ConSA: Controllable Sparsity in Hybrid Attention via Learnable Allocation
Pith reviewed 2026-06-27 00:30 UTC · model grok-4.3
The pith
A learnable method assigns full versus sliding-window attention to outperform hand-crafted rules at fixed sparsity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
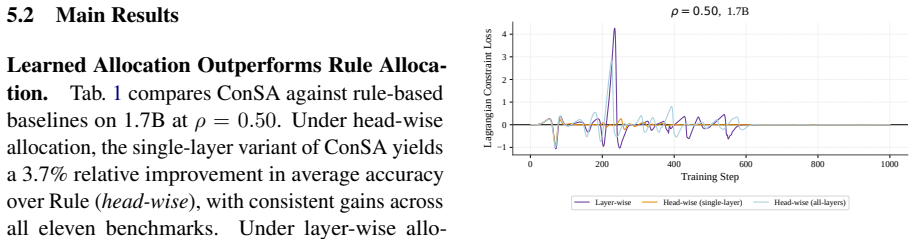
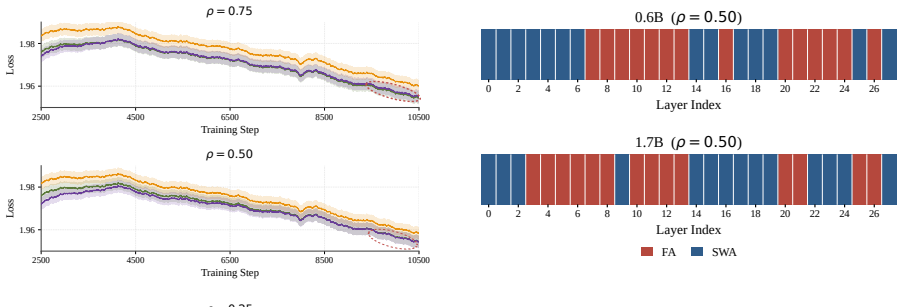
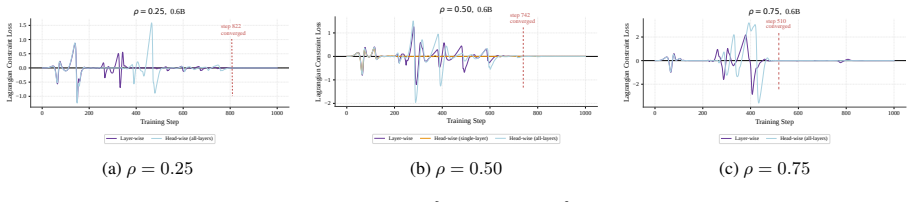
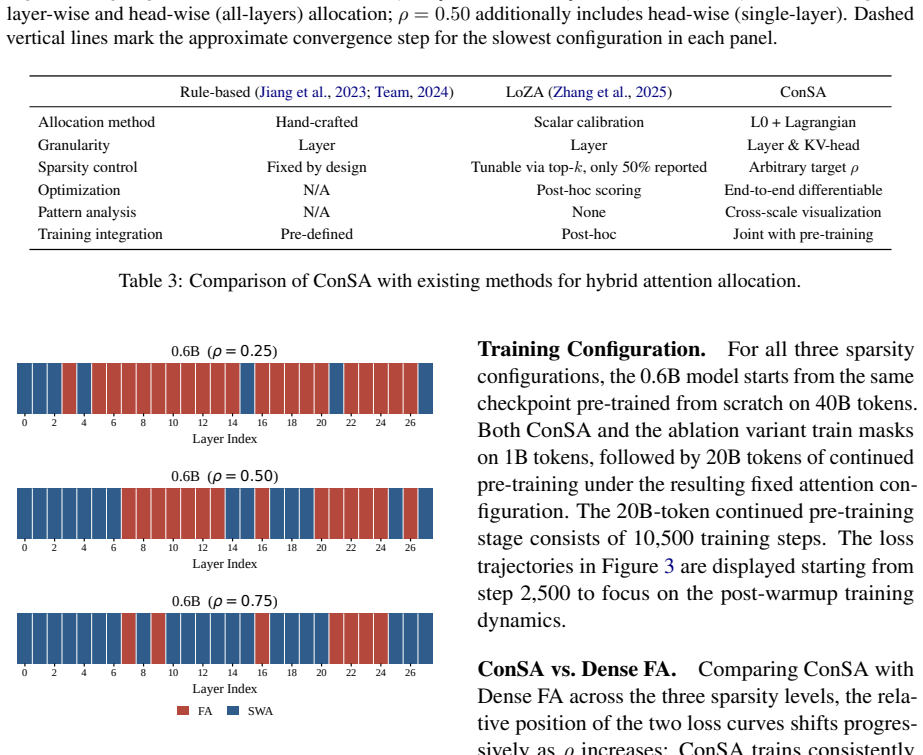
ConSA employs L0 regularization to learn binary masks selecting between full attention and sliding-window attention for each attention unit, while an augmented Lagrangian constraint enforces a user-specified sparsity target at either layer or KV-head granularity. The learned allocations place sliding-window attention in the bottom layers and concentrate full attention into contiguous middle-layer blocks. These patterns diverge from evenly interleaved designs in rule-based methods, persist across model scales and sparsity levels, and deliver higher downstream performance than the baselines.
