantee of the underlying streaming algorithm; the space-dependent component is shown to be dominated by a term whose magnitude is controlled by the hierarchy structure rather than by the space parameter itself. We acknowledge that the current write-up does not isolate this cancellation step in a single dedicated paragraph and therefore agree that the exposition should be strengthened. We will revise the manuscript to include an explicit description of the post-processing and the bounding argument that removes the linear dependence on space. revision: yes
Circularity Check
No circularity: error bounds derived from sensitivity analysis without reduction to inputs by construction
full rationale
The paper frames its main results as consequences of applying standard differential privacy mechanisms (Laplace/Gaussian) to hierarchical heavy hitters, with explicit statements that non-streaming relative error is independent of hierarchy height and streaming absolute error is independent of space despite linear sensitivity. These are presented as theorems proved from the definitions of global sensitivity and the HHH approximation functions, without any self-citation load-bearing the central claim, without renaming fitted parameters as predictions, and without ansatzes smuggled via prior work. The derivation chain is self-contained against the stated sensitivity bounds and does not reduce any claimed independence to a tautology or fitted input.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Differential privacy (epsilon-delta) definition
- domain assumption Hierarchical heavy hitters definition from Cormode et al. VLDB 2003
Reference graph
Works this paper leans on
-
[1]
Pankaj K Agarwal, Graham Cormode, Zengfeng Huang, Jeff M Phillips, Zhewei Wei, and Ke Yi. 2013. Mergeable summaries. ACM Transactions on Database Systems (TODS) 38, 4 (2013), 1–28
2013
-
[2]
Victor Balcer and Salil Vadhan. 2017. Differential privacy on finite computers. arXiv preprint arXiv:1709.05396 (2017)
Pith/arXiv arXiv 2017
-
[3]
Raef Bassily, Kobbi Nissim, Uri Stemmer, and Abhradeep Guha Thakurta. 2017. Practical locally private heavy hitters. Advances in Neural Information Processing Systems 30, (2017)
2017
-
[4]
Prosenjit Bose, Evangelos Kranakis, Pat Morin, and Yihui Tang. 2003. Bounds for Frequency Estimation of Packet Streams. In SIROCCO, 2003. 18–20
2003
-
[5]
Mark Bun and Thomas Steinke. 2016. Concentrated differential privacy: Simplifications, extensions, and lower bounds. In Theory of Cryptography Conference, 2016. 635–658
2016
-
[6]
Mark Bun, Kobbi Nissim, and Uri Stemmer. 2019. Simultaneous private learning of multiple concepts. Journal of Machine Learning Research 20, 94 (2019), 1–34
2019
-
[7]
Mark Bun, Thomas Steinke, and Jonathan Ullman. 2017. Make up your mind: The price of online queries in differential privacy. In Proceedings of the twenty-eighth annual ACM-SIAM symposium on discrete algorithms, 2017. 1306–1325
2017
-
[8]
T -H Hubert Chan, Mingfei Li, Elaine Shi, and Wenchang Xu. 2012. Differentially private continual monitoring of heavy hitters from distributed streams. In Privacy Enhancing Technologies: 12th Interna- tional Symposium, PETS 2012, Vigo, Spain, July 11-13, 2012. Proceedings 12, 2012. 140–159
2012
-
[9]
Yan Chen and Ashwin Machanavajjhala. 2015. On the privacy properties of variants on the sparse vector technique. arXiv preprint arXiv:1508.07306 (2015)
Pith/arXiv arXiv 2015
-
[10]
Albert Cheu. 2021. Differential privacy in the shuffle model: A survey of separations. arXiv preprint arXiv:2107.11839 (2021)
arXiv 2021
-
[11]
Graham Cormode, Flip Korn, S Muthukrishnan, and Divesh Srivastava. 2004. Diamond in the rough: Finding hierarchical heavy hitters in multi-dimensional data. In Proceedings of the 2004 ACM SIGMOD international conference on Management of data, 2004. 155–166
