How Linear Is a Transformer Feed-Forward Block? Per-Block Linear Recoverability Is Learned, Not Architectural
Pith reviewed 2026-06-27 04:40 UTC · model grok-4.3
The pith
Transformer FFN blocks show sharply varying linearity that training learns per block rather than architecture imposing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
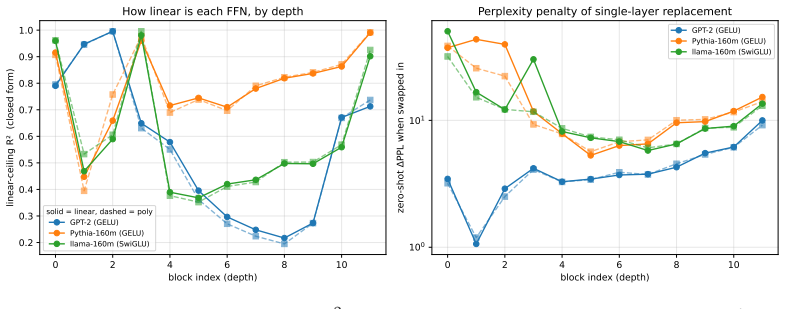
Each FFN block is treated as a position-wise map; its optimal linear approximation is obtained in closed form, and the fraction of held-out variance this map accounts for (R^2_lin) is heterogeneous and non-monotone with depth, independent of the activation function, and therefore a learned attribute of the trained block.
What carries the argument
Closed-form least-squares linear map from a block's activations to its outputs, with R^2_lin on held-out data quantifying the recoverable linear component.
If this is right
- Blocks with high R^2_lin admit single-layer linear replacements that reduce parameters by factors of eight while adding less than one perplexity point.
- Blocks with low R^2_lin concentrate the computation that cannot be recovered linearly and therefore mark where nonlinear capacity is required.
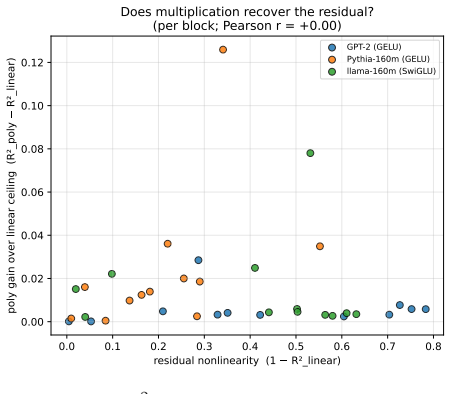
- Low-rank bilinear probes recover only a few additional points of R^2 from the residual, showing that the remaining computation is not a simple position-wise product.
Where Pith is reading between the lines
- Training appears to allocate nonlinear capacity unevenly across layers rather than spreading it uniformly.
- Targeted linear replacement guided by per-block R^2_lin could yield more efficient hybrid transformer variants.
- The method supplies a diagnostic that could be applied during training to monitor how linearity evolves.
Load-bearing premise
That the position-wise input-to-output map of an FFN block can be usefully split into an optimal linear map plus a residual whose size measures nonlinearity.
What would settle it
Observing that every block in a trained model has nearly identical R^2_lin values close to 1, or that GPT-2 and Pythia-160m exhibit matching per-block recoverability profiles despite different training.
