A Layered Security Framework Against Prompt Injection in RAG-Based Chatbots
Pith reviewed 2026-06-26 19:58 UTC · model grok-4.3
The pith
A three-layer framework reduces prompt injection success rate in RAG chatbots from 71.4% to 11.3%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
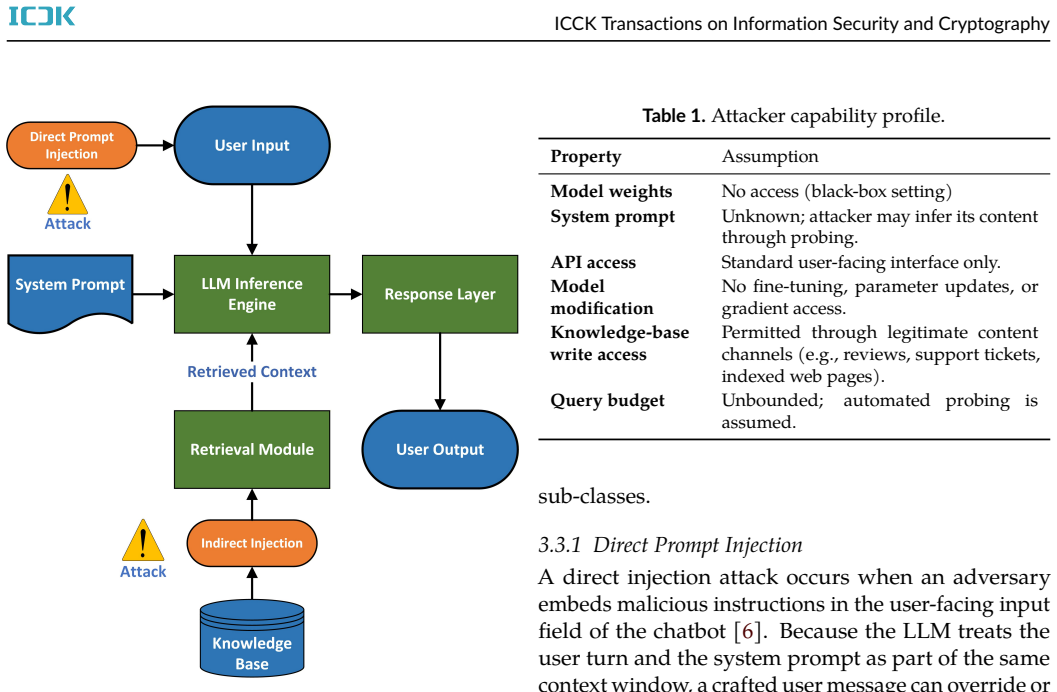
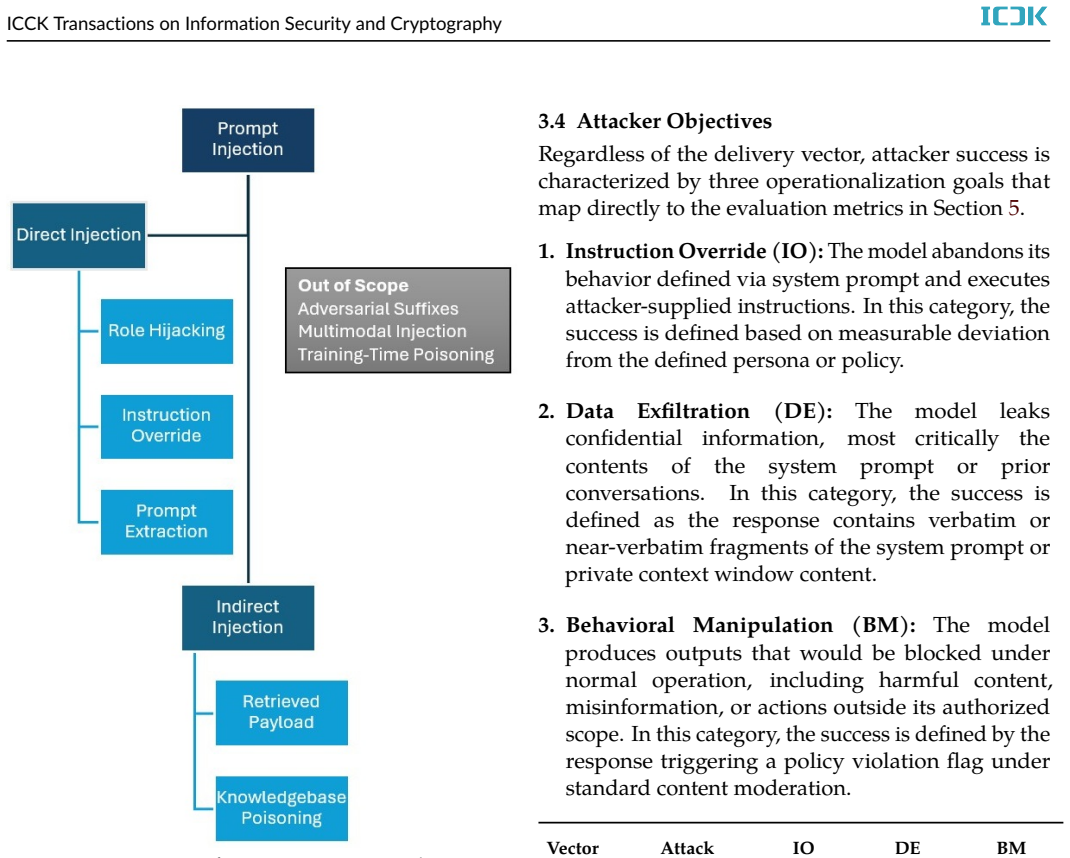
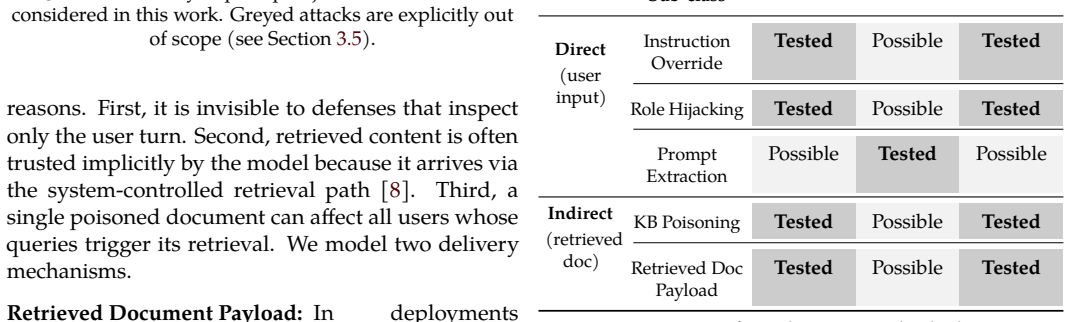
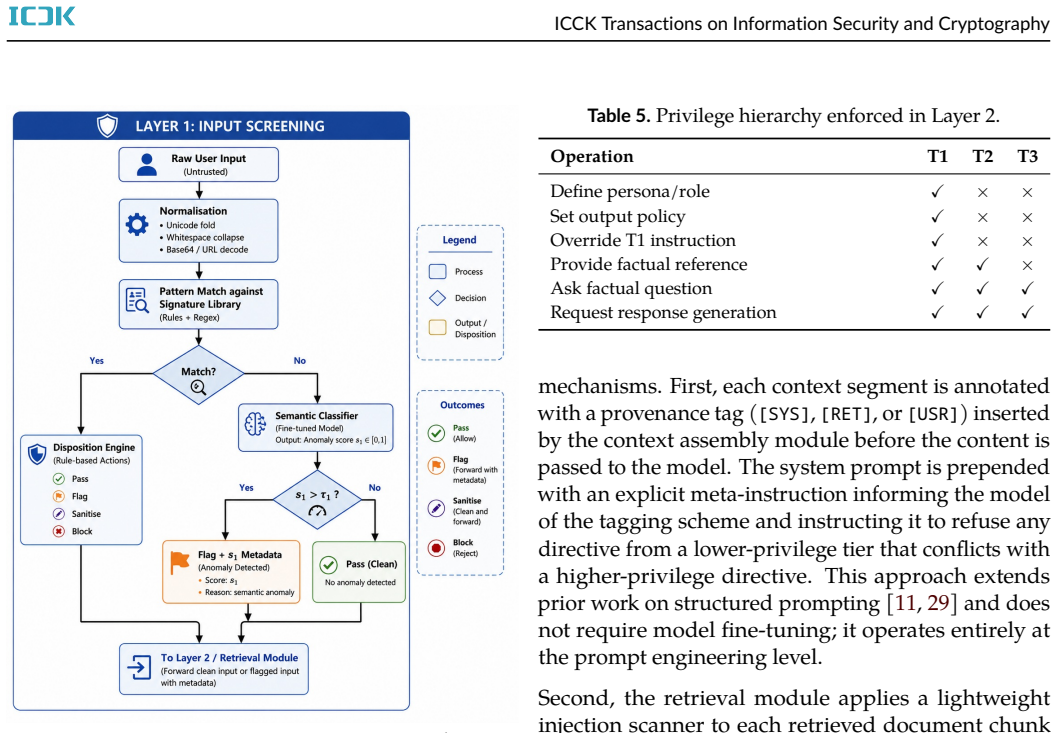
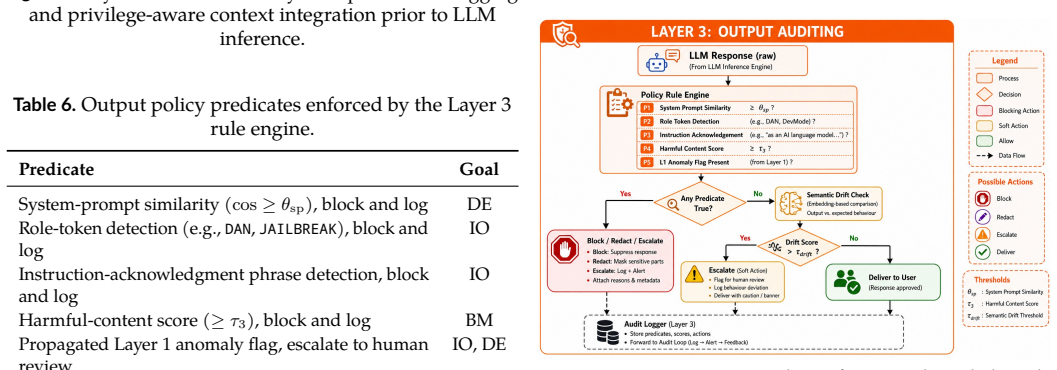
The paper claims that a model-agnostic middleware framework using three complementary layers reduces Attack Success Rate from 71.4% to 11.3% on 5080 samples spanning GPT-4o, Llama 3, and Mistral 7B. Layer 1 applies rule patterns and a fine-tuned semantic anomaly classifier to user input. Layer 2 enforces a provenance-based instruction hierarchy during context assembly so retrieved documents cannot override operator policy. Layer 3 runs a