Qwen-RobotNav Technical Report: A Scalable Navigation Model Designed for an Agentic Navigation System
Pith reviewed 2026-06-27 00:25 UTC · model grok-4.3
The pith
A single navigation model reconfigures its observation strategy at inference time for different tasks without architectural changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
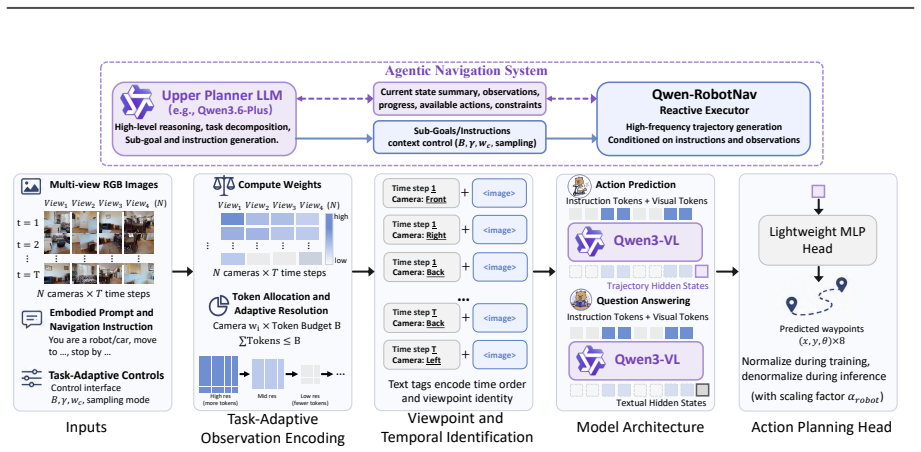
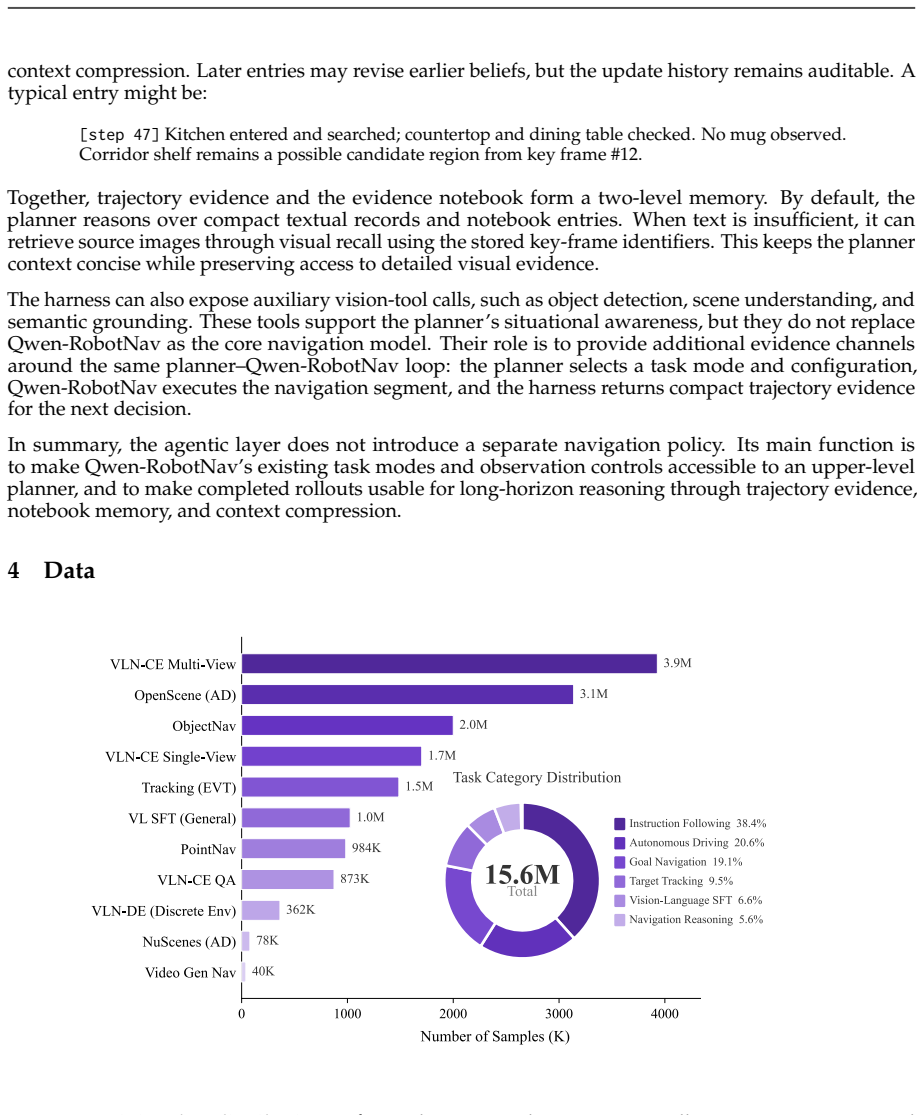
Qwen-RobotNav addresses the need for a base navigation model in agentic systems by providing a parameterized interface with task modes that select navigation behavior and controllable observation parameters that govern visual history encoding. Training-time randomization over all parameters ensures robustness to any inference-time configuration with no changes to the backbone model. Co-training with vision-language data on 15.6M samples prevents collapse to reactive mappers, resulting in new state-of-the-art results on major benchmarks, favorable scaling from 2B to 8B parameters, a shared spatial-planning substrate across tasks, and strong zero-shot generalization to real-world robots.
