Spotlight: Synergizing Seed Exploration and Spot GPUs for DiT RL Post-Training
Pith reviewed 2026-06-26 19:04 UTC · model grok-4.3
The pith
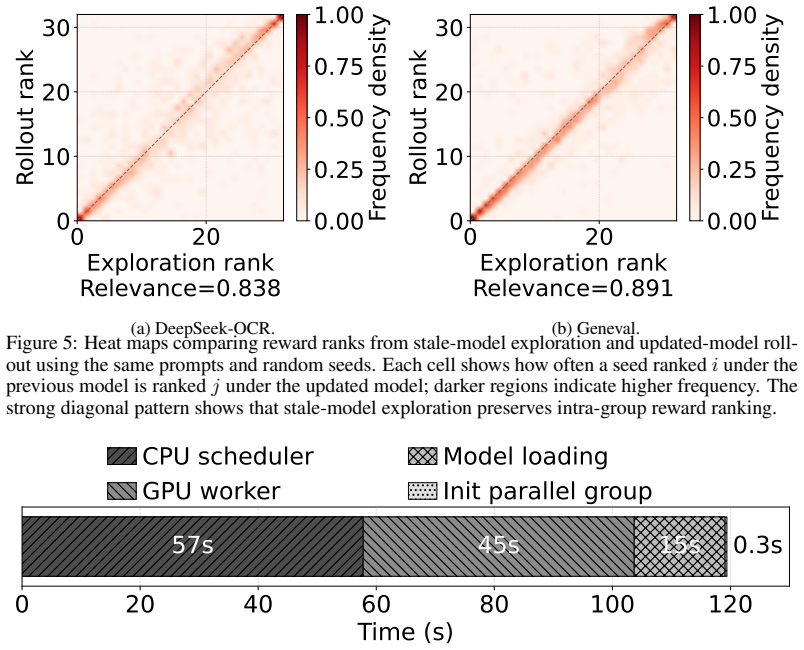
Spotlight shows seed exploration for DiT RL preserves relative seed rankings when run on stale weights, allowing it to use cheap spot GPUs during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
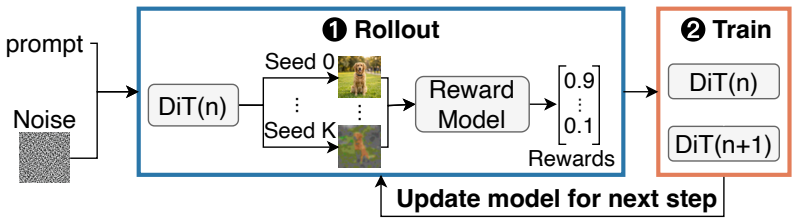
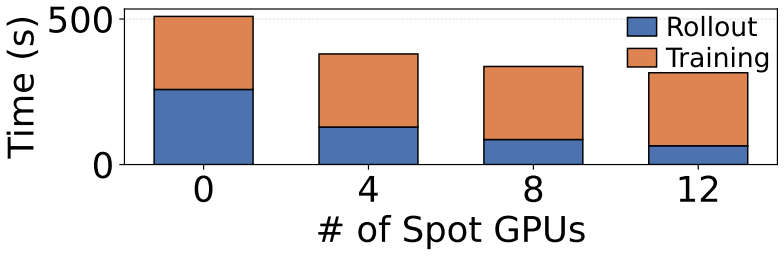
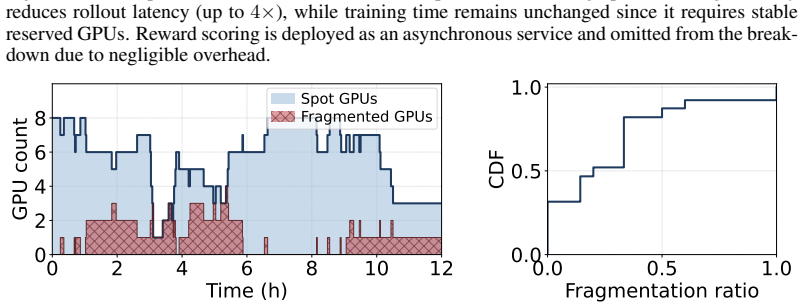
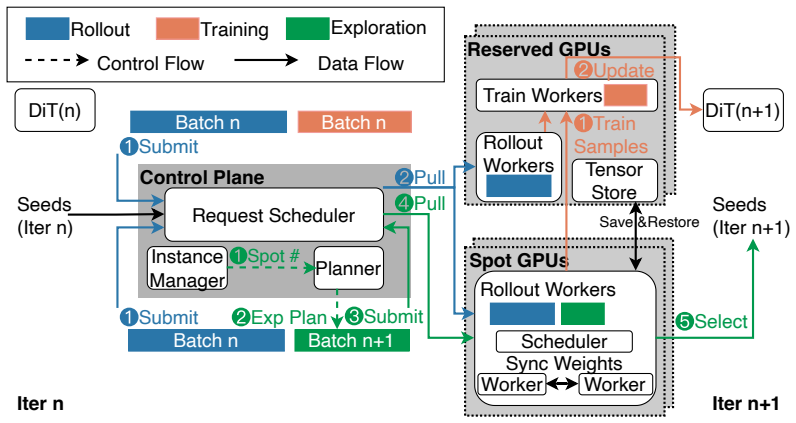
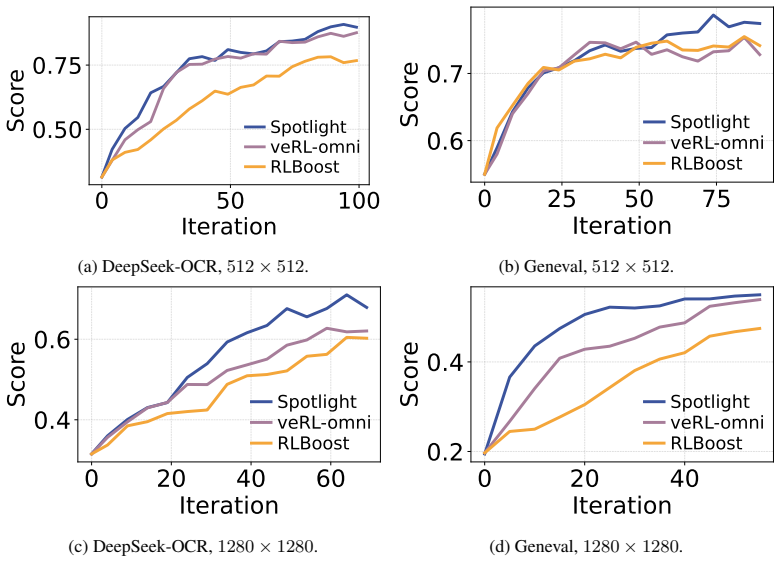
Spotlight claims that exploration performed with weights from the previous training iteration preserves the relative ranking of random seeds, which decouples exploration from the training critical path and permits it to execute on spot GPUs that would otherwise remain idle. This insight, together with elastic sequence parallelism that recovers SP groups in sub-seconds by reusing on-node state and a preemption-aware pull-based scheduler, produces the same target validation score in one-fourth the wall-clock time of baselines, reduces total cost by 1.4-6.4 times, and yields higher image quality on DeepSeek-OCR and Geneval at both 512 by 512 and 1280 by 1280 resolution during Qwen-Image post-tr
What carries the argument
Tolerance of stale model weights in seed exploration, which preserves relative seed rankings and moves exploration onto idle spot GPUs.
If this is right
- Exploration and training can run concurrently on different hardware classes without accuracy loss from staleness.
- Sequence-parallelism groups recover from preemption in sub-seconds rather than minutes by reusing intra-node state.
- A bandit planner can select high-variance seeds inside the exact time window available during each training step.
- Total GPU-hours required to reach a target validation score drop by a factor of four while image quality improves.
Where Pith is reading between the lines
- If the ranking preservation holds across more training iterations, the same pattern could apply to other RL post-training workloads that currently leave spot capacity idle.
- The sub-second SP recovery technique may transfer to any distributed training setting where preemptible instances are common.
