CABLE: Cloud-Assisted Bandwidth-efficient LMM-based Encoding for V2X Systems
Pith reviewed 2026-06-26 21:33 UTC · model grok-4.3
The pith
CABLE transmits only motion-predicted ROI regions to cloud LMMs in V2X systems, forming a feedback loop that reduces bandwidth while preserving perception.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
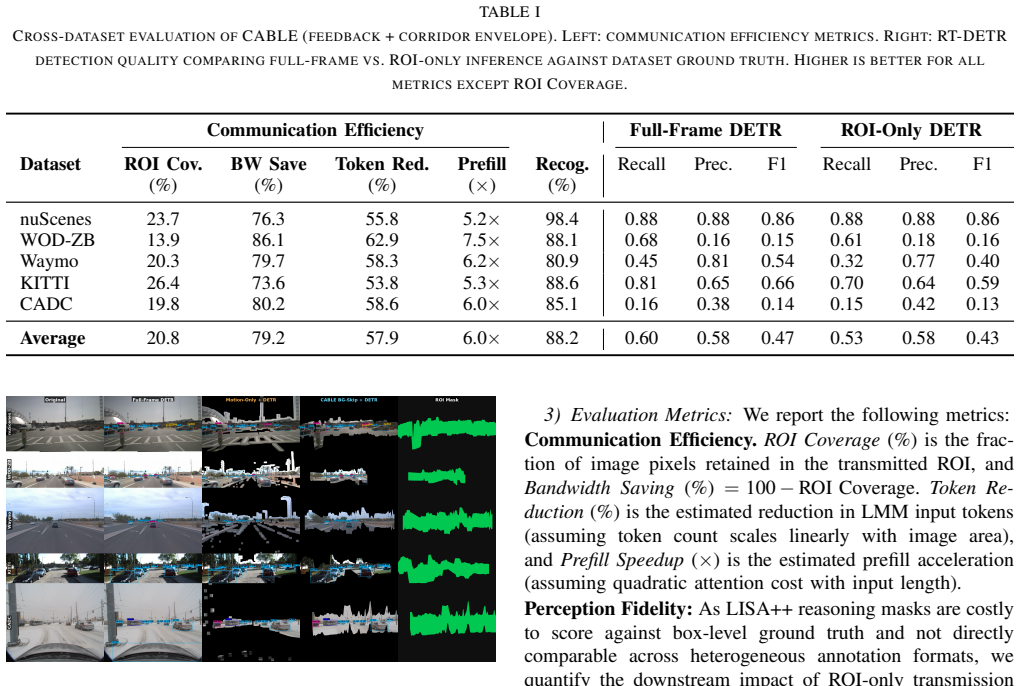
CABLE propagates the previous cloud segmentation mask on the edge using ego-motion compensation, refines it with residual-motion cues, and consolidates disconnected regions via a corridor envelope to form a robust region of interest (ROI). Only ROI-masked images are uploaded, while the cloud segmentation output is fed back as the prior for the next frame, forming a mask-to-ROI-to-LMM feedback loop.
What carries the argument
The mask-to-ROI-to-LMM feedback loop that uses ego-motion-compensated prior masks to determine which image regions to transmit.
If this is right
- Communication volume drops by 73-87 percent ROI pixel coverage on nuScenes, Waymo, KITTI and related datasets.
- LMM prefill latency falls by an estimated 5-8 times due to smaller inputs.
- Detection quality remains close to full-frame performance with only modest trade-offs.
- The same mask feedback mechanism works consistently across multiple independent driving datasets.
Where Pith is reading between the lines
- The feedback loop could be adapted to other edge-cloud vision pipelines where camera motion is known.
- Tighter integration with vehicle odometry might further shrink the corridor size.
- The method opens a path to testing whether similar ROI selection improves latency for non-LMM cloud models.
Load-bearing premise
Propagating the prior cloud mask via ego-motion compensation plus residual-motion refinement and corridor consolidation will reliably capture all objects of interest without critical omissions in varied real-world traffic scenes.
