BrainG3N: A Dual-Purpose Tokenizer for Controllable 3D Brain MRI Generation
Pith reviewed 2026-06-26 20:27 UTC · model grok-4.3
The pith
A frozen 3D MAE encoder produces embeddings that support both clinical linear probing and controllable 3D brain MRI generation via conditional DiT.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
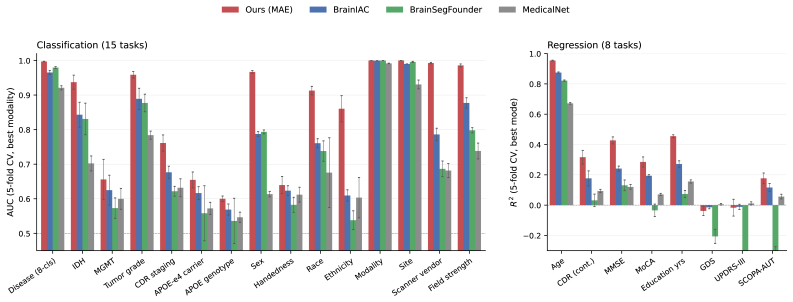
The authors establish that embeddings from one frozen 3D MAE encoder, pretrained across four modalities, ten disease categories and more than 200 sites, retain enough clinical signal to match or exceed prior models on 21 of 23 linear-probing tasks while a separate CNN decoder reconstructs anatomically faithful volumes from a linear projection of those embeddings, enabling a conditional DiT to perform generation across six variables and patient-specific longitudinal forecasting.
What carries the argument
The dual-purpose tokenizer that pairs a frozen 3D MAE encoder for clinically informative embeddings with a dedicated CNN decoder connected by linear projection.
If this is right
- The embeddings enable linear probing that outperforms or matches existing models on 21 of 23 clinical tasks without encoder fine-tuning.
- A conditional diffusion transformer trained on the embeddings supports generation conditioned on six variables.
- The same embeddings allow patient-specific longitudinal forecasting of brain MRI volumes.
- Pretraining on 35,309 volumes spanning 18 cohorts provides broad coverage for both tasks.
Where Pith is reading between the lines
- The shared embedding space could support privacy-preserving synthetic data generation that preserves clinical distributions across cohorts.
- Longitudinal forecasting capability might allow simulation of disease trajectories for planning without additional patient scans.
- The decoupling of encoder and decoder suggests a route to reuse the same clinical embeddings across other generative or analysis pipelines in neuroimaging.
Load-bearing premise
The clinical information retained in the frozen 3D MAE encoder embeddings is sufficient for downstream tasks without any task-specific fine-tuning of the encoder itself, and that the linear projection plus CNN decoder can still produce anatomically faithful reconstructions from those same embeddings.
What would settle it
Linear probing performance falling below SOTA on more than two of the 23 tasks, or generated volumes showing consistent anatomical inaccuracies under expert review, would falsify the claim of dual utility from one embedding space.
