Are LLMs Ready to Assist Physicians? PhysAssistBench for Interactive Doctor-Patient-EHR Assistance
Pith reviewed 2026-06-26 21:12 UTC · model grok-4.3
The pith
Current LLMs remain unreliable for interactive physician assistance because they fail to coordinate knowledge, communication, and EHR systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current models remain unreliable in this setting, which exposes a key bottleneck for clinical LLMs: reliable assistance requires coordination across knowledge, communication, and systems, not isolated gains in any of them.
What carries the argument
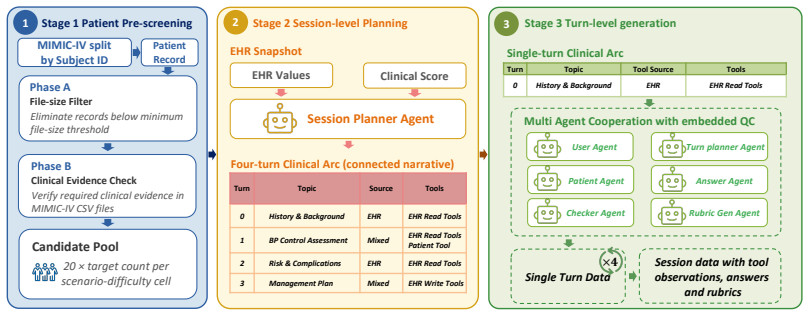
PhysAssistBench, a benchmark that converts static EHR records into interactive record-grounded agentic patients for multi-turn doctor-patient-EHR scenarios.
If this is right
- Models must handle underspecified physician requests alongside ambiguous patient descriptions and precise tool use in EHR systems.
- Success in clinical assistance depends on simultaneous coordination rather than strength in isolated tasks.
- The 1,296 physician-validated turns serve as a representative set for measuring model performance in realistic interactions.
- Future model development should focus on end-to-end interaction capabilities using this type of benchmark.
Where Pith is reading between the lines
- New training methods that simulate complete multi-turn clinical dialogues may be needed to overcome the coordination challenge.
- Hybrid systems combining LLMs with rule-based EHR tools could mitigate current limitations until models improve.
- The pipeline for creating agentic patients from records might extend to other fields like legal or financial advisory simulations.
Load-bearing premise
The pipeline successfully turns static EHR records into interactive agentic patients without losing clinical factuality and the evaluation turns accurately represent real assistance needs.
What would settle it
If new LLMs are tested on PhysAssistBench and achieve consistent high accuracy in completing multi-turn assistance tasks across knowledge, communication, and tool use, the claim of unreliability would be falsified.
Figures



read the original abstract
The most plausible near-term role of medical LLMs is to assist rather than replace physicians, yet current evaluations often test isolated capabilities: clinical knowledge, EHR system interaction, or patient communication. Physician assistance instead requires coordinating these capabilities within the same interaction, where physicians issue underspecified requests, patients describe symptoms ambiguously, and EHR systems demand precise tool use. We introduce PhysAssistBench, a benchmark for interactive doctor-patient-EHR assistance. Built from real MIMIC-IV cases, PhysAssistBench uses a scalable pipeline to construct agentic patients: interactive, record-grounded agents that turn static EHR records into multi-turn clinical scenarios while preserving clinical factuality. PhysAssistBench provides a curated bilingual evaluation set of 1,296 manually reviewed and physician-validated turns. Experiments with leading LLMs show that current models remain unreliable in this setting, which exposes a key bottleneck for clinical LLMs: reliable assistance requires coordination across knowledge, communication, and systems, not isolated gains in any of them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PhysAssistBench, a benchmark for interactive doctor-patient-EHR assistance built from real MIMIC-IV cases. It uses a scalable pipeline to construct interactive, record-grounded agentic patients for multi-turn scenarios while preserving clinical factuality, and provides a curated bilingual evaluation set of 1,296 manually reviewed and physician-validated turns. Experiments with leading LLMs show unreliability in this setting, leading to the claim that reliable assistance requires coordination across knowledge, communication, and systems rather than isolated gains.