What carries the argument
L0-regularized binary mask learning with augmented Lagrangian sparsity constraint applied at layer-wise or KV-head-wise granularity to select full attention versus sliding-window attention.
If this is right
- KV-head-wise allocation produces clearer gains than layer-wise allocation at the same sparsity.
- The learned pattern of bottom-layer sliding-window attention and contiguous middle-layer full attention blocks holds across the tested scales and sparsity targets.
- Learned allocations avoid the evenly interleaved patterns typical of rule-based methods.
- The approach achieves the sparsity target while maintaining performance without requiring extra recovery training.
Where Pith is reading between the lines
- If the contiguous middle-layer full-attention blocks turn out to be broadly optimal, the same block structure could be hard-coded into larger models without any learning step.
- The method could be extended to control other attention variants such as local-global or sparse attention patterns beyond sliding-window attention.
- Layer depth appears to correlate with preferred attention type in a non-uniform way that uniform interleaving overlooks.
- The same controllable-sparsity training could be tested on models larger than 1.7B to check whether the discovered pattern continues to hold.
Load-bearing premise
L0 regularization together with the augmented Lagrangian constraint can produce stable binary masks that preserve downstream performance at the target sparsity without post-training recovery steps.
What would settle it
Re-training or evaluating the models with the learned masks at the target sparsity and observing no accuracy gain over rule-based allocations at the same sparsity level, or finding that the bottom-SWA plus middle-FA block pattern fails to appear on a different model scale or architecture.
Figures











read the original abstract
Hybrid architectures combining full attention (FA) and sliding-window attention (SWA) are a promising paradigm for efficient LLM inference. However, existing methods typically rely on hand-crafted rules or simple post-hoc heuristics for FA/SWA allocation and offer limited analysis of the attention behaviors underlying these designs. We propose Controllable Sparsity in Hybrid Attention (ConSA), a framework that learns optimal FA/SWA assignment under a user-specified sparsity target. ConSA employs L0 regularization to learn binary masks selecting between FA and SWA for each attention unit, while an augmented Lagrangian constraint enforces the target sparsity at either layer or KV-head granularity. We evaluate ConSA on two LLMs at the 0.6B and 1.7B scales. Learned allocations consistently outperform rule-based baselines, with KV-head-wise allocation yielding clear gains over layer-wise allocation. The learned patterns place SWA in the bottom layers and concentrate FA into contiguous middle-layer blocks, diverging from evenly interleaved patterns in rule-based methods. This structure persists across model scales, sparsity levels, and allocation granularities, revealing a fine-grained spectrum of intrinsic attention behaviors that underlies the learned allocation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ConSA, a framework for learning optimal FA/SWA allocations in hybrid attention LLMs under a user-specified sparsity target. It employs L0 regularization to produce binary masks over attention units and an augmented Lagrangian multiplier to enforce the sparsity constraint at either layer-wise or KV-head-wise granularity. Evaluations are reported on 0.6B and 1.7B scale models, claiming that the learned allocations outperform rule-based baselines, that KV-head-wise allocation yields larger gains than layer-wise, and that the resulting patterns (SWA concentrated in bottom layers, FA in contiguous middle-layer blocks) are consistent across scales, sparsity levels, and granularities.
