The Slop Paradox: How Synthetic Standardization Erodes Clinical Uncertainty and Cross-Modal Alignment in AI-Rewritten Radiology Reports
Pith reviewed 2026-06-27 00:42 UTC · model grok-4.3
The pith
Rewriting radiology reports to standardize them degrades image-text alignment more than summarization does.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
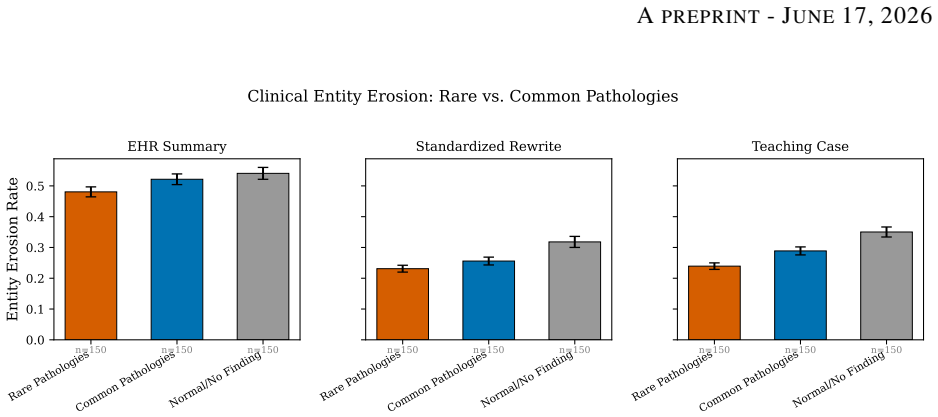
In a study of 450 chest X-ray reports, EHR summarization eroded 51.4% of clinical entities and 43.7% of hedging language with only a 2.5% drop in image-text alignment, whereas standardized rewriting and teaching case preparation eroded 26.8% and 29.3% of entities but caused 14.9-16.5% alignment drops. Rare pathologies showed no preferential degradation. The type of AI rewriting task is the dominant factor in degradation.
What carries the argument
Dissociation between content-level information loss and cross-modal alignment degradation, measured using medical NER for entities, hedging language counts, and BiomedCLIP similarity scores across the three rewriting tasks.
If this is right
- Multimodal training datasets from standardized reports may have reduced image correspondence.
- Governance of AI clinical documentation should account for alignment effects beyond content preservation.
- Condition-specific monitoring will not detect the main source of degradation since it is task-driven.
- AI-rewritten reports for training may introduce misalignment that affects downstream model performance.
Where Pith is reading between the lines
- Rewriting pipelines could incorporate explicit image conditioning to mitigate alignment loss.
- The paradox may extend to other medical imaging modalities or non-radiology reports.
- Human evaluation studies could validate whether the alignment metric corresponds to diagnostic utility.
Load-bearing premise
The metrics for entity erosion, hedging collapse, and image-text similarity via BiomedCLIP reflect meaningful clinical degradation and alignment changes.
What would settle it
A blinded study in which radiologists assess the clinical accuracy and image correspondence of original versus rewritten reports to check if the quantitative drops align with expert judgments.
