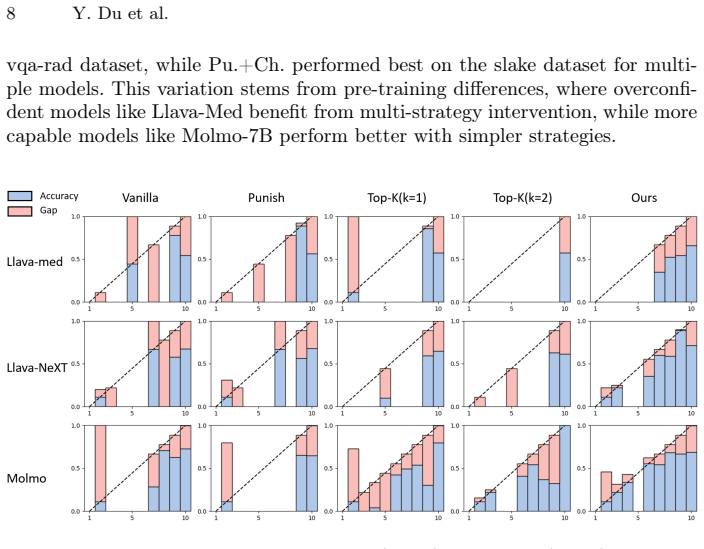
Confidence Calibration for Multimodal LLMs: An Empirical Study through Medical VQA
Pith reviewed 2026-06-26 17:47 UTC · model grok-4.3
The pith
A method pairing multi-strategy interrogation with auxiliary expert LLM review reduces expected calibration error by 40 percent on average in medical visual question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that Multi-Strategy Fusion-Based Interrogation combined with auxiliary expert LLM assessment produces better-calibrated confidence estimates in multimodal LLMs performing medical visual question answering, cutting average Expected Calibration Error by 40 percent across three datasets and thereby increasing reliability for AI-assisted diagnosis.
What carries the argument
Multi-Strategy Fusion-Based Interrogation (MS-FBI) with auxiliary expert LLM assessment, which generates varied question phrasings and uses the expert model to score the primary model's answers for improved confidence alignment.
If this is right
- Lower ECE produces confidence scores that more closely track actual correctness on medical VQA tasks.
- Domain-specific calibration steps become necessary for trustworthy use of MLLMs in healthcare settings.
- The combined MS-FBI and expert-assessment pipeline offers one concrete route to more reliable AI-assisted diagnosis.
Where Pith is reading between the lines
- The same interrogation-plus-expert-review pattern could be tested on non-medical multimodal tasks where confidence misalignment also occurs.
- If the auxiliary LLM itself shows calibration drift on certain question types, the overall gain might shrink or reverse in those cases.
- Future experiments could measure whether the method changes the rate at which models abstain from answering when uncertain.
Load-bearing premise
The auxiliary expert LLM is assumed to supply accurate and unbiased judgments of the primary model's outputs.
What would settle it
Running the same method on a fourth, previously unseen medical VQA dataset and finding no ECE reduction or an increase in error would falsify the reported improvement.
Figures

read the original abstract
Multimodal Large Language Models (MLLMs) show great potential in medical tasks, but their elicited confidence often misaligns with actual accuracy, potentially leading to misdiagnosis or overlooking correct advice. This study presents the first comprehensive analysis of the relationship between accuracy and confidence in medical MLLMs. It proposes a novel method that combines Multi-Strategy Fusion-Based Interrogation (MS-FBI) with auxiliary expert LLM assessment, aiming to improve confidence calibration in Medical Visual Question Answering (VQA). Experiments demonstrate that our method reduces the Expected Calibration Error (ECE) by an average of 40\% across three Medical VQA datasets, significantly enhancing MLLMs' reliability. The findings highlight the importance of domain-specific calibration for MLLMs in healthcare, offering a more trustworthy solution for AI-assisted diagnosis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on confidence calibration for Multimodal Large Language Models (MLLMs) applied to Medical Visual Question Answering (VQA). It claims to provide the first comprehensive analysis of the accuracy-confidence relationship in this domain and proposes a method combining Multi-Strategy Fusion-Based Interrogation (MS-FBI) with auxiliary expert LLM assessment, reporting an average 40% reduction in Expected Calibration Error (ECE) across three Medical VQA datasets.
