Prompt Quality and Pull Request Outcomes: A Stage-Based Empirical Study of LLM-Assisted Development
Pith reviewed 2026-06-26 19:40 UTC · model grok-4.3
The pith
Prompt characteristics exert stage-dependent effects on pull request outcomes in LLM-assisted development.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
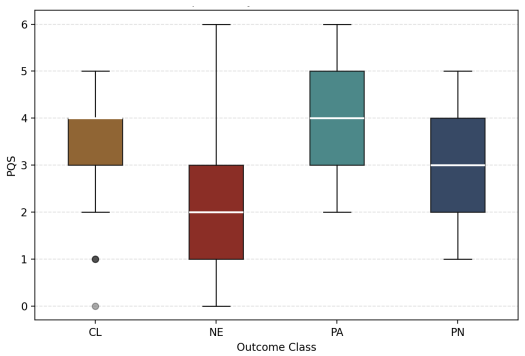
Using the validated dimensions, Specificity and Context associate most strongly with actionable code generation, Verification emerges as the primary predictor of code adoption, and integration depth links most strongly to Context. Prompt characteristics therefore exert distinct, stage-dependent effects across AI-assisted software engineering workflows through contextual grounding, task specificity, and evaluability cues.
What carries the argument
Three prompt-structure dimensions (Context, Specificity, Verification) that operationalize quality and are linked to stage-specific PR outcomes via analysis of 265 interactions.
If this is right
- Higher Specificity and Context increase the chance of generating actionable code.
- Stronger Verification cues raise the likelihood that generated code is adopted into the PR.
- Richer Context improves the depth of code integration.
- LLM-only annotation is inconsistent on Context and Verification, so hybrid validation is required for reliable assessment.
- Prompt design can be tailored separately to generation versus adoption stages.
Where Pith is reading between the lines
- Teams could create stage-specific prompt templates to raise the rate at which LLM suggestions survive review.
- The same dimensions might be tested on other collaborative tasks such as issue triage or code review comments.
- Tool builders could embed real-time prompt-quality checks that flag low-Verification prompts before code is generated.
- Effects observed in self-admitted usage might differ in undisclosed LLM-assisted work, suggesting a need for broader sampling methods.
Load-bearing premise
The three dimensions and the 265 manually validated interactions capture the relevant variation in prompt quality and PR outcomes without substantial selection or measurement bias.
What would settle it
Re-annotating the same interactions with an expanded or alternative set of prompt dimensions and finding that Verification no longer predicts adoption would undermine the stage-dependent effects claim.
Figures

read the original abstract
Large language model (LLM)-powered tools such as ChatGPT are increasingly used in collaborative software engineering workflows, yet little is known about how prompt structure influences downstream pull request (PR) outcomes. Prior studies primarily examine conversational helpfulness, productivity, or coarse-grained adoption metrics, leaving the role of prompt structure in collaborative integration behavior insufficiently understood. We analyze 265 manually validated developer-ChatGPT interactions derived from self-admitted ChatGPT usage in open-source pull requests. Building on prior research on developer-facing artifacts and prompt engineering, we operationalize prompt structure using three dimensions: Context, Specificity, and Verification. We first evaluate whether LLM-assisted annotation can reliably reproduce human judgments of prompt structure, finding substantial variation across dimensions and workflow contexts. Specificity shows the most stable agreement with human judgments; Context is systematically under-scored by the LLM; and Verification remains difficult to assess consistently, motivating a hybrid human-LLM annotation strategy. Using this validated framework, we then examine how prompt structure influences actionable code generation, code adoption, and integration depth across AI-assisted PR workflows. Specificity and Context are most strongly associated with actionable code generation; Verification emerges as the primary predictor of code adoption; and integration depth is most strongly associated with Context. Overall, our findings show that prompt characteristics exert distinct, stage-dependent effects across AI-assisted software engineering workflows, influencing downstream adoption and integration through contextual grounding, task specificity, and evaluability cues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 265 manually validated developer-ChatGPT interactions extracted from self-admitted LLM usage in open-source pull requests. It operationalizes prompt structure along three dimensions (Context, Specificity, Verification), compares LLM-assisted annotation to human judgments (finding dimension-specific agreement variation and adopting a hybrid strategy), and reports associations between these dimensions and three workflow outcomes: actionable code generation, code adoption, and integration depth. The central claim is that prompt characteristics show distinct, stage-dependent associations with these outcomes.
