CloakLM: Obfuscating GPU Memory Layout to Mitigate Model Ex-filtration for Serving
Pith reviewed 2026-06-26 21:40 UTC · model grok-4.3
The pith
CloakLM removes structural regularity from GPU model weights via software memory obfuscation, blocking PCIe and HBM exfiltration while keeping inference unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
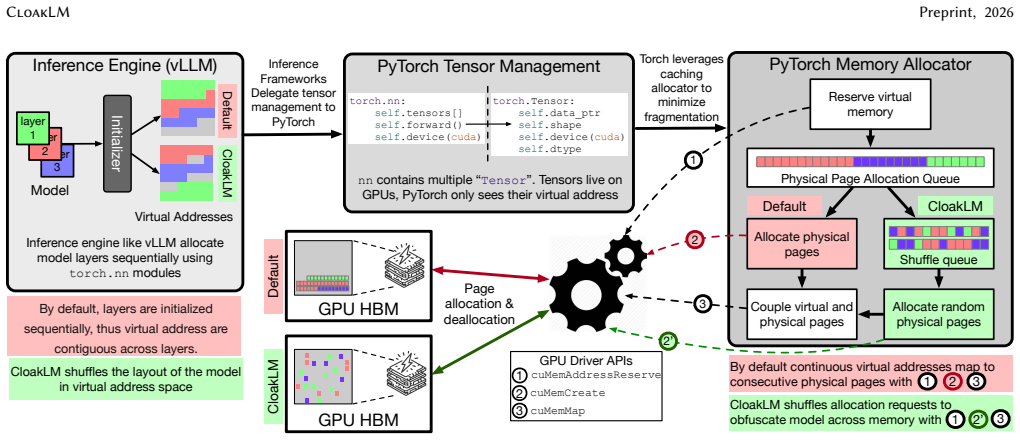
CloakLM is a software-only memory-obfuscation framework that combines PCIe traffic shaping, inter- and intra-layer weight shuffling, and physical HBM page remapping. These mechanisms eliminate the contiguous, repeatedly accessed weight regions that Hermes, TunnelS, and co-tenant attacks rely on, while preserving a valid virtual memory view for the inference stack. The result is that passive PCIe traces and HBM dumps no longer contain enough structure to reconstruct model parameters, yet overhead remains negligible on distributed LLaMA and Qwen workloads running under vLLM and PyTorch.
What carries the argument
The three coordinated obfuscation mechanisms—PCIe traffic shaping, inter- and intra-layer weight shuffling, and physical HBM page remapping—that together fragment the physical memory layout seen by attackers while leaving the logical view intact for authorized execution.
If this is right
- PCIe snooping attacks lose the dense, ordered weight transfers needed for lossless reconstruction.
- HBM dump attacks obtain only remapped and shuffled pages that no longer map back to original model structure.
- The same logical inference code and virtual memory layout continue to work without modification.
- The defense adds no hardware requirement and integrates directly into existing serving frameworks.
- Overhead stays low enough that distributed inference performance remains near native.
Where Pith is reading between the lines
- The same layout-obfuscation idea could be applied to other memory-resident artifacts such as intermediate activations or optimizer states.
- If attackers develop new pattern-matching techniques that tolerate shuffling, the defense would need an additional layer such as lightweight encryption.
- The approach reduces reliance on physical co-location controls or full confidential-computing enclaves for model protection.
- A practical test would measure whether any remaining regular access patterns survive after the three mechanisms are applied together.
Load-bearing premise
Existing attacks depend on contiguous and regularly accessed weight regions, and the three obfuscation steps do not create new patterns that attackers can still exploit at acceptable cost.
What would settle it
An experiment that reconstructs a full LLaMA or Qwen model from PCIe traces or HBM dumps collected while CloakLM is active would show the central claim is false.