policy rule engine and semantic drift detector on model output before delivery. Ablation results show the three layers together exceed the protection of any single layer or published guardrail system.
What carries the argument
The three-layer interception pipeline that screens input, enforces provenance hierarchy in context assembly, and audits output before delivery.
If this is right
- All three layers supply complementary protection whose combined effect exceeds the sum of the parts.
- The framework outperforms the best single-layer baseline by 27.3 percentage points and a published guardrail by 23.8 percentage points.
- False positive rate stays at 4.8% and median added latency is 61.2 ms across the tested models.
- The continuous audit loop aggregates logs to support retraining and adaptation to new attack patterns.
Where Pith is reading between the lines
- Deploying the middleware in existing RAG pipelines would require only configuration of the policy rules and periodic classifier updates rather than model changes.
- If semantic drift detection thresholds are set too loosely, the system could miss subtle output manipulations that still achieve injection goals.
- The same layered structure could be tested against related threats such as retrieval poisoning or context window overflow attacks.
- Long-term maintenance cost depends on how quickly new attack patterns appear relative to the retraining cycle described in the audit loop.
Load-bearing premise
The 5080 evaluation samples and ablation studies accurately represent realistic direct and indirect prompt-injection attacks that would occur in production RAG deployments.
What would settle it
A production RAG chatbot protected by the framework that still experiences an attack success rate above 11.3% on realistic direct or indirect injections would falsify the central performance claim.