What would settle it
A recorded driving sequence in which an object enters the camera view outside the predicted corridor, is excluded from the uploaded ROI, and produces a missed detection relative to full-frame inference.
Figures

read the original abstract
Cloud-hosted large multimodal models (LMMs) can provide strong open-vocabulary perception for Vehicle-to-Everything systems, but naively transmitting full-resolution frames from edge to cloud causes severe communication overhead and high cloud-side prefill latency. We present CABLE, a cloud-assisted bandwidth-efficient LMM-based encoding framework for edge-cloud perception. CABLE propagates the previous cloud segmentation mask on the edge using ego-motion compensation, refines it with residual-motion cues, and consolidates disconnected regions via a corridor envelope to form a robust region of interest (ROI). Only ROI-masked images are uploaded, while the cloud segmentation output is fed back as the prior for the next frame, forming a mask-to-ROI-to-LMM feedback loop. Experiments on five datasets (nuScenes, WOD-ZB, Waymo, KITTI, and CADC) show consistent communication savings while largely preserving perception, achieving $73$--$87\%$ ROI pixel-coverage reduction with $5$--$8\times$ estimated LMM prefill speedup at a modest detection-quality trade-off relative to full-frame inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CABLE, a cloud-assisted framework for V2X perception that reduces bandwidth by constructing ROIs from prior cloud segmentation masks. The edge propagates the mask via ego-motion compensation, refines it with residual-motion cues, and consolidates regions with a corridor envelope before uploading only the masked image; the cloud LMM output feeds back as the next prior. Experiments across five datasets (nuScenes, WOD-ZB, Waymo, KITTI, CADC) report 73–87% ROI pixel-coverage reduction and 5–8× estimated LMM prefill speedup at a modest detection-quality trade-off versus full-frame inference.
Significance. If the no-omission guarantee holds, the closed-loop ROI construction could meaningfully lower communication costs and cloud prefill latency for open-vocabulary LMM perception in V2X, addressing a practical deployment barrier. The multi-dataset scope is a strength, but the absence of quantitative baselines, error bars, ablation results, and omission-rate measurements limits the ability to judge whether the reported savings preserve perception at a level that would justify adoption.
major comments (3)
- [Abstract] Abstract: the central claim of 'modest detection-quality trade-off' relative to full-frame inference is unsupported by any reported metrics (e.g., mAP, precision-recall at specific IoU thresholds), baselines, error bars, or statistical tests, which is load-bearing for assessing whether the 73–87% ROI reduction is acceptable.
- [Abstract] Abstract (pipeline description): the no-critical-omission premise required for the savings claim rests on ego-motion compensation plus residual-motion refinement plus corridor consolidation, yet no quantitative omission rates, failure-case analysis, or robustness evaluation under noisy ego-motion or fast-moving objects is supplied.
- [Experiments] Experiments section (implied by abstract results): the manuscript states results across five datasets but supplies neither ablation studies on the individual ROI-construction components nor comparison against alternative ROI or compression baselines, preventing isolation of the contribution of the feedback loop.
minor comments (2)
- [Abstract] Abstract: replace the qualitative phrase 'modest detection-quality trade-off' with concrete delta values once the quantitative results are added.
- [Abstract] Notation: the term 'LMM prefill speedup' should be defined (e.g., wall-clock time or token count) to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify opportunities to make the quantitative evaluation more explicit and comprehensive. We respond to each major comment in turn and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'modest detection-quality trade-off' relative to full-frame inference is unsupported by any reported metrics (e.g., mAP, precision-recall at specific IoU thresholds), baselines, error bars, or statistical tests, which is load-bearing for assessing whether the 73–87% ROI reduction is acceptable.