Figures


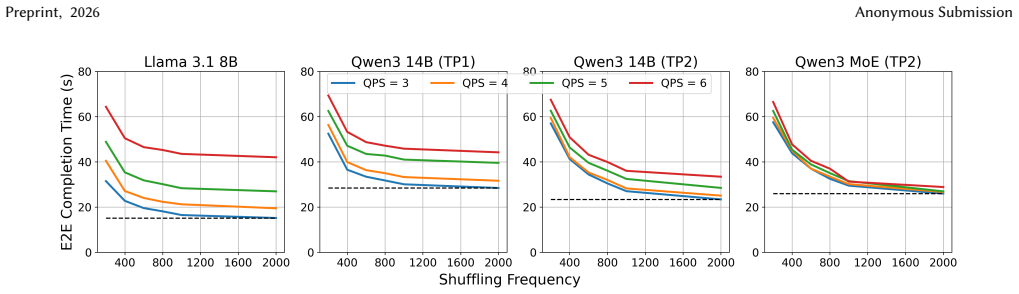


read the original abstract
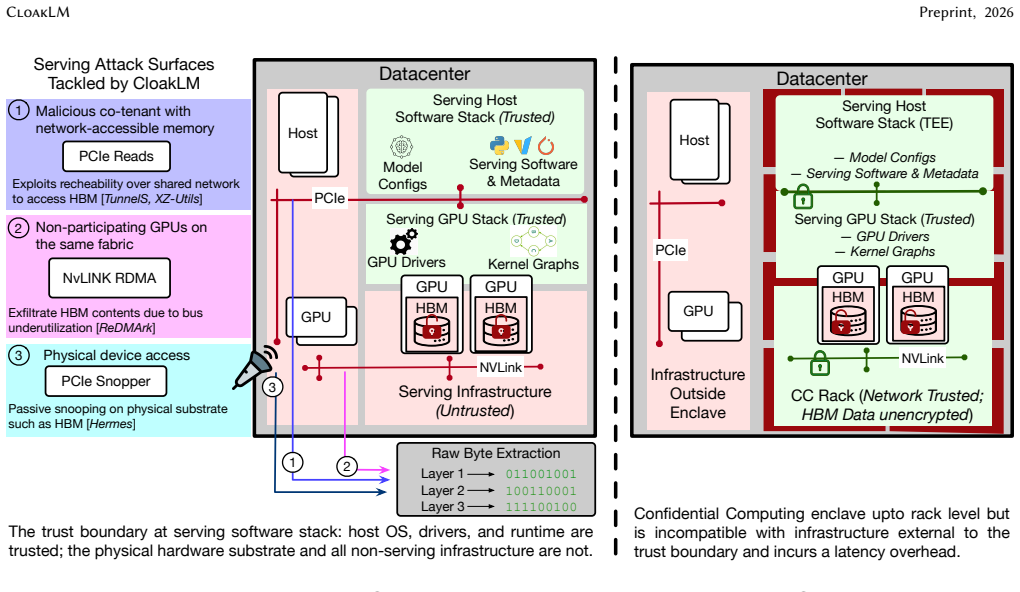
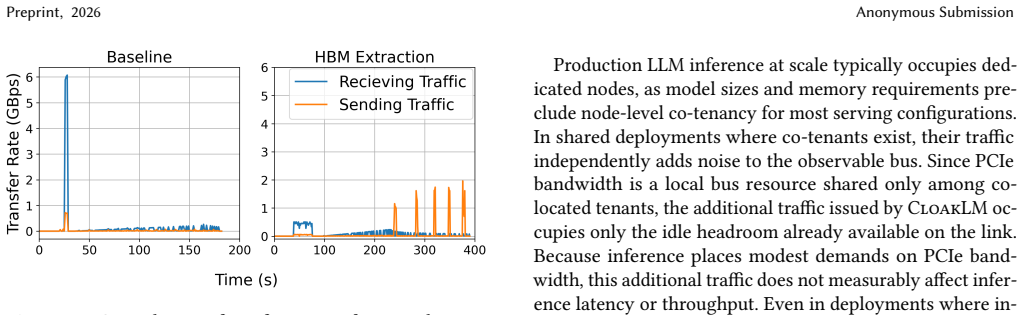
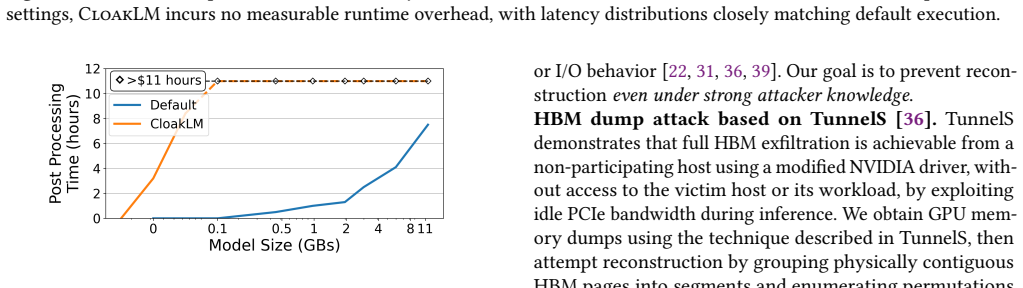
Large foundation models deployed on third-party and shared accelerator infrastructure face a practical risk of model exfiltration that existing defenses do not fully address. In common serving deployments, model providers control the VM or bare-metal serving stack but not the surrounding hardware substrate. The host to GPU interconnect, accelerator fabric, and neighboring infrastructure components remain outside the tenant's trust boundary and have been shown to be exploitable. Hermes demonstrates lossless DNN reconstruction from passive PCIe observation, while TunnelS exfiltrates HBM contents at high throughput via driver-level access without disrupting inference. Co-tenant VMs can further access memory-mapped interfaces or misconfigured RDMA regions without physical co-location. These attacks exploit a common property of ML systems: model weights are stored in large, contiguous, and repeatedly accessed memory regions, making intercepted PCIe transfers and HBM dumps rich enough to reveal model structure and parameters. We present CloakLM, a software-only memory-obfuscation framework that removes this structural regularity without changing the inference stack's logical view of memory. CloakLM combines three mechanisms: PCIe traffic shaping, inter- and intra-layer weight shuffling, and physical HBM page remapping. Authorized execution retains a valid virtual memory layout with negligible overhead, while unauthorized observers see fragmented and semantically incoherent state. CloakLM integrates with vLLM and PyTorch, requires no hardware changes, and complements confidential computing. Evaluation on distributed inference workloads using LLaMA and Qwen models shows near-native performance while significantly increasing resistance to PCIe snooping and HBM dump attacks, making inference-time model exfiltration substantially less practical.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that model exfiltration attacks (Hermes via PCIe, TunnelS via HBM dumps, co-tenant RDMA) succeed because weights occupy large contiguous repeatedly-accessed regions; CloakLM counters this with three software mechanisms—PCIe traffic shaping, inter-/intra-layer weight shuffling, and physical HBM page remapping—that destroy structural regularity visible to an adversary while preserving a correct virtual-memory view for the inference stack (vLLM/PyTorch). Authorized execution incurs negligible overhead; unauthorized observers see fragmented, semantically incoherent state. The approach requires no hardware changes and is evaluated on distributed LLaMA and Qwen inference workloads.