Figures






read the original abstract
Prompt injection is ranked as the most critical vulnerability in large language model (LLM) deployments by the OWASP Top 10 for LLM Applications, yet existing defenses operate at isolated pipeline stages and remain incomplete. Input filters cannot inspect retrieved documents, while output monitors cannot prevent malicious payloads from reaching the model. Consequently, retrieval-augmented generation (RAG) chatbots remain vulnerable to indirect injection, where a poisoned knowledge-base document compromises every user whose query retrieves it. We present a three-layer framework that intercepts both direct and indirect prompt injection throughout the inference pipeline. Layer 1 screens user input using a rule-based pattern library and a fine-tuned semantic anomaly classifier. Layer 2 enforces a provenance-based instruction hierarchy during context assembly, preventing retrieved content from overriding operator policy. Layer 3 audits model output using a policy rule engine and semantic drift detector before delivery. A continuous audit loop aggregates structured logs and supports retraining to adapt the classifier to emerging attack patterns. The framework is model-agnostic and deploys as middleware without modifying the underlying LLM. Evaluation on 5,080 samples across GPT-4o, Llama 3, and Mistral 7B shows that the framework reduces Attack Success Rate (ASR) from 71.4\% to 11.3\%, outperforming the best single-layer baseline by 27.3 percentage points and a published guardrail system by 23.8 percentage points, while maintaining a 4.8\% false positive rate and a median latency overhead of 61.2 ms. Ablation studies confirm that all three layers provide complementary protection and that their combined effect exceeds the sum of individual contributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a three-layer middleware framework for defending RAG-based chatbots against direct and indirect prompt injection. Layer 1 applies rule-based patterns plus a fine-tuned semantic anomaly classifier to user input; Layer 2 enforces a provenance-based instruction hierarchy during context assembly; Layer 3 audits output with a policy engine and semantic drift detector. A continuous audit loop supports retraining. Evaluation on 5,080 samples across GPT-4o, Llama 3, and Mistral 7B reports ASR reduction from 71.4% to 11.3%, outperforming the best single-layer baseline by 27.3 pp and a published guardrail by 23.8 pp, with 4.8% FPR and 61.2 ms median latency overhead. Ablations claim complementary protection from the three layers.
Significance. If the evaluation methodology and sample distribution are shown to be realistic, the work would supply a practical, model-agnostic deployment path for a top-ranked LLM vulnerability, with quantitative evidence that layered defenses exceed single-stage approaches and incur modest overhead.
major comments (3)
- [Evaluation] Evaluation section (and abstract): the central ASR reduction claim (71.4% → 11.3%) rests on an internal collection of 5,080 samples whose construction, attack-prompt distribution, and coverage of realistic indirect/obfuscated injections are not described. Without this information it is impossible to assess whether the reported complementarity of the three layers generalizes beyond the authors' own test distribution.
- [Ablation studies] Ablation studies paragraph: all ablations are performed on the same fixed internal set used for the main results; no hold-out, external corpus, or production-traffic validation is reported. This makes the claim that "their combined effect exceeds the sum of individual contributions" dependent on the unverified representativeness of the test attacks.
- [Evaluation] Baseline comparison: the manuscript states that the framework outperforms "the best single-layer baseline" and "a published guardrail system" by 27.3 and 23.8 percentage points, yet supplies no information on how those baselines were re-implemented or whether the same attack prompts were used.
minor comments (2)
- [Evaluation] The abstract and evaluation section report aggregate metrics without mentioning statistical significance tests or confidence intervals on the ASR differences.
- [Layer 1] No description is given of the training data or hyperparameters used for the fine-tuned semantic anomaly classifier in Layer 1.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing evaluation transparency. We address each major comment below and will revise the manuscript to provide the requested details on dataset construction, ablation methodology, and baseline implementations.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): the central ASR reduction claim (71.4% → 11.3%) rests on an internal collection of 5,080 samples whose construction, attack-prompt distribution, and coverage of realistic indirect/obfuscated injections are not described. Without this information it is impossible to assess whether the reported complementarity of the three layers generalizes beyond the authors' own test distribution.
Authors: We agree that additional description of the test set is required. The 5,080 samples were assembled from public prompt-injection repositories, synthetic indirect attacks via poisoned RAG documents, and obfuscated variants drawn from recent literature. In the revised manuscript we will expand Section 4.1 with a breakdown of attack categories and proportions, example prompts, and generation methodology so that readers can evaluate coverage and generalizability. revision: yes
-
Referee: [Ablation studies] Ablation studies paragraph: all ablations are performed on the same fixed internal set used for the main results; no hold-out, external corpus, or production-traffic validation is reported. This makes the claim that "their combined effect exceeds the sum of individual contributions" dependent on the unverified representativeness of the test attacks.
