A Bayesian spatio-temporal nearest neighbor Gaussian process model for pooled genetic data
Pith reviewed 2026-06-26 16:41 UTC · model grok-4.3
The pith
A nearest neighbor Gaussian process model with a linear-cost sequential Monte Carlo algorithm enables inference of haplotype frequencies from pooled genetic data with six markers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that the NNGP model for pooled genetic data, when combined with the novel SMC squared algorithm that employs particle Gibbs with ancestor sampling to update the NNGP values, achieves linear computational cost in both the number of observations and the number of NNGPs. This permits analysis of datasets involving six genetic markers, extending beyond the three-marker limit of earlier spatio-temporal models, as validated through application to antimalarial drug resistance data in Africa.
What carries the argument
The nearest neighbor Gaussian process (NNGP) model, which approximates a full Gaussian process by conditioning each point only on its nearest neighbors to capture spatio-temporal dependencies in haplotype frequencies, paired with the SMC squared algorithm that mutates the NNGP function values via particle Gibbs with ancestor sampling.
If this is right
- The method applies to a broad range of NNGP models beyond the genetic context.
- Computational cost scales linearly with observations and NNGPs rather than cubically.
- Empirical results confirm feasibility for both three- and six-marker datasets.
- Enables spatio-temporal inference on larger pooled genetic datasets for tracking resistance.
Where Pith is reading between the lines
- The linear scaling could support integration with real-time surveillance systems for infectious diseases.
- If the approximation accuracy generalizes, similar techniques might apply to other high-dimensional spatial data problems like climate or ecological modeling.
- Testing on datasets with varying numbers of markers could reveal the point where the NNGP approximation begins to degrade.
Load-bearing premise