Significance. If the ECE reductions are shown to be robust after validating all components, the work would address a practically important issue for trustworthy AI in healthcare, where miscalibrated confidence can lead to diagnostic errors. The domain-specific focus is relevant, but the empirical claims require strong controls to be impactful.
major comments (2)
- [§4 (Method, auxiliary LLM assessment)] §4 (Method, auxiliary LLM assessment): The central claim of a genuine 40% ECE reduction rests on treating the auxiliary expert LLM's output evaluations as reliable ground truth for adjusting the primary MLLM. No measurement of the auxiliary LLM's own calibration (e.g., its ECE) or validation against human experts/ground-truth labels is reported. This is load-bearing, as bias or miscalibration in the auxiliary would directly artifact the reported improvements.
- [Experiments section / abstract claim] Experiments section / abstract claim: The 40% average ECE reduction is presented without naming the three datasets, without reporting baseline methods or their ECE values, and without statistical significance tests or controls for confounds. This prevents assessment of whether the improvement is substantive or an artifact, directly undermining evaluation of the central empirical result.
minor comments (1)
- [Abstract] Abstract: The three Medical VQA datasets are not named, reducing the reader's ability to assess scope and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting key areas for strengthening our empirical claims. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: §4 (Method, auxiliary LLM assessment): The central claim of a genuine 40% ECE reduction rests on treating the auxiliary expert LLM's output evaluations as reliable ground truth for adjusting the primary MLLM. No measurement of the auxiliary LLM's own calibration (e.g., its ECE) or validation against human experts/ground-truth labels is reported. This is load-bearing, as bias or miscalibration in the auxiliary would directly artifact the reported improvements.
Authors: We agree this validation is essential and was not reported. In the revised manuscript we will add the auxiliary LLM's ECE computed on the same three datasets, along with direct comparisons of its assessments to ground-truth labels (where available in the VQA datasets) to quantify its reliability as an assessor. revision: yes
-
Referee: Experiments section / abstract claim: The 40% average ECE reduction is presented without naming the three datasets, without reporting baseline methods or their ECE values, and without statistical significance tests or controls for confounds. This prevents assessment of whether the improvement is substantive or an artifact, directly undermining evaluation of the central empirical result.
Authors: The full experiments section already specifies the three datasets, the baseline methods, and their ECE values. To improve clarity we will (1) name the datasets explicitly in the abstract and (2) add statistical significance tests plus explicit controls for confounds in the revised version. revision: yes
Circularity Check
No significant circularity; empirical study with independent experimental validation
full rationale