Significance. If the benchmark construction and validation hold, this work would be significant for clinical NLP by shifting evaluation from isolated capabilities to integrated, realistic interactions. It identifies a potential coordination bottleneck with direct implications for medical LLM development and could serve as a useful resource if the pipeline faithfully proxies real clinical scenarios.
major comments (3)
- [§3 (Pipeline)] §3 (Pipeline): The claim that the scalable pipeline preserves clinical factuality when turning static MIMIC-IV records into multi-turn agentic patients is load-bearing for attributing unreliability to coordination failures, yet no quantitative error rates, factual drift measures, or physician review statistics for the conversion process are reported.
- [§4 (Evaluation Set)] §4 (Evaluation Set): The 1,296 manually reviewed turns are described as physician-validated, but the manuscript provides no inter-annotator agreement, sampling details, or bias analysis. This directly affects whether the observed unreliability reflects a general coordination bottleneck or an artifact of the evaluation set construction.
- [§5 (Experiments)] §5 (Experiments): The results demonstrating model unreliability should include explicit baselines, per-capability breakdowns, and failure mode categorization to establish that coordination across the three areas (rather than isolated weaknesses) is the primary issue; the current description leaves this link underspecified.
minor comments (2)
- [Abstract] The bilingual nature of the evaluation set is noted in the abstract but lacks detail on languages used or differential performance analysis.
- [Related Work] Related work could more explicitly contrast PhysAssistBench with prior single-turn or non-EHR-grounded medical dialogue benchmarks.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for strengthening the manuscript. We address each major comment below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [§3 (Pipeline)] The claim that the scalable pipeline preserves clinical factuality when turning static MIMIC-IV records into multi-turn agentic patients is load-bearing for attributing unreliability to coordination failures, yet no quantitative error rates, factual drift measures, or physician review statistics for the conversion process are reported.
Authors: We acknowledge that the current manuscript does not include quantitative error rates or factual drift metrics for the full pipeline. The construction process relies on direct record grounding and physician oversight during evaluation set creation to minimize drift. In revision, we will add a dedicated subsection reporting available validation statistics from the physician review process, including any identified and corrected discrepancies, to better support the factuality claim. revision: yes
-
Referee: [§4 (Evaluation Set)] The 1,296 manually reviewed turns are described as physician-validated, but the manuscript provides no inter-annotator agreement, sampling details, or bias analysis. This directly affects whether the observed unreliability reflects a general coordination bottleneck or an artifact of the evaluation set construction.
Authors: The evaluation set underwent physician validation for clinical accuracy. We will expand §4 to include sampling methodology (stratified selection from MIMIC-IV cases), details on the review process, and any available inter-annotator agreement metrics. A brief bias analysis will also be added. If full multi-annotator statistics are limited by the single-primary-reviewer design, we will explicitly note this limitation and provide supporting qualitative evidence. revision: partial
-
Referee: [§5 (Experiments)] The results demonstrating model unreliability should include explicit baselines, per-capability breakdowns, and failure mode categorization to establish that coordination across the three areas (rather than isolated weaknesses) is the primary issue; the current description leaves this link underspecified.
Authors: We agree the link to coordination as the primary bottleneck requires stronger empirical support. In the revised experiments section, we will add explicit single-capability baselines, per-area performance breakdowns (knowledge, communication, systems), and a categorized failure mode analysis distinguishing coordination errors from isolated capability failures. This will include updated tables and discussion to clarify the claim. revision: yes
Circularity Check
No circularity: benchmark construction and evaluation are independent of the unreliability claim
full rationale
The paper constructs PhysAssistBench from external MIMIC-IV records via a described pipeline, validates turns with physicians, and reports LLM performance on the resulting set. The central claim (unreliability due to coordination needs) follows directly from those new experimental outcomes rather than reducing to self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or derivations are present that equate outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The pipeline for constructing agentic patients from static EHR records preserves clinical factuality across multi-turn scenarios.
- domain assumption The 1,296 manually reviewed turns constitute a valid and representative evaluation set for the interactive assistance task.