What carries the argument
The parameterized interface consisting of multiple task modes and controllable observation parameters, which enables external reconfiguration of the visual stream consumption strategy at inference time while using the same perception-planning backbone.
If this is right
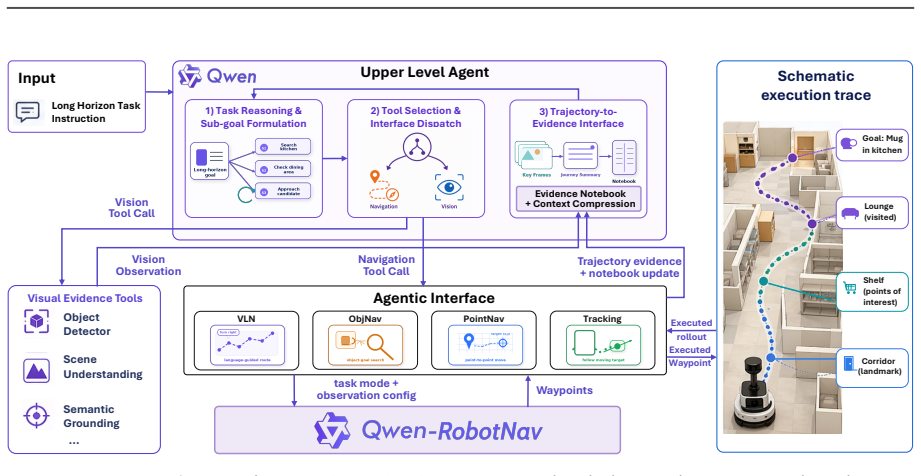
- For long-horizon scenarios, an upper-level planner can decompose goals into sub-tasks and switch the model's task mode and context strategy mid-episode.
- Joint multi-task training develops a shared spatial-planning substrate that transfers across task families.
- The model shows favorable scaling behavior from 2B to 8B parameters.
- Qwen-RobotNav demonstrates strong zero-shot generalization to real-world robots in diverse environments.
Where Pith is reading between the lines
- The approach suggests that a single backbone can serve as a modular component in larger agentic systems by allowing dynamic task switching.
- Co-training with vision-language data may help preserve general reasoning capabilities that pure trajectory training loses.
- Such models could be tested for integration with higher-level planners in simulated long-horizon tasks to verify composability.
Load-bearing premise
That randomizing parameters during training is sufficient to make the model perform well on any combination of task modes and observation parameters at inference time.
What would settle it
