From Texts to Scores: Tracing the Emergence of Essay Quality Representations in Large Language Models
Pith reviewed 2026-06-26 17:15 UTC · model grok-4.3
The pith
LLMs encode essay quality as linearly readable signals that build across layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
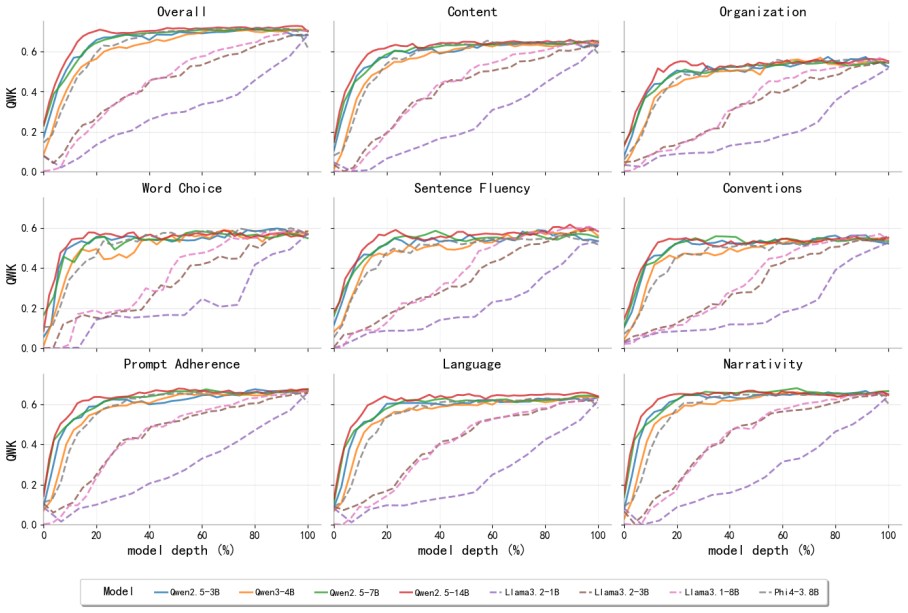
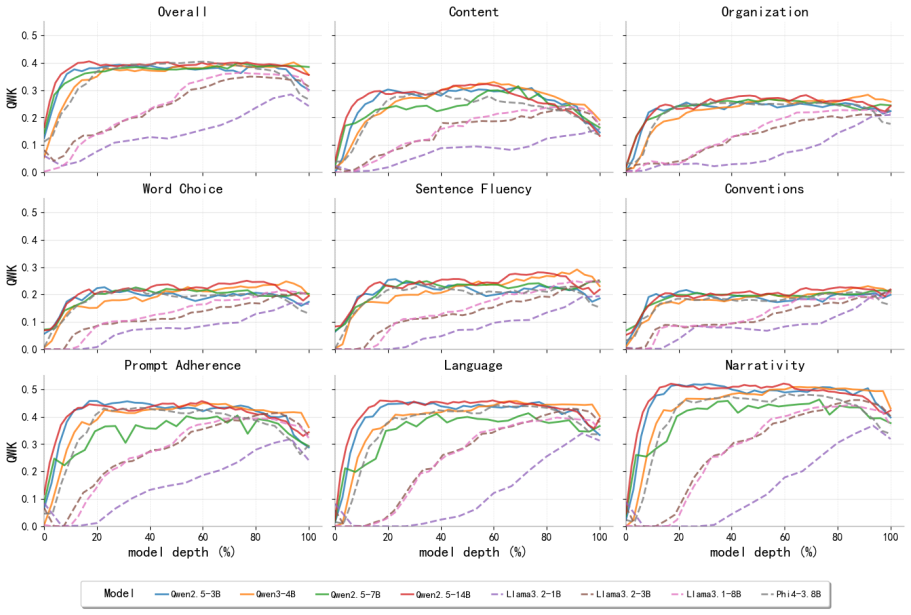
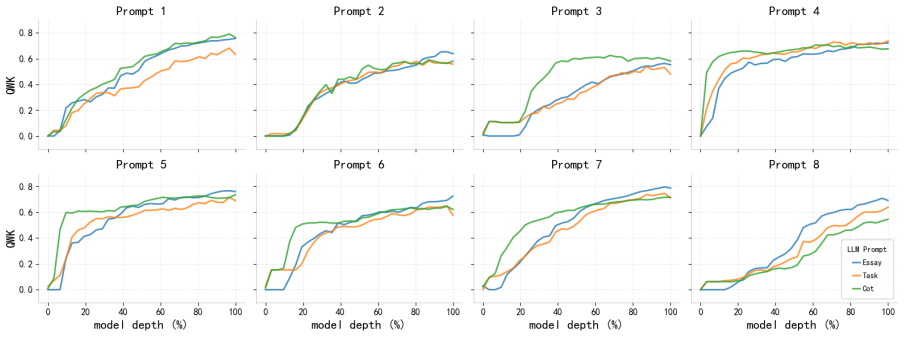
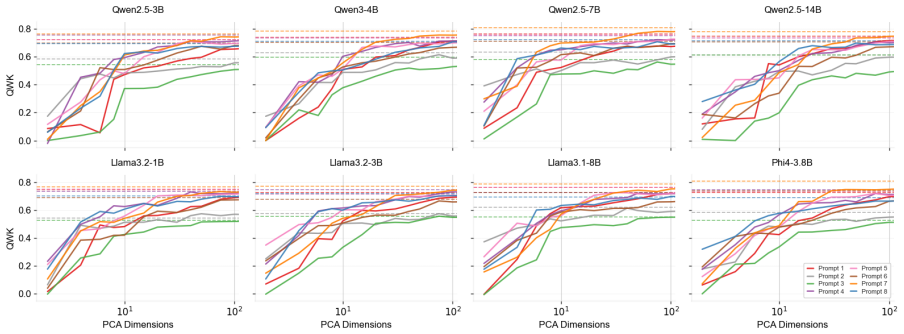
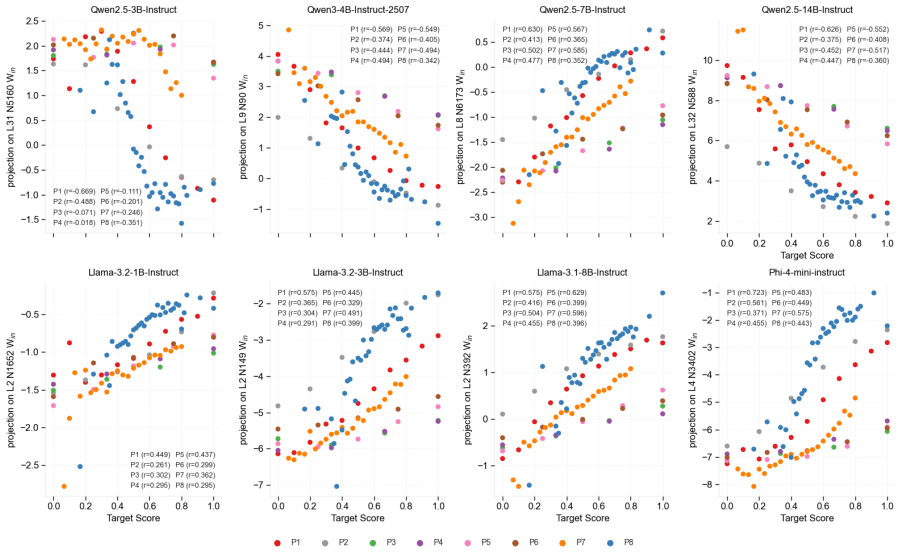
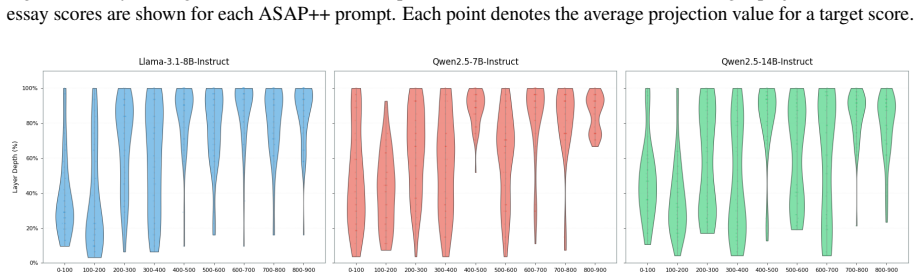