The nearest neighbor approximation in the Gaussian process remains accurate enough to capture the true spatio-temporal structure in the pooled haplotype frequency data as the number of markers increases.
What would settle it
Comparing the posterior inferences or predictive accuracy of the NNGP model against a full Gaussian process model on a simulated or small real dataset with known haplotype frequencies for four or more markers.
Figures

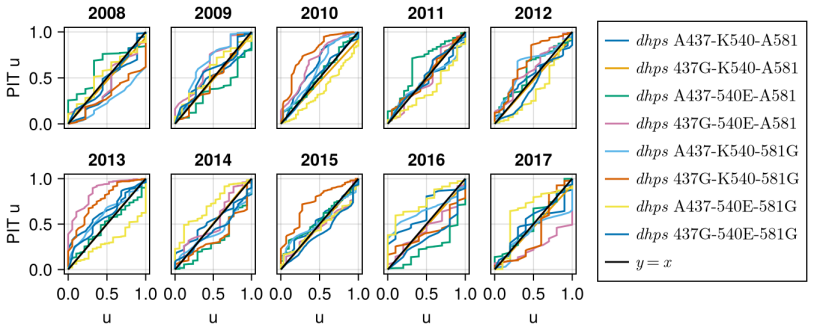
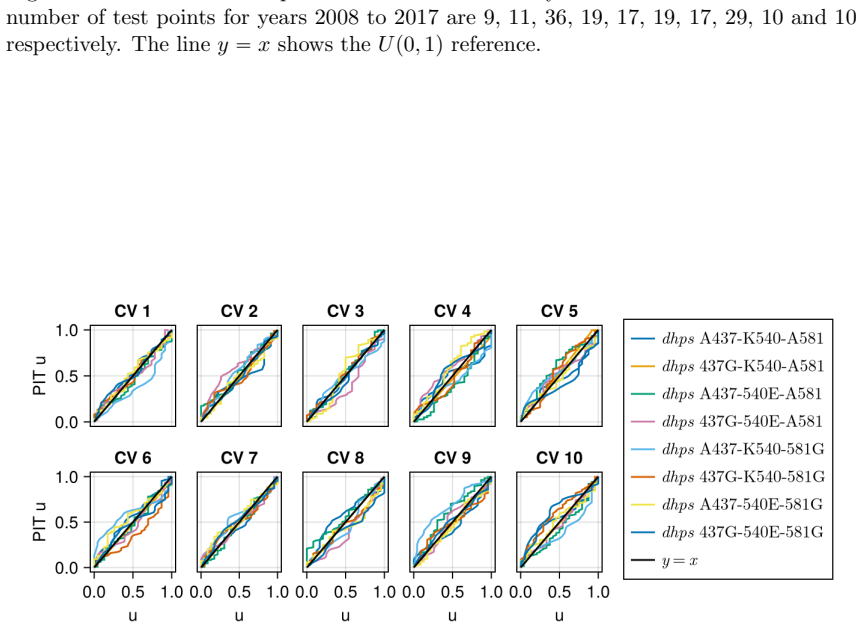
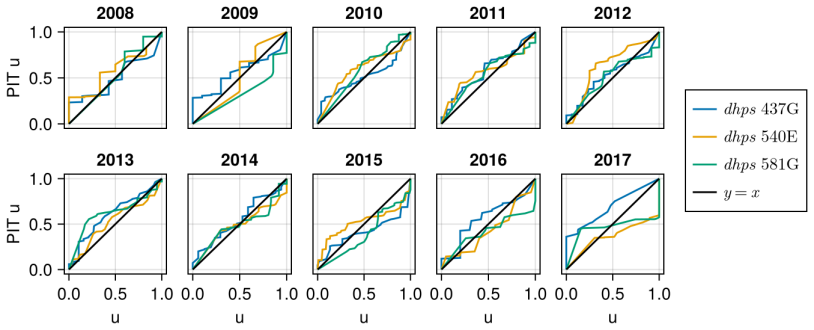
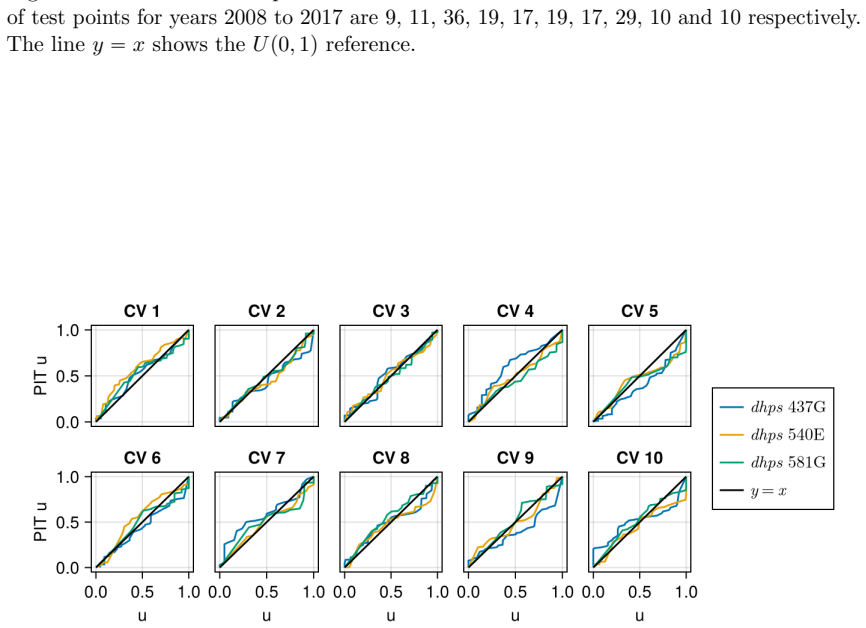

read the original abstract
Large scale genetic datasets often aggregate the total allele counts of distinct genetic markers. Inferring haplotype frequencies (i.e.\ the frequency of multimarker alleles) from these pooled data is a challenge. Previous spatio-temporal modelling in this context has been limited to 3 markers due to the computational cost. In this work, we propose a nearest neighbor Gaussian process (NNGP) model to improve scaling with the number of markers and observations. To infer the parameters of our model, we develop a novel sequential Monte Carlo squared algorithm, which uses particle Gibbs with ancestor sampling to mutate the NNGP function values. The latter has a linear cost in the number of observations and the number of NNGPs, and can be applied to a broad range of NNGP models. As a case study, we analyse genetic data relating to antimalarial drug resistance in Africa, and show our scaling results empirically on a 3 and 6 genetic marker dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a nearest-neighbor Gaussian process (NNGP) model for Bayesian spatio-temporal inference of haplotype frequencies from pooled allele-count genetic data. It develops a novel SMC² algorithm that employs particle Gibbs with ancestor sampling to update NNGP function values, claiming linear cost in the number of observations and the number of NNGPs. The approach is motivated by the computational barrier that previously restricted spatio-temporal models to three markers; a case study applies the method to African antimalarial-resistance data on three- and six-marker panels and reports empirical runtime scaling.
