SkMTEB: Slovak Massive Text Embedding Benchmark and Model Adaptation
Pith reviewed 2026-06-27 06:37 UTC · model grok-4.3
The pith
Large instruction-tuned multilingual models outperform Slovak-specific NLU models on text embeddings, and adapted smaller versions compete with proprietary APIs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
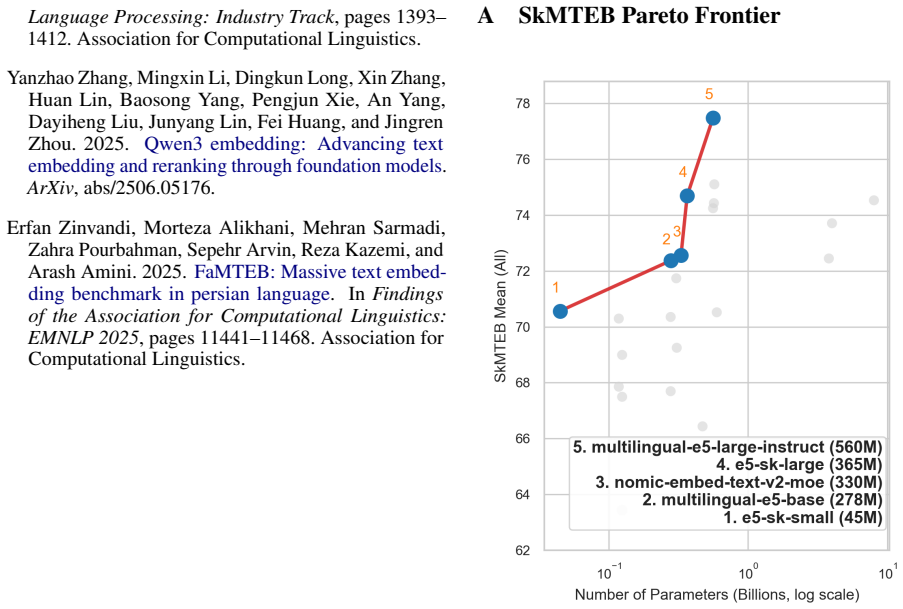
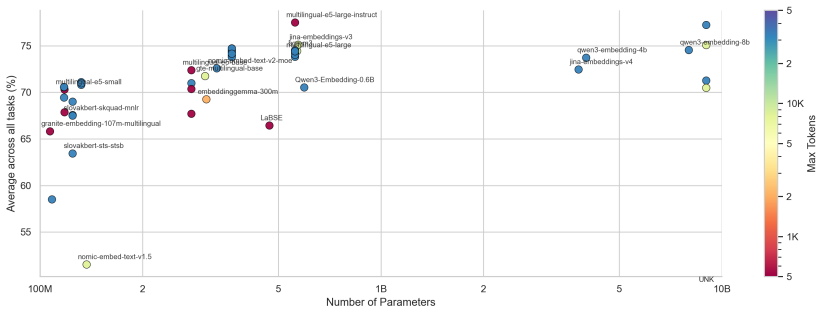
SkMTEB reveals that for Slovak embeddings, instruction-tuned multilingual models lead in performance, Slovak NLU models do not transfer effectively, and vocabulary-trimmed and fine-tuned versions of Multilingual E5 models deliver competitive results at reduced sizes suitable for local use.
What carries the argument
Vocabulary trimming and fine-tuning applied to Multilingual E5 models on the SkMTEB benchmark to produce smaller Slovak embedding models.
If this is right
- Large multilingual models are preferable for Slovak embedding tasks over language-specific NLU models.
- Model size can be reduced by up to 62% while maintaining competitive performance through adaptation.
- Open-source adapted models enable local semantic search and RAG without relying on proprietary APIs.
- The benchmark and adaptation method offer a template for other under-resourced languages.
Where Pith is reading between the lines
- Embedding tasks may require different training signals than traditional NLU tasks even in the same language.
- Similar adaptation techniques could reduce computational costs for embeddings in many low-resource settings.
- Performance gaps between open and closed models may narrow further with targeted fine-tuning on language-specific benchmarks.
Load-bearing premise
The 31 datasets across 7 task types represent a fair sample of actual Slovak embedding applications.
What would settle it
A new embedding model achieving substantially higher average scores on SkMTEB than the adapted e5-sk models, or a demonstration that key real-world Slovak use cases are missing from the benchmark.