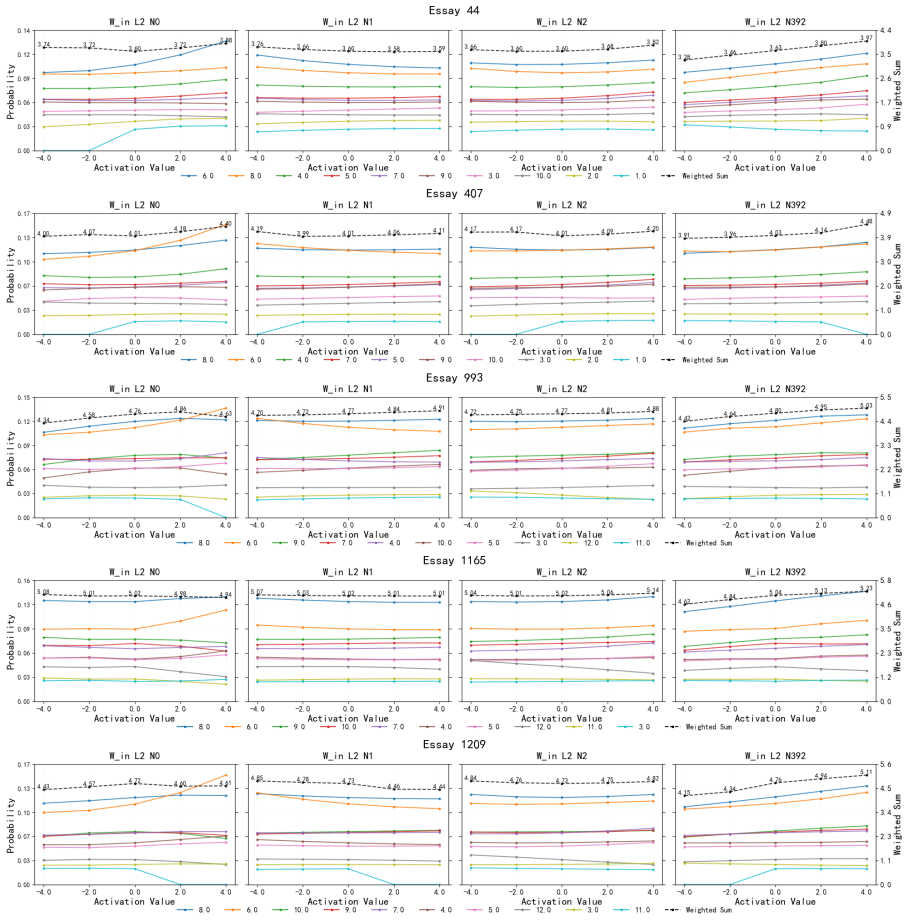
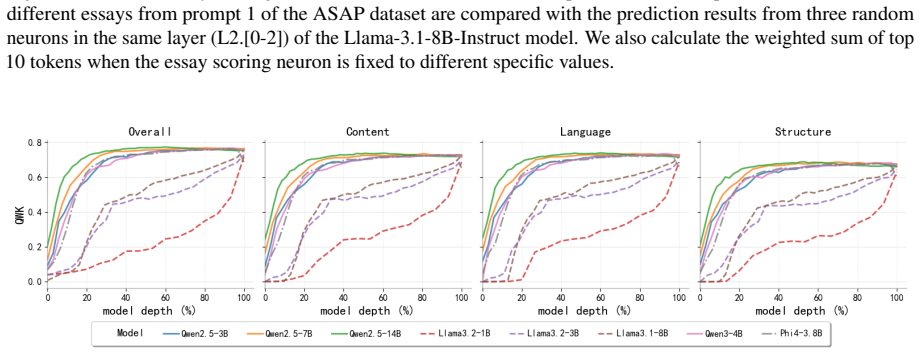
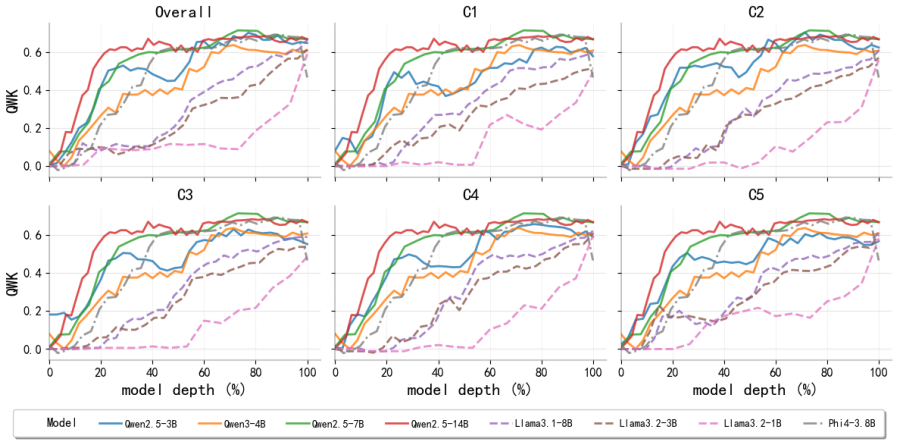
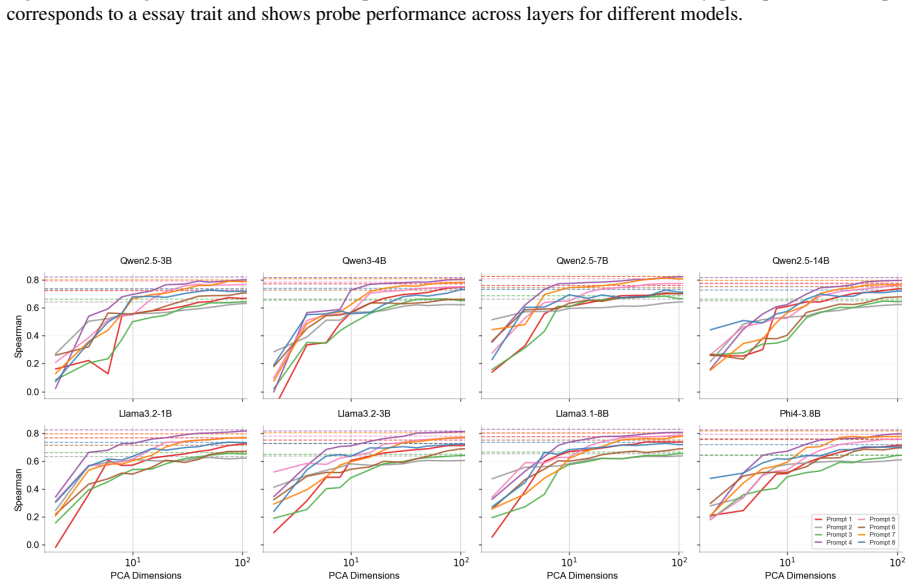
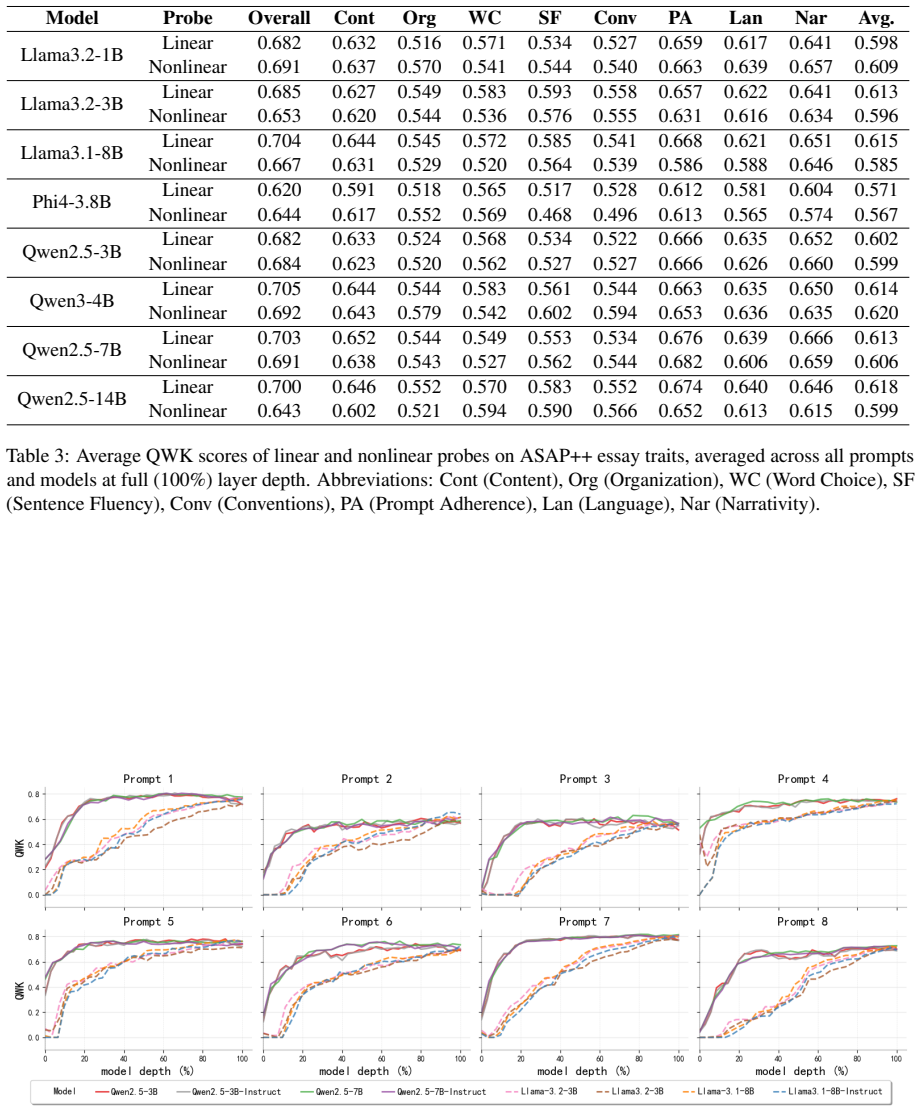
Essay quality information is encoded in a linearly accessible form within LLM representations. These representations emerge progressively across layers, remain robust across prompting strategies, and partially transfer across essay prompts despite differences in scoring rubrics. Nonlinear probes provide only marginal and inconsistent improvements over linear probes, suggesting that most essay quality information is already linearly decodable. Individual essay scoring neurons can be identified whose activations correlate with scores and respond to targeted intervention, and their layer-wise distribution shifts with essay length.
What carries the argument
Linear probes applied to hidden-state activations across LLM layers to decode essay quality scores.
If this is right
- Essay quality can be read from internal activations without requiring the model to generate a score in text.
- Quality signals remain detectable even when the input prompt or rubric changes.
- Targeted changes to identified scoring neurons can alter the model's effective scoring behavior.
- Longer essays depend more on deeper-layer representations for quality information.
Where Pith is reading between the lines
- The same linear structure might allow similar decoding for other subjective judgments such as code quality or argument strength.
- Intervening on the identified neurons could be used to steer automated scoring systems toward different criteria.