Significance. If the quantitative claims hold, the work supplies a practical, software-only complement to confidential computing for third-party GPU serving that directly targets the memory-layout regularity exploited by existing side-channel and dump attacks. The absence of new hardware or changes to the logical inference API is a notable strength.
major comments (2)
- [Abstract, Evaluation section] Abstract and §Evaluation: the manuscript asserts 'near-native performance' and 'significantly increasing resistance' on LLaMA/Qwen workloads yet supplies no quantitative metrics (throughput, latency, attack success rate before/after), baselines, error bars, or methodology details. This absence makes the central performance and security claims unverifiable and load-bearing for the contribution.
- [Section 3] §3 (mechanisms): the description of how PCIe traffic shaping, weight shuffling, and HBM remapping interact to avoid introducing new observable patterns (e.g., new timing channels or access-frequency artifacts) is stated at a high level; a concrete argument or micro-benchmark showing that the obfuscated layout does not create exploitable regularity is required to support the 'no new patterns' claim.
minor comments (2)
- [Section 3] Notation for the three mechanisms is introduced without a summary table relating each mechanism to the attack surface it targets (PCIe vs. HBM vs. co-tenant).
- [Implementation section] Integration details with vLLM (e.g., which hooks or memory allocators are modified) are mentioned but not accompanied by a code or configuration snippet.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for verifiable quantitative claims and more detailed analysis of the obfuscation mechanisms. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract, Evaluation section] Abstract and §Evaluation: the manuscript asserts 'near-native performance' and 'significantly increasing resistance' on LLaMA/Qwen workloads yet supplies no quantitative metrics (throughput, latency, attack success rate before/after), baselines, error bars, or methodology details. This absence makes the central performance and security claims unverifiable and load-bearing for the contribution.