The paper presents an empirical study on confidence calibration for MLLMs in medical VQA. It proposes MS-FBI combined with auxiliary expert LLM assessment and reports measured ECE reductions (average 40%) across three datasets. No mathematical derivation chain exists, and no 'predictions' or first-principles results are claimed that reduce to inputs by construction. The auxiliary LLM serves as an external assessment tool whose outputs are used to adjust the primary model; this is a methodological choice whose validity is tested via downstream ECE metrics on held-out data, not a self-referential fit. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The work is self-contained against external benchmarks (standard ECE on public VQA datasets) and receives a normal non-finding score.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint (2022), https://arxiv.org/abs/2210.12265, arXiv:2210.12265
Ahuja, K., Sitaram, S., Dandapat, S., et al.: On the calibration of massively multi- lingual language models. arXiv preprint (2022), https://arxiv.org/abs/2210.12265, arXiv:2210.12265
arXiv 2022
-
[2]
arXiv preprint (2020), https://arxiv.org/abs/2002.07650, arXiv:2002.07650
Andrey, M., Mark, G.: Uncertainty estimation in autoregressive structured predic- tion. arXiv preprint (2020), https://arxiv.org/abs/2002.07650, arXiv:2002.07650
arXiv 2020
-
[3]
Pattern Recognition30(7), 1145–1159 (1997)
Bradley, A.P.: The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition30(7), 1145–1159 (1997)
1997
-
[4]
arXiv preprint (2024), https: //arxiv.org/abs/2409.17146, arXiv:2409.17146
Deitke, M., Clark, C., Lee, S., et al.: MOLMO and PIXMO: Open weights and open data for state-of-the-art multimodal models. arXiv preprint (2024), https: //arxiv.org/abs/2409.17146, arXiv:2409.17146
Pith/arXiv arXiv 2024
-
[5]
Geng,J.,Cai,F.,Wang,Y.,etal.:Asurveyofconfidenceestimationandcalibration inlargelanguagemodels.arXivpreprint(2023),https://arxiv.org/abs/2311.08298, arXiv:2311.08298
arXiv 2023
-
[6]
In: International Conference on Machine Learning
Guo, C., Pleiss, G., Sun, Y., et al.: On calibration of modern neural networks. In: International Conference on Machine Learning. pp. 1321–1330. PMLR (2017)
2017
-
[7]
In: Proceedings of CLEF Working Notes (2018)
Hasan, S.A., Ling, Y., Farri, O., et al.: Overview of ImageCLEF 2018 medical domain visual question answering task. In: Proceedings of CLEF Working Notes (2018)
2018
-
[8]
arXiv preprint (2022), https://arxiv.org/abs/2207.05221, arXiv:2207.05221
Kadavath, S., Conerly, T., Askell, A., et al.: Language models (mostly) know what they know. arXiv preprint (2022), https://arxiv.org/abs/2207.05221, arXiv:2207.05221
Pith/arXiv arXiv 2022
-
[9]
Scientific Data5(180251) (2018)
Lau, J., Gayen, S., Ben Abacha, A., et al.: A dataset of clinically generated visual questions and answers about radiology images. Scientific Data5(180251) (2018)
2018
-
[10]
In: Advances in Neural Information Processing Systems
Li, C., Wong, C., Zhang, S., et al.: LLaVA-Med: Training a large language-and- vision assistant for biomedicine in one day. In: Advances in Neural Information Processing Systems. vol. 36 (2024) 10 Y. Du et al
2024
-
[11]
In: IEEE 18th Interna- tional Symposium on Biomedical Imaging
Liu, B., Zhan, L.M., Xu, L., et al.: SLAKE: A semantically-labeled knowledge- enhanced dataset for medical visual question answering. In: IEEE 18th Interna- tional Symposium on Biomedical Imaging. pp. 1650–1654 (2021)
2021
-
[12]
arXiv preprint (2023), https: //arxiv.org/abs/2311.09731, arXiv:2311.09731
Liu, G., Wang, X., Yuan, L., et al.: Examining LLMs’ uncertainty expression towards questions outside parametric knowledge. arXiv preprint (2023), https: //arxiv.org/abs/2311.09731, arXiv:2311.09731
arXiv 2023
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, H., Li, C., Li, Y., et al.: Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26296–26306 (2024)
2024
-
[14]
Liu, H., Li, C., Li, Y., et al.: LLaVA-Next (2024), https://llava-vl.github.io/blog/ 2024-01-30-llava-next/
2024
-
[15]
arXiv preprint (2023), https://arxiv