- The progressive layer emergence suggests that training methods emphasizing deeper-layer alignment could improve AES consistency.
Load-bearing premise
The essay datasets and their scoring rubrics produce a quality signal that reflects general essay quality rather than artifacts specific to those rubrics or prompt distributions.
What would settle it
Linear probes trained on one essay dataset would fail to predict scores above chance level when tested on a new dataset using entirely different rubrics and topics, or nonlinear probes would show large consistent gains over linear ones.
Figures


read the original abstract
Recent advances in Large Language Models (LLMs) have substantially transformed Automated Essay Scoring (AES), yet the internal mechanisms underlying LLM-based scoring remain poorly understood. In this work, we systematically analyze the hidden representations of eight LLMs across two English essay datasets (ASAP++, CSEE) and one Portuguese dataset (ENEM). Using linear probing, cross-prompt generalization, dimensionality reduction, and neuron-level analyses, we find consistent evidence that essay quality information is encoded in a linearly accessible form within LLM representations. These representations emerge progressively across layers, remain robust across prompting strategies, and partially transfer across essay prompts despite differences in scoring rubrics. In addition, nonlinear probes provide only marginal and inconsistent improvements over linear probes, suggesting that most essay quality information is already linearly decodable. We further identify individual ``essay scoring neurons'' whose activations strongly correlate with essay scores and whose behavior is sensitive to targeted intervention. Moreover, the layer-wise distribution of these neurons systematically shifts with essay length, with longer essays relying more heavily on deeper layers. Overall, our findings provide evidence that LLMs encode structured representations related to essay quality and offer new insights into the interpretability of LLM-based AES systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes hidden representations from eight LLMs on three essay datasets (ASAP++, CSEE, ENEM) via linear probing, cross-prompt generalization tests, dimensionality reduction, and neuron-level interventions. It claims that essay quality information is encoded in a linearly accessible form, emerges progressively across layers, remains robust across prompting strategies, shows partial transfer across prompts with differing rubrics, that nonlinear probes yield only marginal gains, and that specific 'essay scoring neurons' can be identified whose activations correlate with scores and shift in layer distribution with essay length.
Significance. If the central claims hold after addressing controls for surface features, the work would advance interpretability of LLM-based automated essay scoring by providing observational evidence for structured, linearly decodable quality representations that generalize partially across datasets. The multi-model, multi-dataset design and identification of progressive emergence and neuron interventions are strengths that could inform future mechanistic analyses in AES.
major comments (1)
- [cross-prompt generalization and neuron intervention results] The claim that representations encode essay quality in a linearly accessible form (rather than rubric-specific or surface correlates such as length or vocabulary) is load-bearing for the abstract's conclusions on emergence, robustness, and transfer. The reported layer-wise shifts with essay length and partial cross-prompt transfer are consistent with possible confounds, yet the manuscript does not appear to include an ablation that replaces human scores with matched-length or matched-vocabulary proxies while retaining the same representations and probes. Without this control, the linear decodability and neuron findings could track surface statistics rather than the intended quality construct.
minor comments (1)
- [Abstract] The abstract states consistent evidence across analyses but does not list the specific eight LLMs or their parameter scales; adding this detail would clarify the scope of generality.
Simulated Author's Rebuttal
We thank the referee for the careful review and the suggestion to strengthen controls against surface-feature confounds. We address the single major comment below and will incorporate the requested ablation.
read point-by-point responses
-
Referee: The claim that representations encode essay quality in a linearly accessible form (rather than rubric-specific or surface correlates such as length or vocabulary) is load-bearing for the abstract's conclusions on emergence, robustness, and transfer. The reported layer-wise shifts with essay length and partial cross-prompt transfer are consistent with possible confounds, yet the manuscript does not appear to include an ablation that replaces human scores with matched-length or matched-vocabulary proxies while retaining the same representations and probes. Without this control, the linear decodability and neuron findings could track surface statistics rather than the intended quality construct.