Authors: We agree that the current version of the manuscript does not provide the specific quantitative metrics, baselines, error bars, or methodology details in the abstract and evaluation sections, which renders the performance and security claims difficult to verify. In the revised manuscript, we will add concrete throughput and latency numbers (with native vLLM/PyTorch baselines), attack success rates before/after applying CloakLM, error bars from repeated runs, and full methodology descriptions for the LLaMA and Qwen workloads. This will directly support the claims of near-native performance and increased resistance. revision: yes
-
Referee: [Section 3] §3 (mechanisms): the description of how PCIe traffic shaping, weight shuffling, and HBM remapping interact to avoid introducing new observable patterns (e.g., new timing channels or access-frequency artifacts) is stated at a high level; a concrete argument or micro-benchmark showing that the obfuscated layout does not create exploitable regularity is required to support the 'no new patterns' claim.
Authors: We acknowledge that §3 currently presents the interaction of the three mechanisms at a high level without concrete evidence against new patterns. In the revision, we will expand this section with a detailed argument on why the combined obfuscations (PCIe shaping + shuffling + remapping) avoid introducing timing channels or access-frequency artifacts, supported by micro-benchmark results measuring observable regularity in the obfuscated state versus the original. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a systems description of three software mechanisms (PCIe traffic shaping, weight shuffling, HBM page remapping) that preserve logical memory view while fragmenting physical layout. No equations, derivations, fitted parameters, or first-principles predictions appear anywhere in the provided text. Claims rest on design properties and empirical evaluation rather than any self-referential reduction. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2025. Claude Sonnet 4.5.https://www.anthropic.com/ news/claude-sonnet-4-5
2025
-
[2]
Marcin Chrapek, Marcin Copik, Etienne Mettaz, and Torsten Hoefler
-
[3]
arXiv:2509.18886 [cs.PF]https://arxiv.org/abs/2509
Confidential LLM Inference: Performance and Cost Across CPU and GPU TEEs. arXiv:2509.18886 [cs.PF]https://arxiv.org/abs/2509. 18886
-
[4]
Carbon Credits. 2026. NVIDIA Controls 92% of the GPU Market in 2025 and Reveals Next Gen AI Supercomputer
2026
-
[5]
Michael Davies, Neal Crago, Karthikeyan Sankaralingam, and Christos Kozyrakis. 2025. LIMINAL: Exploring The Frontiers of LLM Decode Performance. arXiv:2507.14397 [cs.AR]https://arxiv.org/abs/2507. 14397
arXiv 2025
-
[6]
Zachary DeVito. 2022. A guide to PyTorch’s CUDA Caching Allocator. https://zdevito.github.io/2022/08/04/cuda-caching-allocator.html
2022
-
[7]
Sankha Baran Dutta, Hoda Naghibijouybari, Arjun Gupta, Nael Abu- Ghazaleh, Andres Marquez, and Kevin Barker. 2023. Spy in the GPU- box: Covert and Side Channel Attacks on Multi-GPU Systems. In Proceedings of the 50th Annual International Symposium on Computer Architecture(Orlando, FL, USA)(ISCA ’23). Association for Computing Machinery, New York, NY, USA,...