Figures


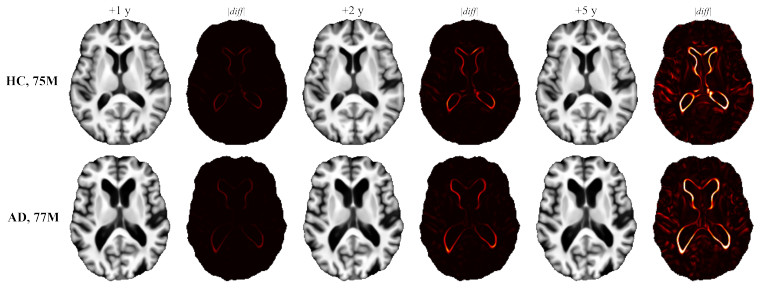
read the original abstract
Three-dimensional (3D) brain MRI is central to clinical neurology and neuro-oncology, where generative models could augment under-represented cohorts, simulate disease trajectories, and support privacy-preserving data sharing. Latent diffusion has been the go-to solution for modeling imaging data, but it places two competing demands on the tokenizer: encoder embeddings must retain the clinical information that downstream tasks act on, and the decoder must reconstruct anatomically faithful volumes. Existing reconstruction-driven tokenizers achieve the second at the expense of the first. To address this, we introduce a fully volumetric masked-autoencoder (MAE) based tokenizer for 3D brain MRI latent diffusion, decoupling encoder and decoder: a frozen 3D MAE encoder produces clinically informative embeddings, while a dedicated CNN decoder reconstructs voxels from a linear projection of those embeddings. We pretrain the encoder on 35,309 volumes from 18 public cohorts spanning four modalities, ten disease categories, and 200+ acquisition sites, and demonstrate its dual utility in two settings. First, on a 23-task linear-probing benchmark, the encoder outperforms or matches SOTA models (i.e., BrainIAC, BrainSegFounder, and MedicalNet) on 21 of 23 tasks. Second, a conditional diffusion transformer (DiT) trained on these clinically informative embeddings supports both conditional generation across six variables and patient-specific longitudinal forecasting. Together these results establish a single 3D brain-MRI embedding space capable of both downstream clinical tasks and controllable generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BrainG3N, a dual-purpose tokenizer for 3D brain MRI latent diffusion. It pretrains a 3D MAE encoder on 35,309 volumes from 18 cohorts, freezes it to produce clinically informative embeddings, routes those through a linear projection to a dedicated CNN decoder for voxel reconstruction, and trains a conditional DiT on the embeddings for controllable generation across six variables plus patient-specific longitudinal forecasting. The encoder is reported to outperform or match SOTA (BrainIAC, BrainSegFounder, MedicalNet) on 21 of 23 linear-probing tasks.
Significance. If the dual-purpose claim holds, the work would be significant for neuroimaging by supplying a single embedding space that supports both clinical downstream tasks without encoder fine-tuning and controllable generative modeling. The large-scale, multi-cohort, multi-modality pretraining is a clear strength; successful validation would directly address the tension between clinical signal retention and anatomical reconstruction fidelity in latent diffusion tokenizers.
major comments (2)
- [Abstract] Abstract: The central dual-utility claim requires that embeddings from the frozen MAE encoder remain sufficiently informative after the additional linear projection step for the separate CNN decoder to produce anatomically faithful volumes usable by the DiT; however, the manuscript supplies no quantitative reconstruction metrics (PSNR, SSIM, or equivalent), no ablation of the linear-projection interface, and no comparison against reconstruction-driven baselines, leaving the generation side of the argument unverified.
- [Abstract] Abstract: The 23-task linear-probing benchmark reports wins on 21 tasks, but the text provides no dataset-split details, error bars, multiple-testing correction, or task definitions, making it impossible to assess whether the performance advantage is robust or whether information loss at the linear-projection step affects downstream clinical utility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications from the full text and indicate revisions where the presentation can be strengthened without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central dual-utility claim requires that embeddings from the frozen MAE encoder remain sufficiently informative after the additional linear projection step for the separate CNN decoder to produce anatomically faithful volumes usable by the DiT; however, the manuscript supplies no quantitative reconstruction metrics (PSNR, SSIM, or equivalent), no ablation of the linear-projection interface, and no comparison against reconstruction-driven baselines, leaving the generation side of the argument unverified.
Authors: The manuscript emphasizes the clinical utility of the frozen encoder embeddings (via 23-task probing) and their direct use as conditioning for the DiT, with the linear projection plus CNN decoder serving as an auxiliary reconstruction pathway to close the tokenizer loop. We agree that explicit reconstruction metrics would better substantiate the fidelity of this pathway. In revision we will add PSNR, SSIM, and perceptual metrics for the CNN decoder, an ablation isolating the linear-projection step, and a brief comparison to reconstruction-driven tokenizers, while preserving the primary focus on the embedding space. revision: yes
-
Referee: [Abstract] Abstract: The 23-task linear-probing benchmark reports wins on 21 tasks, but the text provides no dataset-split details, error bars, multiple-testing correction, or task definitions, making it impossible to assess whether the performance advantage is robust or whether information loss at the linear-projection step affects downstream clinical utility.