Significance. The stage-based framing and hybrid annotation validation represent a useful extension of prior LLM productivity studies into collaborative integration behaviors. If the associations prove robust after explicit confounder adjustment, the work could inform prompt design guidelines for AI-assisted SE; the manual validation of 265 cases and dimension-specific reliability findings are concrete strengths that support reproducibility and extension.
major comments (2)
- [Abstract] Abstract: the claim that prompt characteristics 'exert distinct, stage-dependent effects' and 'influenc[e] downstream adoption and integration through contextual grounding, task specificity, and evaluability cues' asserts directional influence. The study reports observational associations from self-admitted ChatGPT PRs with no mentioned randomization, instrumental variables, or controls for confounders (task complexity, developer experience, PR size); the language therefore exceeds what the design can support.
- [Abstract] Sampling and analysis description (Abstract and implied §3/§4): reliance on self-admitted usage introduces potential selection bias, as developers who publicly acknowledge ChatGPT may differ in experience or task type from non-admitters. Without discussion or sensitivity checks, this threatens the generalizability of the reported stage-specific predictors.
minor comments (1)
- [Abstract] Abstract: the statement of 'substantial variation across dimensions' in LLM-human agreement would be strengthened by reporting specific agreement metrics (e.g., Cohen's kappa or percentage agreement per dimension) rather than qualitative description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting issues with causal language and sampling. We agree both points require revision and will update the abstract and add explicit limitations discussion in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that prompt characteristics 'exert distinct, stage-dependent effects' and 'influenc[e] downstream adoption and integration through contextual grounding, task specificity, and evaluability cues' asserts directional influence. The study reports observational associations from self-admitted ChatGPT PRs with no mentioned randomization, instrumental variables, or controls for confounders (task complexity, developer experience, PR size); the language therefore exceeds what the design can support.
Authors: We agree the abstract phrasing implies directional effects beyond what an observational study of associations can support. The manuscript reports correlations between prompt dimensions and outcomes but does not adjust for confounders such as task complexity or developer experience. We will revise the abstract to replace 'exert distinct, stage-dependent effects' and 'influencing ... through' with language emphasizing observed associations (e.g., 'are associated with' and 'stage-dependent associations'). We will also add a limitations paragraph noting the absence of confounder controls. revision: yes
-
Referee: [Abstract] Sampling and analysis description (Abstract and implied §3/§4): reliance on self-admitted usage introduces potential selection bias, as developers who publicly acknowledge ChatGPT may differ in experience or task type from non-admitters. Without discussion or sensitivity checks, this threatens the generalizability of the reported stage-specific predictors.
Authors: We acknowledge that self-admitted LLM usage in public PRs may introduce selection bias, as such developers could differ in experience or task selection from those who do not disclose usage. The current manuscript does not discuss this or perform sensitivity checks. We will add an explicit subsection in Threats to Validity describing this limitation, its potential impact on generalizability, and the fact that results apply primarily to developers who publicly acknowledge ChatGPT use. We will also note that the 265 manually validated cases support internal validity but do not mitigate external selection concerns. revision: yes
Circularity Check
No significant circularity: purely observational empirical study with no derivations or self-referential predictions
full rationale
The paper conducts an observational analysis of 265 manually validated developer-ChatGPT interactions drawn from open-source PRs. It operationalizes prompt structure via three author-defined dimensions (Context, Specificity, Verification), assesses LLM annotation agreement with human judgments, and reports associations with code generation, adoption, and integration outcomes. No equations, fitted parameters presented as predictions, uniqueness theorems, or ansatzes appear in the provided text. Claims rest on direct empirical measurement and hybrid annotation rather than any reduction to prior self-citations or definitional inputs. The study is self-contained against external benchmarks and contains no load-bearing self-citation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The three dimensions Context, Specificity, and Verification capture the relevant aspects of prompt structure for downstream PR outcomes.