Reference graph
Works this paper leans on
-
[1]
Er-reason: A benchmark dataset for llm-based clinical reasoning in the emergency room.arXiv preprint arXiv:2505.22919. MiniMax. 2026. MiniMax M2.7: Early echoes of self-evolution. https://www.minimax.io/news/ minimax-m27-en. Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M. Krumholz, Jure Leskovec, Eric J. Topol, and Pranav Rajpurkar. 20...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Data or Specimens Only Research
Lefusion: Controllable pathology synthesis via lesion-focused diffusion models. InInternational Conference on Learning Representations, volume 2025, pages 13232–13253. Shuang Zhou, Wenya Xie, Jiaxi Li, Zaifu Zhan, Mei- jia Song, Han Yang, Cheyenna Espinoza, Lindsay Welton, Xinnie Mai, Yanwei Jin, and 1 others. 2025. Automating expert-level medical reasoni...
2025
-
[3]
CheckerAgent(ValidatePlans) [LLM]IL:1 read tool DG: ≥ 2read toolsCR:1read tool and clinical reasoningWU: 1 writetool MIMIC-IVRaw Data Admissions LabEvents Prescriptions Microbiology· · · Apply Per-Scenario Clinical data requirements to the MIMIC-IV Pool DiagnosticWorkup≥ 2 organ systems+imaging study+≥ 3 diagnoses Meddical Safetymonitored drugs+monitoring...
-
[4]
Session PlanAgent(LLM, once per entry)Inputs: Patient EHR Summary + Scenario Rules + 4-turn Arc TemplateOutput: Session Plan: Turn Intent, topic and tool hint for each of the 4 turns Per-Turn Loop ×4 (turn_idx∈{0,1,2,3})(Any failed check will result in the rerun of entire turn)
-
[5]
User Agent(Implicit Reformulation)[LLM] Selects an implicit Query Subtype (NA, PE, or AE) and rewrites the Explicit query accordingly
-
[6]
User Agent[LLM]Inputs: Turn Intent, Dialogue History, Failed Questions, and Current EHR Snapshot.Output: Explicit Physician Query
-
[7]
Tool ExecutorFHIR:Actions querythe local MIMIC-IV-backed FHIR store
Planner Agent [LLM]Inputs: User Query, Available tools, Task Type, Tool Hints, and current EHR Snapshot.Output: Ordered Action List consisting of tool invocations with Arguments. Tool ExecutorFHIR:Actions querythe local MIMIC-IV-backed FHIR store. Patient:Actions invoke the Patient Agent. Write:Actions simulate resource creation. 5 Patient Agent [LLM]The ...
-
[8]
Given that
Answer Agent[LLM]Inputs: User Query, Executed Actions, Dialogue History, and Task Type.Output: Task-specific Response Formatted according to Task Type (IL, DG, CR, or WU). ·····4. Checker Agent (Validate Answer) [LLM]FormationCompliance +DeterministicAnswers 8.Rubric Generation Agent[LLM]Generates several EHR-anchored evaluation criteria for the current t...
-
[9]
An explicit user question (from Stage 1)
-
[10]
The conversation history (prior turns)
-
[11]
"" [User Prompt]=
A transformation rule specifying which implicitness subtype to apply Your task: rewrite the explicit question into its elliptic/anaphoric form. Rules: • Keep the clinical meaningidentical. • Applyonlythe transformation described — do not add new information. • Maintain the casual bedside tone. • Returnonlythe rewritten question text. • Critical for DG:if ...
-
[12]
Items with1 resultare restricted to Information Lookup turns only
Everytopic must appear in the[QUERYABLE ITEMS] block of the EHR snapshot. Items with1 resultare restricted to Information Lookup turns only
-
[13]
Topics must not repeat across turns — each turn adds new information
-
[14]
4.turn_intents[i]must matchtopicandtool_hintinturns[i]
Turns form a progressive clinical investigation, not random questions. 4.turn_intents[i]must matchtopicandtool_hintinturns[i]
-
[15]
Tool diversity:each FHIR resource type appears in at most 2 turns; the session must span ≥2 distinct resource types
-
[16]
T{i}[R] retrieve {item} — {clinical purpose}
Clinical scoring priority:if a CLINICAL SCORING OPPORTUNITIES section is present, at least one DG or CR turn must compute the listed score (retrieve all required components in parallel). [arc / intent formats] • IL:"T{i}[R] retrieve {item} — {clinical purpose}" • DG:"T{i}[W] {item A}×{item B} — {clinical question}" • CR:"T{i}[KG] interpret {item} — {clini...