Authors: The full manuscript and supplementary material define the 23 tasks, describe the multi-cohort splits, and report per-task accuracies, but these details are not consolidated in the main text or abstract. We will expand the methods and results sections to include explicit dataset-split descriptions, error bars from repeated runs, Bonferroni or FDR correction for the 23 comparisons, and a direct before/after-projection probing comparison to quantify any information loss. This will allow readers to evaluate robustness and clinical utility more rigorously. revision: yes
Circularity Check
No circularity in claimed derivation chain
full rationale
The paper presents two independent empirical evaluations of a frozen 3D MAE encoder pretrained on 35,309 external public volumes: (1) linear probing on a 23-task benchmark where it matches or exceeds cited SOTA models, and (2) training a separate conditional DiT on the resulting embeddings for generation. No equations, fitted parameters, or self-citations are described that reduce either result to the other by construction, nor is any prediction shown to be a renaming or re-use of its own inputs. The architecture's decoupling of encoder and decoder is stated explicitly without circular justification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. J. Aine et al. Multimodal neuroimaging in schizophrenia: Description and dissemination. Neuroinformatics, 15(4):343–364, 2017
2017
-
[2]
Albergo, Mark Goldstein, Nicholas M
Michael S. Albergo, Mark Goldstein, Nicholas M. Boffi, Rajesh Ranganath, and Eric Vanden-Eijnden. Stochastic interpolants with data-dependent couplings. InICML, 2024. arXiv:2310.03725
arXiv 2024
-
[3]
Alexander et al
Lindsay M. Alexander et al. An open resource for transdiagnostic research in pediatric mental health and learning disorders.Scientific Data, 2017
2017
-
[4]
Avants, Charles L
Brian B. Avants, Charles L. Epstein, Murray Grossman, and James C. Gee. Symmetric diffeo- morphic image registration with cross-correlation.Medical Image Analysis, 2008
2008
-
[5]
The University of Pennsylvania glioblastoma (UPenn-GBM) cohort
Spyridon Bakas et al. The University of Pennsylvania glioblastoma (UPenn-GBM) cohort. Scientific Data, 2022. 8
2022
-
[6]
Biswal et al
Bharat B. Biswal et al. Toward discovery science of human brain function.PNAS, 2010
2010
-
[7]
The UCSF-PDGM: A public radiology-pathology dataset for diffuse glioma.Radiology: Artificial Intelligence, 2022
Evan Calabrese et al. The UCSF-PDGM: A public radiology-pathology dataset for diffuse glioma.Radiology: Artificial Intelligence, 2022
2022
-
[8]
Extracting training data from dif- fusion models
Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from dif- fusion models. InUSENIX Security, 2023
2023
-
[9]
Masked autoencoders are effective tokenizers for diffusion models
Hao Chen, Yujin Han, Fangyi Chen, Xiang Li, Yidong Wang, Jindong Wang, Ze Wang, Zicheng Liu, Difan Zou, and Bhiksha Raj. Masked autoencoders are effective tokenizers for diffusion models. InICML, 2025. arXiv:2502.03444
arXiv 2025
-
[10]
Med3d: Transfer learning for 3d medical image analysis.arXiv:1904.00625, 2019
Sihong Chen, Kai Ma, and Yefeng Zheng. Med3d: Transfer learning for 3d medical image analysis.arXiv:1904.00625, 2019
Pith/arXiv arXiv 1904
-
[11]
Stolte, Yunchao Yang, Kang Liu, Kyle B
Joseph Cox, Peng Liu, Skylar E. Stolte, Yunchao Yang, Kang Liu, Kyle B. See, Huiwen Ju, and Ruogu Fang. BrainSegFounder: Towards 3D foundation models for neuroimage segmentation. Medical Image Analysis, 2024. arXiv:2406.10395
arXiv 2024
-
[12]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat GANs on image synthesis. In NeurIPS, 2021
2021
-
[13]
Di Martino et al
A. Di Martino et al. The autism brain imaging data exchange.Molecular Psychiatry, 2014
2014
-
[14]
Di Martino et al
A. Di Martino et al. Enhancing studies of the connectome in autism using the Autism Brain Imaging Data Exchange II.Scientific Data, 2017
2017
-
[15]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[16]