Significance. If the NNGP approximation remains faithful to the underlying spatio-temporal GP for the pooled-count likelihood and the SMC² procedure delivers the stated linear complexity, the work would remove a key computational obstacle and enable routine analysis of larger marker panels. The claimed generality of the SMC² sampler to other NNGP models is a potential methodological contribution.
major comments (3)
- [Abstract / case study] Abstract and case-study description: the claim that the NNGP model 'improves scaling with the number of markers' rests on the untested premise that the nearest-neighbor approximation remains sufficiently accurate for the spatio-temporal covariance structure when the number of markers grows from three to six. No quantitative diagnostic (KL divergence to a full GP, predictive coverage, or posterior comparison on the same data) is supplied for the six-marker panel.
- [Abstract] Abstract: the novel SMC² algorithm is asserted to have 'linear cost in the number of observations and the number of NNGPs,' yet the abstract supplies neither a complexity derivation, pseudocode, nor reference to a specific section containing the analysis that would allow verification of the linear-cost claim.
- [Case study] Case study: runtime results are presented for the six-marker dataset, but the manuscript does not report any direct check that the induced NNGP posterior haplotype frequencies remain consistent with those that would be obtained under the full spatio-temporal GP on the same pooled data.
minor comments (1)
- [Abstract] The abstract states that the SMC² procedure 'can be applied to a broad range of NNGP models,' but does not indicate which other NNGP constructions were tested or what conditions are required for the linear-cost property to hold.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We respond to each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / case study] Abstract and case-study description: the claim that the NNGP model 'improves scaling with the number of markers' rests on the untested premise that the nearest-neighbor approximation remains sufficiently accurate for the spatio-temporal covariance structure when the number of markers grows from three to six. No quantitative diagnostic (KL divergence to a full GP, predictive coverage, or posterior comparison on the same data) is supplied for the six-marker panel.
Authors: We agree that a quantitative diagnostic of the NNGP approximation for six markers would strengthen the paper. However, the full spatio-temporal GP is computationally intractable for six markers, which is the central motivation for the NNGP model. In the revision we will add a direct NNGP-versus-full-GP comparison on the three-marker dataset (where the full model remains feasible) together with a discussion of the NNGP approximation properties that justify its use for larger panels. revision: yes
-
Referee: [Abstract] Abstract: the novel SMC² algorithm is asserted to have 'linear cost in the number of observations and the number of NNGPs,' yet the abstract supplies neither a complexity derivation, pseudocode, nor reference to a specific section containing the analysis that would allow verification of the linear-cost claim.
Authors: The linear-complexity derivation and pseudocode for the SMC² algorithm appear in Section 3.2 and Algorithm 1 of the manuscript. We will revise the abstract to include an explicit reference to this section. revision: yes
-
Referee: [Case study] Case study: runtime results are presented for the six-marker dataset, but the manuscript does not report any direct check that the induced NNGP posterior haplotype frequencies remain consistent with those that would be obtained under the full spatio-temporal GP on the same pooled data.