Figures


read the original abstract
We introduce SkMTEB, the first comprehensive MTEB-style text embedding benchmark for Slovak, a low-resource West Slavic language, comprising 31 datasets across 7 task types -- nearly 4$\times$ the depth of existing multilingual benchmark coverage for Slovak. Our evaluation of 31 embedding models reveals that large instruction-tuned multilingual models achieve the strongest performance, while existing Slovak-specific models trained for NLU tasks transfer poorly to embedding tasks. To address the need for efficient, locally-deployable Slovak embeddings, we develop \texttt{e5-sk-small} (45M parameters) and \texttt{e5-sk-large} (365M) by applying vocabulary trimming and fine-tuning to Multilingual E5 models. Despite size reductions of up to 62\%, our open-source models achieve competitive performance with proprietary APIs while remaining locally deployable for semantic search and retrieval-augmented generation (RAG). We release the benchmark, models, datasets, and code openly, hoping our approach offers a replicable path for other under-resourced languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkMTEB, the first MTEB-style benchmark for Slovak text embeddings comprising 31 datasets across 7 task types (nearly 4× existing multilingual coverage for the language). It evaluates 31 embedding models, finding that large instruction-tuned multilingual models perform best while Slovak-specific NLU models transfer poorly to embeddings; it also presents vocabulary-trimmed and fine-tuned e5-sk-small (45M params) and e5-sk-large (365M params) models that achieve competitive results with proprietary APIs while remaining open-source and locally deployable for semantic search and RAG.
Significance. If the benchmark datasets are representative, the work supplies a much-needed evaluation resource for a low-resource language and demonstrates a replicable adaptation path (vocabulary trimming + fine-tuning) that yields practical, smaller open models. The open release of the benchmark, models, datasets, and code strengthens the contribution for the community working on multilingual embeddings.
major comments (2)
- [Abstract and dataset section] Abstract and § on dataset construction: the central performance claims (large instruction-tuned models dominate; e5-sk models are competitive with proprietary APIs) rest on the 31 datasets being a representative proxy for real Slovak semantic-search and RAG workloads, yet the manuscript supplies no quantitative evidence such as the fraction of native versus machine-translated text, domain-coverage statistics, or validation metrics on native data. This is load-bearing for the headline rankings and generalizability statements.
- [Model adaptation section] Model adaptation section (description of e5-sk-small/large): the vocabulary-trimming procedure and fine-tuning data/protocol are described at high level, but the manuscript does not report the exact trimming ratio, the composition or size of the fine-tuning corpus, or ablation results isolating the contribution of trimming versus fine-tuning; without these, the claim that the size reductions (up to 62%) preserve competitive performance cannot be fully assessed.
minor comments (2)
- [Results tables] Table reporting model sizes and scores: ensure all 31 models are listed with consistent parameter counts and that the two new e5-sk variants are clearly distinguished from the base Multilingual E5 models.
- [Abstract and introduction] The phrase “nearly 4× the depth of existing multilingual benchmark coverage” should be accompanied by an explicit citation or table comparing prior Slovak coverage to the new 31 datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper accordingly to improve transparency and support for our claims.
read point-by-point responses
-
Referee: [Abstract and dataset section] Abstract and § on dataset construction: the central performance claims (large instruction-tuned models dominate; e5-sk models are competitive with proprietary APIs) rest on the 31 datasets being a representative proxy for real Slovak semantic-search and RAG workloads, yet the manuscript supplies no quantitative evidence such as the fraction of native versus machine-translated text, domain-coverage statistics, or validation metrics on native data. This is load-bearing for the headline rankings and generalizability statements.
Authors: We agree that quantitative details on dataset composition would better substantiate the representativeness claims. The manuscript describes the 31 datasets and their sources but does not include breakdowns such as native vs. machine-translated fractions or domain statistics. In the revision we will add these metrics (e.g., a table reporting the proportion of native text per task type and domain coverage) drawn from the dataset documentation and curation process to strengthen the generalizability discussion. revision: yes
-
Referee: [Model adaptation section] Model adaptation section (description of e5-sk-small/large): the vocabulary-trimming procedure and fine-tuning data/protocol are described at high level, but the manuscript does not report the exact trimming ratio, the composition or size of the fine-tuning corpus, or ablation results isolating the contribution of trimming versus fine-tuning; without these, the claim that the size reductions (up to 62%) preserve competitive performance cannot be fully assessed.
Authors: We acknowledge the high-level description limits assessment of the adaptation method. We will expand the section to report the exact trimming ratios, the fine-tuning corpus size and composition (including sources and example counts), and any existing comparisons between trimmed and untrimmed variants. Full isolating ablations of trimming versus fine-tuning were not performed in the original experiments; we will therefore provide the requested details while noting this as a limitation and potential future direction. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces an empirical benchmark (SkMTEB with 31 datasets) and performs direct model evaluations plus standard vocabulary-trimming + fine-tuning adaptations on Multilingual E5. All performance claims rest on measured results against the new datasets rather than any self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. The representativeness of the 31 datasets is an external validity assumption, not a circularity in the reported chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MTEB-NL and E5-NL: Embedding bench- mark and models for dutch.arXiv preprint arXiv:2509.12340. Lucas Bandarkar, Davis Liang, Benjamin Muller, Mikel Artetxe, Satya Narayan Shukla, Donald Husa, Naman Goyal, Abhinandan Krishnan, Luke Zettlemoyer, and Madian Khabsa. 2024. The belebele benchmark: a parallel reading comprehension dataset in 122 lan- guage varia...