Authors: We agree with this observation. Although the experiments section provides mAP, precision-recall curves, and comparisons at standard IoU thresholds (0.5 and 0.75) with error bars across the five datasets, these specifics were not highlighted in the abstract. In the revised version, we will update the abstract to explicitly state the observed mAP drops (typically under 3-5% relative to full-frame) and direct readers to the relevant experimental tables and figures. revision: yes
-
Referee: [Abstract] Abstract (pipeline description): the no-critical-omission premise required for the savings claim rests on ego-motion compensation plus residual-motion refinement plus corridor consolidation, yet no quantitative omission rates, failure-case analysis, or robustness evaluation under noisy ego-motion or fast-moving objects is supplied.
Authors: The overall detection quality metrics serve as an indirect measure of omission impact. However, we concur that direct quantification would strengthen the claims. We will incorporate quantitative omission rates (fraction of annotated objects falling outside the constructed ROI), present failure cases involving fast-moving objects, and add robustness experiments with perturbed ego-motion estimates in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section (implied by abstract results): the manuscript states results across five datasets but supplies neither ablation studies on the individual ROI-construction components nor comparison against alternative ROI or compression baselines, preventing isolation of the contribution of the feedback loop.
Authors: We acknowledge that additional ablations and baselines would better isolate the contributions. The revised manuscript will include ablations for each ROI construction stage (ego-motion propagation, residual cue refinement, and corridor envelope) measuring their individual impact on pixel reduction and detection performance. We will also add comparisons to alternative approaches such as optical-flow-based ROI selection and standard image compression methods. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an engineering pipeline (ego-motion compensation of prior masks, residual-motion refinement, corridor consolidation to form ROI, feedback loop) and reports empirical results from experiments on five datasets. No equations, fitted parameters presented as predictions, self-citations, or derivations are present that would reduce any claim to its inputs by construction. All performance numbers (ROI reduction, speedup, detection trade-off) are stated as direct experimental outcomes rather than derived quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LIDAR based cooperative sensing in vehicular edge computing,
L. Jiang, K. Liu, C. Liu, H. Ren, G. Yan, F. Jin, and S. Guo, “LIDAR based cooperative sensing in vehicular edge computing,” in2023 19th International Conference on Mobility, Sensing and Networking (MSN). IEEE Computer Society, 2023, pp. 17–23
2023
-
[2]
Cloud-assisted 360-degree 3D perception for autonomous vehicles using V2X com- munication and hybrid computing,
F. Hawlader, F. Robinet, G. Elghazaly, and R. Frank, “Cloud-assisted 360-degree 3D perception for autonomous vehicles using V2X com- munication and hybrid computing,” in2025 20th Wireless On-Demand Network Systems and Services Conference (WONS). IEEE, 2025, pp. 1–8
2025
-
[3]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “GPT-4o system card,”arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[4]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2024
2024
-
[5]
LISA: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y . Chen, Y . Li, Y . Yuan, S. Liu, and J. Jia, “LISA: Reasoning segmentation via large language model,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 9579–9589
2024
-
[6]
LISA++: An improved baseline for reasoning segmentation with large language model,
S. Yang, T. Qu, X. Lai, Z. Tian, B. Peng, S. Liu, and J. Jia, “LISA++: An improved baseline for reasoning segmentation with large language model,”arXiv preprint arXiv:2312.17240, 2023
arXiv 2023