- domain assumption The 265 manually validated interactions form a representative sample of LLM-assisted PR activity.
Reference graph
Works this paper leans on
-
[1]
ACM Trans
Russo, D.: Navigating the complexity of generative ai adoption in software engi- neering. ACM Trans. Softw. Eng. Methodol. (2024) https://doi.org/10.1145/ 3652154 41
2024
-
[2]
arXiv preprint arXiv:2403.02583 (2024) https://doi.org/10.48550/arXiv.2403.02583
Huang, Y., Chen, Y., Chen, X., Chen, J., Peng, R., Tang, Z., Huang, J., Xu, F., Zheng, Z.: Generative software engineering. arXiv preprint arXiv:2403.02583 (2024) https://doi.org/10.48550/arXiv.2403.02583 . Submitted on 5 Mar 2024, last revised 3 Apr 2024 (this version, v2)
-
[3]
IEEE Software 40(4), 30–38 (2023) https://doi.org/10.1109/MS.2023.3265877
Ebert, C., Louridas, P.: Generative ai for software practitioners. IEEE Software 40(4), 30–38 (2023) https://doi.org/10.1109/MS.2023.3265877
-
[4]
Automated Software Engineering31(26) (2024) https://doi.org/10.1007/s10515-024-00330-1
Sauvola, J., Tarkoma, S., Klemettinen, M., Riekki, J., Doermann, D.: Future of software development with generative ai. Automated Software Engineering31(26) (2024) https://doi.org/10.1007/s10515-024-00330-1
-
[5]
Empirical Software Engineering31(108) (2026) https://doi.org/ 10.1007/s10664-026-10848-w
Tufano, R., Pepe, F., Zampetti, F., Mastropaolo, A., Dabi´ c, O., Di Penta, M., Bavota, G.: Developers and generative ai: A study of self-admitted usage in open source projects. Empirical Software Engineering31(108) (2026) https://doi.org/ 10.1007/s10664-026-10848-w
-
[6]
Xiao, T., Hata, H., Treude, C., Matsumoto, K.: Generative ai for pull request descriptions: Adoption, impact, and developer interventions. Proc. ACM Softw. Eng.1(FSE) (2024) https://doi.org/10.1145/3643773
-
[7]
ACM Transactions on Software Engineering and Methodology33(8), 1–79 (2024)
Hou, X., Zhao, Y., Liu, Y., Yang, Z., Wang, K., Li, L., Luo, X., Lo, D., Grundy, J., Wang, H.: Large language models for software engineering: A sys- tematic literature review. ACM Trans. Softw. Eng. Methodol.33(8) (2024) https://doi.org/10.1145/3695988
-
[8]
IEEE Transactions on Software Engineering, 1–18 (2026) https://doi.org/10.1109/TSE.2026.3681886
Xiao, T., Fan, Y., Calefato, F., Treude, C., Kula, R.G., Hata, H., Baltes, S.: Self- admitted genai usage in open-source software. IEEE Transactions on Software Engineering, 1–18 (2026) https://doi.org/10.1109/TSE.2026.3681886
-
[9]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
Peng, S., Kalliamvakou, E., Cihon, P., Demirer, M.: The impact of ai on devel- oper productivity: Evidence from github copilot. arXiv preprint arXiv:2302.06590 (2023) https://doi.org/10.48550/arXiv.2302.06590 . Submitted on 13 Feb 2023
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.06590 2023
-
[10]
In: Proceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering, pp
Siddiq, M.L., Da Silva Santos, J.C., Tanvir, R.H., Ulfat, N., Al Rifat, F., Car- valho Lopes, V.: Using large language models to generate junit tests: An empirical study. In: Proceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering, pp. 313–322 (2024)
2024
-
[11]
https: 43 //doi.org/10.1145/3643991.3645072 .https://doi.org/10.1145/3643991.3645072
Jin, K., Wang, C.-Y., Pham, H.V., Hemmati, H.: Can chatgpt support devel- opers? an empirical evaluation of large language models for code generation. In: Proceedings of the 21st International Conference on Mining Software Repositories. MSR ’24, pp. 167–171. Association for Computing Machin- ery, New York, NY, USA (2024). https://doi.org/10.1145/3643991.3...
