Through the PRISM: Preference Representation in Intermediate States of Video Diffusion Models
Pith reviewed 2026-06-26 18:23 UTC · model grok-4.3
The pith
A frozen video diffusion backbone can decode user preferences directly from its noisy intermediate latents via a lightweight query head.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
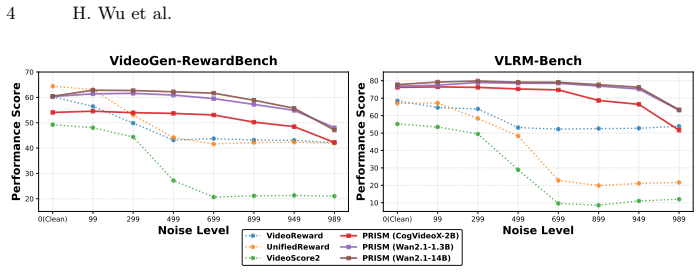
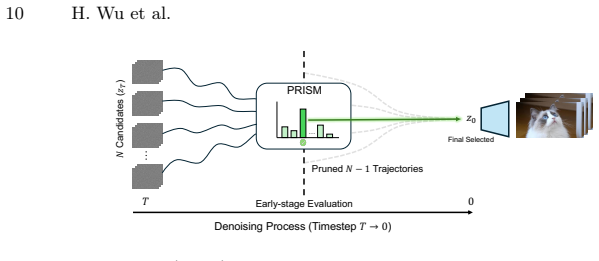
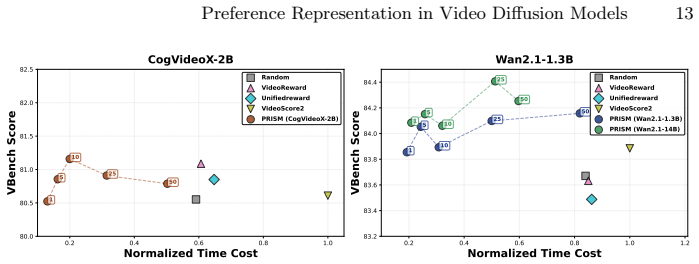
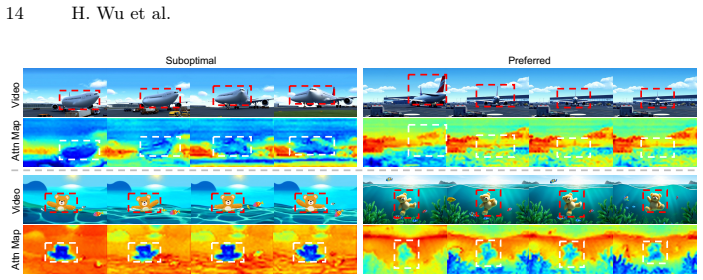
PRISM shows that preference signals are already linearly or query-decodable from the intermediate noisy latents of a frozen video diffusion backbone. A lightweight Query-based Aggregation head attached to this backbone extracts those signals with higher accuracy than prior clean-pixel reward models while remaining robust across noise levels, which in turn permits early-stage Best-of-N sampling that filters suboptimal candidates before most denoising steps occur. The paper further reports a positive correlation between a backbone's generative performance and its inherent preference discrimination power.
What carries the argument
The Query-based Aggregation head, a lightweight module that pools information across noisy latents to output preference scores without altering the frozen diffusion backbone.
If this is right
- Best-of-N sampling can begin at the first denoising step instead of after full generation, cutting total compute while raising output quality.
- Generative performance and evaluative power are positively correlated, so stronger backbones automatically become stronger judges.
- Reward modeling can reuse the same frozen weights used for generation rather than requiring separate clean-frame networks.
- Video alignment pipelines can operate entirely inside the diffusion process without VAE decoding at every evaluation step.
Where Pith is reading between the lines
- The same query-head approach might be tested on image or audio diffusion models to check whether the noise-robust preference signal is modality-specific or general.
- If the correlation between generation and evaluation holds, iterative self-improvement loops could alternate generation and preference filtering using only the backbone plus the head.
- Early rejection at high noise could be combined with existing consistency or distillation methods to further reduce sampling cost.