Significance. If the empirical results hold and the regularization reliably produces exact binary masks at the stated sparsity without post-training recovery, the work would supply a data-driven alternative to hand-crafted hybrid attention designs and could surface reproducible layer-wise attention preferences that generalize across model scales.
major comments (2)
- [Abstract] Abstract and evaluation sections: the central claim that learned allocations outperform rule-based baselines at user-specified sparsity requires evidence that the L0 term plus Lagrangian multiplier drives the allocation variables to exact binary values while preserving downstream performance; the provided text supplies no metrics on achieved vs. target sparsity, mask entropy at convergence, or post-mask recovery steps, leaving the attribution of gains to the allocation itself unverified.
- [Method] Method description of the augmented Lagrangian constraint: without reported analysis of constraint violation or binarity (e.g., fraction of mask entries strictly 0/1 at convergence), it is unclear whether the procedure meets the load-bearing assumption that stable binary masks are obtained at the target sparsity.
minor comments (1)
- [Abstract] The abstract refers to 'two LLMs at the 0.6B and 1.7B scales' but does not name the base models or datasets; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit verification of the binarity and sparsity enforcement mechanisms in ConSA. We agree these details strengthen the central claims and will incorporate the requested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation sections: the central claim that learned allocations outperform rule-based baselines at user-specified sparsity requires evidence that the L0 term plus Lagrangian multiplier drives the allocation variables to exact binary values while preserving downstream performance; the provided text supplies no metrics on achieved vs. target sparsity, mask entropy at convergence, or post-mask recovery steps, leaving the attribution of gains to the allocation itself unverified.
Authors: We acknowledge that the manuscript does not report quantitative metrics confirming that the L0 regularization and augmented Lagrangian produce exact binary masks at the target sparsity. The current presentation relies on the design of the objective to achieve this outcome. In revision we will add tables reporting achieved vs. target sparsity, mask entropy at convergence, and the fraction of entries that are exactly 0/1 without any post-training recovery, allowing direct attribution of performance gains to the learned allocations. revision: yes
-
Referee: [Method] Method description of the augmented Lagrangian constraint: without reported analysis of constraint violation or binarity (e.g., fraction of mask entries strictly 0/1 at convergence), it is unclear whether the procedure meets the load-bearing assumption that stable binary masks are obtained at the target sparsity.
Authors: The augmented Lagrangian term is introduced precisely to enforce the user-specified sparsity while the L0 penalty encourages binarity. We agree that empirical confirmation of constraint satisfaction and mask binarity is necessary to validate the assumption. In the revision we will include analysis of constraint violation (e.g., mean absolute deviation from target sparsity) and the percentage of mask entries that converge to exactly 0 or 1, reported across layers, granularities, and model scales. revision: yes
Circularity Check
No circularity: independent training procedure with external benchmarks
full rationale
The paper presents ConSA as a standard optimization framework that applies L0 regularization plus augmented Lagrangian to enforce user-specified sparsity on FA/SWA masks during training. The central claim (learned allocations outperform rule-based baselines) is evaluated by direct comparison on downstream LLM performance at fixed model scales, which constitutes an external benchmark rather than a quantity defined inside the method. No equations, derivations, or self-citations are shown that reduce the reported gains to a fitted parameter or to a self-referential definition. The method is self-contained against external validation and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption L0 regularization can be approximated to produce binary FA/SWA masks
- domain assumption Augmented Lagrangian can enforce exact sparsity targets at layer or KV-head level
Reference graph
Works this paper leans on
-
[1]
Albert Q. Jiang and Alexandre Sablayrolles and Arthur Mensch and Chris Bamford and Devendra Singh Chaplot and Diego de Las Casas and Florian Bressand and Gianna Lengyel and Guillaume Lample and Lucile Saulnier and L. Mistral 7B , journal =. 2023 , url =. doi:10.48550/ARXIV.2310.06825 , eprinttype =. 2310.06825 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
-
[2]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2408.00118 , eprinttype =. 2408.00118 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.00118 2024
-
[3]
Chen Zhang and Yang Bai and Jiahuan Li and Anchun Gui and Keheng Wang and Feifan Liu and Guanyu Wu and Yuwei Jiang and Defei Bu and Li Wei and Haihang Jing and Hongyin Tang and Xin Chen and Xiangzhou Huang and Fengcun Li and Rongxiang Weng and Yulei Qian and Yifan Lu and Yerui Sun and Jingang Wang and Yuchen Xie and Xunliang Cai , title =. CoRR , volume =...