Liu, Y., Yao, Y., Ton, J.F., et al.: Trustworthy llms: a survey and guideline for evaluating large language models’ alignment. arXiv preprint (2023), https://arxiv. org/abs/2308.05374, arXiv:2308.05374
Pith/arXiv arXiv 2023
-
[16]
Balkan Social Science Review17, 41–55 (2021)
Manea, T.: Lie detection during the interview and interrogation process: A psy- chosocial criminal approach. Balkan Social Science Review17, 41–55 (2021)
2021
-
[17]
arXiv preprint (2024), https://arxiv.org/abs/2402.11457, arXiv:2402.11457
Ni, S., Bi, K., Guo, J., et al.: When do LLMs need retrieval augmentation? Miti- gating LLMs’ overconfidence helps retrieval augmentation. arXiv preprint (2024), https://arxiv.org/abs/2402.11457, arXiv:2402.11457
arXiv 2024
-
[18]
arXiv preprint (2025), https: //arxiv.org/abs/2502.19634, arXiv:2502.19634
Pan, J., Liu, C., Wu, J., Liu, F., Zhu, J., Li, H.B., Chen, C., Cheng, O., Rueckert, D.: MedVLM-R1: Incentivizing medical reasoning capability of vision- language models (VLMs) via reinforcement learning. arXiv preprint (2025), https: //arxiv.org/abs/2502.19634, arXiv:2502.19634
arXiv 2025
-
[19]
In: International Conference on Learning Representations (2025), iCLR
Ren, Y., Sutherland, D.J.: Learning dynamics of llm finetuning. In: International Conference on Learning Representations (2025), iCLR
2025
-
[20]
medRxiv (2024)
Savage, T., Wang, J., Gallo, R., et al.: Large language model uncertainty measure- ment and calibration for medical diagnosis and treatment. medRxiv (2024)
2024
-
[21]
arXiv preprint (2022), https://arxiv.org/abs/2205.12507, arXiv:2205.12507
Si, C., Zhao, C., Min, S., et al.: Re-examining calibration: The case of question answering. arXiv preprint (2022), https://arxiv.org/abs/2205.12507, arXiv:2205.12507
arXiv 2022
-
[22]
Nature Machine Intelligence pp
Steyvers, M., Tejeda, H., Kumar, A., et al.: What large language models know and what people think they know. Nature Machine Intelligence pp. 1–11 (2025)
2025
-
[23]
arXiv preprint (2024), https://arxiv.org/abs/2404.17287, arXiv:2404.17287
Tao, S., Yao, L., Ding, H., et al.: When to trust llms: Aligning confidence with response quality. arXiv preprint (2024), https://arxiv.org/abs/2404.17287, arXiv:2404.17287
arXiv 2024
-
[24]
arXiv preprint (2023), https://arxiv.org/abs/2305.14975, arXiv:2305.14975
Tian, K., Mitchell, E., Zhou, A., et al.: Just ask for calibration: Strategies for elicit- ing calibrated confidence scores from language models fine-tuned with human feed- back. arXiv preprint (2023), https://arxiv.org/abs/2305.14975, arXiv:2305.14975
arXiv 2023
-
[25]
Diagnostics14, 1541 (2024)
Wada, A., Akashi, T., Shih, G., et al.: Optimizing GPT-4 turbo diagnostic ac- curacy in neuroradiology through prompt engineering and confidence thresholds. Diagnostics14, 1541 (2024)
2024
-
[26]
arXiv preprint (2024), https://arxiv.org/abs/2410.06707, arXiv:2410.06707
Wang, C., Szarvas, G., Balazs, G., et al.: Calibrating verbalized probabilities for large language models. arXiv preprint (2024), https://arxiv.org/abs/2410.06707, arXiv:2410.06707
arXiv 2024
-
[27]
arXiv preprint (2024), https://arxiv.org/abs/2407.18418, arXiv:2407.18418
Wen, B., Yao, J., Feng, S., et al.: Know your limits: A survey of abstention in large language models. arXiv preprint (2024), https://arxiv.org/abs/2407.18418, arXiv:2407.18418
arXiv 2024
-
[28]
arXiv preprint (2023), https://arxiv
Xiong, M., Hu, Z., Lu, X., et al.: Can LLMs express their uncertainty? An empirical evaluation of confidence elicitation in LLMs. arXiv preprint (2023), https://arxiv. org/abs/2306.13063, arXiv:2306.13063
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.