- Lower per-iteration cost could make repeated DiT fine-tuning rounds feasible for groups that cannot afford thousands of on-demand GPUs.
- Measuring whether the speedup remains fourfold when model size or batch size increases would test whether the approach scales beyond the evaluated regime.
Load-bearing premise
Exploration using weights from the previous iteration still preserves the relative ranking of random seeds.
What would settle it
A direct comparison that ranks the same set of seeds once with current weights and once with previous-iteration weights and finds the top-ranked seeds differ enough to change which samples are chosen for training, producing measurably slower convergence or lower final validation score.
Figures









read the original abstract
Reinforcement learning (RL) post-training of Diffusion Transformers (DiTs) is prohibitively expensive, requiring thousands of high-end GPUs. Existing works explore two directions to reduce cost: seed exploration improves training convergence by selecting high-contrast samples, yet adds compute to the critical path; spot GPUs offer 69--77\% lower cost, yet sit idle during training because DiT rollouts finish nearly simultaneously, which prevents LLM-style pipelining of rollout with training. Spot preemptions further break Sequence Parallelism (SP) groups, fragmenting GPU topology. We present Spotlight, the first system that harvests spot GPUs for DiT RL post-training. Spotlight rests on two key insights we devise: (1)~we show that exploration can tolerate stale model weights because exploration that uses the model weights from the previous iteration preserves the relative ranking of random seeds, allowing exploration to run on idle spot GPUs during training. (2)~SP reconfiguration can reuse on-node state, reducing group recovery from minutes to sub-second launches. Built on these insights, Spotlight introduces three techniques: a bandit-based exploration planner that maximizes reward variance within the training time budget, elastic sequence parallelism that reconfigures SP groups on the fly via persistent schedulers and intra-node weight copying, and a preemption-aware pull-based request scheduler that balances load and commits in-flight state upon preemption. We implement Spotlight on the open-source RL platform ROLL and evaluate it on Qwen-Image post-training. Spotlight reaches the same target validation score $4\times$ faster than baselines, reducing total cost by $1.4$-$6.4\times$ while achieving superior image quality on DeepSeek-OCR and Geneval datasets with resolution $512\times512$ and $1280\times1280$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Spotlight, a system for DiT RL post-training that offloads seed exploration to preemptible spot GPUs. It rests on two insights: (1) exploration with stale (prior-iteration) model weights preserves relative seed rankings, enabling asynchronous execution during training; (2) SP groups can be reconfigured in sub-second time by reusing on-node state. The system adds a bandit planner, elastic sequence parallelism, and a preemption-aware scheduler. On Qwen-Image post-training it reports reaching target validation scores 4× faster than baselines, with 1.4–6.4× cost reduction and better image quality on DeepSeek-OCR and Geneval at 512² and 1280² resolutions.
Significance. If the empirical claims and the stale-weight ranking invariance hold under realistic DiT RL dynamics, the work would materially lower the barrier to RL post-training of large diffusion models by converting otherwise-idle spot capacity into useful compute. The combination of systems techniques (elastic SP, pull-based scheduling) with the RL-specific observation is novel for this workload.
major comments (2)
- [Abstract / §3 (insights)] The central performance claim (4× wall-clock reduction) depends on insight (1) that prior-iteration weights preserve relative seed ranking. The abstract states this is shown, yet supplies no rank-correlation coefficients, Kendall-τ plots, or sensitivity analysis across training iterations; without these data the asynchronous offload benefit cannot be assessed and the 4× figure remains unsupported.
- [Abstract / Evaluation section] Experimental reporting is incomplete for a systems paper making quantitative claims: no description of baselines, number of runs, statistical tests, or error bars appears in the abstract, and the soundness note indicates the full manuscript must be checked for these elements before the cost-reduction numbers (1.4–6.4×) can be trusted.
minor comments (2)
- [Evaluation] Clarify the exact definition of “target validation score” and how it is measured on DeepSeek-OCR and Geneval.