Gollub et al
Randy L. Gollub et al. The MCIC collection: A shared repository of multi-modal, multi-site brain image data from a clinical investigation of schizophrenia.Neuroinformatics, 11(3):367– 388, 2013
2013
-
[17]
GenerateCT: Text-conditional generation of 3D chest CT volumes
Ibrahim Ethem Hamamci, Sezgin Er, Furkan Almas, Ayse Gulnihan Simsek, Sevval Nil Esir- gun, Irem Dogan, Muhammed Furkan Dasdelen, Bastian Wittmann, Enis Simsar, Mehmet Simsek, et al. GenerateCT: Text-conditional generation of 3D chest CT volumes. InECCV,
-
[18]
Better tokens for bet- ter 3D: Advancing vision-language modeling in 3D medical imaging
Ibrahim Ethem Hamamci, Sezgin Er, Suprosanna Shit, Hadrien Reynaud, Dong Yang, Pengfei Guo, Marc Edgar, Daguang Xu, Bernhard Kainz, and Bjoern Menze. Better tokens for bet- ter 3D: Advancing vision-language modeling in 3D medical imaging. InNeurIPS, 2025. arXiv:2510.20639
arXiv 2025
-
[19]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InCVPR, 2022
2022
-
[20]
Classifier-free diffusion guidance.NeurIPS Workshop, 2021
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.NeurIPS Workshop, 2021
2021
-
[21]
Holmes et al
Avram J. Holmes et al. Brain Genomics Superstruct Project initial data release with structural, functional, and behavioral measures.Scientific Data, 2015
2015
-
[22]
Automated brain extraction of multisequence MRI using artificial neural networks.Human Brain Mapping, 2019
Fabian Isensee et al. Automated brain extraction of multisequence MRI using artificial neural networks.Human Brain Mapping, 2019
2019
-
[23]
IXI dataset.https://brain-development.org/ixi-dataset/
IXI Project. IXI dataset.https://brain-development.org/ixi-dataset/. Accessed 2025
2025
-
[24]
Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
Yaron Lipman, Ricky T.Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[25]
Marcus et al
Daniel S. Marcus et al. Open access series of imaging studies (OASIS).Journal of Cognitive Neuroscience, 2007. 9
2007
-
[26]
Marcus et al
Daniel S. Marcus et al. Open access series of imaging studies (OASIS): Longitudinal MRI data in nondemented and demented older adults.Journal of Cognitive Neuroscience, 2010
2010
-
[27]
The parkinson progression marker initiative (PPMI).Progress in Neuro- biology, 2011
Kenneth Marek et al. The parkinson progression marker initiative (PPMI).Progress in Neuro- biology, 2011
2011
-
[28]
The NKI-Rockland sample: A model for accelerating the pace of discovery science in psychiatry.Frontiers in Neuroscience, 2012
Kate Brody Nooner et al. The NKI-Rockland sample: A model for accelerating the pace of discovery science in psychiatry.Frontiers in Neuroscience, 2012
2012
-
[29]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[30]
Petersen et al
Ronald C. Petersen et al. Alzheimer’s Disease Neuroimaging Initiative (ADNI): Clinical char- acterization.Neurology, 74(3):201–209, 2010
2010
-
[31]
Walter H. L. Pinaya, Petru-Daniel Tudosiu, Jessica Dafflon, Pedro F. Da Costa, Virginia Fernan- dez, Parashkev Nachev, Sebastien Ourselin, and M. Jorge Cardoso. Brain imaging generation with latent diffusion models.arXiv:2209.07162, 2022
arXiv 2022
-
[32]
Lemuel Puglisi, Daniel C. Alexander, and Daniele Ravì. Enhancing spatiotemporal dis- ease progression models via latent diffusion and prior knowledge. InMICCAI, 2024. arXiv:2405.03328
arXiv 2024
-
[33]
Zahr, Edith V
Torsten Rohlfing, Natalie M. Zahr, Edith V . Sullivan, and Adolf Pfefferbaum. The SRI24 multichannel atlas of normal adult human brain structure.Human Brain Mapping, 31(5), 2010
2010
-
[34]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[35]
Christoph Sadée, Stefano Testa, Thomas Barba, Katherine Hartmann, Maximilian Schuessler, Alexander Thieme, George M. Church, Ifeoma Okoye, Tina Hernandez-Boussard, Leroy Hood, Ilya Shmulevich, Ellen Kuhl, and Olivier Gevaert. Medical digital twins: enabling precision medicine and medical artificial intelligence.The Lancet Digital Health, 7(7):e100864, 202...