Authors: Ablations were run on the full set to isolate each layer's marginal contribution under identical attack conditions. We acknowledge the absence of hold-out or external validation. The revision will add an explicit limitations paragraph explaining this design choice and the consistency observed across three LLMs, while noting plans for future cross-validation studies. revision: partial
-
Referee: [Evaluation] Baseline comparison: the manuscript states that the framework outperforms "the best single-layer baseline" and "a published guardrail system" by 27.3 and 23.8 percentage points, yet supplies no information on how those baselines were re-implemented or whether the same attack prompts were used.
Authors: Single-layer baselines were re-implemented from the original publications and adapted to the RAG pipeline; the published guardrail was evaluated on the identical 5,080 prompts. The revision will include a dedicated subsection (or appendix) describing the re-implementation steps, parameter settings, and explicit confirmation that the same attack prompts were used for all comparisons. revision: yes
Circularity Check
No circularity; empirical metrics on fixed test set with no derivations or self-referential definitions
full rationale
The manuscript presents an empirical security framework evaluated on a fixed collection of 5,080 samples. No equations, fitted parameters, uniqueness theorems, or derivation chains appear in the provided text. The central claim (ASR reduction from 71.4% to 11.3%) is a direct measurement on the reported test distribution rather than a quantity defined in terms of itself or obtained by renaming a fitted input. Self-citations are absent from the abstract and evaluation description. The evaluation methodology is therefore self-contained against external benchmarks and does not reduce to any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GPT-4o system card
OpenAI, “GPT-4o system card.”https:/ /openai.com/index /gpt-4o-system-card, 2024
2024
-
[2]
Llama 3 model card
Meta AI, “Llama 3 model card.”https:/ /ai.meta.com/blog /meta-llama-3/, 2024
2024
-
[3]
A. Q. Jianget al., “Mistral 7B,”arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Retrieval-augmented generation for knowledge-intensiveNLPtasks,
P. Lewiset al., “Retrieval-augmented generation for knowledge-intensiveNLPtasks,”inAdvancesinNeural Information Processing Systems (NeurIPS), 2020
2020
-
[5]
OWASP top 10 for large language model applications
OWASP Foundation, “OWASP top 10 for large language model applications.”https:/ /owasp.org/www-pr oject-top-10-for-large-language-model-applications/, 2023
2023
-
[6]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez and M. T. Ribeiro, “Ignore previous prompt: Attack techniques for language models.” arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Prompt injection attacks against GPT-3
S. Willison, “Prompt injection attacks against GPT-3.” https:/ /simonwillison.net/2022/Sep/12/prompt-injection/, 2022
2022
-
[8]
K. Greshakeet al., “Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,”arXiv preprint arXiv:2302.12173, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Evaluating the susceptibility of pre-trained language models via handcrafted adversarialexamples,
H. Branchet al., “Evaluating the susceptibility of pre-trained language models via handcrafted adversarialexamples,”arXivpreprintarXiv:2209.02128, 2022
-
[10]
Formalizing and Benchmarking Prompt Injection Attacks and Defenses
Y. Liuet al., “Prompt injection attacks and defenses in LLM-integrated applications,”arXiv preprint arXiv:2310.12815, 2023
-
[11]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
E. Wallaceet al., “The instruction hierarchy: Training LLMs to prioritise privileged instructions,”arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails
T. Rebedeaet al., “NeMo Guardrails: A toolkit for controllable and safe LLM applications with programmable rails.” arXiv preprint arXiv:2310.10501, 2023
-
[13]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H.Inanetal.,“LlamaGuard: LLM-basedinput-output safeguard for human-AI conversations.” arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
N. Ahmed, M. I. Zaman, G. Saleem, and A. Hassan, “Do llms know they are being tested? evaluation awareness and incentive-sensitive failures in gpt-oss-20b,”arXiv preprint arXiv:2510.08624, 2025
-
[15]
Improving arabicmulti-label emotion classificationusing stacked embeddings and hybrid loss function,
Y. Xu, M. A. Aslam, W. Jun, N. Ahmed, M. I. Zaman, M. Hamza, and S. Aslam, “Improving arabicmulti-label emotion classificationusing stacked embeddings and hybrid loss function,”IEEE Access, 2025
2025
-
[16]
Benchmarking and defending against indirect prompt injection attacks on large language models,