Figures



read the original abstract
AI-assisted clinical documentation tools increasingly summarize, standardize, and reformat radiology reports using large language models (LLMs). We present a controlled measurement of the resulting information degradation. Using 450 chest X-ray reports from the Indiana University dataset, we generate synthetic versions via three realistic LLM rewriting tasks: EHR summarization, standardized rewriting, and teaching case preparation. We measure entity erosion (via medical NER), hedging collapse (loss of clinical uncertainty language), and cross-modal alignment degradation (via BiomedCLIP image-text similarity). Our central finding is a dissociation between information loss and cross-modal fidelity. EHR summarization is the most destructive at the content level, eroding 51.4% of clinical entities and 43.7% of hedging language, yet it preserves image-text alignment almost entirely (a 2.5% drop). The two tasks meant to produce cleaner training data, standardized rewriting and teaching case preparation, do the reverse: they preserve more entities (26.8% and 29.3% eroded) but cause 14.9-16.5% alignment drops, six to seven times those of EHR summarization. We term this the slop paradox: rewriting that makes clinical text look cleaner for multimodal training is precisely what pulls it away from the image. Contrary to our pre-specified hypothesis, rare pathologies were not preferentially degraded: across nine rare-versus-common comparisons, no difference survived multiple-comparison correction, and nominal differences ran in the opposite direction (common > rare), so contamination is invisible to condition-specific monitoring. The dominant determinant of degradation is the type of AI rewriting task, not the clinical content. These findings bear on multimodal medical AI dataset construction and the governance of AI-assisted clinical documentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM rewriting of radiology reports produces a 'slop paradox': EHR summarization erodes the most clinical entities (51.4%) and hedging language (43.7%) yet causes the smallest drop in BiomedCLIP image-text alignment (2.5%), while standardized rewriting and teaching-case preparation erode fewer entities (26.8–29.3%) but produce substantially larger alignment drops (14.9–16.5%). Using 450 Indiana University chest X-ray reports and automated metrics (medical NER, hedging detection, BiomedCLIP similarity), the authors conclude that rewriting task type—not clinical content—dominates degradation and that rare pathologies are not preferentially affected.
Significance. If the automated proxies are shown to track clinically meaningful loss and alignment, the dissociation result would directly inform best practices for constructing multimodal medical training corpora and for regulating AI-assisted documentation. The work’s use of a public dataset, named external tools, and pre-specified hypotheses is a strength that supports reproducibility.
major comments (2)
- [Methods (three measurement approaches)] The dissociation between content erosion and cross-modal fidelity (abstract and §4) is load-bearing for the central claim yet rests on the unvalidated assumption that medical NER, the chosen hedging rules, and BiomedCLIP similarity scores accurately reflect clinical information loss and diagnostic alignment. No radiologist judgment correlation or expert validation of these proxies is reported.
- [Results (rare-versus-common comparisons)] The claim that rare pathologies are not preferentially degraded (abstract) rests on nine rare-versus-common comparisons whose exact definition, statistical tests, multiple-comparison procedure, and error bars are not detailed enough for independent verification of the 'no difference survived correction' result.
minor comments (1)
- [Abstract] The abstract states specific percentages and a multiple-comparison outcome but omits the LLM models, prompt templates, exact hedging detection algorithm, and statistical software used; these details belong in the abstract or a methods summary table.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment below with point-by-point responses and indicate where revisions will be made to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [Methods (three measurement approaches)] The dissociation between content erosion and cross-modal fidelity (abstract and §4) is load-bearing for the central claim yet rests on the unvalidated assumption that medical NER, the chosen hedging rules, and BiomedCLIP similarity scores accurately reflect clinical information loss and diagnostic alignment. No radiologist judgment correlation or expert validation of these proxies is reported.
Authors: We appreciate the emphasis on proxy validation. The metrics were selected because medical NER tools have been validated in prior radiology NLP studies, hedging rules derive from established linguistic analyses of clinical uncertainty, and BiomedCLIP is a standard model for biomedical image-text similarity. We agree, however, that direct correlation with radiologist judgments is absent and constitutes a limitation. In revision we will add an explicit limitations subsection in the Discussion that acknowledges reliance on automated proxies, cites supporting validation literature for each tool, and outlines the need for future expert studies. This addition provides necessary context without altering the reported quantitative results. revision: partial
-
Referee: [Results (rare-versus-common comparisons)] The claim that rare pathologies are not preferentially degraded (abstract) rests on nine rare-versus-common comparisons whose exact definition, statistical tests, multiple-comparison procedure, and error bars are not detailed enough for independent verification of the 'no difference survived correction' result.
