Evaluating and Enhancing Negation Comprehension in Remote Sensing MLLMs
Pith reviewed 2026-06-26 18:06 UTC · model grok-4.3
The pith
Remote sensing MLLMs struggle with negation in imagery and exhibit hallucinations, yet NeFo recovers much of the lost performance with about 5% unlabeled test samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
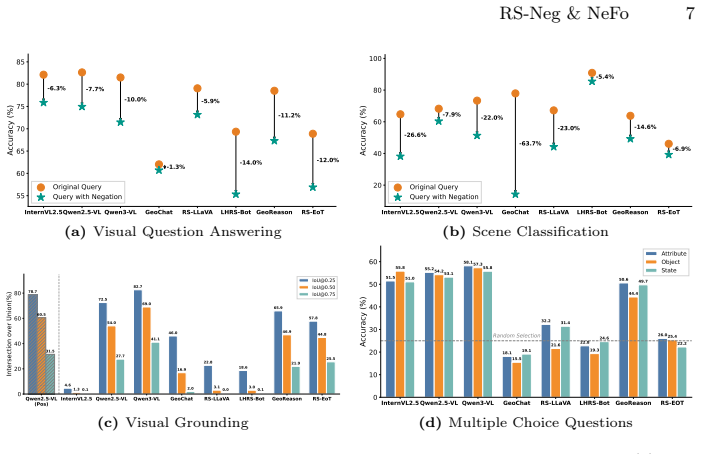
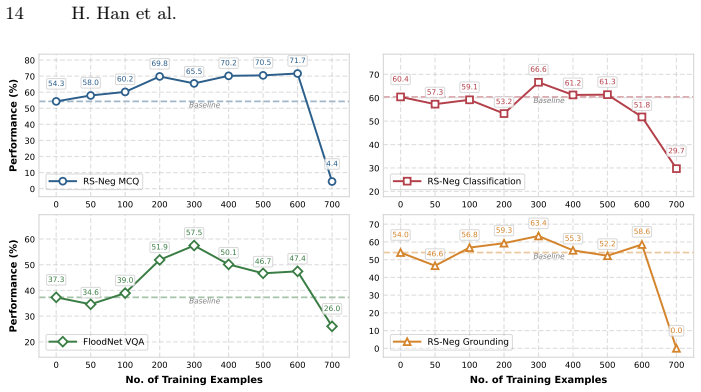
Advanced RS MLLMs struggle with negation, exhibiting hallucinations and substantial performance degradation. To close this gap, NeFo is proposed as a novel test-time learning method that explicitly incorporates the logical role of negation into the model optimization. Using about 5% unlabeled test samples, NeFo significantly improves the negation understanding of models and shows strong generalization to unseen tasks.
What carries the argument
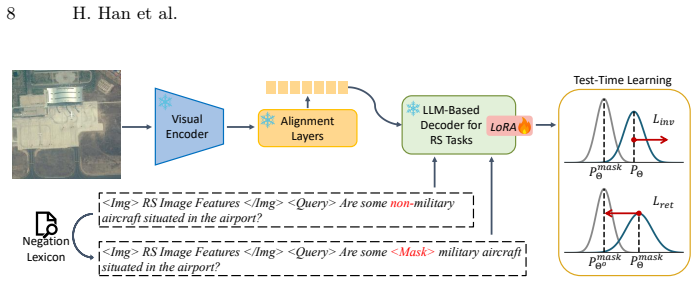
NeFo, a test-time learning method that incorporates the logical role of negation into model optimization to reduce hallucinations.
Load-bearing premise
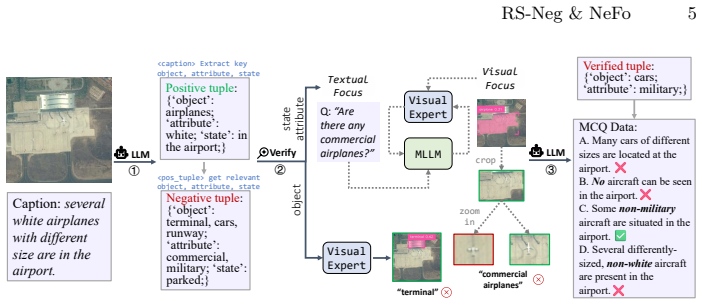
The automated pipeline that uses LLMs to synthesize negation queries, together with the dynamic visual focus module, produces queries that represent real negation comprehension needs in remote sensing imagery.