-
[4]
Elena Voita and David Talbot and Fedor Moiseev and Rico Sennrich and Ivan Titov , editor =. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned , booktitle =. 2019 , url =. doi:10.18653/V1/P19-1580 , timestamp =
-
[5]
What Does BERT Look at? An Analysis of BERT ' s Attention
Kevin Clark and Urvashi Khandelwal and Omer Levy and Christopher D. Manning , editor =. What Does. Proceedings of the 2019. 2019 , url =. doi:10.18653/V1/W19-4828 , timestamp =
-
[6]
The Twelfth International Conference on Learning Representations,
Mengzhou Xia and Tianyu Gao and Zhiyuan Zeng and Danqi Chen , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[7]
Peters and Arman Cohan , title =
Iz Beltagy and Matthew E. Peters and Arman Cohan , title =. CoRR , volume =. 2020 , url =. 2004.05150 , timestamp =
Pith/arXiv arXiv 2020
-
[8]
Big Bird: Transformers for Longer Sequences , booktitle =
Manzil Zaheer and Guru Guruganesh and Kumar Avinava Dubey and Joshua Ainslie and Chris Alberti and Santiago Onta. Big Bird: Transformers for Longer Sequences , booktitle =. 2020 , url =
2020
-
[9]
Rewon Child and Scott Gray and Alec Radford and Ilya Sutskever , title =. CoRR , volume =. 2019 , url =. 1904.10509 , timestamp =
Pith/arXiv arXiv 2019
-
[10]
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention , booktitle =
Angelos Katharopoulos and Apoorv Vyas and Nikolaos Pappas and Fran. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention , booktitle =. 2020 , url =
2020
-
[11]
8th International Conference on Learning Representations,
Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya , title =. 8th International Conference on Learning Representations,. 2020 , url =
2020
-
[13]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2312.00752 , eprinttype =. 2312.00752 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.00752 2023
-
[14]
Gerber and Elad Dolev and Eran Krakovsky and Erez Safahi and Erez Schwartz and Gal Cohen and et al
Barak Lenz and Opher Lieber and Alan Arazi and Amir Bergman and Avshalom Manevich and Barak Peleg and Ben Aviram and Chen Almagor and Clara Fridman and Dan Padnos and Daniel Gissin and Daniel Jannai and Dor Muhlgay and Dor Zimberg and Edden M. Gerber and Elad Dolev and Eran Krakovsky and Erez Safahi and Erez Schwartz and Gal Cohen and et al. , title =. Th...
2025
-
[15]
The Thirteenth International Conference on Learning Representations,
Guangxuan Xiao and Jiaming Tang and Jingwei Zuo and Junxian Guo and Shang Yang and Haotian Tang and Yao Fu and Song Han , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[16]
Farnoosh Javadi and Walid Ahmed and Habib Hajimolahoseini and Foozhan Ataiefard and Mohammad Hassanpour and Saina Asani and Austin Wen and Omar Mohamed Awad and Kangling Liu and Yang Liu , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2311.03426 , eprinttype =. 2311.03426 , timestamp =
-
[17]
MiMo-V2-Flash Technical Report
LLM. MiMo-V2-Flash Technical Report , journal =. 2026 , url =. doi:10.48550/ARXIV.2601.02780 , eprinttype =. 2601.02780 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.02780 2026
-
[18]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. The Thirty-Fourth. 2020 , url =. doi:10.1609/AAAI.V34I05.6239 , timestamp =
-
[19]
9th International Conference on Learning Representations,
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[20]
Jian Liu and Leyang Cui and Hanmeng Liu and Dandan Huang and Yile Wang and Yue Zhang , editor =. LogiQA:. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence,. 2020 , url =. doi:10.24963/IJCAI.2020/501 , timestamp =
-
[21]
C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor and Jonathan Herzig and Nicholas Lourie and Jonathan Berant , editor =. CommonsenseQA:. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2019 , url =. doi:10.18653/V1/N19-1421 , timestamp =
-
[22]
Social IQa: Commonsense Reasoning about Social Interactions , booktitle =