A test where the model is evaluated on inference configurations with token budgets or camera weights outside the range randomized during training, checking if performance drops significantly compared to seen configurations.
Figures







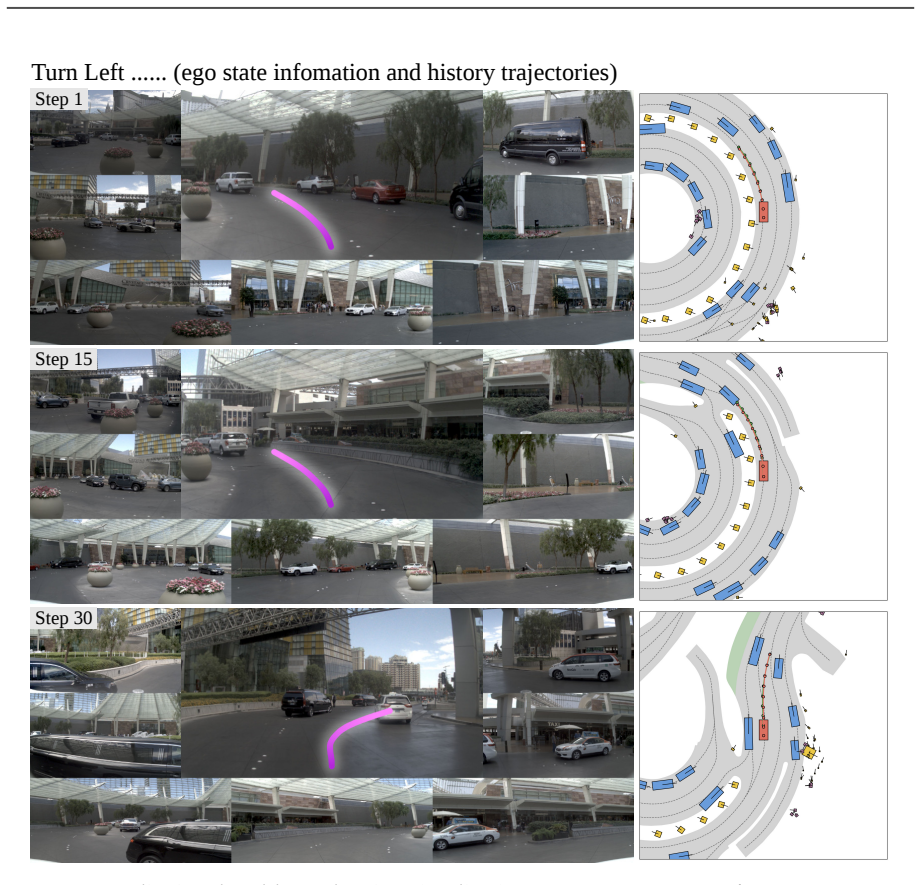

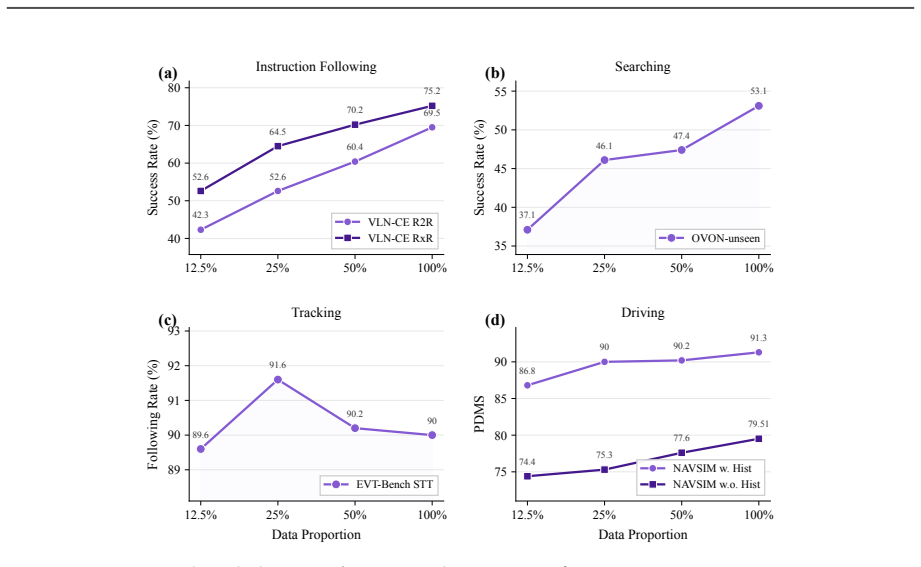
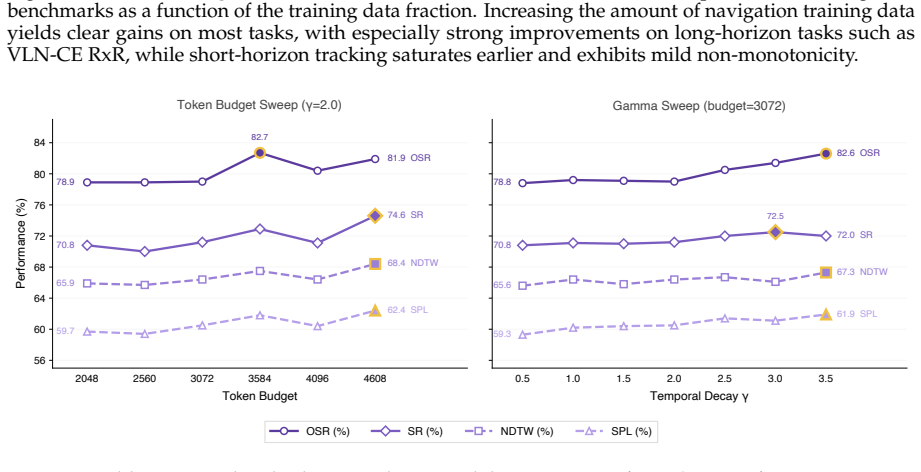


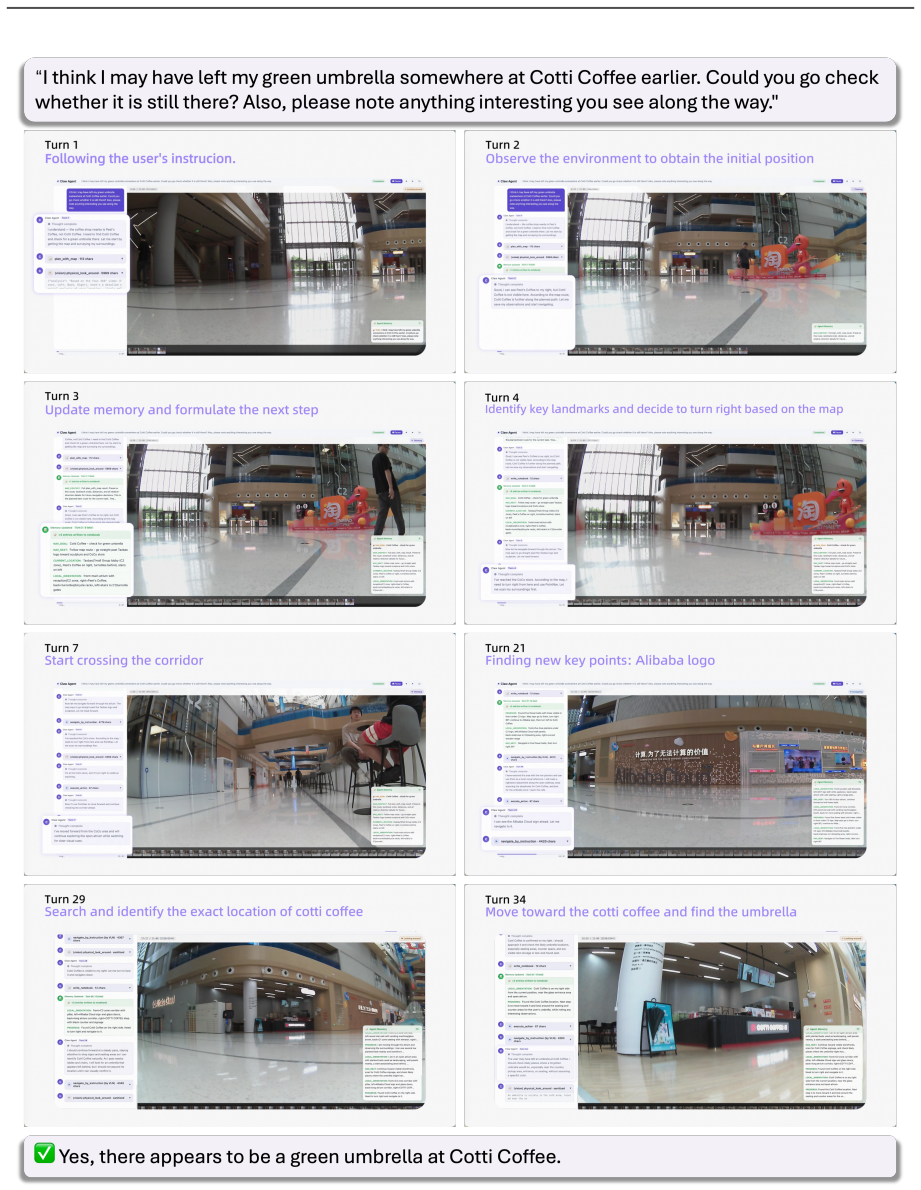
read the original abstract
Agentic navigation systems require a base navigation model whose observation strategy can be externally reconfigured at inference time, because instruction following, object search, target tracking, and autonomous driving share the same perception-planning backbone yet demand fundamentally different strategies for consuming the visual stream. We present Qwen-RobotNav, a scalable navigation model built on Qwen-RobotNav that addresses it through a parameterised interface with two complementary dimensions: multiple task modes that select the navigation behaviour, and controllable observation parameters (e.g., token budget, per-camera weights) that govern how visual history is encoded. With training-time randomization over all parameters, Qwen-RobotNav is robust to any inference-time configuration requiring zero architectural modification to the Qwen-RobotNav backbone. We train Qwen-RobotNav on 15.6M samples; co-training with vision-language data prevents the collapse into reactive action-sequence mappers observed in trajectory-only training. The parameterised interface also makes Qwen-RobotNav a natural building block for agentic systems: for long-horizon scenarios, an upper-level planner decomposes goals into sub-tasks and dynamically switches Qwen-RobotNav's task mode and context strategy mid-episode, composing complex behaviours from repeated calls to the same model. Extensive experiments show that Qwen-RobotNav sets new state-of-the-art results across major navigation benchmarks. The model exhibits favourable scaling from 2B to 8B parameters, with joint multi-task training developing a shared spatial-planning substrate that transfers across task families, and demonstrates strong zero-shot generalisation to real-world robots across diverse environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Qwen-RobotNav, a scalable navigation model extending the Qwen architecture with a parameterized interface of task modes and controllable observation parameters (token budget, per-camera weights, history lengths). It claims that training-time randomization over all parameters renders the model robust to arbitrary inference-time configurations with zero architectural modification to the backbone. Trained on 15.6M samples with co-training on vision-language data to avoid collapse into reactive mappers, the model is positioned as a building block for agentic systems where an upper-level planner dynamically switches modes mid-episode. The manuscript asserts new SOTA results on major navigation benchmarks, favorable scaling from 2B to 8B parameters, development of a shared spatial-planning substrate via multi-task training, and strong zero-shot generalization to real-world robots.