-
[7]
Applications of large language models and multimodal large models in autonomous driving: A comprehensive review,
J. Li, J. Li, G. Yang, L. Yang, H. Chi, and L. Yang, “Applications of large language models and multimodal large models in autonomous driving: A comprehensive review,”Drones, vol. 9, no. 4, p. 238, 2025
2025
-
[8]
CoLMDriver: LLM-based negotiation benefits cooperative autonomous driving,
C. Liu, G. Liu, Z. Wang, J. Yang, and S. Chen, “CoLMDriver: LLM-based negotiation benefits cooperative autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 25 951–25 960
2025
-
[9]
nuScenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuScenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[10]
Bandwidth-efficient communication modelling for autonomous vehicle collaborative perception,
D. Jin, Y . Zeng, and Y . Gong, “Bandwidth-efficient communication modelling for autonomous vehicle collaborative perception,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, 2025, pp. 6146–6155
2025
-
[11]
V2X cooperative perception for autonomous driving: Recent advances and challenges,
T. Huang, J. Liu, X. Zhou, D. C. Nguyen, M. R. Azghadi, Y . Xia, Q.-L. Han, and S. Sun, “V2X cooperative perception for autonomous driving: Recent advances and challenges,”arXiv preprint arXiv:2310.03525, 2023
arXiv 2023
-
[12]
LLaV A-PruMerge: Adaptive token reduction for efficient large multimodal models,
Y . Shang, M. Cai, B. Xu, Y . J. Lee, and Y . Yan, “LLaV A-PruMerge: Adaptive token reduction for efficient large multimodal models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 22 857–22 867
2025
-
[13]
Token merging: Your ViT but faster,
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your ViT but faster,”arXiv preprint arXiv:2210.09461, 2022
Pith/arXiv arXiv 2022
-
[14]
Y . Li, H. Jiang, C. Zhang, Q. Wu, X. Luo, S. Ahn, A. H. Abdi, D. Li, J. Gao, Y . Yanget al., “MMInference: Accelerating pre-filling for long-context VLMs via modality-aware permutation sparse attention,” arXiv preprint arXiv:2504.16083, 2025
arXiv 2025
-
[15]
DETRs beat YOLOs on real-time object detection,
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “DETRs beat YOLOs on real-time object detection,”IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16 965–16 974, 2024
2024
-
[16]
Open-world hazard detection and captioning for autonomous driving with a unified multimodal pipeline,
M. Hatamiet al., “Open-world hazard detection and captioning for autonomous driving with a unified multimodal pipeline,” inProceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
2025
-
[17]
Openad: Open-world autonomous driving bench- mark for 3d object detection,
M.-H. Yanget al., “Openad: Open-world autonomous driving bench- mark for 3d object detection,” inAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[18]
Mcds-vss: Moving camera dynamic scene video semantic segmentation by filtering with self-supervised geometry and motion,
C. Villaret al., “Mcds-vss: Moving camera dynamic scene video semantic segmentation by filtering with self-supervised geometry and motion,” inBritish Machine Vision Conference (BMVC), 2024
2024
-
[19]
Enhanced dynamic obstacle avoidance for uavs using event camera and ego-motion compensation,
B. Huanget al., “Enhanced dynamic obstacle avoidance for uavs using event camera and ego-motion compensation,”Drones, vol. 9, no. 11, p. 745, 2025
2025
-
[20]
Scalability in perception for autonomous driving: Waymo Open Dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo Open Dataset,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2443– 2451
2020
-
[21]
Are we ready for autonomous driving? The KITTI vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? The KITTI vision benchmark suite,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2012, pp. 3354– 3361
2012
-
[22]
Canadian adverse driving conditions dataset,
M. Pitropov, D. Garcia, S. Aklanoglu, M. Abdelwahab, M. Smart, A. O’Reilly, C. Lu, W. Schwarting, E. Yurtsever, R. Urtasunet al., “Canadian adverse driving conditions dataset,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 11 565–11 574