Authors: A direct comparison with the full GP on the six-marker data is not feasible for the same computational reasons that motivate the NNGP. We will revise the case-study section to report the NNGP-versus-full-GP comparison on the three-marker data and to provide theoretical justification, based on the nearest-neighbor construction, for expecting consistency on the six-marker panel. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces an NNGP approximation and a novel SMC² algorithm (particle Gibbs with ancestor sampling) as new methodological contributions to scale spatio-temporal modeling of pooled haplotype data beyond 3 markers. The abstract and description present these as independent developments, with empirical scaling results shown on 3- and 6-marker datasets. No equations or steps are described that reduce a claimed prediction to a fitted input by construction, nor is there load-bearing self-citation of a uniqueness theorem or ansatz from prior author work. The central claims rest on the modeling and algorithmic innovations themselves rather than re-deriving inputs. This is the expected non-finding for a methods paper focused on computational scaling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An introduction to multivariate statistical analysis , author =
-
[2]
The Pseudo-Marginal Approach for Efficient
Andrieu, Christophe and Roberts, Gareth O , year =. The Pseudo-Marginal Approach for Efficient. The Annals of Statistics , volume =
-
[3]
Particle
Andrieu, Christophe and Doucet, Arnaud and Holenstein, Roman , year =. Particle. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =
-
[4]
Barratt, B. J. and Payne, F. and Rance, H. E. and Nutland, S. and Todd, J. A. and Clayton, D. G. , year =. Identification of the sources of error in allele frequency estimations from pooled. Annals of Human Genetics , volume =. doi:10.1017/S0003480002001252 , url =
-
[5]
and Jacob, P
Chopin, N. and Jacob, P. E. and Papaspiliopoulos, O. , year =. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =
-
[6]
, year =
Chopin, Nicolas and Singh, Sumeetpal S. , year =. On particle. Bernoulli , volume =
-
[7]
Corenflos, Adrien and Finke, Axel , year =. Particle-. doi:10.48550/ARXIV.2401.14868 , url =
-
[8]
Datta, Abhirup and Banerjee, Sudipto and Finley, Andrew O. and Gelfand, Alan E. , year =. Hierarchical. Journal of the American Statistical Association , shortjournal =. doi:10.1080/01621459.2015.1044091 , langid =
-
[9]
and Hamm, Nicholas A
Datta, Abhirup and Banerjee, Sudipto and Finley, Andrew O. and Hamm, Nicholas A. S. and Schaap, Martijn , year =. Nonseparable dynamic nearest neighbor. The Annals of Applied Statistics , shortjournal =
-
[10]
Sequential
Del Moral, Pierre and Doucet, Arnaud and Jasra, Ajay , year =. Sequential. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =
-
[11]
Density-Tempered Marginalized Sequential
Duan, Jin-Chuan and Fulop, Andras , year =. Density-Tempered Marginalized Sequential. Journal of Business & Economic Statistics , volume =
-
[12]
Efficient algorithms for Bayesian Nearest Neighbor Gaussian Processes
Finley, Andrew O. and Datta, Abhirup and Cook, Bruce C. and Morton, Douglas C. and Andersen, Hans E. and Banerjee, Sudipto , year =. Efficient Algorithms for. doi:10.48550/ARXIV.1702.00434 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1702.00434
-
[13]
Finke, Axel and Thiery, Alexandre H. , year =. Conditional sequential. The Annals of Statistics , shortjournal =. doi:10.1214/22-AOS2252 , url =
-
[14]
Haplotype Frequency Inference from Pooled Genetic Data with a Latent Multinomial Model , author =. 2023 , publisher =. doi:10.48550/ARXIV.2308.16465 , urldate =
-
[15]
A Spatio-Temporal Model of Multi-Marker Antimalarial Resistance , author =. 2024 , month = jan, journal =. doi:10.1098/rsif.2023.0570 , urldate =
-
[16]
Fast and Accurate Haplotype Frequency Estimation for Large Haplotype Vectors from Pooled