What would settle it
A human evaluation in which domain experts rate the realism of the generated RS-Neg queries or measure whether NeFo produces no gains on a manually authored negation test set.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) have demonstrated remarkable success in various Remote Sensing (RS) tasks. However, their ability to comprehend negation remains underexplored, limiting deployment in real-world applications where models must explicitly identify what is false or absent, e.g., emergency responders need to locate non-flooded routes for evacuation. To comprehensively study this limitation, we introduce RS-Neg, the first benchmark to evaluate negation understanding across region-level to scene-level tasks. Specifically, we design an automated data generation pipeline for RS imagery, using LLMs to synthesize diverse negation queries, and introduce a dynamic visual focus module for verification. Our evaluation reveals that advanced RS MLLMs struggle with negation, exhibiting hallucinations and substantial performance degradation. To close this gap, we propose NeFo, a novel test-time learning method that explicitly incorporates the logical role of negation into the model optimization. Remarkably, using about 5\% unlabeled test samples, NeFo significantly improves the negation understanding of models and shows strong generalization to unseen tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RS-Neg, the first benchmark for negation comprehension in remote sensing MLLMs spanning region- to scene-level tasks. It uses an automated LLM-based pipeline to synthesize negation queries paired with a dynamic visual focus module for verification, demonstrates that existing advanced RS MLLMs exhibit hallucinations and substantial performance drops on negation, and proposes NeFo, a test-time learning method that incorporates negation's logical role to improve understanding and generalize to unseen tasks using roughly 5% unlabeled test samples.
Significance. If the benchmark construction and NeFo gains prove robust, the work addresses a practically important gap in MLLM reliability for remote-sensing applications that require explicit reasoning about absence (e.g., evacuation routing). The automated synthesis approach and low-data test-time adaptation are efficient and potentially reusable; the empirical framing with a new benchmark constitutes a clear contribution.
major comments (2)
- [Benchmark construction] Benchmark construction section: the automated data-generation pipeline that relies on LLMs to synthesize negation queries and the dynamic visual focus module lack reported validation against human judgments or ground-truth RS imagery; without such checks the benchmark's representativeness remains unverified and is load-bearing for all downstream claims of model failure.
- [Evaluation] Evaluation section: the manuscript does not specify the exact metrics or protocols used to quantify hallucinations and performance degradation, nor does it report statistical significance or variance for the NeFo improvements; these omissions prevent assessment of whether the reported gains are reliable.
minor comments (1)
- [Abstract / Introduction] The abstract and introduction could more explicitly list the concrete tasks included in RS-Neg and the precise definition of "unseen tasks" used for the generalization experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments highlight important aspects of benchmark validation and evaluation rigor that we will address through targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the automated data-generation pipeline that relies on LLMs to synthesize negation queries and the dynamic visual focus module lack reported validation against human judgments or ground-truth RS imagery; without such checks the benchmark's representativeness remains unverified and is load-bearing for all downstream claims of model failure.
Authors: We agree that explicit validation of the automated pipeline is necessary to confirm representativeness. The dynamic visual focus module performs automated verification by cross-referencing synthesized queries against image content, but this is internal to the pipeline. In the revision we will add a new subsection reporting human evaluation results on a random sample of 200 generated queries (with inter-annotator agreement), comparing them to ground-truth RS imagery annotations where available. This will directly address the concern and support the downstream claims. revision: yes
-
Referee: [Evaluation] Evaluation section: the manuscript does not specify the exact metrics or protocols used to quantify hallucinations and performance degradation, nor does it report statistical significance or variance for the NeFo improvements; these omissions prevent assessment of whether the reported gains are reliable.