-
[12]
In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering
Guo, Q., Cao, J., Xie, X., Liu, S., Li, X., Chen, B., Peng, X.: Explor- ing the potential of chatgpt in automated code refinement: An empirical study. In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. ICSE ’24, pp. 1–13. Association for Computing Machin- ery, New York, NY, USA (2024). https://doi.org/10.1145/3597503.36...
-
[13]
In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering
Deng, Y., Xia, C.S., Yang, C., Zhang, S.D., Yang, S., Zhang, L.: Large lan- guage models are edge-case generators: Crafting unusual programs for fuzzing deep learning libraries. In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. ICSE ’24, pp. 1–13. Association for Com- puting Machinery, New York, NY, USA (2024). https:/...
-
[14]
Empirical Software Engi- neering31(1), 22 (2026) https://doi.org/10.1007/s10664-025-10745-8
Ehsani, R., Pathak, S., Rodriguez, E.P., Haiduc, S., Chatterjee, P.: What charac- teristics make chatgpt effective for software issue resolution? an empirical study of task, project, and conversational signals in github issues. Empirical Software Engi- neering31(1), 22 (2026) https://doi.org/10.1007/s10664-025-10745-8 . Published online: 18 November 2025
-
[15]
Empirical Software Engineering31(5), 136 (2026) https://doi.org/10.1007/s10664-026-10869-5
Ogenrwot, D., Businge, J.: Patchtrack: A comprehensive analysis of chatgpt’s influence on pull request outcomes. Empirical Software Engineering31(5), 136 (2026) https://doi.org/10.1007/s10664-026-10869-5
-
[16]
Tie, J., Yao, B., Li, T., Fang, H., Ahmed, S.I., Wang, D., Zhou, S.: ”should i give up now?” investigating llm pitfalls in software engineering. ACM Trans. Softw. Eng. Methodol. (2026) https://doi.org/10.1145/3801972 . Just Accepted
-
[17]
Chen, Z., Wang, C., Sun, W., Liu, X., Zhang, J.M., Liu, Y.: Promptware engi- neering: Software engineering for prompt-enabled systems. ACM Trans. Softw. Eng. Methodol. (2026) https://doi.org/10.1145/3796535
-
[18]
Villamizar, H., Fischbach, J., Korn, A., Vogelsang, A., Mendez, D.: Prompts as software engineering artifacts: A research agenda and preliminary findings. In: Product-Focused Software Process Improvement: 26th International Conference, PROFES 2025, Salerno, Italy, December 1–3, 2025, Proceedings, pp. 470–478. Springer, Berlin, Heidelberg (2025). https://d...