Figures



read the original abstract
Transformer feed-forward networks (FFNs) are often treated as nonlinear stores of computation, yet how nonlinear a trained FFN block actually is has rarely been measured. We treat each FFN as a position-wise input-to-output map and split it into the exact least-squares linear approximation plus a residual. The held-out variance the closed-form linear map explains defines a block's linear recoverability (R^2_lin), an optimiser-free measure of its linearity. Across all twelve blocks of GPT-2, Pythia-160m, and llama-160m, R^2_lin is highly heterogeneous and non-monotone with depth, ranging from near-linear (>0.99) to strongly nonlinear (<0.3) between adjacent blocks, and is not set by the activation function: same-width GELU models GPT-2 and Pythia-160m have sharply different profiles, so recoverability is a learned property of individual trained blocks, not an architectural one. A low-rank bilinear probe of the residual recovers only a few points of R^2, with gain uncorrelated with residual nonlinearity: the unrecovered computation is not a single position-wise product but higher-order or distributed structure. The measurement also serves as a targeted compression signal: recoverable blocks admit large single-layer replacements (GPT-2's early FFN at 8x fewer parameters for +0.77 perplexity), while low-recoverability blocks flag where this is unsafe. It further exposes a methodological pitfall: trained linear baselines can badly under-converge on ill-conditioned transformer activations, so we report the exact closed-form least-squares ceiling throughout.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines R^2_lin as the coefficient of determination achieved by the closed-form least-squares linear map from FFN input activations to output activations, evaluated on held-out data drawn from each model's forward passes. It reports that R^2_lin varies sharply and non-monotonically across the 12 blocks of GPT-2, Pythia-160m and Llama-160m (near 1.0 in some blocks, below 0.3 in others), that identical GELU activations produce dissimilar layer-wise profiles in GPT-2 versus Pythia-160m, and therefore that per-block linear recoverability is a learned property rather than an architectural one. A low-rank bilinear probe recovers only a few additional points of variance in the residual, and the measure is proposed as a compression signal that identifies blocks safe for large linear replacement.
Significance. If the per-block R^2_lin values faithfully isolate the degree of linearity in the learned weights rather than merely reflecting model-specific activation statistics, the work supplies an optimiser-free diagnostic that challenges the uniform treatment of FFNs as nonlinear stores and supplies a concrete, falsifiable signal for targeted compression. The closed-form normal-equation construction and explicit warning about under-convergence of trained linear baselines are concrete methodological contributions.
major comments (2)
- [Abstract and §4 (cross-model comparison)] The central claim that recoverability 'is a learned property of individual trained blocks, not an architectural one' rests on the cross-model comparison of R^2_lin profiles for GPT-2 and Pythia-160m (both GELU). Because the held-out activations are drawn from each model's own residual stream, differences in input covariance or dynamic range could produce the observed profile divergence even if the weight matrices were identical. No experiment that feeds activations from one model into the FFN of the other, or that normalises input statistics, is described; this leaves the inference from profile difference to 'learned' status load-bearing and untested.
- [§3 (definition of R^2_lin) and experimental setup] The weakest-assumption paragraph notes that R^2_lin is computed on held-out activations from the model's own forward passes. The manuscript provides no quantitative characterisation of how narrow or model-specific these distributions are (e.g., condition numbers of the input Gram matrix, effective support size), which directly affects whether the reported heterogeneity can be attributed to the learned map rather than to the test distribution.
minor comments (2)
- [Abstract and §4] The abstract states that 'the abstract provides no details on data splits, token sampling, or statistical significance'; the full manuscript should supply these (number of tokens, train/test split per block, bootstrap or jackknife error bars on R^2_lin) so that the reported heterogeneity can be verified.
- [§3] Notation for the linear map (W_lin, b_lin) and the precise definition of the residual variance should be stated once in a single equation block rather than scattered across the text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important nuances in the interpretation of R^2_lin and the strength of evidence for our central claim. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4 (cross-model comparison)] The central claim that recoverability 'is a learned property of individual trained blocks, not an architectural one' rests on the cross-model comparison of R^2_lin profiles for GPT-2 and Pythia-160m (both GELU). Because the held-out activations are drawn from each model's own residual stream, differences in input covariance or dynamic range could produce the observed profile divergence even if the weight matrices were identical. No experiment that feeds activations from one model into the FFN of the other, or that normalises input statistics, is described; this leaves the inference from profile difference to 'learned' status load-bearing and untested.