Significance. If the robustness, scaling, and generalization claims hold under rigorous evaluation, the work would offer a practical, reconfigurable backbone for agentic navigation, enabling flexible composition of behaviors across task families without per-task retraining or architectural changes. The design choice of joint multi-task training with vision-language data to maintain planning capability, together with the explicit support for dynamic switching, addresses a genuine need in long-horizon robotic systems and could influence how VLMs are integrated into planners.
major comments (3)
- [Abstract] Abstract: The central claim that Qwen-RobotNav 'sets new state-of-the-art results across major navigation benchmarks' is unsupported by any quantitative metrics, baseline comparisons, evaluation protocols, or error analysis. This absence is load-bearing because the SOTA assertion, scaling behavior, and zero-shot generalization are the primary empirical contributions.
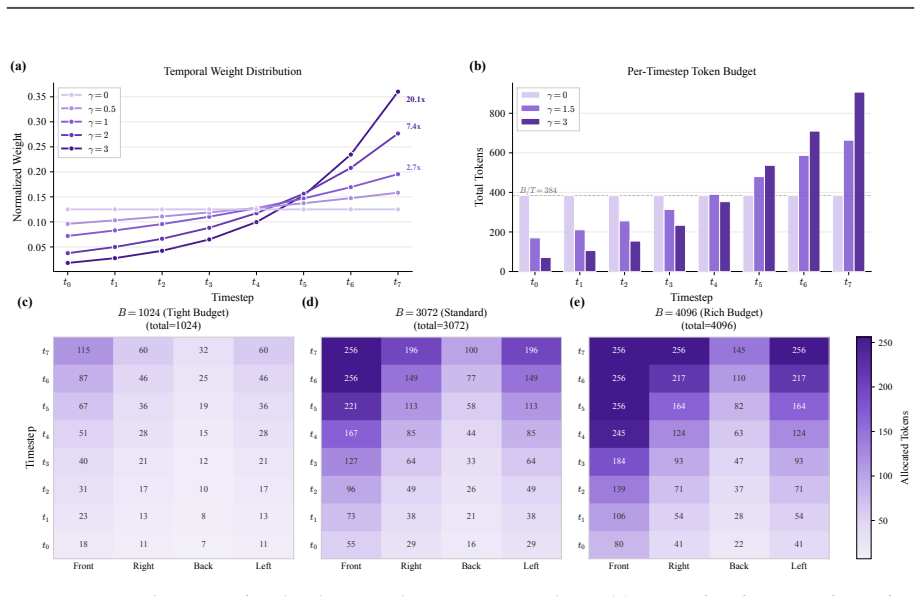
- [Method / Training procedure] Description of the parameterized interface and training procedure: The claim that 'training-time randomization over all parameters' makes the model 'robust to any inference-time configuration' with 'zero architectural modification' lacks any specification of randomization ranges, distributions, or support coverage for inference settings (token budgets, history lengths, camera weights). No ablations against non-randomized baselines or held-out configuration tests are referenced, leaving the transfer argument for long-horizon planner-driven switching unanchored.
- [Experiments] Experiments section: The statements of 'favourable scaling from 2B to 8B parameters' and 'strong zero-shot generalisation to real-world robots' are presented without performance tables, curves, or details on the real-robot environments, success criteria, or comparison to prior zero-shot methods. These omissions prevent assessment of whether the shared spatial-planning substrate actually transfers as asserted.
minor comments (2)
- [Abstract] Abstract contains a clear naming inconsistency: 'a scalable navigation model built on Qwen-RobotNav' repeats the model name; the intended base model (Qwen-VL or similar) should be stated explicitly.
- [Method] The manuscript provides no equations or formal notation defining the task-mode embedding or the observation-parameter interface, making the 'parameterised interface' description difficult to reproduce or extend.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential value of a reconfigurable navigation backbone for agentic systems. We agree that the current manuscript version requires additional quantitative detail to fully support its central claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Qwen-RobotNav 'sets new state-of-the-art results across major navigation benchmarks' is unsupported by any quantitative metrics, baseline comparisons, evaluation protocols, or error analysis. This absence is load-bearing because the SOTA assertion, scaling behavior, and zero-shot generalization are the primary empirical contributions.