-
[19]
Liang, J.T., Lin, M., Rao, N., Myers, B.A.: Prompts are programs too! under- standing how developers build software containing prompts. Proc. ACM Softw. Eng.2(FSE) (2025) https://doi.org/10.1145/3729342
-
[20]
In: Proceedings of the 21st International Conference on Mining Software Repositories
Grewal, B., Lu, W., Nadi, S., Bezemer, C.-P.: Analyzing developer use of chat- gpt generated code in open source github projects. In: Proceedings of the 21st International Conference on Mining Software Repositories. MSR ’24, pp. 157–
-
[21]
https: 43 //doi.org/10.1145/3643991.3645072 .https://doi.org/10.1145/3643991.3645072
Association for Computing Machinery, New York, NY, USA (2024). https: 43 //doi.org/10.1145/3643991.3645072 .https://doi.org/10.1145/3643991.3645072
-
[22]
In: Proceedings of the 21st International Conference on Mining Software Repositories
Siddiq, M.L., Roney, L., Zhang, J., Santos, J.C.D.S.: Quality assessment of chat- gpt generated code and their use by developers. In: Proceedings of the 21st International Conference on Mining Software Repositories. MSR ’24, pp. 152–
-
[23]
https: 43 //doi.org/10.1145/3643991.3645072 .https://doi.org/10.1145/3643991.3645072
Association for Computing Machinery, New York, NY, USA (2024). https: //doi.org/10.1145/3643991.3645071 .https://doi.org/10.1145/3643991.3645071
-
[24]
Della Porta, A., Lambiase, S., Palomba, F.: Do prompt patterns affect code quality? a first empirical assessment of chatgpt-generated code. In: Proceedings of the 29th International Conference on Evaluation and Assessment in Soft- ware Engineering. EASE ’25, pp. 181–192. Association for Computing Machin- ery, New York, NY, USA (2025). https://doi.org/10.1...
-
[25]
In: Proceedings of the IEEE/ACM 46th International Confer- ence on Software Engineering
Tanzil, M.H., Khan, J.Y., Uddin, G.: Chatgpt incorrectness detection in soft- ware reviews. In: Proceedings of the IEEE/ACM 46th International Confer- ence on Software Engineering. ICSE ’24. Association for Computing Machin- ery, New York, NY, USA (2024). https://doi.org/10.1145/3597503.3639194 . https://doi.org/10.1145/3597503.3639194
-
[26]
arXiv preprint arXiv:2506.04418 (2025)
Nashid, N., Ding, D., Gallaba, K., Hassan, A.E., Mesbah, A.: Characteriz- ing multi-hunk patches: Divergence, proximity, and llm repair challenges. arXiv preprint arXiv:2506.04418 (2025)
arXiv 2025
-
[27]
In: Proceedings of the 23rd International Conference on Mining Software Repositories (MSR 2026)
Ogenrwot, D., Businge, J.: How ai coding agents modify code: A large-scale study of github pull requests. In: Proceedings of the 23rd International Conference on Mining Software Repositories (MSR 2026). IEEE/ACM, ??? (2026). Accepted for publication
2026
-
[28]
In: Proceedings of the 3rd ACM Inter- national Conference on AI-powered Software (AIWare 2026)
Ogenrwot, D., Businge, J.: Agenticflict: A large-scale dataset of merge conflicts in ai coding agent pull requests on github. In: Proceedings of the 3rd ACM Inter- national Conference on AI-powered Software (AIWare 2026). ACM, ??? (2026). Accepted for publication
2026
-
[29]
In: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering
Ogenrwot, D., Businge, J.: Patchtrack: Analyzing chatgpt’s impact on software patch decision-making in pull requests. In: Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. ASE ’24, pp. 2480–
-
[30]
https: //doi.org/10.1145/3691620.3695338 .https://doi.org/10.1145/3691620.3695338
Association for Computing Machinery, New York, NY, USA (2024). https: //doi.org/10.1145/3691620.3695338 .https://doi.org/10.1145/3691620.3695338
-
[31]
Wang, G., Sun, Z., Ye, S., Gong, Z., Chen, Y., Zhao, Y., Liang, Q., Hao, D.: Do advanced language models eliminate the need for prompt engineering in software engineering? ACM Trans. Softw. Eng. Methodol. (2025) https://doi.org/10.1145/ 3771933
2025
-
[32]
Bettenburg, N., Just, S., Schr¨ oter, A., Weiss, C., Premraj, R., Zimmermann, 44 T.: What makes a good bug report? In: Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of Software Engineer- ing. SIGSOFT ’08/FSE-16, pp. 308–318. Association for Computing Machin- ery, New York, NY, USA (2008). https://doi.org/10.1145/1453101.145314...