Authors: We concur that additional methodological detail is needed for independent verification. The nine comparisons were pre-specified and pair rare conditions (e.g., specific pneumothorax or effusion subtypes) against common ones using the same reports; statistical tests were Wilcoxon signed-rank or paired t-tests as appropriate, with Bonferroni correction applied across the nine tests. Error bars represent standard error. In the revised manuscript we will expand the Methods and Results sections to list the exact nine comparisons, report the precise statistical procedures, provide all corrected and uncorrected p-values, and ensure error bars are described (or added) in the relevant figure. These changes will enable full reproducibility of the finding that no differences survived correction. revision: yes
Circularity Check
No circularity: purely empirical measurements on public data with external tools
full rationale
The paper reports controlled experiments on 450 Indiana University chest X-ray reports, applying three LLM rewriting tasks and measuring outcomes via named external components (medical NER for entity erosion, hedging detection rules, and BiomedCLIP for image-text similarity). No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the abstract or described methods. The central dissociation finding is a direct comparison of observed percentages across tasks, not a reduction to any prior result or definition by construction. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BiomedCLIP similarity is a valid proxy for clinically relevant cross-modal alignment between rewritten reports and source images
- domain assumption The three LLM rewriting tasks (EHR summarization, standardized rewriting, teaching case preparation) are representative of real-world AI-assisted clinical documentation
invented entities (1)
-
Slop paradox
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Improving documentation quality and patient interaction with AI: a tool for transform- ing medical records.Journal of Medical Artificial Intelligence, 8:19, 2025
Pedro Angelo Basei de Paula, João Victor Bruneti Severino, Matheus Nespolo Berger, Maria Han Veiga, Karen Dyminski Parente Ribeiro, Fillipe Silveira Loures, Solano Amadori Todeschini, Eduardo Augusto Roeder, and Gustavo Lenci Marques. Improving documentation quality and patient interaction with AI: a tool for transform- ing medical records.Journal of Medi...
2025
-
[2]
Mohammad Alkhalaf, Ping Yu, Mengyang Yin, and Chao Deng. Applying generative AI with retrieval aug- mented generation to summarize and extract key clinical information from electronic health records.Journal of Biomedical Informatics, 156:104662, 2024
2024
-
[3]
Collaboration between clinicians and vision-language models in radiology report generation.Nature Medicine, 31(2):599–608, 2025
Ryutaro Tanno, David GT Barrett, Andrew Sellergren, Sumedh Ghaisas, Sumanth Dathathri, Abigail See, Jo- hannes Welbl, Charles Lau, Tao Tu, Shekoofeh Azizi, et al. Collaboration between clinicians and vision-language models in radiology report generation.Nature Medicine, 31(2):599–608, 2025
2025
-
[4]
Automated radiology report generation: A review of recent advances.IEEE Reviews in Biomedical Engineering, 18:368–387, 2024
Phillip Sloan, Philip Clatworthy, Edwin Simpson, and Majid Mirmehdi. Automated radiology report generation: A review of recent advances.IEEE Reviews in Biomedical Engineering, 18:368–387, 2024
2024
-
[5]
AI-generated clinical summaries require more than accuracy.JAMA, 331(8):637–638, 2024
Katherine E Goodman, Paul H Yi, and Daniel J Morgan. AI-generated clinical summaries require more than accuracy.JAMA, 331(8):637–638, 2024
2024
-
[6]
Resnik and Mohammad Hosseini
David B. Resnik and Mohammad Hosseini. The vicious spiral of AI slop.American Scientist, 114(2):86–89, Mar 2026
2026
-
[7]
Mohammad Samar Ansari. AI slop and data pollution in the age of generative AI: Strategic risks, economic consequences, and governance pathways for business, management, and the creative industries.Economic Con- sequences, and Governance Pathways for Business, Management, and the Creative Industries (October 23, 2025), 2025
2025
-
[8]
MediVLM: A vision language model for radiol- ogy report generation from medical images.Findings of the Association for Computational Linguistics: EMNLP, 2025:10287–10304, 2025
Debanjan Goswami, Ronast Subedi, and Shayok Chakraborty. MediVLM: A vision language model for radiol- ogy report generation from medical images.Findings of the Association for Computational Linguistics: EMNLP, 2025:10287–10304, 2025
2025
-
[9]
Takeshi Nakaura, Naofumi Yoshida, Naoki Kobayashi, Kaori Shiraishi, Yasunori Nagayama, Hiroyuki Uetani, Masafumi Kidoh, Masamichi Hokamura, Yoshinori Funama, and Toshinori Hirai. Preliminary assessment of automated radiology report generation with generative pre-trained transformers: comparing results to radiologist- generated reports.Japanese Journal of ...