Load-bearing premise
Preference signals already exist in a decodable form inside the noisy latents of a pre-trained diffusion backbone and do not require any fine-tuning of that backbone.
What would settle it
Training the query head on latents from a deliberately weak video diffusion backbone and measuring whether preference accuracy falls to chance level or whether early Best-of-N sampling fails to improve final video quality.
Figures



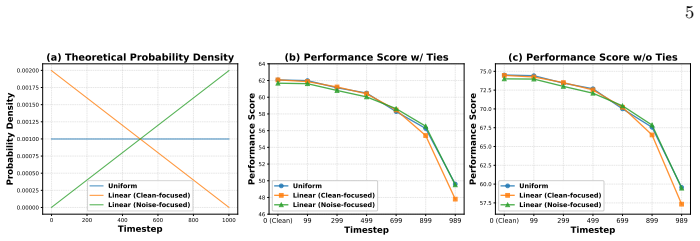

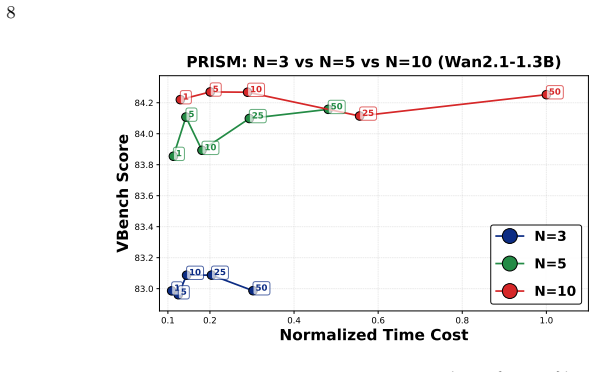
read the original abstract
Evaluating video generation with clean, pixel-based reward models disconnects evaluation from the noisy diffusion process and incurs massive VAE decoding costs. In this paper, we challenge this paradigm by asking a fundamental question: Can a powerful video generator inherently discriminate preferences directly from noisy latents? To answer this, we introduce \textbf{PRISM} (\textbf{P}reference \textbf{R}epresentation in \textbf{I}ntermediate \textbf{S}tates of Diffusion \textbf{M}odels). PRISM employs a lightweight Query-based Aggregation head with a frozen video diffusion backbone to decode preference signals from noisy latents. Surprisingly, PRISM not only achieves SOTA preference accuracy but also unlocks strong noise-robustness, which enables early-stage Best-of-$N$ sampling. This allows for filtering suboptimal candidates at the very beginning of denoising, drastically reducing computation while boosting video quality. We also reveal a strong positive correlation between a backbone's generative performance and its inherent evaluative power, enabling self-improving video backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, which attaches a lightweight Query-based Aggregation head to a frozen pre-trained video diffusion backbone to decode preference signals directly from noisy intermediate latents. It reports state-of-the-art preference accuracy, strong noise robustness that enables early-stage Best-of-N sampling (filtering before full denoising), and an empirical positive correlation between a backbone's generative quality and its inherent evaluative power.
Significance. If the reported results hold, the work is significant because it demonstrates that preference information is already linearly/query-decodable from the diffusion process itself, eliminating the need for separate clean-pixel reward models and costly VAE decoding. The noise-robust early filtering result offers a concrete route to lower compute in Best-of-N pipelines, while the generative-evaluative correlation is a falsifiable empirical observation that could support self-improving video models.
minor comments (3)
- [§3] §3 (method): the Query-based Aggregation head is described at a high level; an explicit equation or pseudocode showing how the learned query aggregates over the noisy latent features would improve reproducibility.
- [Table 2, Figure 4] Table 2 and Figure 4: the noise-robustness curves would benefit from error bars or multiple random seeds to confirm that the early-stage Best-of-N gains are statistically reliable across backbones.