-
[33]
Zimmermann, T., Premraj, R., Bettenburg, N., Just, S., Schroter, A., Weiss, C.: What makes a good bug report? IEEE Transactions on Software Engineering 36(5), 618–643 (2010) https://doi.org/10.1109/TSE.2010.63
-
[34]
In: Proceedings of the 38th International Conference on Software Engineering
Gousios, G., Storey, M.-A., Bacchelli, A.: Work practices and challenges in pull- based development: the contributor’s perspective. In: Proceedings of the 38th International Conference on Software Engineering. ICSE ’16, pp. 285–296. Asso- ciation for Computing Machinery, New York, NY, USA (2016). https://doi.org/ 10.1145/2884781.2884826 .https://doi.org/1...
-
[35]
In: Proceedings of the 36th International Conference on Software Engineering
Tsay, J., Dabbish, L., Herbsleb, J.: Influence of social and technical factors for evaluating contribution in github. In: Proceedings of the 36th International Conference on Software Engineering. ICSE 2014, pp. 356–366. Association for Computing Machinery, New York, NY, USA (2014). https://doi.org/10.1145/ 2568225.2568315 .https://doi.org/10.1145/2568225.2568315
-
[36]
In: Pro- ceedings of the 2015 10th Joint Meeting on Foundations of Software Engi- neering
Vasilescu, B., Yu, Y., Wang, H., Devanbu, P., Filkov, V.: Quality and pro- ductivity outcomes relating to continuous integration in github. In: Pro- ceedings of the 2015 10th Joint Meeting on Foundations of Software Engi- neering. ESEC/FSE 2015, pp. 805–816. Association for Computing Machin- ery, New York, NY, USA (2015). https://doi.org/10.1145/2786805.2...
-
[37]
In: 2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC), pp
Zampetti, F., Ponzanelli, L., Bavota, G., Mocci, A., Di Penta, M., Lanza, M.: How developers document pull requests with external references. In: 2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC), pp. 23–33 (2017). https://doi.org/10.1109/ICPC.2017.30
-
[38]
In: Proceedings of the International Conference on Program Comprehension (ICPC) (2026)
Midolo, A., Giagnorio, A., Zampetti, F., Tufano, R., Bavota, G., Penta, M.D.: Guidelines to prompt large language models for code generation: An empirical characterization. In: Proceedings of the International Conference on Program Comprehension (ICPC) (2026). To appear
2026
-
[39]
arXiv preprint arXiv:2508.15503v3 [cs.SE]
Baltes, S., Angermeir, F., Arora, C., Bar´ on, M.M., Chen, C., B¨ ohme, L., Calefato, F., Ernst, N., Falessi, D., Fitzgerald, B., Fucci, D., Kalinowski, M., Lambiase, S., Russo, D., Lungu, M., Prechelt, L., Ralph, P., Tonder, R., Treude, C., Wagner, S.: Guidelines for empirical studies in software engineering involving large lan- guage models (2025) arXiv...
Pith/arXiv arXiv 2025
-
[40]
In: Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems
Wang, X., Kim, H., Rahman, S., Mitra, K., Miao, Z.: Human-llm collaborative 45 annotation through effective verification of llm labels. In: Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems. CHI ’24. Association for Computing Machinery, New York, NY, USA (2024). https://doi.org/10.1145/ 3613904.3641960 .https://doi.org/10.1145/3...
-
[41]
Takehi, R., Voorhees, E.M., Sakai, T., Soboroff, I.: Llm-assisted relevance assessments: When should we ask llms for help? In: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval. SIGIR ’25, pp. 95–105. Association for Computing Machin- ery, New York, NY, USA (2025). https://doi.org/10.1145/372...