2024
-
[10]
Paloma Rabaey, Jong Hak Moon, Jung-Oh Lee, Min Gwan Kim, Hangyul Yoon, Thomas Demeester, and Edward Choi. Modeling clinical uncertainty in radiology reports: from explicit uncertainty markers to implicit reasoning pathways.arXiv preprint arXiv:2511.04506, 2025
arXiv 2025
-
[11]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. BiomedCLIP: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915, 2023
Pith/arXiv arXiv 2023
-
[12]
Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 23(2):304–310, 2016
Dina Demner-Fushman, Marc D Kohli, Marc B Rosenman, Sonya E Shooshan, Laritza Rodriguez, Sameer Antani, George R Thoma, and Clement J McDonald. Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 23(2):304–310, 2016
2016
-
[13]
Context collapse: In-context learning and model collapse.arXiv preprint arXiv:2601.00923, 2026
Josef Ott. Context collapse: In-context learning and model collapse.arXiv preprint arXiv:2601.00923, 2026
arXiv 2026
-
[14]
Synthetic data in radiological imaging: current state and future outlook.BJR| Artificial Intelligence, 1(1):ubae007, 2024
Elena Sizikova, Andreu Badal, Jana G Delfino, Miguel Lago, Brandon Nelson, Niloufar Saharkhiz, Berkman Sahiner, Ghada Zamzmi, and Aldo Badano. Synthetic data in radiological imaging: current state and future outlook.BJR| Artificial Intelligence, 1(1):ubae007, 2024
2024
-
[15]
Samar Ansari. Compound deception in elite peer review: A failure mode taxonomy of 100 fabricated citations at neurips 2025.arXiv preprint arXiv:2602.05930, 2026
arXiv 2025
-
[16]
TGIAlign: Text-guided dual-branch bidirectional framework for cross-modal semantic alignment in medical vision-language.Computerized Medical Imaging and Graphics, page 102694, 2026
Wenhua Li, Lifang Wang, Min Zhao, Xingzhang Lü, and Linwen Yi. TGIAlign: Text-guided dual-branch bidirectional framework for cross-modal semantic alignment in medical vision-language.Computerized Medical Imaging and Graphics, page 102694, 2026. 9 APREPRINT- JUNE17, 2026
2026
-
[17]
Comparative development of BioMedCLIP for enhanced biomedical data integration
Praveen Pandey, Hiyaa Malik, Sofia Singh, Dipti Theng, Urvashi Agrawal, Raj Kumar, Sanjay Balwani, and Anoop Kumar Shukla. Comparative development of BioMedCLIP for enhanced biomedical data integration. Engineering, Technology & Applied Science Research, 16(1):30978–30983, 2026
2026
-
[18]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[19]
Scispacy: fast and robust models for biomedical natural language processing
Mark Neumann, Daniel King, Iz Beltagy, and Waleed Ammar. Scispacy: fast and robust models for biomedical natural language processing. InProceedings of the 18th BioNLP workshop and shared task, pages 319–327, 2019
2019
-
[20]
Gov- erning healthcare AI in the real world: How fairness, transparency, and human oversight can coexist.Sci, 8(2):36, 2026
Paolo Bailo, Giulio Nittari, Giuliano Pesel, Emerenziana Basello, Tommaso Spasari, and Giovanna Ricci. Gov- erning healthcare AI in the real world: How fairness, transparency, and human oversight can coexist.Sci, 8(2):36, 2026. 10
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.