Authors: We agree the abstract claim is insufficiently anchored. The Experiments section of the manuscript contains the supporting tables and protocols, but to make the connection explicit we will revise the abstract to include the key quantitative deltas versus prior SOTA (e.g., success-rate improvements on the primary benchmarks) together with a direct pointer to the evaluation protocol and error analysis. revision: yes
-
Referee: [Method / Training procedure] Description of the parameterized interface and training procedure: The claim that 'training-time randomization over all parameters' makes the model 'robust to any inference-time configuration' with 'zero architectural modification' lacks any specification of randomization ranges, distributions, or support coverage for inference settings (token budgets, history lengths, camera weights). No ablations against non-randomized baselines or held-out configuration tests are referenced, leaving the transfer argument for long-horizon planner-driven switching unanchored.
Authors: We will expand the training-procedure subsection to list the precise randomization ranges and sampling distributions (token budget: uniform [128,4096]; history length: uniform [1,16]; per-camera weights: Dirichlet(1,…,1) normalized to sum to 1). We will also insert an ablation table contrasting randomized versus fixed-parameter training and a held-out configuration test that simulates planner-driven mid-episode switches. revision: yes
-
Referee: [Experiments] Experiments section: The statements of 'favourable scaling from 2B to 8B parameters' and 'strong zero-shot generalisation to real-world robots' are presented without performance tables, curves, or details on the real-robot environments, success criteria, or comparison to prior zero-shot methods. These omissions prevent assessment of whether the shared spatial-planning substrate actually transfers as asserted.
Authors: We will add (i) a scaling table and log-log plot of success rate versus parameter count from 2 B to 8 B, (ii) a dedicated real-world subsection specifying the robot platforms, sensor configurations, success criteria (navigation success rate and SPL), and environment diversity, and (iii) direct numerical comparisons against published zero-shot baselines. These additions will allow readers to evaluate transfer of the shared spatial-planning substrate. revision: yes
Circularity Check
No significant circularity; empirical claims rest on training and evaluation without self-referential derivations
full rationale
The paper contains no equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations. The central robustness claim is an empirical assertion about training-time randomization over parameters, not a mathematical reduction that equates to its own inputs by construction. All reported results (scaling, SOTA benchmarks, zero-shot transfer) are presented as outcomes of data collection and model training rather than tautological re-statements of the training procedure itself. This is a standard empirical technical report with no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Training-time randomization over task modes and observation parameters ensures robustness to any inference-time configuration without architectural modification
- domain assumption Co-training with vision-language data prevents collapse into reactive action-sequence mappers
Reference graph
Works this paper leans on
-
[1]
ObjectNav revisited: On evaluation of embodied agents navigating to objects
Dhruv Batra, Aaron Gokaslan, Aniruddha Kembhavi, Oleksandr Maksymets, Roozbeh Mottaghi, Manolis Savva, Alexander Toshev, and Erik Wijmans. ObjectNav revisited: On evaluation of embodied agents navigating to objects. InarXiv preprint arXiv:2006.13171,
arXiv 2006
-
[2]
Yihan Cao, Jiazhao Zhang, Zhinan Yu, Shuzhen Liu, Zheng Qin, Qin Zou, Bo Du, and Kai Xu
URLhttps://internrobotics.github.io/internvla-n1.github.io/. Yihan Cao, Jiazhao Zhang, Zhinan Yu, Shuzhen Liu, Zheng Qin, Qin Zou, Bo Du, and Kai Xu. Cognav: Cognitive process modeling for object goal navigation with llms.arXiv preprint arXiv:2412.10439,
-
[3]
†Project lead
*Equal contribution. †Project lead. ‡Corresponding author. 31 Angel X. Chang, Angela Dai, Thomas A. Funkhouser, Maciej Halber, Matthias Nießner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from RGB-D data in indoor environments. In2017 International Conference on 3D Vision, 3DV 2017, Qingdao, China, October 10- 12, 2017,...
2017
-
[4]
In: 2016 fourth international conference on 3D vision (3DV)
doi: 10.1109/3DV .2017.00081. URL https: //doi.org/10.1109/3DV.2017.00081. Yitong Chen, Lingchen Meng, Wujian Peng, Zuxuan Wu, and Yu-Gang Jiang. Comp: Continual multi- modal pre-training for vision foundation models.arXiv preprint arXiv:2503.18931, 2025a. Yuntao Chen, Yuqi Wang, and Zhaoxiang Zhang. Drivinggpt: Unifying driving world modeling and plannin...