- [§4.2] Add a short table or plot showing SP reconfiguration latency before/after the persistent-scheduler optimization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the presentation of our empirical evidence.
read point-by-point responses
-
Referee: [Abstract / §3 (insights)] The central performance claim (4× wall-clock reduction) depends on insight (1) that prior-iteration weights preserve relative seed ranking. The abstract states this is shown, yet supplies no rank-correlation coefficients, Kendall-τ plots, or sensitivity analysis across training iterations; without these data the asynchronous offload benefit cannot be assessed and the 4× figure remains unsupported.
Authors: Section 3 of the manuscript presents the rank-preservation result with supporting correlation analysis across iterations. To directly address the request for explicit visualization and sensitivity, we will add Kendall-τ plots and iteration-wise sensitivity analysis in the revised §3 and will insert a concise reference to these results in the abstract. revision: yes
-
Referee: [Abstract / Evaluation section] Experimental reporting is incomplete for a systems paper making quantitative claims: no description of baselines, number of runs, statistical tests, or error bars appears in the abstract, and the soundness note indicates the full manuscript must be checked for these elements before the cost-reduction numbers (1.4–6.4×) can be trusted.
Authors: The full manuscript (§5) specifies the baselines, reports results from multiple independent runs with error bars, and includes statistical comparisons. The abstract is length-limited and therefore omits these details. We will add a short clause to the abstract summarizing the evaluation protocol and will verify that all requested elements are clearly presented in the evaluation section. revision: partial
Circularity Check
No circularity: empirical systems paper with independent experimental validation
full rationale
The paper is a systems contribution that introduces techniques for DiT RL post-training on spot GPUs. Its two key insights are presented as observations validated through implementation and evaluation on Qwen-Image with DeepSeek-OCR/Geneval datasets, rather than any derivation, equation, or fitted parameter that reduces to its own inputs. No self-citations, ansatzes, or uniqueness theorems are invoked to support the central claims. The work is self-contained as an engineering result measured against external baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Exploration using model weights from the previous iteration preserves the relative ranking of random seeds
- domain assumption SP reconfiguration can reuse on-node state to reduce group recovery from minutes to sub-second
Reference graph
Works this paper leans on
-
[1]
AWS Price List Bulk API.https://docs.aws.amazon.com/awsaccountbilling/ latest/aboutv2/using-the-aws-price-list-bulk-api-fetching-price-list-files- manually.html, 2026a
Amazon Web Services. AWS Price List Bulk API.https://docs.aws.amazon.com/awsaccountbilling/ latest/aboutv2/using-the-aws-price-list-bulk-api-fetching-price-list-files- manually.html, 2026a. Accessed: 2026-06-09. Amazon Web Services. Amazon EC2 Spot Instances Pricing.https://aws.amazon.com/ec2/spot/ pricing/, 2026b. Accessed: 2026-06-09. Yufeng Cui, Hongha...
2026
-
[2]
URLhttps://arxiv.org/abs/ 2510.26583. Zheng Ding and Weirui Ye. TreeGRPO: Tree-advantage GRPO for online RL post-training of diffusion models. InThe Fourteenth International Conference on Learning Representations,
-
[3]
Association for Computing Machinery. ISBN 9798400721656. doi: 10.1145/3760250.3762231. URLhttps://doi.org/10.1145/3760250.3762231. Jiangfei Duan, Ziang Song, Xupeng Miao, Xiaoli Xi, Dahua Lin, Harry Xu, Minjia Zhang, and Zhihao Jia. Par- cae: Proactive, liveput-optimized dnn training on preemptible instances.arXiv preprint arXiv:2403.14097,
-
[4]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. Areal: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298,
-
[5]
Wei Gao, Yuheng Zhao, Dakai An, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Ju Huang, Weixun Wang, Siran Yang, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang. Rollpacker: Mitigating long-tail rollouts for fast, synchronous rl post-training.arXiv preprint arXiv:2509.21009, 2025a. Wei Gao, Yuheng Zhao, Tianyuan Wu, Shaopan Xiong, Weixun Wang, Dakai An, L...