Iliadis, Alexandros and Anastassiou, Dimitris and Wang, Xiaodong , year =. Fast and Accurate Haplotype Frequency Estimation for Large Haplotype Vectors from Pooled. BMC Genetics , volume =. doi:10.1186/1471-2156-13-94 , urldate =
-
[17]
Ito, Toshikazu and Chiku, Suenori and Inoue, Eisuke and Tomita, Makoto and Morisaki, Takayuki and Morisaki, Hiroko and Kamatani, Naoyuki , year =. Estimation of. The American Journal of Human Genetics , volume =. doi:10.1086/346116 , urldate =
-
[18]
Kuk, Anthony Y. C. and Zhang, Han and Yang, Yaning , year =. Computationally Feasible Estimation of Haplotype Frequencies from Pooled. Bioinformatics , volume =. doi:10.1093/bioinformatics/btn623 , urldate =
-
[19]
Lindsten, Fredrik and Schön, Thomas B. , year =. Backward. Foundations and Trends in Machine Learning , shortjournal =. doi:10.1561/2200000045 , url =
-
[20]
Lindsten, Fredrik and Jordan, Michael I. and Sch. Particle. 2014 , journal =
2014
-
[21]
Link, William A. and Yoshizaki, Jun and Bailey, Larissa L. and Pollock, Kenneth H. , year =. Uncovering a. Biometrics , volume =. doi:10.1111/j.1541-0420.2009.01244.x , urldate =
-
[22]
Estimating Population Haplotype Frequencies from Pooled
Pirinen, Matti , year =. Estimating Population Haplotype Frequencies from Pooled. Bioinformatics , volume =. doi:10.1093/bioinformatics/btp584 , urldate =
-
[23]
Optimal Scaling of Discrete Approximations to Langevin Diffusions,
Roberts, Gareth O. and Rosenthal, Jeffrey S. , year =. Optimal. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. doi:10.1111/1467-9868.00123 , url =
-
[24]
and Craig, Ian and O'Donovan, Michael and Owen, Michael , year =
Sham, Pak and Bader, Joel S. and Craig, Ian and O'Donovan, Michael and Owen, Michael , year =. Nature Reviews Genetics , shortjournal =. doi:10.1038/nrg930 , url =
-
[25]
Benefits and Limitations of Genome-Wide Association Studies , author =. 2019 , month = aug, journal =. doi:10.1038/s41576-019-0127-1 , urldate =
-
[26]
Vecchia, A. V. , year =. Estimation and. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. doi:10.1111/j.2517-6161.1988.tb01729.x , urldate =
-
[27]
Discussion on particle
Whiteley, Nick , year =. Discussion on particle. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume =
-
[28]
, year = 2017, month = may, edition =
Wood, Simon N. , year = 2017, month = may, edition =. Generalized. doi:10.1201/9781315370279 , urldate =
-
[29]
Wright, Alan F , year =. Genetic. Encyclopedia of. doi:10.1038/npg.els.0005005 , urldate =
-
[30]
Comparing composite likelihood methods based on pairs for spatial
Bevilacqua, Moreno and Gaetan, Carlo , year = 2015, month = sep, journal =. Comparing composite likelihood methods based on pairs for spatial. doi:10.1007/s11222-014-9460-6 , urldate =
-
[31]
AStA Advances in Statistical Analysis , volume =
On composite marginal likelihoods , author =. AStA Advances in Statistical Analysis , volume =. doi:10.1007/s10182-008-0060-7 , urldate =
-
[32]
Statistica Sinica , volume =
An overview of composite likelihood methods , author =. Statistica Sinica , volume =
-
[33]
Compendium of molecular markers for antimalarial drug resistance , year =
-
[34]
Eisele, Thomas P and Larsen, David A and Anglewicz, Philip A and Keating, Joseph and Yukich, Josh and Bennett, Adam and Hutchinson, Paul and Steketee, Richard W , year = 2012, month = dec, journal =. Malaria Prevention in Pregnancy, Birthweight, and Neonatal Mortality: A Meta-Analysis of 32 National Cross-Sectional Datasets in. doi:10.1016/S1473-3099(12)7...
-
[35]
Van Eijk, Anna Maria and Larsen, David A and Kayentao, Kassoum and Koshy, Gibby and Slaughter, Douglas E C and Roper, Cally and Okell, Lucy C and Desai, Meghna and Gutman, Julie and Khairallah, Carole and Rogerson, Stephen J and Hopkins Sibley, Carol and Meshnick, Steven R and Taylor, Steve M and Ter Kuile, Feiko O , year = 2019, month = may, journal =. E...