-
[42]
In: Proceedings of the LAK26: 16th International Learning Analytics and Knowledge Conference
Xu, Z., Khatri, V., Dai, Y., Liu, X., Li, S., Zhang, X., Yu, R.: Enhancing llm-based data annotation with error decomposition. In: Proceedings of the LAK26: 16th International Learning Analytics and Knowledge Conference. LAK ’26, pp. 325–
-
[43]
https: //doi.org/10.1145/3785022.3785070 .https://doi.org/10.1145/3785022.3785070
Association for Computing Machinery, New York, NY, USA (2026). https: //doi.org/10.1145/3785022.3785070 .https://doi.org/10.1145/3785022.3785070
-
[44]
Sserunjogi, R., Ogenrwot, D., Businge, J.: Replication Package: A Stage-Based Empirical Study of LLM-Assisted Development. https://doi.org/10.5281/zenodo. 20451325 . https://doi.org/10.5281/zenodo.20451325
-
[45]
In: Proceedings of the 11th Working Conference on Mining Software Repositories
Kalliamvakou, E., Gousios, G., Blincoe, K., Singer, L., German, D.M., Damian, D.: The promises and perils of mining github. In: Proceedings of the 11th Working Conference on Mining Software Repositories. MSR 2014, pp. 92–101. Association for Computing Machinery, New York, NY, USA (2014). https://doi.org/10.1145/ 2597073.2597074 .https://doi.org/10.1145/25...
-
[46]
Ramkisoen, P.K., Businge, J., Bladel, B., Decan, A., Demeyer, S., De Roover, C., Khomh, F.: Pareco: patched clones and missed patches among the divergent variants of a software family. In: Proceedings of the 30th ACM Joint Euro- pean Software Engineering Conference and Symposium on the Foundations of Software Engineering. ESEC/FSE 2022, pp. 646–658. Assoc...
-
[47]
Psychological Bulletin70(4), 213–220 (1968) https: //doi.org/10.1037/h0026256
Cohen, J.: Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit. Psychological Bulletin70(4), 213–220 (1968) https: //doi.org/10.1037/h0026256
-
[48]
John Wiley & Sons, New York (1981)
Fleiss, J.L.: Statistical Methods for Rates and Proportions. John Wiley & Sons, New York (1981)
1981
-
[49]
Climate Research30(1), 79–82 (2005)
Willmott, C.J., Matsuura, K.: Advantages of the mean absolute error (mae) over the root mean square error (rmse) in assessing average model performance. Climate Research30(1), 79–82 (2005). Accessed 2026-04-28 46
2005
-
[50]
Landis, J.R., Koch, G.G.: The measurement of observer agreement for categorical data. Biometrics33(1), 159–174 (1977) https://doi.org/10.2307/2529310
-
[51]
In: International Conference on Software Maintenance and Evolution, pp
Businge, J., Openja, M., Nadi, S., Bainomugisha, E., Berger, T.: Clone-based variability management in the Android ecosystem. In: International Conference on Software Maintenance and Evolution, pp. 625–634. IEEE, ??? (2018)
2018
-
[52]
Businge, J., Decan, A., Zerouali, A., Mens, T., Demeyer, S., De Roover, C.: Vari- ant forks – motivations and impediments. In: Proceedings of the 29th Edition of the IEEE International Conference on Software Analysis, Evolution and Reengi- neering, pp. 867–877. IEEE Computer Society, ??? (2022). https://doi.org/10. 1109/SANER53432.2022.00105
arXiv 2022
-
[53]
Empirical Softw
Businge, J., Openja, M., Nadi, S., Berger, T.: Reuse and maintenance practices among divergent forks in three software ecosystems. Empirical Softw. Engg.27(2) (2022)
2022
-
[54]
McGraw-Hill Irwin, Boston (2005)
Kutner, M.H., Nachtsheim, C.J., Neter, J., Li, W.: Applied Linear Statistical Models, 5th edn. McGraw-Hill Irwin, Boston (2005)
2005
-
[55]