Authors: We agree that the cross-model comparison relies on model-specific activation distributions and that an explicit activation-swapping or input-normalization experiment would provide stronger isolation of the effect of learned weights. The within-model heterogeneity across blocks (which share identical architecture and activation within each model) remains the primary evidence that recoverability is not uniformly determined by architecture. The GPT-2 vs. Pythia-160m difference with matched GELU and width is offered as supporting evidence that training produces distinct profiles, but we acknowledge the referee's point that input statistics are not controlled. In revision we will add a clarifying paragraph noting this limitation and the value of future cross-feeding experiments; we do not alter the central claim but qualify its evidential basis. revision: partial
-
Referee: [§3 (definition of R^2_lin) and experimental setup] The weakest-assumption paragraph notes that R^2_lin is computed on held-out activations from the model's own forward passes. The manuscript provides no quantitative characterisation of how narrow or model-specific these distributions are (e.g., condition numbers of the input Gram matrix, effective support size), which directly affects whether the reported heterogeneity can be attributed to the learned map rather than to the test distribution.
Authors: We accept that quantitative descriptors of the input distributions would help readers assess whether heterogeneity reflects the learned map. In the revised manuscript we will report, for each block and model, the condition number of the input Gram matrix (computed on the same held-out activations used for R^2_lin), the effective rank, and a simple measure of dynamic range. These additions will be placed in §3 and the appendix. revision: yes
Circularity Check
No circularity: R^2_lin is standard closed-form regression on held-out activations
full rationale
The paper computes R^2_lin directly as the held-out variance explained by the exact least-squares linear map (closed-form normal equations) fitted to each FFN block's position-wise input-output pairs. This quantity is defined from the observed activations alone and does not reduce to any model parameter, self-citation, or prior result by construction. The inference that recoverability is learned (rather than architectural) rests on the empirical observation of heterogeneous, non-monotone profiles that differ across models with identical activations; these comparisons are external to the measurement itself and introduce no self-referential loop. No load-bearing step invokes fitted inputs renamed as predictions, uniqueness theorems, or ansatzes smuggled via citation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The ordinary least-squares solution minimises the L2 residual for a linear map between finite-dimensional vector spaces.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Transformer Feed-Forward Layers Are Key-Value Memories , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2021 , doi =
2021
-
[2]
Shazeer, Noam , journal =
-
[3]
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , booktitle =
-
[4]
Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations , editor =
-
[5]
International Joint Conference on Neural Networks (IJCNN) , pages =
The Pi-Sigma Network: An Efficient Higher-Order Neural Network for Pattern Classification and Function Approximation , author =. International Joint Conference on Neural Networks (IJCNN) , pages =
-
[6]
International Conference on Learning Representations (ICLR) , year =
Multiplicative Interactions and Where to Find Them , author =. International Conference on Learning Representations (ICLR) , year =
-
[7]
IEEE International Conference on Data Mining (ICDM) , pages =
Factorization Machines , author =. IEEE International Conference on Data Mining (ICDM) , pages =. 2010 , doi =
2010
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Higher-Order Factorization Machines , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[9]
Language Models are Unsupervised Multitask Learners , author =
-
[10]
Biderman, Stella and Schoelkopf, Hailey and Anthony, Quentin and Bradley, Herbie and O'Brien, Kyle and Hallahan, Eric and Khan, Mohammad Aflah and Purohit, Shivanshu and Prashanth, USVSN Sai and Raff, Edward and Skowron, Aviya and Sutawika, Lintang and van der Wal, Oskar , booktitle =
-
[11]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. arXiv preprint arXiv:2302.13971 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
International Conference on Learning Representations (ICLR) , year =
Pointer Sentinel Mixture Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[13]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author =. arXiv preprint arXiv:1503.02531 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Revisiting Model Stitching to Compare Neural Representations , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[15]
Understanding intermediate layers using linear classifier probes
Understanding Intermediate Layers Using Linear Classifier Probes , author =. arXiv preprint arXiv:1610.01644 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Deep Polynomial Neural Networks , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2022 , doi =
2022
-
[17]
When Does the Pi Branch Fire? Multiplicative Hypernetworks for Few-Shot Weight Initialisation , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.