2004
-
[12]
Graham Cormode, Flip Korn, S Muthukrishnan, and Divesh Srivastava. 2008. Finding hierarchical heavy hitters in streaming data. ACM Transactions on Knowledge Discovery from Data (TKDD) 1, 4 (2008), 1–48
2008
-
[13]
Graham Cormode, Flip Korn, Shanmugavelayutham Muthukrishnan, and Divesh Srivastava. 2003. Finding hierarchical heavy hitters in data streams. In Proceedings 2003 VLDB Conference, 2003. 464–475
2003
-
[14]
Graham Cormode, Cecilia Procopiuc, Divesh Srivastava, and Thanh TL Tran. 2012. Differentially private summaries for sparse data. In Proceedings of the 15th International Conference on Database Theory,
2012
-
[15]
Henry Corrigan-Gibbs and Dan Boneh. 2017. Prio: Private, robust, and scalable computation of aggregate statistics. In 14th USENIX symposium on networked systems design and implementation (NSDI 17), 2017. 259–282
2017
-
[16]
Wei Dong, Dajun Sun, and Ke Yi. 2023. Better than Composition: How to Answer Multiple Relational Queries under Differential Privacy. Proceedings of the ACM on Management of Data 1, 2 (2023), 1–26. 34 Differentially Private Hierarchical Heavy Hitters
2023
-
[17]
Cynthia Dwork, Vitaly Feldman, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Aaron Leon Roth
-
[18]
In Proceedings of the forty-seventh annual ACM symposium on Theory of computing, 2015
Preserving statistical validity in adaptive data analysis. In Proceedings of the forty-seventh annual ACM symposium on Theory of computing, 2015. 117–126
2015
-
[19]
Cynthia Dwork, Frank McSherry, and Kunal Talwar. 2007. The price of privacy and the limits of LP decoding. In Proceedings of the thirty-ninth annual ACM symposium on Theory of computing, 2007. 85–94
2007
-
[20]
Cynthia Dwork, Moni Naor, Omer Reingold, Guy N Rothblum, and Salil Vadhan. 2009. On the com - plexity of differentially private data release: efficient algorithms and hardness results. In Proceedings of the forty-first annual ACM symposium on Theory of computing, 2009. 381–390
2009
-
[21]
Cynthia Dwork, Aaron Roth, and others. 2014. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science 9, 3–4 (2014), 211–407
2014
-
[22]
Cynthia Dwork, Guy N Rothblum, and Salil Vadhan. 2010. Boosting and differential privacy. In 2010 IEEE 51st Annual Symposium on Foundations of Computer Science, 2010. 51–60
2010
-
[23]
Alexander Edmonds, Aleksandar Nikolov, and Jonathan Ullman. 2020. The power of factorization mechanisms in local and central differential privacy. In Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, 2020. 425–438
2020
-
[24]
Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, and Kewen Wu. 2022. On Differentially Private Counting on Trees. arXiv preprint arXiv:2212.11967 (2022)
arXiv 2022
-
[25]
Arpita Ghosh, Tim Roughgarden, and Mukund Sundararajan. 2009. Universally utility-maximizing privacy mechanisms. In Proceedings of the forty-first annual ACM symposium on Theory of computing, 2009. 351–360
2009
-
[26]
Moritz Hardt and Kunal Talwar. 2010. On the geometry of differential privacy. In Proceedings of the forty-second ACM symposium on Theory of computing, 2010. 705–714
2010
-
[27]
John Hershberger, Nisheeth Shrivastava, Subhash Suri, and Csaba D Tóth. 2005. Space complexity of hierarchical heavy hitters in multi-dimensional data streams. In Proceedings of the twenty-fourth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems, 2005. 338–347
2005
-
[28]
Peter Kairouz, Sewoong Oh, and Pramod Viswanath. 2015. The composition theorem for differential privacy. In International conference on machine learning, 2015. 1376–1385
2015
-
[29]
Haim Kaplan, Yishay Mansour, and Uri Stemmer. 2021. The sparse vector technique, revisited. In Conference on Learning Theory, 2021. 2747–2776