-
[36]
2025 , howpublished =
2025
-
[37]
Czado, Claudia and Gneiting, Tilmann and Held, Leonhard , year = 2009, month = dec, journal =. Predictive. doi:10.1111/j.1541-0420.2009.01191.x , urldate =
-
[38]
and Turek, Daniel , publisher =
B. Approximate Leave-Future-out Cross-Validation for. Journal of Statistical Computation and Simulation , volume =. doi:10.1080/00949655.2020.1783262 , urldate =
-
[39]
Cross-validation Strategies for Data with Temporal, Spatial, Hierarchical, or Phylogenetic Structure , author =. Ecography , volume =. doi:10.1111/ecog.02881 , urldate =
-
[40]
Zhang, Hao , year = 2004, month = mar, journal =. Inconsistent. doi:10.1198/016214504000000241 , urldate =
-
[41]
Comparison of Resampling Schemes for Particle Filtering , booktitle =
Douc, Randal and Capp. Comparison of Resampling Schemes for Particle Filtering , booktitle =
-
[42]
Spatiotemporal Mathematical Modelling of Mutations of the Dhps Gene in
Flegg, Jennifer A and Patil, Anand P and Venkatesan, Meera and Roper, Cally and Naidoo, Inbarani and Hay, Simon I and Sibley, Carol Hopkins and Guerin, Philippe J , year = 2013, month = dec, journal =. Spatiotemporal Mathematical Modelling of Mutations of the Dhps Gene in. doi:10.1186/1475-2875-12-249 , urldate =
-
[43]
Flegg, Jennifer A. and Humphreys, Georgina S. and Montanez, Brenda and Strickland, Taryn and. Spatiotemporal Spread of. PLOS Computational Biology , volume =. doi:10.1371/journal.pcbi.1010317 , urldate =
-
[44]
and Kandanaarachchi, Sevvandi and Guerin, Philippe J
Flegg, Jennifer A. and Kandanaarachchi, Sevvandi and Guerin, Philippe J. and Dondorp, Arjen M. and Nosten, Francois H. and Otienoburu, Sabina Dahlstr. Spatio-Temporal Spread of Artemisinin Resistance in. PLOS Computational Biology , volume =. doi:10.1371/journal.pcbi.1012017 , urldate =
-
[45]
and Banerjee, Sudipto and Martin, Adam P
Davies, Tilman M. and Banerjee, Sudipto and Martin, Adam P. and Turnbull, Rose E. , year = 2022, journal =. A. doi:10.1111/rssc.12565 , urldate =
-
[46]
Spatial. Statistica Sinica , issn =. doi:10.5705/ss.202018.0005 , urldate =
-
[47]
Bayesian Inference and Learning in
Frigola, Roger and Lindsten, Fredrik and Sch. Bayesian Inference and Learning in. Advances in
-
[48]
, editor =
Neal, Radford M. , editor =. Handbook of
-
[49]
and Roberts, Gareth O
Beskos, Alexandros and Pillai, Natesh S. and Roberts, Gareth O. and. Optimal Tuning of the Hybrid. Bernoulli. Official Journal of the Bernoulli Society for Mathematical Statistics and Probability , volume =
-
[50]
Multivariate Nearest-Neighbors
Grenier, Isabelle and Sans. Multivariate Nearest-Neighbors. Environmetrics (London, Ont.) , volume =
-
[51]
Meeting Report of the
-
[52]
Computational Statistics & Data Analysis , volume =
Improving Performances of. Computational Statistics & Data Analysis , volume =
-
[53]
Kublin, James G. and Dzinjalamala, Fraction K. and Kamwendo, Deborah D. and Malkin, Elissa M. and Cortese, Joseph F. and Martino, Lisa M. and Mukadam, Rabia A. G. and Rogerson, Stephen J. and Lescano, Andres G. and Molyneux, Malcolm E. and Winstanley, Peter A. and Chimpeni, Phillips and Taylor, Terrie E. and Plowe, Christopher V. , year = 2002, month = fe...
-
[54]
Porcu, Emilio and Furrer, Reinhard and Nychka, Douglas , year = 2021, month = mar, journal =. 30. doi:10.1002/wics.1512 , urldate =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.