Authors: We acknowledge the omission. The current manuscript describes hallucination as incorrect affirmative responses to negation queries and performance degradation via accuracy drops, but does not detail the precise counting protocol or error taxonomy. In revision we will add an explicit subsection defining the metrics (including hallucination rate as the proportion of affirmative answers on negation queries), the evaluation protocol, and results with mean, standard deviation, and statistical significance tests (paired t-tests or Wilcoxon) across three random seeds for all NeFo experiments. This will allow readers to assess reliability of the reported gains. revision: yes
Circularity Check
No significant circularity; empirical benchmark and test-time method are self-contained
full rationale
The paper presents an empirical study: it constructs the RS-Neg benchmark via an LLM-based synthesis pipeline, evaluates existing RS MLLMs on negation tasks, and introduces NeFo as a test-time optimization technique that incorporates negation logic. No equations, fitted parameters, or derivations are described that reduce by construction to the inputs. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claims rest on direct performance measurements against the introduced benchmark and generalization tests, which are externally falsifiable and do not collapse into self-definition or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Alhamoud, K., Alshammari, S., Tian, Y., Li, G., Torr, P.H., Kim, Y., Ghassemi, M.: Vision-language models do not understand negation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29612–29622 (2025)
2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
Pith/arXiv arXiv 2025
-
[3]
Remote Sensing16(9), 1477 (2024)
Bazi, Y., Bashmal, L., Al Rahhal, M.M., Ricci, R., Melgani, F.: Rs-llava: A large vision-language model for joint captioning and question answering in remote sens- ing imagery. Remote Sensing16(9), 1477 (2024)
2024
-
[4]
arXiv preprint arXiv:2412.05271 (2024)
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
Pith/arXiv arXiv 2024
-
[5]
IEEE Transactions on Geo- science and Remote Sensing60, 1–19 (2022)
Cheng, Q., Huang, H., Xu, Y., Zhou, Y., Li, H., Wang, Z.: Nwpu-captions dataset and mlca-net for remote sensing image captioning. IEEE Transactions on Geo- science and Remote Sensing60, 1–19 (2022)
2022
-
[6]
Advances in neural information processing systems36, 49250–49267 (2023)
Dai, W., Li, J., Li, D., Tiong, A., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems36, 49250–49267 (2023)
2023
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Danish, M., Munir, M.A., Shah, S.R.A., Kuckreja, K., Khan, F.S., Fraccaro, P., Lacoste, A., Khan, S.: Geobench-vlm: Benchmarking vision-language models for geospatial tasks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7132–7142 (2025)
2025
-
[8]
Oxford University Press (2020)
Déprez, V., Déprez, V.M., Espinal, M.T., i Farré, M.T.E.: The Oxford handbook of negation. Oxford University Press (2020)
2020
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guo, X., Lao, J., Dang, B., Zhang, Y., Yu, L., Ru, L., Zhong, L., Huang, Z., Wu, K., Hu, D., et al.: Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 27672–27683 (2024)
2024
-
[10]
IEEE Transactions on Pattern Analysis and Machine In- telligence (2026)
Han, H., Wang, A.J., Liu, F., Zhu, J.: Negation-aware test-time adaptation for vision-language models. IEEE Transactions on Pattern Analysis and Machine In- telligence (2026)
2026
-
[11]
Journal of Pragmatics38(7), 1015–1032 (2006)
Hasson, U., Glucksberg, S.: Does understanding negation entail affirmation?: An examination of negated metaphors. Journal of Pragmatics38(7), 1015–1032 (2006)
2006
-
[12]
David Hume series, CSLI (2001),https: //books.google.com.sg/books?id=hBFtAAAAIAAJ
Horn, L.: A Natural History of Negation. David Hume series, CSLI (2001),https: //books.google.com.sg/books?id=hBFtAAAAIAAJ
2001
-
[13]
In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., Zhu, J
Hu, J., Zhang, Z., Chen, G., Wen, X., Shuai, C., Luo, W., Xiao, B., Li, Y., Tan, M.: Test-time learning for large language models. In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., Zhu, J. (eds.) 16 H. Han et al. Proceedings of the 42nd International Conference on Machine Learning. Proceed- ings of Machine L...