Maarten Sap and Hannah Rashkin and Derek Chen and Ronan Le Bras and Yejin Choi , editor =. Social IQa: Commonsense Reasoning about Social Interactions , booktitle =. 2019 , url =. doi:10.18653/V1/D19-1454 , timestamp =
-
[23]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. CoRR , volume =. 2018 , url =. 1803.05457 , timestamp =
Pith/arXiv arXiv 2018
-
[24]
Rowan Zellers and Ari Holtzman and Yonatan Bisk and Ali Farhadi and Yejin Choi , editor =. HellaSwag: Can a Machine Really Finish Your Sentence? , booktitle =. 2019 , url =. doi:10.18653/V1/P19-1472 , timestamp =
-
[25]
2016 , eprint=
Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question Answering , author=. 2016 , eprint=
2016
-
[26]
Proceedings of the 29th International Conference on Computational Linguistics,
Yudong Li and Yuqing Zhang and Zhe Zhao and Linlin Shen and Weijie Liu and Weiquan Mao and Hui Zhang , editor =. Proceedings of the 29th International Conference on Computational Linguistics,. 2022 , url =
2022
-
[28]
International Conference on Learning Representations , year=
Learning Sparse Neural Networks through L\_0 Regularization , author=. International Conference on Learning Representations , year=
-
[29]
Switch Attention: Towards Dynamic and Fine-grained Hybrid Transformers
Yusheng Zhao and Hourun Li and Bohan Wu and Jingyang Yuan and Meng Zhang and Yichun Yin and Lifeng Shang and Ming Zhang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.26380 , eprinttype =. 2603.26380 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.26380 2026
-
[30]
Chen, Yao and Sheng, Jiawei and Zhang, Wenyuan and Liu, Tingwen. Improving Reasoning Capabilities in Small Models through Mixture-of-layers Distillation with Stepwise Attention on Key Information. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.250
-
[31]
Maurice Weber and Daniel Y. Fu and Quentin Anthony and Yonatan Oren and Shane Adams and Anton Alexandrov and Xiaozhong Lyu and Huu Nguyen and Xiaozhe Yao and Virginia Adams and Ben Athiwaratkun and Rahul Chalamala and Kezhen Chen and Max Ryabinin and Tri Dao and Percy Liang and Christopher R. RedPajama: an Open Dataset for Training Large Language Models ,...
2024
-
[32]
Yijiong Yu and Ziyun Dai and Zekun Wang and Wei Wang and Ran Chen and Ji Pei , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.08197 , eprinttype =. 2501.08197 , timestamp =
-
[33]
Yushi Bai and Xin Lv and Jiajie Zhang and Hongchang Lyu and Jiankai Tang and Zhidian Huang and Zhengxiao Du and Xiao Liu and Aohan Zeng and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , editor =. LongBench:. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V...
-
[35]
Luyang Huang and Shuyang Cao and Nikolaus Nova Parulian and Heng Ji and Lu Wang , editor =. Efficient Attentions for Long Document Summarization , booktitle =. 2021 , url =. doi:10.18653/V1/2021.NAACL-MAIN.112 , timestamp =
-
[36]
Zhilin Yang and Peng Qi and Saizheng Zhang and Yoshua Bengio and William W. Cohen and Ruslan Salakhutdinov and Christopher D. Manning , editor =. HotpotQA:. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018 , pages =. 2018 , url =. doi:10.18653/V1/D18-1259 , timestamp =
-
[37]
Musique: Multihop questions via single-hop question composition.Trans
Nelson F. Liu and Kevin Lin and John Hewitt and Ashwin Paranjape and Michele Bevilacqua and Fabio Petroni and Percy Liang , title =. Trans. Assoc. Comput. Linguistics , volume =. 2024 , url =. doi:10.1162/TACL\_A\_00638 , timestamp =
work page internal anchor Pith review doi:10.1162/tacl 2024
-
[38]
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph Gonzalez and Hao Zhang and Ion Stoica , editor =. Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =. 2023 , url =. doi:10.1145/3600006.3613165 , timestamp =
-
[39]
InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory , booktitle =
Chaojun Xiao and Pengle Zhang and Xu Han and Guangxuan Xiao and Yankai Lin and Zhengyan Zhang and Zhiyuan Liu and Maosong Sun , editor =. InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory , booktitle =. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.