James, G., Witten, D., Hastie, T., Tibshirani, R.: An Introduction to Statistical Learning: with Applications in R. Springer Texts in Statistics. Springer, New York (2013). https://doi.org/10.1007/978-1-4614-7138-7
-
[56]
Biometrika71(1), 1–10 (1984) https://doi.org/10
Albert, A., Anderson, J.A.: On the existence of maximum likelihood estimates in logistic regression models. Biometrika71(1), 1–10 (1984) https://doi.org/10. 1093/biomet/71.1.1
1984
-
[57]
Biometrika69(1), 239–241 (1982) https://doi.org/10.1093/biomet/69.1.239
Schoenfeld, D.: Partial residuals for the proportional hazards regression model. Biometrika69(1), 239–241 (1982) https://doi.org/10.1093/biomet/69.1.239
-
[58]
Biometrika81(3), 515–526 (1994) https://doi.org/ 10.1093/biomet/81.3.515
Grambsch, P.M., Therneau, T.M.: Proportional hazards tests and diagnostics based on weighted residuals. Biometrika81(3), 515–526 (1994) https://doi.org/ 10.1093/biomet/81.3.515
-
[59]
Qualitative Health Research15(9), 1277–1288 (2005) https://doi.org/10.1177/ 1049732305276687
Hsieh, H.-F., Shannon, S.E.: Three approaches to qualitative content analysis. Qualitative Health Research15(9), 1277–1288 (2005) https://doi.org/10.1177/ 1049732305276687
2005
-
[60]
Journal of Systems and Software202, 111707 (2023)
Gonz´ alez-Prieto,´A., Perez, J., Diaz, J., L´ opez-Fern´ andez, D.: Reliability in soft- ware engineering qualitative research through inter-coder agreement. Journal of Systems and Software202, 111707 (2023)
2023
-
[61]
Journal of Systems and Software195, 111520 (2023) 47
D´ ıaz, J., P´ erez, J., Gallardo, C., Gonz´ alez-Prieto,´A.: Applying inter-rater reli- ability and agreement in collaborative grounded theory studies in software engineering. Journal of Systems and Software195, 111520 (2023) 47
2023
-
[62]
Fan, A., Gokkaya, B., Harman, M., Lyubarskiy, M., Sengupta, S., Yoo, S., Zhang, J.M.: Large language models for software engineering: Survey and open problems. In: 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), pp. 31–53 (2023). https://doi.org/10.1109/ ICSE-FoSE59343.2023.00008
arXiv 2023
-
[63]
Empirical Softw
Hao, H., Hasan, K.A., Qin, H., Macedo, M., Tian, Y., Ding, S.H.H., Hassan, A.E.: An empirical study on developers’ shared conversations with chatgpt in github pull requests and issues. Empirical Softw. Engg.29(6) (2024) https://doi.org/10. 1007/s10664-024-10540-x
2024
-
[64]
576–580, doi: 10.1109/MSR66628.2025.00090
Ehsani, R., Pathak, S., Chatterjee, P.: Towards detecting prompt knowledge gaps for improved llm-guided issue resolution. In: 2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR), pp. 699–711 (2025). https: //doi.org/10.1109/MSR66628.2025.00107
-
[65]
arXiv preprint arXiv:2510.06000 (2025) https://doi.org/10.48550/arXiv.2510
Otten, D., Stalnaker, T., Wintersgill, N., Chaparro, O., Poshyvanyk, D.: Prompt- ing in practice: Investigating software practitioners’ use of generative ai tools. arXiv preprint arXiv:2510.06000 (2025) https://doi.org/10.48550/arXiv.2510. 06000
-
[66]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.-N
Tan, Z., Li, D., Wang, S., Beigi, A., Jiang, B., Bhattacharjee, A., Karami, M., Li, J., Cheng, L., Liu, H.: Large language models for data annotation and synthesis: A survey. In: Al-Onaizan, Y., Bansal, M., Chen, Y.-N. (eds.) Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 930–957. Association for Computational ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.