-
[17]
Respond in natural spoken language as the patient
-
[18]
Stay strictly in character based on the personality above
-
[19]
Base your responseonlyon the provided PHM data nodes — do not invent symptoms or medications
-
[20]
Donotuse medical jargon ifhealth_literacy=low
-
[21]
If asked about a medication you never filled, express this naturally
-
[22]
For symptom history, follow OPQRST: Onset, Provocation, Quality, Radiation, Severity, Timing
-
[23]
Keep responses concise (2–5 sentences) unless probed for details
-
[24]
"" [User Prompt]=
Stay consistent with what was already disclosed in prior conversation turns. [WithheldFlags —critical_withheldpersona only] Critical information (e.g. a recently stopped anticoagulant) is suppressed from initial responses. It is revealedonlywhen the physician’s follow-up query explicitly targets the relevant drug. Once revealed, the information remains di...
-
[25]
No read/search tools allowed
Write/Update:exactly 1 write tool ( MedicationRequest.create,ServiceRequest.create, orFlag.create) + prepare_to_answer. No read/search tools allowed
-
[26]
6.subject_idmust be present in EHR tool arguments when the patient is known
All tools must exist in theAvailable Toolslist. 6.subject_idmust be present in EHR tool arguments when the patient is known
-
[27]
Patient tools (patient.xxx): bothsubject_idandsession_idrequired
-
[28]
Tool arguments must match their schema (no missing required parameters)
-
[29]
"" [User Prompt]=
The tools chosen must berelevantto the question asked. 10.Action_Listmust end withprepare_to_answer. Outputonlythe JSON, no other text.""" [User Prompt]=""" User question:"{{user_question}}" Task type:{{Information Lookup / Data Gathering / Clinical Reasoning / Write/Update}} Tool source:{{ehr / patient / mixed / write}} Plan:{{Action_List from Planner Ag...
-
[30]
The answer correctly cites creatinine as 0.9 mg/dL
Each item describes anoutcome or clinical goal— never a tool call, API name, or process step. 2.Ground items in actual EHR values. Write:“The answer correctly cites creatinine as 0.9 mg/dL”— not“mentions the creatinine value”
-
[31]
Each item must be independently evaluable asYESorNO
-
[32]
Include≥1 reasoning or recommendation item (not just fact retrieval)
-
[33]
For safety-critical decisions, include one item checking a dangerous recommendation isabsent
-
[34]
Donotmention tool names, function names, or system internals
-
[35]
If a claim is debatable, write the rubric to check thereasoning process, not the specific conclusion
Clinical accuracy:verify the reference answer’s conclusions before echoing them. If a claim is debatable, write the rubric to check thereasoning process, not the specific conclusion
-
[36]
The answer cites creatinine as 0.9 mg/dL
Mixed/patient turns:coverbothdimensions — (a) EHR data cited and interpreted correctly; (b) patient-reported symptoms/adherence quoted and clinically interpreted. Item count by task type: •IL:3 items — value cited, value interpreted, conclusion stated •DG:4–5 items — each value cited, relationship stated, conclusion •CR:5–6 items — value cited, threshold ...
-
[37]
medication, dose, route, frequency, indication)
Each item names aspecific fieldof tool_call.arguments (e.g. medication, dose, route, frequency, indication)
-
[38]
Each item has a clearPASS / FAILcriterion checkable from the field value
-
[39]
Explicitly allow clinically equivalent values (drug synonyms, dose ranges, frequency synonyms)
-
[40]
dose ≥ contraindicated threshold, wrong drug class, unjustifiedstatpriority)
Include exactly onenegative safety itemthat FAILS when a dangerous value is present (e.g. dose ≥ contraindicated threshold, wrong drug class, unjustifiedstatpriority)
-
[41]
"" [User Prompt]=
Donotwrite items about clinical reasoning or prose justification. """ [User Prompt]="""(shared across all turn types) Clinical question:"{{user_question}}" [EHR Data Retrieved] [{{tool_name}}]: {{actual FHIR R4 Bundle values used in the gold answer}} [Reference Answer] {{gold_answer generated by Answer Agent}} Generate the rubric criteria:""" Figure H10: ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.