2025
-
[14]
In: International conference on machine learning
Jia, C., Yang, Y., Xia, Y., Chen, Y.T., Parekh, Z., Pham, H., Le, Q., Sung, Y.H., Li, Z., Duerig, T.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning. pp. 4904–4916. PMLR (2021)
2021
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kuckreja, K., Danish, M.S., Naseer, M., Das, A., Khan, S., Khan, F.S.: Geochat: Grounded large vision-language model for remote sensing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 27831– 27840 (2024)
2024
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, G., Xu, J., Zhao, Y., Peng, Y.: Dyfo: A training-free dynamic focus visual search for enhancing lmms in fine-grained visual understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9098–9108 (2025)
2025
-
[17]
In: IGARSS 2025-2025 IEEE International Geoscience and Remote Sensing Symposium
Li, Q., He, X., Shu, X., Yu, Y., Chen, D., Chen, Y., Yang, X.: A simple aerial detection baseline of multimodal language models. In: IGARSS 2025-2025 IEEE International Geoscience and Remote Sensing Symposium. pp. 6833–6837. IEEE (2025)
2025
-
[18]
Remote Sensing18(2), 222 (2026)
Li, Q., Ma, S., Luo, J., Yu, Y., Zhou, Y., Wang, F., Lu, X., Wang, X., He, X., Chen, Y., et al.: Co-training vision-language models for remote sensing multi-task learning. Remote Sensing18(2), 222 (2026)
2026
-
[19]
arXiv preprint arXiv:2601.04118 (2026)
Li, W., Xiang, X., Wen, Z., Zhou, G., Niu, B., Wang, F., Huang, L., Wang, Q., Hu, Y.: Georeason: Aligning thinking and answering in remote sensing vision- language models via logical consistency reinforcement learning. arXiv preprint arXiv:2601.04118 (2026)
arXiv 2026
-
[20]
Advances in Neural Information Processing Systems37, 3229–3242 (2024)
Li, X., Ding, J., Elhoseiny, M.: Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding. Advances in Neural Information Processing Systems37, 3229–3242 (2024)
2024
-
[21]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[22]
In: European conference on computer vision
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In: European conference on computer vision. pp. 38–55. Springer (2024)
2024
-
[23]
arXiv preprint arXiv:2403.05525 (2024)
Lu, H., Liu, W., Zhang, B., Wang, B., Dong, K., Liu, B., Sun, J., Ren, T., Li, Z., Yang, H., et al.: Deepseek-vl: towards real-world vision-language understanding. arXiv preprint arXiv:2403.05525 (2024)
Pith/arXiv arXiv 2024
-
[24]
IEEE Transactions on Geoscience and Remote Sensing 56(4), 2183–2195 (2017)
Lu, X., Wang, B., Zheng, X., Li, X.: Exploring models and data for remote sensing image caption generation. IEEE Transactions on Geoscience and Remote Sensing 56(4), 2183–2195 (2017)
2017
-
[25]
Ma, Z., Hong, J., Gul, M.O., Gandhi, M., Gao, I., Krishna, R.: Crepe: Can vision-language foundation models reason compositionally? In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10910– 10921 (2023)
2023
-
[26]
In: European Conference on Computer Vision
Muhtar, D., Li, Z., Gu, F., Zhang, X., Xiao, P.: Lhrs-bot: Empowering remote sens- ing with vgi-enhanced large multimodal language model. In: European Conference on Computer Vision. pp. 440–457. Springer (2024)
2024
-
[27]
In: European Conference on Computer Vision
Nedungadi, V., Kariryaa, A., Oehmcke, S., Belongie, S., Igel, C., Lang, N.: Mmearth: Exploring multi-modal pretext tasks for geospatial representation learn- ing. In: European Conference on Computer Vision. pp. 164–182. Springer (2024) RS-Neg & NeFo 17
2024
-
[28]
In: The Eleventh International Conference on Learning Representations (2023)
Niu, S., Wu, J., Zhang, Y., Wen, Z., Chen, Y., Zhao, P., Tan, M.: Towards sta- ble test-time adaptation in dynamic wild world. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[29]
arXiv preprint arXiv:2501.10913 (2025)