arXiv 2023
-
[8]
Jonah Ekelund, Stefano Markidis, and Ivy Peng. 2025. Boosting Performance of Iterative Applications on GPUs: Kernel Batching with CUDA Graphs. In2025 33rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP). 70–77. doi:10.1109/PDP66500.2025.00019
-
[9]
Yansong Gao, Huming Qiu, Zhi Zhang, Binghui Wang, Hua Ma, Al- sharif Abuadbba, Minhui Xue, Anmin Fu, and Surya Nepal. 2024. DeepTheft: Stealing DNN Model Architectures through Power Side Channel. In2024 IEEE Symposium on Security and Privacy (SP). 3311–
2024
-
[10]
doi:10.1109/SP54263.2024.00250
-
[11]
Michael Godfrey and Mohammad Zulkernine. 2014. Preventing cache- based side-channel attacks in a cloud environment.IEEE Transac- tions on Cloud Computing2, 4 (2014), 395–408. doi:10.1109/TCC.2014. 2358236
-
[12]
Google. 2025. Gemini.https://gemini.google.com/
2025
-
[13]
Zhongshu Gu, Enriquillo Valdez, Salman Ahmed, Julian James Stephen, Michael Le, Hani Jamjoom, Shixuan Zhao, and Zhiqiang Lin. 2025. NVIDIA GPU Confidential Computing Demystified. arXiv:2507.02770 [cs.CR]https://arxiv.org/abs/2507.02770
Pith/arXiv arXiv 2025
-
[14]
Yanan Guo, Zhenkai Zhang, and Jun Yang. 2024. GPU Memory Exploitation for Fun and Profit. In33rd USENIX Security Sympo- sium (USENIX Security 24). USENIX Association, Philadelphia, PA, 4033–4050.https://www.usenix.org/conference/usenixsecurity24/ presentation/guo-yanan
2024
-
[15]
Red Hat. 2024. CVE-2024-3094.https://access.redhat.com/security/ cve/cve-2024-3094
2024
-
[16]
Xing Hu, Ling Liang, Shuangchen Li, Lei Deng, Pengfei Zuo, Yu Ji, Xinfeng Xie, Yufei Ding, Chang Liu, Timothy Sherwood, and Yuan Xie. 2020. DeepSniffer: A DNN Model Extraction Framework Based on Learning Architectural Hints. InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Lan- guages and Operating System...
-
[17]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gi- anna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7B. arXiv:2310.0...
Pith/arXiv arXiv 2023
-
[18]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie- Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teve...
Pith/arXiv arXiv 2024
-
[19]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23). As- sociation for Computing Machinery, New Yor...
-
[20]
Fangfei Liu, Hao Wu, Kenneth Mai, and Ruby B. Lee. 2016. Newcache: Secure Cache Architecture Thwarting Cache Side-Channel Attacks. IEEE Micro36, 5 (2016), 8–16. doi:10.1109/MM.2016.85
-
[21]
McKinsey and Company. 2025. The next big shifts in AI workloads and hyperscaler strategies.https://www.mckinsey.com/industries/ technology-media-and-telecommunications/our-insights/the-next- big-shifts-in-ai-workloads-and-hyperscaler-strategies
2025
-
[22]
Meta. 2025. The Llama 4 herd: The beginning of a new era of na- tively multimodal AI innovation.https://ai.meta.com/blog/llama-4- multimodal-intelligence/
2025
-
[23]
Onur Mutlu and Jeremie S. Kim. 2020. RowHammer: A Retrospective. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems39, 8 (2020), 1555–1571. doi:10.1109/TCAD.2019.2915318
-
[24]
Hoda Naghibijouybari, Ajaya Neupane, Zhiyun Qian, and Nael Abu- Ghazaleh. 2018. Rendered Insecure: GPU Side Channel Attacks are Practical. InProceedings of the 2018 ACM SIGSAC Conference on Com- puter and Communications Security(Toronto, Canada)(CCS ’18). As- sociation for Computing Machinery, New York, NY, USA, 2139–2153. doi:10.1145/3243734.3243831
-
[25]
2026.https://www.nvidia.com/en-us/data-center/solutions/ confidential-computing/
NVIDIA. 2026.https://www.nvidia.com/en-us/data-center/solutions/ confidential-computing/
2026
-
[26]
Zhenghang Ren, Yuxuan Li, Zilong Wang, Xinyang Huang, Wenxue Li, Kaiqiang Xu, Xudong Liao, Yijun Sun, Bowen Liu, Han Tian, Junxue Zhang, Mingfei Wang, Zhizhen Zhong, Guyue Liu, Ying Zhang, and 13 Preprint, 2026 Anonymous Submission Kai Chen. 2025. Enabling efficient GPU communication over multiple NICs with FuseLink. InProceedings of the 19th USENIX Confe...