2021
-
[23]
Cooper: Cooperative perception for connected autonomous vehicles based on 3D point clouds,
Q. Chen, X. Ma, S. Tang, J. Guo, Q. Yang, and S. Fu, “Cooper: Cooperative perception for connected autonomous vehicles based on 3D point clouds,”IEEE International Conference on Distributed Computing Systems (ICDCS), pp. 514–524, 2019
2019
-
[24]
V2VNet: Vehicle-to-vehicle communication for joint perception and prediction,
T.-H. Wang, S. Manivasagam, M. Liang, B. Yang, W. Zeng, and R. Urtasun, “V2VNet: Vehicle-to-vehicle communication for joint perception and prediction,” inEuropean Conference on Computer Vision (ECCV), 2020, pp. 605–621
2020
-
[25]
Learning distilled collaboration graph for multi-agent perception,
Y . Li, S. Ren, P. Wu, S. Chen, C. Feng, and W. Zhang, “Learning distilled collaboration graph for multi-agent perception,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 29 541–29 552
2021
-
[26]
When2com: Multi- agent perception via communication graph grouping,
Y .-C. Liu, J. Tian, N. Glaser, and Z. Kira, “When2com: Multi- agent perception via communication graph grouping,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 4106–4115
2020
-
[27]
Who2com: Collaborative perception via learnable handshake com- munication,
Y .-C. Liu, J. Tian, C.-Y . Ma, N. Glaser, C.-W. Kuo, and Z. Kira, “Who2com: Collaborative perception via learnable handshake com- munication,” inIEEE International Conference on Robotics and Au- tomation (ICRA), 2020, pp. 6876–6883
2020
-
[28]
Where2comm: Communication-efficient collaborative perception via spatial confi- dence maps,
Y . Hu, S. Fang, Z. Lei, Y . Zhong, and S. Chen, “Where2comm: Communication-efficient collaborative perception via spatial confi- dence maps,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 4874–4886
2022
-
[29]
A novel communication-efficient cooperative percep- tion framework based on infrastructure-side critical feature extraction,
A. Authoret al., “A novel communication-efficient cooperative percep- tion framework based on infrastructure-side critical feature extraction,” IEEE Transactions on Intelligent Transportation Systems, 2024
2024
-
[30]
Supply-demand-driven information selection algo- rithm for efficient V2X perception,
B. Authoret al., “Supply-demand-driven information selection algo- rithm for efficient V2X perception,” inProc. IEEE Int. Conf., 2024
2024
-
[31]
Lifetime-guaranteed cost-minimized heterogeneous visual sensor networks with feature collection for effective target coverage in 3-D space,
C. Authoret al., “Lifetime-guaranteed cost-minimized heterogeneous visual sensor networks with feature collection for effective target coverage in 3-D space,”IEEE Internet of Things Journal, 2023
2023
-
[32]
V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer,
R. Xu, H. Xiang, Z. Tu, X. Xia, M.-H. Yang, and J. Ma, “V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer,” inEuropean Conference on Computer Vision (ECCV), 2022, pp. 107– 124
2022
-
[33]
Among us: Adversarially robust collaborative perception by consensus,
Y . Li, Q. Ren, L. Che, S. Chen, C. Feng, and W. Zhang, “Among us: Adversarially robust collaborative perception by consensus,” in IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 186–195
2023
-
[34]
Collaborative perception in autonomous driving: Methods, datasets, and challenges,
Y . Han, H. Zhang, H. Li, Y . Jin, C. Lang, and Y . Li, “Collaborative perception in autonomous driving: Methods, datasets, and challenges,” IEEE Intelligent Transportation Systems Magazine, vol. 15, no. 6, pp. 131–151, 2023
2023
-
[35]
OPV2V: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,
R. Xu, H. Xiang, X. Xia, X. Han, J. Li, and J. Ma, “OPV2V: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,” inIEEE International Conference on Robotics and Automation (ICRA), 2022, pp. 2583–2589
2022
-
[36]
V2X- Sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving,
Y . Li, D. Ma, Z. An, Z. Wang, Y . Zhong, S. Chen, and C. Feng, “V2X- Sim: Multi-agent collaborative perception dataset and benchmark for autonomous driving,” inIEEE Robotics and Automation Letters, vol. 7, no. 4, 2022, pp. 10 914–10 921