work page doi:10.1109/3dv 2017
-
[5]
Weijing Hu, Jun Wang, Teng Hu, Jiteng Chen, Siwen Xue, Yufeng Yue, Haoran Xie, Weixun Zhang, Huchuan Lu, Zongqing Lu, Haibin He, and Bolei Wang. OmniNav: A unified framework for prospec- tive exploration and visual-language navigation.arXiv preprint arXiv:2510.06436,
-
[6]
AstraNav-World: World model for foresight control and consistency.arXiv preprint arXiv:2603.23745,
Weijing Hu, Jun Wang, Teng Hu, Jiteng Chen, Siwen Xue, Yufeng Yue, Yanyun Wu, Haibin He, Bolei Wang, Huchuan Lu, and Zongqing Lu. AstraNav-World: World model for foresight control and consistency.arXiv preprint arXiv:2603.23745,
-
[7]
Beyond the destination: A novel benchmark for exploration-aware embodied question answering
Kaixuan Jiang, Yang Liu, Weixing Chen, Jingzhou Luo, Ziliang Chen, Ling Pan, Guanbin Li, and Liang Lin. Beyond the destination: A novel benchmark for exploration-aware embodied question answering. InIEEE/CVF International Conference on Computer Vision, ICCV 2025, Honolulu, HI, USA, October 19-25, 2025, pp. 9091–9101. IEEE,
2025
-
[8]
Figureqa: An annotated figure dataset for visual reasoning.arXiv preprint arXiv:1710.07300,
Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkinson, Ákos Kádár, Adam Trischler, and Yoshua Bengio. Figureqa: An annotated figure dataset for visual reasoning.arXiv preprint arXiv:1710.07300,
-
[9]
32 Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara L. Berg. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL, pp. 787–798. ACL,
2014
-
[10]
R efer I t G ame: Referring to Objects in Photographs of Natural Scenes
doi: 10.3115/V1/D14-1086. URL https: //doi.org/10.3115/v1/d14-1086. Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision-and-language navigation in continuous environments. InEuropean Conference on Computer Vision (ECCV),
-
[11]
Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding
Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 4392–4412,
2020
-
[12]
Yuxuan Kuang, Hai Lin, and Meng Jiang. Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models.arXiv preprint arXiv:2402.10670,
-
[13]
Memory centric power allocation for multi-agent embodied question answering
Chengyang Li, Shuai Wang, Kejiang Ye, Weijie Yuan, Boyu Zhou, Yik-Chung Wu, Cheng-Zhong Xu, and Huseyin Arslan. Memory centric power allocation for multi-agent embodied question answering. CoRR, abs/2604.17810, 2026a. Kailin Li, Zhenxin Li, Shiyi Lan, Yuan Xie, Zhizhong Zhang, Jiayi Liu, Zuxuan Wu, Zhiding Yu, and Jose M Alvarez. Hydra-mdp++: Advancing en...
-
[14]
End-to-end driving with online trajectory evaluation via bev world model
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via bev world model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 27137–27146, 2025b. Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bin...
-
[15]
Sihao Lin, Zerui Li, Xunyi Zhao, Gengze Zhou, Liuyi Wang, Rong Wei, Rui Tang, Juncheng Li, Hanqing Wang, Jiangmiao Pang, Anton van den Hengel, Jiajun Liu, and Qi Wu. Vlnverse: A benchmark for vision-language navigation with versatile, embodied, realistic simulation and evaluation.CoRR, abs/2512.19021,
-
[17]
Jiahang Liu, Yunpeng Qi, Jiazhao Zhang, Minghan Li, Shaoan Wang, Kui Wu, Hanjing Ye, Hong Zhang, Zhibo Chen, Fangwei Zhong, et al. Trackvla++: Unleashing reasoning and memory capabilities in vla models for embodied visual tracking.arXiv preprint arXiv:2510.07134,
-
[18]
Instructnav: Zero-shot system for generic instruction navigation in unexplored environment
Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. Instructnav: Zero-shot system for generic instruction navigation in unexplored environment. In Pulkit Agrawal, Oliver Kroemer, and Wolfram Burgard (eds.),Conference on Robot Learning, 6-9 November 2024, Munich, Germany, Proceedings of Machine Learning Research, pp. 2049–2060. PMLR,
2024
-
[19]
Decoupled weight decay regularization
33 Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9,
2019
-
[20]
Dujun Nie, Xianda Guo, Yiqun Duan, Ruijun Zhang, and Long Chen. Wmnav: Integrating vision- language models into world models for object goal navigation.arXiv preprint arXiv:2503.02247,
-
[21]
Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X
Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexan- der Clegg, John M. Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X. Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat-matterport 3d dataset (HM3D): 1000 large-scale 3d environments for embodied AI. InProceedings of the Neural Information Pro...
2021
-
[22]
URL https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/ 34173cb38f07f89ddbebc2ac9128303f-Abstract-round2.html. Allen Z. Ren, Jaden Clark, Anushri Dixit, Masha Itkina, Anirudha Majumdar, and Dorsa Sadigh. Explore until confident: Efficient exploration for embodied question answering. In Dana Kulic, Gentiane Venture, Kostas E. Bekris, and En...
2021
-
[23]
Habitat: A platform for embodied AI research
Manolis Savva, Jitendra Malik, Devi Parikh, Dhruv Batra, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, and Vladlen Koltun. Habitat: A platform for embodied AI research. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pp. 9338...