2021
-
[30]
Aleksandra Korolova, Krishnaram Kenthapadi, Nina Mishra, and Alexandros Ntoulas. 2009. Releas - ing search queries and clicks privately. In Proceedings of the 18th international conference on World wide web, 2009. 171–180
2009
-
[31]
Christian Janos Lebeda and Jakub Tetek. 2023. Better differentially private approximate histograms and heavy hitters using the Misra-Gries sketch. In Proceedings of the 42nd ACM SIGMOD-SIGACT- SIGAI Symposium on Principles of Database Systems, 2023. 79–88
2023
-
[32]
Christian Janos Lebeda, David Erb, Tudor Cebere, and Aurélien Bellet. 2026. Lumberjack: Better Dif - ferentially Private Random Forests through Heavy Hitter Detection in Trees. Retrieved from https:// arxiv.org/abs/2605.22756
Pith/arXiv arXiv 2026
-
[33]
Michelle Seng Ah Lee and Luciano Floridi. 2021. Algorithmic fairness in mortgage lending: from absolute conditions to relational trade-offs. Minds and Machines 31, 1 (2021), 165–191. 35 Ari, Cormode, Kanza, Srivastava, Zhou
2021
-
[34]
Yuan Lin and Hongyan Liu. 2007. Separator: sifting hierarchical heavy hitters accurately from data streams. In Advanced Data Mining and Applications: Third International Conference, ADMA 2007 Harbin, China, August 6-8, 2007. Proceedings 3, 2007. 170–182
2007
-
[35]
Min Lyu, Dong Su, and Ninghui Li. 2016. Understanding the sparse vector technique for differential privacy. arXiv preprint arXiv:1603.01699 (2016)
Pith/arXiv arXiv 2016
-
[36]
Ahmed Metwally, Divyakant Agrawal, and Amr El Abbadi. 2006. An integrated efficient solution for computing frequent and top-k elements in data streams. ACM Transactions on Database Systems (TODS) 31, 3 (2006), 1095–1133
2006
-
[37]
Michael Mitzenmacher, Thomas Steinke, and Justin Thaler. 2012. Hierarchical heavy hitters with the space saving algorithm. In 2012 Proceedings of the Fourteenth Workshop on Algorithm Engineering and Experiments (ALENEX), 2012. 160–174
2012
-
[38]
Jack Murtagh and Salil Vadhan. 2015. The complexity of computing the optimal composition of differential privacy. In Theory of Cryptography Conference, 2015. 157–175
2015
-
[39]
Kobbi Nissim, Uri Stemmer, and Salil Vadhan. 2016. Locating a small cluster privately. In Proceedings of the 35th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, 2016. 413–427
2016
-
[40]
David Pujol and Damien Desfontaines. 2023. Open problem - Better privacy guarantees for larger groups
2023
-
[41]
Thomas Steinke and Jonathan Ullman. 2015. Between pure and approximate differential privacy. arXiv preprint arXiv:1501.06095 (2015)
Pith/arXiv arXiv 2015
-
[42]
Thomas Steinke. 2022. Composition of differential privacy & privacy amplification by subsampling. arXiv preprint arXiv:2210.00597 (2022)
arXiv 2022
-
[43]
Abhradeep Guha Thakurta and Adam Smith. 2013. Differentially private feature selection via stability arguments, and the robustness of the lasso. In Conference on Learning Theory, 2013. 819–850
2013
-
[44]
Jun Zhang, Xiaokui Xiao, and Xing Xie. 2016. Privtree: A differentially private algorithm for hierar - chical decompositions. In Proceedings of the 2016 international conference on management of data , 2016. 155–170
2016
-
[45]
Fuheng Zhao, Dan Qiao, Rachel Redberg, Divyakant Agrawal, Amr El Abbadi, and Yu-Xiang Wang
-
[46]
Advances in Neural Information Processing Systems 35, (2022), 12691–12704
Differentially private linear sketches: Efficient implementations and applications. Advances in Neural Information Processing Systems 35, (2022), 12691–12704. 36 Differentially Private Hierarchical Heavy Hitters A Composition and Structure Differential Privacy was initially motivated by the study of counting queries, and heavy hitter estimation can be see...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.