-
[6]
URLhttps://arxiv.org/abs/2312.14385. Google Cloud. Compute Engine VM Instance Pricing.https://cloud.google.com/products/compute/ pricing,
-
[7]
20 Jingkai He, Tianjian Li, Erhu Feng, Dong Du, Qian Liu, Tao Liu, Yubin Xia, and Haibo Chen
Accessed: 2026-06-09. 20 Jingkai He, Tianjian Li, Erhu Feng, Dong Du, Qian Liu, Tao Liu, Yubin Xia, and Haibo Chen. History doesn’t repeat itself but rollouts rhyme: Accelerating reinforcement learning with rhymerl. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, AS...
2026
-
[8]
Association for Computing Machinery. ISBN 9798400723599. doi: 10.1145/3779212.3790172. URLhttps://doi.org/10.1145/ 3779212.3790172. Jian Hu, Xibin Wu, Weixun Wang, Xianyu, Dehao Zhang, and Yu Cao. OpenRLHF: An easy-to-use, scalable and high-performance RLHF framework.CoRR,
-
[9]
Qinghao Hu, Shang Yang, Junxian Guo, Xiaozhe Yao, Yujun Lin, Yuxian Gu, Han Cai, Chuang Gan, Ana Klimovic, and Song Han. Taming the long-tail: Efficient reasoning rl training with adaptive drafter.arXiv preprint arXiv:2511.16665,
-
[10]
Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang
URLhttps://arxiv.org/abs/2604.06916. Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. Branchgrpo: Stable and efficient grpo with structured branching in diffusion models,
-
[11]
URLhttps://arxiv.org/ abs/2509.06040. Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model, 2025a. URL https://arxiv.org/abs/2411.19108. Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan...
arXiv 1982
-
[12]
Association for Computing Machinery. ISBN 9798400723599. doi: 10.1145/3779212.3790233. URLhttps://doi.org/10.1145/3779212.3790233. Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, Changyi Wan, Ranchen Ming, Xiaoniu Song, Xing Chen, Yu Zhou, Deshan Sun, Deyu Zhou, Jian Zhou, Kaijun Tan, Kang An, Mei Chen, Wei Ji, Qiling Wu, Wen Su...
-
[13]
Xupeng Miao, Chunan Shi, Jiangfei Duan, Xiaoli Xi, Dahua Lin, Bin Cui, and Zhihao Jia. Spotserve: Serving generative large language models on preemptible instances.arXiv preprint arXiv:2311.15566,
-
[14]
Aurick Qiao, Sang Keun Choe, Suhas Jayaram Subramanya, Willie Neiswanger, Qirong Ho, Hao Zhang, Gre- gory R
Accessed: 2026-06-09. Aurick Qiao, Sang Keun Choe, Suhas Jayaram Subramanya, Willie Neiswanger, Qirong Ho, Hao Zhang, Gre- gory R. Ganger, and Eric P. Xing. Pollux: Co-adaptive cluster scheduling for goodput-optimized deep learning. OSDI ’21,
2026
-
[15]
Ruoyu Qin, Weiran He, Weixiao Huang, Yangkun Zhang, Yikai Zhao, Bo Pang, Xinran Xu, Yingdi Shan, Yongwei Wu, and Mingxing Zhang. Seer: Online context learning for fast synchronous llm reinforcement learning.arXiv preprint arXiv:2511.14617,
-
[16]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300,
-
[17]
Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv:2409.19256,
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv:2409.19256,
-
[18]
Laminar: A scalable asynchronous rl post- training framework.arXiv preprint arXiv:2510.12633,
Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, Haibin Lin, Xin Liu, and Chuan Wu. Laminar: A scalable asynchronous rl post- training framework.arXiv preprint arXiv:2510.12633,
-
[19]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, Zichen Liu, Haizhou Zhao, Dakai An, Lunxi Cao, Qiyang Cao, Wanxi Deng, Feilei Du, Yiliang Gu, Jiahe Li, Xiang Li, Mingjie Liu, Yijia Luo, Zihe Liu, Yadao Wang, Pei Wang, Tianyuan Wu, Yanan Wu, Yuheng Zhao, Shuaibing Zhao, Jin Yang, Si...