2022
-
[37]
DAIR-V2X: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection,
H. Yu, Y . Luo, M. Shu, Y . Huo, Z. Yang, Y . Shi, Z. Guo, H. Li, X. Hu, J. Yuan, and Z. Nie, “DAIR-V2X: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 21 361–21 370
2022
-
[38]
Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,
Y . Kang, J. Hauswald, C. Gao, A. Rovinski, T. Mudge, J. Mars, and L. Tang, “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,” inACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASP- LOS), 2017, pp. 615–629
2017
-
[39]
BottleNet++: An end-to-end approach for feature compression in device-edge co-inference systems,
J. Shao and J. Zhang, “BottleNet++: An end-to-end approach for feature compression in device-edge co-inference systems,”IEEE Com- munications Letters, vol. 24, no. 8, pp. 1652–1656, 2020
2020
-
[40]
JointDNN: An efficient training and inference engine for intelligent mobile cloud computing services,
A. E. Eshratifar, M. S. Abrishami, and M. Pedram, “JointDNN: An efficient training and inference engine for intelligent mobile cloud computing services,”IEEE Transactions on Mobile Computing, vol. 20, no. 2, pp. 565–576, 2019
2019
-
[41]
BottleFit: Learning compressed representations in deep neural networks for effective and efficient split computing,
Y . Matsubara, D. Callegaro, S. Singh, M. Levorato, and F. Restuc- cia, “BottleFit: Learning compressed representations in deep neural networks for effective and efficient split computing,” inIEEE Interna- tional Workshop on Machine Learning for Signal Processing (MLSP), 2022, pp. 1–6
2022
-
[42]
FrankenSplit: Saliency-guided neural feature com- pression with shallow variational bottleneck injection for mobile edge computing,
A. Furutanpey, P. Barco, D. Schinagl, K. Schoeffmann, C. Timmerer, and S. Dustdar, “FrankenSplit: Saliency-guided neural feature com- pression with shallow variational bottleneck injection for mobile edge computing,” inACM Multimedia, 2023, pp. 5424–5432
2023
-
[43]
Edge intelligence: On-demand deep learning model co-inference with device-edge synergy,
E. Li, L. Zeng, Z. Zhou, and X. Chen, “Edge intelligence: On-demand deep learning model co-inference with device-edge synergy,”ACM SIGCOMM Workshop on Mobile Edge Communications (MECOMM), pp. 31–36, 2019
2019
-
[44]
Edge computing for autonomous driving: Opportunities and challenges,
S. Liu, L. Liu, J. Tang, B. Yu, Y . Wang, and W. Shi, “Edge computing for autonomous driving: Opportunities and challenges,”Proceedings of the IEEE, vol. 107, no. 8, pp. 1697–1716, 2019
2019
-
[45]
ROI-aware video encoding for bandwidth-efficient cloud inference,
Z. Wang, W. Liu, and H. Li, “ROI-aware video encoding for bandwidth-efficient cloud inference,” inIEEE International Confer- ence on Multimedia and Expo (ICME), 2024, pp. 1–6
2024
-
[46]
Task-driven semantic coding via reinforcement learning,
X. Zhang, J. Shao, and J. Zhang, “Task-driven semantic coding via reinforcement learning,”IEEE Transactions on Image Processing, vol. 32, pp. 6250–6262, 2023
2023
-
[47]
Efficient large-scale vision model inference with tiling and caching,
K. Chenet al., “Efficient large-scale vision model inference with tiling and caching,” inAAAI Conference on Artificial Intelligence, 2024, pp. 1–9
2024
-
[48]
Communication-efficient edge AI: Federated learning and integrated communication and computation,
G. Shiet al., “Communication-efficient edge AI: Federated learning and integrated communication and computation,”IEEE Communica- tions Surveys and Tutorials, vol. 22, no. 4, pp. 2168–2207, 2020
2020
-
[49]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 26 296–26 306
2024
-
[50]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Dollar, and R. Gir- shick, “Segment anything,” inIEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4015–4026
2023
-
[51]
SAM 2: Segment anything in images and videos,
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R¨adle, C. Rolland, L. Gustafsonet al., “SAM 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.