2019
-
[24]
Yolact: Real- time instance segmentation,
doi: 10.1109/ICCV .2019.00943. URLhttps://doi.org/10.1109/ICCV.2019.00943. Saumya Saxena, Blake Buchanan, Chris Paxton, Bingqing Chen, Narunas Vaskevicius, Luigi Palmieri, Jonathan Francis, and Oliver Kroemer. Grapheqa: Using 3d semantic scene graphs for real-time embodied question answering.CoRR, abs/2412.14480,
-
[25]
34 Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786,
-
[27]
Bootstrapping language-guided navigation learning with self-refining data flywheel
Zun Wang, Jialu Li, Yicong Hong, Songze Li, Kunchang Li, Shoubin Yu, Yi Wang, Yu Qiao, Yali Wang, Mohit Bansal, and Limin Wang. Bootstrapping language-guided navigation learning with self-refining data flywheel. InInternational Conference on Learning Representations, volume 2025, pp. 23542–23568, 2025c. Meng Wei, Chenyang Wan, Jiaqi Peng, Xiqian Yu, Yuqia...
arXiv 2025
-
[28]
Qwen-image technical report.CoRR, abs/2508.02324,
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Shengming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun ...
-
[29]
doi: 10.48550/ARXIV .2508.02324. URL https://doi.org/10.48550/arXiv.2508.02324. Ziyuan Xia, Jingyi Xu, Chong Cui, Yuanhong Yu, Jiazhao Zhang, Qingsong Yan, Tao Ni, Junbo Chen, Xiaowei Zhou, Hujun Bao, et al. Habitat-gs: A high-fidelity navigation simulator with dynamic gaussian splatting.arXiv preprint arXiv:2604.12626,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, et al. Qwen3 technical report, 2025a. Yuncong Yang, Han Yang, Jiachen Zhou, Peihao Chen, Hongxin Zhang, Yilun Du, and Chuang Gan. 3d- mem: 3d scene memory for embodied exploration and reasoning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nas...
arXiv 2025
-
[31]
Hang Yin, Haoyu Wei, Xiuwei Xu, Wenxuan Guo, Jie Zhou, and Jiwen Lu. Gc-vln: Instruction as graph constraints for training-free vision-and-language navigation.arXiv preprint arXiv:2509.10454, 2025a. 35 Hang Yin, Xiuwei Xu, Linqing Zhao, Ziwei Wang, Jie Zhou, and Jiwen Lu. Unigoal: Towards universal zero-shot goal-oriented navigation.arXiv preprint arXiv:2...
-
[32]
Vlfm: Vision- language frontier maps for zero-shot semantic navigation
Naoki Yokoyama, Sehoon Ha, Dhruv Batra, Jiuguang Wang, and Bernadette Bucher. Vlfm: Vision- language frontier maps for zero-shot semantic navigation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 42–48. IEEE, 2024a. Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, Dhruv Batra, and Sehoon Ha. HM3D-OVON: A dataset and benchmark for...
-
[33]
Kuo-Hao Zeng, Zichen Zhang, Kiana Ehsani, Rose Hendrix, Jordi Salvador, Alvaro Herrasti, Ross Girshick, Aniruddha Kembhavi, and Luca Weihs. Poliformer: Scaling on-policy rl with transformers results in masterful navigators.arXiv preprint arXiv:2406.20083,
-
[34]
FAST-EQA: efficient embodied question answering with global and local region relevancy
Haochen Zhang, Nirav Savaliya, Faizan Siddiqui, and Enna Sachdeva. FAST-EQA: efficient embodied question answering with global and local region relevancy. InIEEE/CVF Winter Conference on Ap- plications of Computer Vision, WACV 2026, Tucson, AZ, USA, March 6-10, 2026, pp. 1664–1673. IEEE,
2026
-
[35]
Navid: Video-based vlm plans the next step for vision-and-language navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation. arXiv preprint arXiv:2402.15852, 2024a. Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, e...
-
[36]
Xunyi Zhao, Gengze Zhou, and Qi Wu. Vln-mme: Diagnosing mllms as language-guided visual navigation agents.arXiv preprint arXiv:2512.24851,
-
[37]
Denseg: Alleviating vision-language feature sparsity in multi-view 3d visual grounding
Henry Zheng, Hao Shi, Yong Xien Chng, Rui Huang, Zanlin Ni, Tianyi Tan, Qihang Peng, Yepeng Weng, Zhongchao Shi, and Gao Huang. Denseg: Alleviating vision-language feature sparsity in multi-view 3d visual grounding. InAutonomous Grand Challenge CVPR 2024 Workshop, volume 2, pp. 6,
2024
-
[38]
Navgpt-2: Unleashing navigational reasoning capability for large vision-language models
Gengze Zhou, Yicong Hong, Zun Wang, Xin Eric Wang, and Qi Wu. Navgpt-2: Unleashing navigational reasoning capability for large vision-language models. InEuropean Conference on Computer Vision, pp. 260–278. Springer, 2024a. 36 Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. InPro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.