Authors: We agree that an explicit ablation replacing human scores with length- or vocabulary-matched proxies is a valuable control that is currently missing. Our existing cross-prompt and cross-dataset results (including transfer to the Portuguese ENEM corpus) already indicate that performance is not fully explained by prompt-specific surface statistics, and the neuron-intervention results show causal effects on predicted scores. Nevertheless, these do not directly isolate quality from length or lexical richness. In the revision we will add the requested ablation: we will train the same linear probes to predict (i) essay length and (ii) a vocabulary-richness proxy from the identical hidden representations, then compare layer-wise emergence curves, cross-prompt generalization, and the set of high-correlation “scoring neurons” against the human-score results. We will also report the raw correlations between human scores and these surface variables in each dataset to quantify the potential confound. revision: yes
Circularity Check
No circularity: purely empirical probing study with observational claims
full rationale
The paper reports results from linear and nonlinear probing, cross-prompt transfer tests, dimensionality reduction, and neuron interventions on LLM hidden states for essay scoring. No equations, derivations, or first-principles claims appear; all findings are direct measurements on fixed datasets (ASAP++, CSEE, ENEM). No fitted parameters are relabeled as predictions, no self-definitional loops, and no load-bearing self-citations or uniqueness theorems are invoked to force conclusions. The central claim (linear decodability of quality) is an empirical observation, not a reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes can extract meaningful semantic information from LLM hidden states
Reference graph
Works this paper leans on
-
[1]
Designing and Interpreting Probes with Control Tasks
Hewitt, John and Liang, Percy. Designing and Interpreting Probes with Control Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1275
-
[2]
2025 , eprint=
Activations as Features: Probing LLMs for Generalizable Essay Scoring Representations , author=. 2025 , eprint=
2025
-
[3]
Behaviormetrika , volume=
A review of deep-neural automated essay scoring models , author=. Behaviormetrika , volume=. 2021 , publisher=
2021
-
[4]
, author=
Automated Essay Scoring: A Survey of the State of the Art. , author=. IJCAI , volume=
-
[5]
Prompt- and Trait Relation-aware Cross-prompt Essay Trait Scoring
Do, Heejin and Kim, Yunsu and Lee, Gary Geunbae. Prompt- and Trait Relation-aware Cross-prompt Essay Trait Scoring. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.98
-
[6]
Expert Systems with Applications , volume=
Pairwise dual-level alignment for cross-prompt automated essay scoring , author=. Expert Systems with Applications , volume=. 2025 , publisher=
2025
-
[7]
International Journal of Educational Technology in Higher Education , volume=
AI-generated feedback on writing: Insights into efficacy and ENL student preference , author=. International Journal of Educational Technology in Higher Education , volume=. 2023 , publisher=
2023
-
[8]
arXiv , author=
Exploring LLM prompting strategies for joint essay scoring and feedback generation. arXiv , author=
-
[9]
Proceedings of the 1st Workshop on Customizable NLP: Progress and Challenges in Customizing NLP for a Domain, Application, Group, or Individual (CustomNLP4U) , pages=
LLM-as-a-tutor in EFL writing education: Focusing on evaluation of student-LLM interaction , author=. Proceedings of the 1st Workshop on Customizable NLP: Progress and Challenges in Customizing NLP for a Domain, Application, Group, or Individual (CustomNLP4U) , pages=
-
[10]
Proceedings of the 15th international learning analytics and knowledge conference , pages=
Human-ai collaborative essay scoring: A dual-process framework with llms , author=. Proceedings of the 15th international learning analytics and knowledge conference , pages=
-
[11]
Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018) , year=
ASAP++: Enriching the ASAP automated essay grading dataset with essay attribute scores , author=. Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018) , year=
2018
-
[12]
Proceedings of the 16th International Conference on Computational Processing of Portuguese-Vol
A new benchmark for automatic essay scoring in Portuguese , author=. Proceedings of the 16th International Conference on Computational Processing of Portuguese-Vol. 1 , pages=
-
[13]
Unleashing Large Language Models' Proficiency in Zero-shot Essay Scoring
Lee, Sanwoo and Cai, Yida and Meng, Desong and Wang, Ziyang and Wu, Yunfang. Unleashing Large Language Models' Proficiency in Zero-shot Essay Scoring. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.10
-
[14]
A Neural Approach to Automated Essay Scoring
Taghipour, Kaveh and Ng, Hwee Tou. A Neural Approach to Automated Essay Scoring. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1193
-
[15]
Automatic Text Scoring Using Neural Networks
Alikaniotis, Dimitrios and Yannakoudakis, Helen and Rei, Marek. Automatic Text Scoring Using Neural Networks. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1068
-
[16]
Dong, Fei and Zhang, Yue. Automatic Features for Essay Scoring -- An Empirical Study. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1115
-
[17]
Attention-based Recurrent Convolutional Neural Network for Automatic Essay Scoring