-
[36]
Garomsa, Anna Zapaishchykova, Tafadzwa L
Divyanshu Tak, Biniam A. Garomsa, Anna Zapaishchykova, Tafadzwa L. Chaunzwa, Juan Car- los Climent Pardo, Zezhong Ye, John Zielke, Yashwanth Ravipati, Suraj Pai, Sri Vajapeyam, et al. A generalizable foundation model for analysis of human brain MRI.Nature Neuroscience, 29:945–956, 2026
2026
-
[37]
The ADHD-200 consortium: A model to advance the transla- tional potential of neuroimaging in clinical neuroscience.Frontiers in Systems Neuroscience, 2012
The ADHD-200 Consortium. The ADHD-200 consortium: A model to advance the transla- tional potential of neuroimaging in clinical neuroscience.Frontiers in Systems Neuroscience, 2012
2012
-
[38]
Tustison et al
Nicholas J. Tustison et al. N4ITK: Improved N3 bias correction.IEEE TMI, 2010
2010
-
[39]
Van Essen et al
David C. Van Essen et al. The WU-Minn human connectome project: An overview.NeuroIm- age, 2013
2013
-
[40]
Anatomi- cally guided latent diffusion for brain MRI progression modeling.arXiv:2601.14584, 2026
Cheng Wan, Bahram Jafrasteh, Ehsan Adeli, Miaomiao Zhang, and Qingyu Zhao. Anatomi- cally guided latent diffusion for brain MRI progression modeling.arXiv:2601.14584, 2026
arXiv 2026
-
[41]
Haoshen Wang, Zhentao Liu, Kaicong Sun, Xiaodong Wang, Dinggang Shen, and Zhiming Cui. 3D MedDiffusion: A 3D medical latent diffusion model for controllable and high-quality medical image generation.arXiv:2412.13059, 2024
arXiv 2024
-
[42]
SchizConnect: Mediating neuroimaging databases on schizophrenia and re- lated disorders for large-scale integration.NeuroImage, 124:1155–1167, 2016
Lei Wang et al. SchizConnect: Mediating neuroimaging databases on schizophrenia and re- lated disorders for large-scale integration.NeuroImage, 124:1155–1167, 2016
2016
-
[43]
Yizhou Wu, Shansong Wang, Yuheng Li, Mojtaba Safari, Mingzhe Hu, Chih-Wei Chang, Harini Veeraraghavan, and Xiaofeng Yang. BrainDINO: A brain MRI foundation model for generalizable clinical representation learning.arXiv preprint arXiv:2604.27277, 2026
Pith/arXiv arXiv 2026
-
[44]
Yongrui Yu, Yannian Gu, Shaoting Zhang, and Xiaofan Zhang. MedDiff-FM: A diffusion- based foundation model for versatile medical image applications.arXiv:2410.15432, 2024
arXiv 2024
-
[45]
Xi-Nian Zuo et al. An open science resource for establishing reliability and reproducibility in functional connectomics.Scientific Data, 2014. 10 A Dataset card Aggregation.35,309 preprocessed brain MRI volumes from 17,399 unique subjects across 18 public cohorts and 200+ acquisition sites worldwide. Four imaging modalities (T1, T2, FLAIR, T1c). Ages 5–98...
arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.