J. Yiet al., “Benchmarking and defending against indirect prompt injection attacks on large language models,”arXiv preprint arXiv:2312.14197, 2023
-
[17]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
X. Liuet al., “Jailbreaking ChatGPT via prompt engineering: An empirical study,”arXiv preprint arXiv:2305.13860, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zouet al., “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Baselinedefensesforadversarialattacks against aligned language models,
N.Jainetal.,“Baselinedefensesforadversarialattacks against aligned language models,” 2023
2023
-
[20]
SmoothLLM: Defending large language models against jailbreaking attacks,
A. Robeyet al., “SmoothLLM: Defending large language models against jailbreaking attacks,” 2023
2023
-
[21]
StruQ: Defending against prompt injection with structured queries,
S. Chenet al., “StruQ: Defending against prompt injection with structured queries,” 2024
2024
-
[22]
Jailbreak and guard aligned language models with only few in-context demonstrations, 2024
Z. Wuet al., “Defending ChatGPT against jailbreak attack via self-reminder.” arXiv preprint arXiv:2310.06387, 2023
-
[23]
PromptBench: Towards evaluating the robustness of large language models on adversarial prompts,
K. Zhuet al., “PromptBench: Towards evaluating the robustness of large language models on adversarial prompts,” 2023
2023
-
[24]
S.Schulhoffetal.,“IgnorethistitleandHackAPrompt: Exposing systemic vulnerabilities of LLMs through a global prompt hacking competition.” arXiv preprint arXiv:2311.16119, 2023
-
[25]
Shostack,Threat Modeling: Designing for Security
A. Shostack,Threat Modeling: Designing for Security. Wiley, 2014
2014
-
[26]
Promptsshouldnotbeseenassecrets: Systematically measuring prompt extraction attack success
Y.Zhangetal., “Promptsshouldnotbeseenassecrets: Systematically measuring prompt extraction attack success.” arXiv preprint arXiv:2307.06865, 2023
-
[27]
Poisoning language models during instruction tuning,
A. Wanet al., “Poisoning language models during instruction tuning,” 2023
2023
-
[28]
Abusing images and sounds for indirect instruction injection in multi-modal LLMs,
E. Bagdasaryan and V. Shmatikov, “Abusing images and sounds for indirect instruction injection in multi-modal LLMs,” 2023
2023
-
[29]
Constitutional AI: Harmlessness from AI Feedback
Anthropic, “Constitutional AI: Harmlessness from AI feedback.” arXiv preprint arXiv:2212.08073, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Dense passage retrieval for open-domain question answering,
V. Karpukhinet al., “Dense passage retrieval for open-domain question answering,” inProceedings of EMNLP, 2020
2020
-
[31]
Billion-scale similarity search with GPUs,
J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with GPUs,”IEEE Transactions on Big Data, 2019
2019
-
[32]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
T. Wolfet al., “HuggingFace transformers: State-of-the-art natural language processing.” arXiv preprint arXiv:1910.03771, 2020
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[33]
Sentence-BERT: 19 ICCK T ransactions on Information Security and Cryptography Sentence embeddings using siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: 19 ICCK T ransactions on Information Security and Cryptography Sentence embeddings using siamese BERT-networks,” inProceedings of EMNLP, 2019
2019
-
[34]
Decoupled weight decay regularisation,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularisation,” inProceedings of ICLR, 2019
2019
-
[35]
Llama Guard 2: Safeguarding human-AI conversations
Meta AI, “Llama Guard 2: Safeguarding human-AI conversations.”https:/ /ai.meta.com/research/publications/ll ama-guard-2/, 2024
2024
-
[36]
MS MARCO: A human generated machine reading comprehension dataset,
T. Nguyenet al., “MS MARCO: A human generated machine reading comprehension dataset,” in Proceedings of NeurIPS Workshop on Cognitive Computation, 2016
2016
-
[37]
Judging LLM-as-a-judge with MT-Bench and chatbot arena,
L. Zhenget al., “Judging LLM-as-a-judge with MT-Bench and chatbot arena,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[38]
BERTScore: Evaluatingtextgeneration with BERT,
T.Zhangetal.,“BERTScore: Evaluatingtextgeneration with BERT,” inProceedings of ICLR, 2020
2020
-
[39]
Towards evaluating the robustnessofneuralnetworks,
N. Carlini and D. Wagner, “Towards evaluating the robustnessofneuralnetworks,”in2017ieeesymposium on security and privacy (sp), pp. 39–57, Ieee, 2017. Data and Code AvailabilityThe datasets, code, and related resources used in the implementation and experiments of this study are available at: GitHub Repository. Funding This study did not receive any speci...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.