Dong, Fei and Zhang, Yue and Yang, Jie. Attention-based Recurrent Convolutional Neural Network for Automatic Essay Scoring. Proceedings of the 21st Conference on Computational Natural Language Learning ( C o NLL 2017). 2017. doi:10.18653/v1/K17-1017
-
[18]
2019 , eprint=
Language models and Automated Essay Scoring , author=. 2019 , eprint=
2019
-
[19]
Automated Essay Scoring via Pairwise Contrastive Regression
Xie, Jiayi and Cai, Kaiwei and Kong, Li and Zhou, Junsheng and Qu, Weiguang. Automated Essay Scoring via Pairwise Contrastive Regression. Proceedings of the 29th International Conference on Computational Linguistics. 2022
2022
-
[20]
Automated Essay Scoring with Discourse-Aware Neural Models
Nadeem, Farah and Nguyen, Huy and Liu, Yang and Ostendorf, Mari. Automated Essay Scoring with Discourse-Aware Neural Models. Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications. 2019. doi:10.18653/v1/W19-4450
-
[21]
Yang, Ruosong and Cao, Jiannong and Wen, Zhiyuan and Wu, Youzheng and He, Xiaodong. Enhancing Automated Essay Scoring Performance via Fine-tuning Pre-trained Language Models with Combination of Regression and Ranking. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.141
-
[22]
Neural Automated Essay Scoring Incorporating Handcrafted Features
Uto, Masaki and Xie, Yikuan and Ueno, Maomi. Neural Automated Essay Scoring Incorporating Handcrafted Features. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.535
-
[23]
Prompt agnostic essay scorer: a domain generalization approach to cross-prompt automated essay scoring. arXiv , author=. arXiv preprint arXiv:2008.01441 , year=
arXiv 2008
-
[24]
PMAES : Prompt-mapping Contrastive Learning for Cross-prompt Automated Essay Scoring
Chen, Yuan and Li, Xia. PMAES : Prompt-mapping Contrastive Learning for Cross-prompt Automated Essay Scoring. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.83
-
[25]
Expert Systems with Applications , pages=
Making meta-learning solve cross-prompt automatic essay scoring , author=. Expert Systems with Applications , pages=. 2025 , publisher=
2025
-
[26]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[27]
Research Methods in Applied Linguistics, 2 (2), 100050 , author=
Exploring the potential of using an AI language model for automated essay scoring. Research Methods in Applied Linguistics, 2 (2), 100050 , author=
-
[28]
Proceedings of the 18th workshop on innovative use of NLP for building educational applications (BEA 2023) , pages=
Rating short L2 essays on the CEFR scale with GPT-4 , author=. Proceedings of the 18th workshop on innovative use of NLP for building educational applications (BEA 2023) , pages=
2023
-
[29]
arXiv preprint arXiv:2505.08498 , year=
LCES: Zero-shot Automated Essay Scoring via Pairwise Comparisons Using Large Language Models , author=. arXiv preprint arXiv:2505.08498 , year=
-
[30]
2012 , howpublished =
Ben Hamner and Jaison Morgan and lynnvandev and Mark Shermis and Tom Vander Ark , title =. 2012 , howpublished =
2012
-
[31]
ETS Research Report Series , volume=
TOEFL11: A corpus of non-native English , author=. ETS Research Report Series , volume=. 2013 , publisher=
2013
-
[32]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[33]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[34]
Natural Language Engineering , volume=
Evaluation of text coherence for electronic essay scoring systems , author=. Natural Language Engineering , volume=. 2004 , publisher=
2004
-
[35]
The Journal of Technology, Learning and Assessment , volume=
Automated essay scoring using Bayes' theorem , author=. The Journal of Technology, Learning and Assessment , volume=
-
[36]
Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies , pages=
A new dataset and method for automatically grading ESOL texts , author=. Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies , pages=
-
[37]
Human-AI collaborative essay scoring: A dual-process framework with LLMs. arXiv. doi: 10.48550 , author=. arXiv preprint arXiv.2401.06431 , year=
-
[38]
arXiv preprint arXiv:2504.05736 , year=
Rank-then-score: Enhancing large language models for automated essay scoring , author=. arXiv preprint arXiv:2504.05736 , year=
-
[39]
Conundrums in Cross-Prompt Automated Essay Scoring: Making Sense of the State of the Art
Li, Shengjie and Ng, Vincent. Conundrums in Cross-Prompt Automated Essay Scoring: Making Sense of the State of the Art. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.414
-
[40]
arXiv preprint arXiv:2403.06149 , year=
Can large language models automatically score proficiency of written essays? , author=. arXiv preprint arXiv:2403.06149 , year=
-
[41]
Analyzing Encoded Concepts in Transformer Language Models
Sajjad, Hassan and Durrani, Nadir and Dalvi, Fahim and Alam, Firoj and Khan, Abdul and Xu, Jia. Analyzing Encoded Concepts in Transformer Language Models. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.225
-
[42]
Computational linguistics , volume=
Building a large annotated corpus of English: The Penn Treebank , author=. Computational linguistics , volume=
-
[43]
CoRR , volume =
Jacob Devlin and Ming. CoRR , volume =. 2018 , url =
2018
-
[44]
arXiv preprint arXiv:2408.13533 , year=
Pandora's Box or Aladdin's Lamp: A Comprehensive Analysis Revealing the Role of RAG Noise in Large Language Models , author=. arXiv preprint arXiv:2408.13533 , year=
-
[45]
Sennrich, Rico and Haddow, Barry and Birch, Alexandra. Neural Machine Translation of Rare Words with Subword Units. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1162
-