Park, J., Lee, J., Song, J., Yu, S., Jung, D., Yoon, S.: Know" no”better: A data-driven approach for enhancing negation awareness in clip. arXiv preprint arXiv:2501.10913 (2025)
arXiv 2025
-
[30]
In: 2016 International conference on computer, information and telecommunication systems (Cits)
Qu, B., Li, X., Tao, D., Lu, X.: Deep semantic understanding of high resolution remote sensing image. In: 2016 International conference on computer, information and telecommunication systems (Cits). pp. 1–5. IEEE (2016)
2016
-
[31]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
2021
-
[32]
IEEE Access9, 89644–89654 (2021)
Rahnemoonfar, M., Chowdhury, T., Sarkar, A., Varshney, D., Yari, M., Murphy, R.R.: Floodnet: A high resolution aerial imagery dataset for post flood scene un- derstanding. IEEE Access9, 89644–89654 (2021)
2021
-
[33]
arXiv preprint arXiv:2511.22396 (2025)
Shao, R., Li, Z., Zhang, Z., Xu, L., He, X., Yuan, H., He, B., Dai, Y., Yan, Y., Chen, Y., et al.: Asking like socrates: Socrates helps vlms understand remote sensing images. arXiv preprint arXiv:2511.22396 (2025)
Pith/arXiv arXiv 2025
-
[34]
Singh, J., Shrivastava, I., Vatsa, M., Singh, R., Bharati, A.: Learn" no" to say" yes" better: Improving vision-language models via negations. arXiv preprint arXiv:2403.20312 (2024)
arXiv 2024
-
[35]
arXiv preprint arXiv:2006.10726 (2020)
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: Tent: Fully test-time adaptation by entropy minimization. arXiv preprint arXiv:2006.10726 (2020)
Pith/arXiv arXiv 2006
-
[36]
arXiv preprint arXiv:2409.12191 (2024)
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
Pith/arXiv arXiv 2024
-
[37]
IEEE Transactions on Geoscience and Remote Sensing55(7), 3965–3981 (2017)
Xia, G.S., Hu, J., Hu, F., Shi, B., Bai, X., Zhong, Y., Zhang, L., Lu, X.: Aid: A benchmark data set for performance evaluation of aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing55(7), 3965–3981 (2017)
2017
-
[38]
In: Proceedings of the 18th SIGSPATIAL international conference on advances in geographic information systems
Yang, Y., Newsam, S.: Bag-of-visual-words and spatial extensions for land-use classification. In: Proceedings of the 18th SIGSPATIAL international conference on advances in geographic information systems. pp. 270–279 (2010)
2010
-
[39]
Yuksekgonul, M., Bianchi, F., Kalluri, P., Jurafsky, D., Zou, J.: When and why vision-language models behave like bags-of-words, and what to do about it? arXiv preprint arXiv:2210.01936 (2022)
arXiv 2022
-
[40]
Zhang, Y., Ye, M., Zhu, G., Liu, Y., Guo, P., Yan, J.: Ffca-yolo for small object detection in remote sensing images. IEEE Transactions on Geoscience and Remote Sensing62, 1–15 (2024).https://doi.org/10.1109/TGRS.2024.3363057
-
[41]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, Y., Ru, L., Wu, K., Yu, L., Liang, L., Li, Y., Chen, J.: Skysense v2: A unified foundation model for multi-modal remote sensing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9136–9146 (2025)
2025
-
[42]
Zhang, Y., Su, Y., Liu, Y., Yeung-Levy, S.: Negvqa: Can vision language models understand negation? arXiv preprint arXiv:2505.22946 (2025)
arXiv 2025
-
[43]
arXiv preprint arXiv:2501.19017 (2025)
Zhu, B., Qi, H., Gui, Y., Chen, J., Ngo, C.W., Lim, E.P.: Calling a spade a heart: Gaslighting multimodal large language models via negation. arXiv preprint arXiv:2501.19017 (2025)
arXiv 2025
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, Q., Lao, J., Ji, D., Luo, J., Wu, K., Zhang, Y., Ru, L., Wang, J., Chen, J., Yang, M., et al.: Skysense-o: Towards open-world remote sensing interpretation with vision-centric visual-language modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14733–14744 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.