arXiv 2024
-
[2]
Kenneth Enevoldsen, Márton Kardos, Niklas Muen- nighoff, and Kristoffer Laigaard Nielbo
Webfaq: A multilingual collection of nat- ural q&a datasets for dense retrieval.Preprint, arXiv:2502.20936. Kenneth Enevoldsen, Márton Kardos, Niklas Muen- nighoff, and Kristoffer Laigaard Nielbo. 2024. The scandinavian embedding benchmarks: Comprehen- sive assessment of multilingual and monolingual text embedding. InAdvances in Neural Information Pro- ce...
arXiv 2024
-
[3]
InInternational Conference on Learning Representations
MMTEB: Massive multilingual text embed- ding benchmark. InInternational Conference on Learning Representations. Christian Federmann, Tom Kocmi, and Ying Xin. 2022. NTREX-128 – news test references for MT evalua- tion of 128 languages. InProceedings of the First Workshop on Scaling Up Multilingual Evaluation, pages 21–24, Online. Association for Computatio...
Pith/arXiv arXiv 2022
-
[4]
InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 16024–16036, Torino, Italy
The ParlaSent multilingual training dataset for sentiment identification in parliamentary proceed- ings. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 16024–16036, Torino, Italy. ELRA and ICCL. Sepideh Mollanorozy, Marc Tanti, and Malvina Nissim
2024
-
[5]
Cross-lingual transfer learning with Persian. InProceedings of the 5th Workshop on Research in Computational Linguistic Typology and Multilingual NLP, pages 89–95, Dubrovnik, Croatia. Association for Computational Linguistics. Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. 2023. MTEB: Massive text embedding benchmark. InProceedings of th...
arXiv 2023
-
[6]
The russian-focused embedders’ exploration: ruMTEB benchmark and Russian embedding model design. InProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies (Volume 1: Long Papers), pages 236–254, Albuquerque, New Mexico. Association for Compu- tational Linguistics. Zuz...
arXiv 2025
-
[7]
InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 14725–14739, Singapore
Efficient multilingual language model com- pression through vocabulary trimming. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 14725–14739, Singapore. Asso- ciation for Computational Linguistics. Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Pa- nyam, Sara Smoot, Iftekhar Naim, ...
2023
-
[8]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman
Embeddinggemma: Powerful and lightweight text representations.ArXiv, abs/2509.20354. Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for nat- ural language understanding. InProceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Net...
Pith/arXiv arXiv 2018
-
[9]
Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos
Association for Computational Linguistics. Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos. 2024. Arctic-embed 2.0: Multilingual retrieval without compromise.arXiv preprint arXiv:2412.04506. Biao Zhang, Philip Williams, Ivan Titov, and Rico Sen- nrich. 2020. Improving massively multilingual neu- ral machine translation and zero-shot translation. I...
arXiv 2024
-
[10]
Association for Computational Linguistics. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 embedding: Advancing text embedding and reranking through foundation models. ArXiv, abs/2506.05176. Erfan Zinvandi, Morteza Alikhani, Mehran Sarmadi...
Pith/arXiv arXiv 2025
-
[11]
Read an original Slovak sentence from the SlovakSum corpus
-
[12]
Generate six variant sentences, one for each STS score (0–5)
-
[13]
Provide a Slovak explanation justifying each score assignment
-
[14]
5, score 1 vs
Follow detailed score boundary definitions distinguishing between adjacent scores (e.g., score 4 vs. 5, score 1 vs. 2)
-
[15]
Maintain natural Slovak language quality suit- able for native speakers
-
[16]
nearly equivalent with minor gener- alizations
Return output in a structured JSON format. The prompt (in Figure 4) includes two complete worked examples demonstrating expected outputs for different source sentences. Key design choices include: Annotator pair Overall Accuracy Pearson Corr. Spearman Corr. Cohen’sκ [1,2] 0.67 0.94 0.94 0.60 [1,3] 0.63 0.91 0.92 0.56 [2,3] 0.61 0.93 0.93 0.53 Table 5: Pai...
-
[17]
Prečítať si jednu slovenskú vetu (ORIGINÁL)
-
[18]
0": {"sentence
Pre KAŽDÉ skóre podobnosti 0–5 (STS) vytvor: – jednu slovenskú vetu (VARIANT), – jedno krátke vysvetlenie v slovenčine. DEFINÍCIE SKÓRE 0–5 Všeobecné pravidlo:„Dôležitá informácia" = hlavná udalost’, aktér, miesto,ˇcas, množstvo, základná pointa. Ak zmeníš alebo vynecháš dôležitú informáciu, skóre NEMÔŽE byt’ 4 ani 5. Skóre 0– ÚPLNE INÁ TÉMA Vety sú o úpl...
2048
-
[19]
Compute token frequencies on FineWeb2-Slovak corpus
-
[20]
Rank tokens by frequency in target language
-
[21]
Retain top 60K tokens (recommended threshold from original paper)
-
[22]
Resize embedding and output projection matrices
-
[23]
Fine-tune on downstream tasks The 60K threshold was chosen based on the original vocabulary trimming paper’s recommendation, which found this value provides good coverage while maximizing compression. For comparison, MTEB- NL (Banar et al., 2025) uses 50K tokens for Dutch. F.4 Model and Data Availability All released models and datasets are collected on H...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.