[46]
The imminence of grading essays by computer—25 years later , journal =. 1993 , issn =. doi:https://doi.org/10.1016/S8755-4615(05)80058-1 , url =
-
[47]
A Report on the First Native Language Identification Shared Task
Tetreault, Joel and Blanchard, Daniel and Cahill, Aoife. A Report on the First Native Language Identification Shared Task. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[48]
Educational and psychological measurement , volume=
A coefficient of agreement for nominal scales , author=. Educational and psychological measurement , volume=. 1960 , publisher=
1960
-
[49]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[50]
The Claude 3 Model Family: Technical Report
Anthropic. The Claude 3 Model Family: Technical Report. 2024
2024
-
[51]
The Development of Writing Proficiency as a Function of Grade Level: A Linguistic Analysis , volume =
Weston, Jennifer and Sullivan, Susan and McNamara, Danielle , year =. The Development of Writing Proficiency as a Function of Grade Level: A Linguistic Analysis , volume =. Written Communication , doi =
-
[52]
Journal of Writing Research , volume=
Linguistic features in writing quality and development: An overview , author=. Journal of Writing Research , volume=
-
[53]
Scientific reports , volume=
A large-scale comparison of human-written versus ChatGPT-generated essays , author=. Scientific reports , volume=. 2023 , publisher=
2023
-
[54]
arXiv preprint arXiv:2409.11547 , year=
Small language models can outperform humans in short creative writing: A study comparing slms with humans and llms , author=. arXiv preprint arXiv:2409.11547 , year=
-
[55]
2010 , edition=
The Cambridge Dictionary of Statistics , author=. 2010 , edition=
2010
-
[56]
A New Benchmark for Automatic Essay Scoring in P ortuguese
Silveira, Igor Cataneo and Barbosa, Andr \'e and Mau \'a , Denis Deratani. A New Benchmark for Automatic Essay Scoring in P ortuguese. Proceedings of the 16th International Conference on Computational Processing of Portuguese - Vol. 1. 2024
2024
-
[57]
arXiv preprint arXiv:2409.13120 , year=
Are large language models good essay graders? , author=. arXiv preprint arXiv:2409.13120 , year=
-
[58]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[59]
arXiv preprint arXiv:2305.01610 , year=
Finding neurons in a haystack: Case studies with sparse probing , author=. arXiv preprint arXiv:2305.01610 , year=
-
[60]
Discovering latent knowledge in language models without supervision, 2024 , author=
2024
-
[61]
arXiv preprint arXiv:2308.09124 , year=
Linearity of relation decoding in transformer language models , author=. arXiv preprint arXiv:2308.09124 , year=
-
[62]
arXiv preprint arXiv:2310.02207 , year=
Language models represent space and time , author=. arXiv preprint arXiv:2310.02207 , year=
-
[63]
2023 , eprint=
Toward Transparent AI: A Survey on Interpreting the Inner Structures of Deep Neural Networks , author=. 2023 , eprint=
2023
-
[64]
2020 , eprint=
A Primer in BERTology: What we know about how BERT works , author=. 2020 , eprint=
2020
-
[65]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=
-
[66]
2022 , eprint=
Toy Models of Superposition , author=. 2022 , eprint=
2022
-
[67]
Distill , volume=
Zoom in: An introduction to circuits , author=. Distill , volume=
-
[68]
Understanding intermediate layers using linear classifier probes, 2018 , author=. URL https://arxiv. org/abs/1610.01644 , volume=
Pith/arXiv arXiv 2018
-
[69]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
Probing the probing paradigm: Does probing accuracy entail task relevance? , author=. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
-
[70]
2009 , publisher=
The elements of statistical learning: data mining, inference, and prediction , author=. 2009 , publisher=
2009
-
[71]
Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
Linguistic regularities in continuous space word representations , author=. Proceedings of the 2013 conference of the north american chapter of the association for computational linguistics: Human language technologies , pages=
2013
-
[72]
Neuroscience & Biobehavioral Reviews , volume=
The ‘reading’brain: Meta-analytic insight into functional activation during reading in adults , author=. Neuroscience & Biobehavioral Reviews , volume=. 2025 , publisher=
2025
-
[73]
2019 , eprint=
BERT Rediscovers the Classical NLP Pipeline , author=. 2019 , eprint=
2019
-
[74]
Cognition , volume=
Linguistic complexity: Locality of syntactic dependencies , author=. Cognition , volume=. 1998 , publisher=
1998
-
[75]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[76]
2025 , eprint=
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs , author=. 2025 , eprint=
2025
-
[77]
2023 , eprint=
Textbooks Are All You Need , author=. 2023 , eprint=
2023
-
[78]
2024 , eprint=
TinyLlama: An Open-Source Small Language Model , author=. 2024 , eprint=
2024
-
[79]
Probing for semantic evidence of composition by means of simple classification tasks
Ettinger, Allyson and Elgohary, Ahmed and Resnik, Philip. Probing for semantic evidence of composition by means of simple classification tasks. Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP. 2016. doi:10.18653/v1/W16-2524
-
[80]
Analysis Methods in Neural Language Processing: A Survey
Belinkov, Yonatan and Glass, James. Analysis Methods in Neural Language Processing: A Survey. Transactions of the Association for Computational Linguistics. 2019. doi:10.1162/tacl_a_00254
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.