-
[20]
URLhttps://arxiv.org/abs/2602. 22718. Qizhen Weng, Lingyun Yang, Yinghao Yu, Wei Wang, Xiaochuan Tang, Guodong Yang, and Liping Zhang. Beware of fragmentation: Scheduling{GPU-Sharing}workloads with fragmentation gradient descent. In 2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 995–1008,
2023
-
[21]
Tianyuan Wu, Lunxi Cao, Yining Wei, Wei Gao, Yuheng Zhao, Dakai An, Shaopan Xiong, Zhiqiang Lv, Ju Huang, Siran Yang, Yinghao Yu, Jiamang Wang, Lin Qu, and Wei Wang. Rollmux: Phase-level multi- plexing for disaggregated rl post-training.arXiv preprint arXiv:2512.11306, 2025a. Yongji Wu, Xueshen Liu, Haizhong Zheng, Juncheng Gu, Beidi Chen, Z. Morley Mao, ...
-
[22]
URLhttps: //arxiv.org/abs/2505.07818. Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Sho- janazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proc. ...
-
[23]
Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proc
ISSN 2150-8097. doi: 10.14778/3611540.3611569. URLhttps://doi.org/10.14778/3611540.3611569. Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process. arXiv preprint arXiv:2509.16117,
-
[24]
URLhttps://arxiv.org/abs/2503.09642. Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, and Daxin Jiang. Streamrl: Scalable, het- erogeneous, and elastic rl for llms with disaggregated stream generation.arXiv preprint arXiv:2504.15930, 2025a. Yinmin Zho...
-
[25]
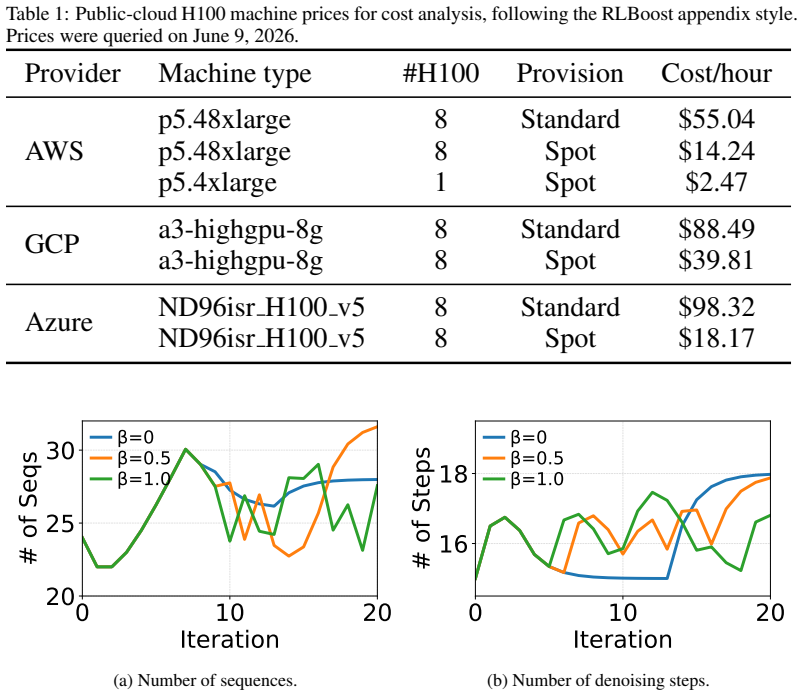
0 10 20 Iteration 16 18# of Steps =0 =0.5 =1.0 (b) Number of denoising steps
Provider Machine type #H100 Provision Cost/hour AWS p5.48xlarge 8 Standard $55.04 p5.48xlarge 8 Spot $14.24 p5.4xlarge 1 Spot $2.47 GCP a3-highgpu-8g 8 Standard $88.49 a3-highgpu-8g 8 Spot $39.81 Azure ND96isr H100 v5 8 Standard $98.32 ND96isr H100 v5 8 Spot $18.17 0 10 20 Iteration 20 25 30# of Seqs =0 =0.5 =1.0 (a) Number of sequences. 0 10 20 Iteration...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.