2026
-
[27]
Benjamin Rothenberger, Konstantin Taranov, Adrian Perrig, and Torsten Hoefler. 2021. ReDMArk: Bypassing RDMA Security Mech- anisms. In30th USENIX Security Symposium (USENIX Security 21). USENIX Association, 4277–4292.https://www.usenix.org/conference/ usenixsecurity21/presentation/rothenberger
2021
-
[28]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
Pith/arXiv arXiv 2025
-
[29]
Tyler Sorensen and Heidy Khlaaf. 2024. LeftoverLocals: Lis- tening to LLM Responses Through Leaked GPU Local Memory. arXiv:2401.16603 [cs.CR]https://arxiv.org/abs/2401.16603
arXiv 2024
-
[30]
Mingtian Tan, Junpeng Wan, Zhe Zhou, and Zhou Li. 2021. Invisible Probe: Timing Attacks with PCIe Congestion Side-channel. In2021 IEEE Symposium on Security and Privacy (SP). 322–338. doi:10.1109/ SP40001.2021.00059
arXiv 2021
-
[31]
Yifan Tan and Zeyu Mi. 2024. Performance Analysis and Optimization of Nvidia H100 Confidential Computing for AI Workloads. In2024 IEEE International Symposium on Parallel and Distributed Processing with Applications (ISPA). 1426–1432. doi:10.1109/ISPA63168.2024.00192
-
[32]
National Telecommunications and Information Administration. [n. d.]. Dual-Use Foundation Models With Widely Available Model Weights Report.https://www.ntia.gov/programs-and-initiatives/artificial- intelligence/open-model-weights-report 14 CloakLM Preprint, 2026
2026
-
[33]
Junyi Wei, Yicheng Zhang, Zhe Zhou, Zhou Li, and Mohammad Ab- dullah Al Faruque. 2020. Leaky DNN: Stealing Deep-Learning Model Secret with GPU Context-Switching Side-Channel. In2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). 125–137. doi:10.1109/DSN48063.2020.00031
-
[34]
Zhenyu Wu, Zhang Xu, and Haining Wang. 2012. Whispers in the hyper-space: high-speed covert channel attacks in the cloud. InProceed- ings of the 21st USENIX Conference on Security Symposium(Bellevue, WA)(Security’12). USENIX Association, USA, 9
2012
-
[35]
Yuval Yarom and Katrina Falkner. 2014. FLUSH+RELOAD: a high resolution, low noise, L3 cache side-channel attack. InProceedings of the 23rd USENIX Conference on Security Symposium(San Diego, CA) (SEC’14). USENIX Association, USA, 719–732
2014
-
[36]
Reiter, and Thomas Risten- part
Yinqian Zhang, Ari Juels, Michael K. Reiter, and Thomas Risten- part. 2014. Cross-Tenant Side-Channel Attacks in PaaS Clouds. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security(Scottsdale, Arizona, USA)(CCS ’14). As- sociation for Computing Machinery, New York, NY, USA, 990–1003. doi:10.1145/2660267.2660356
-
[37]
Yicheng Zhang, Ravan Nazaraliyev, Sankha Baran Dutta, Andres Marquez, Kevin Barker, and Nael Abu-Ghazaleh. 2025. NVBleed: Covert and Side-Channel Attacks on NVIDIA Multi-GPU Interconnect. arXiv:2503.17847 [cs.CR]https://arxiv.org/abs/2503.17847
arXiv 2025
-
[38]
Zhenkai Zhang, Tyler Allen, Fan Yao, Xing Gao, and Rong Ge. 2023. TunneLs for Bootlegging: Fully Reverse-Engineering GPU TLBs for Challenging Isolation Guarantees of NVIDIA MIG. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security(Copenhagen, Denmark)(CCS ’23). Association for Computing Machinery, New York, NY, USA, 960–...
-
[39]
Zirui Neil Zhao, Adam Morrison, Christopher W. Fletcher, and Josep Torrellas. 2024. Last-Level Cache Side-Channel Attacks Are Feasible in the Modern Public Cloud. InProceedings of the 29th ACM Interna- tional Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(La Jolla, CA, USA)(ASPLOS ’24). Association for Comput...
-
[40]
Zirui Neil Zhao, Adam Morrison, Christopher W. Fletcher, and Josep Torrellas. 2025. From Colocation to Exfiltration: Practical Cache Side- Channel Attacks in the Modern Public Cloud.IEEE Micro45, 4 (2025), 95–102. doi:10.1109/MM.2025.3574715
-
[41]
Yuankun Zhu, Yueqiang Cheng, Husheng Zhou, and Yantao Lu
-
[42]
In30th USENIX Security Symposium (USENIX Security 21)
Hermes Attack: Steal DNN Models with Lossless Inference Accuracy. In30th USENIX Security Symposium (USENIX Security 21). USENIX Association, 1973–1988.https://www.usenix.org/conference/ usenixsecurity21/presentation/zhu 15
1973
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.