- The abstract and §1 both use 'SOTA preference accuracy' without immediately citing the exact metric (e.g., accuracy@K or pairwise preference) and the primary competing reward models; this should be stated explicitly on first use.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation for minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity
full rationale
The paper's central construction is a new lightweight query-based head applied to a frozen pre-trained video diffusion backbone to extract preference signals from noisy latents. Claims of SOTA accuracy, noise robustness, early Best-of-N sampling, and generative-evaluative correlation are presented as empirical observations from experiments, not as mathematical derivations or predictions that reduce by construction to fitted parameters or self-citations. No load-bearing step equates a result to its own inputs via definition, renaming, or self-referential fitting. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2502.01051 , year=
Diffusion model as a noise-aware latent reward model for step-level preference optimization , author=. arXiv preprint arXiv:2502.01051 , year=
-
[2]
2025 , eprint=
VideoScore2: Think before You Score in Generative Video Evaluation , author=. 2025 , eprint=
2025
-
[3]
Unified Reward Model for Multimodal Understanding and Generation
Unified reward model for multimodal understanding and generation , author=. arXiv preprint arXiv:2503.05236 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Improving Video Generation with Human Feedback
Improving video generation with human feedback , author=. arXiv preprint arXiv:2501.13918 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. arXiv preprint arXiv:2408.06072 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Open-Sora: Democratizing Efficient Video Production for All
Open-sora: Democratizing efficient video production for all , author=. arXiv preprint arXiv:2412.20404 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Hunyuanvideo: A systematic framework for large video generative models , author=. arXiv preprint arXiv:2412.03603 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
2025 , eprint=
SkyReels-V2: Infinite-length Film Generative Model , author=. 2025 , eprint=
2025
-
[10]
P. V. Rao and L. L. Kupper , journal =. Ties in Paired-Comparison Experiments: A Generalization of the Bradley-Terry Model , urldate =
-
[11]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[12]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[13]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[14]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[15]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[16]
2022 , journal=
Scalable Diffusion Models with Transformers , author=. 2022 , journal=
2022
-
[17]
ArXiv , year =
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation , author =. ArXiv , year =
-
[18]
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and Wang, Yaohui and Chen, Xinyuan and Wang, Limin and Lin, Dahua and Qiao, Yu and Liu, Ziwei , booktitle=
-
[19]
NeurIPS , year=
UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models , author=. NeurIPS , year=
-
[20]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Transactions on Machine Learning Research , year=
MANTIS: Interleaved Multi-Image Instruction Tuning , author=. Transactions on Machine Learning Research , year=
-
[23]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
LLaVA-OneVision: Easy Visual Task Transfer
LLaVA-OneVision: Easy Visual Task Transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2501.19252 , year =
Inference-Time Text-to-Video Alignment with Diffusion Latent Beam Search , author =. arXiv preprint arXiv:2501.19252 , year =
-
[26]
2025 , booktitle=
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think , author=. 2025 , booktitle=
2025
-
[27]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Seedance 1.0: Exploring the boundaries of video generation models , author=. arXiv preprint arXiv:2506.09113 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Transactions on Machine Learning Research , year=
Latte: Latent Diffusion Transformer for Video Generation , author=. Transactions on Machine Learning Research , year=
-
[29]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable video diffusion: Scaling latent video diffusion models to large datasets , author=. arXiv preprint arXiv:2311.15127 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
arXiv preprint arXiv:2503.18942 , year=
Video-T1: Test-Time Scaling for Video Generation , author=. arXiv preprint arXiv:2503.18942 , year=
-
[31]
Proceedings of the 37th International Conference on Neural Information Processing Systems , pages=
ImageReward: learning and evaluating human preferences for text-to-image generation , author=. Proceedings of the 37th International Conference on Neural Information Processing Systems , pages=
-
[32]
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis , author=. arXiv preprint arXiv:2306.09341 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Inference-time scaling for diffusion models beyond scaling denoising steps , author=. arXiv preprint arXiv:2501.09732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [34]
-
[35]
The Eleventh International Conference on Learning Representations , year=
UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining , author=. The Eleventh International Conference on Learning Representations , year=
-
[36]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. Journal of Machine Learning Research , year =
-
[37]
arXiv preprint , year=
Video Generation Models are Good Latent Reward Models , author=. arXiv preprint , year=
-
[38]
arXiv preprint arXiv:2406.03035 , year=
Towards multiple character image animation through enhancing implicit decoupling , author=. arXiv preprint arXiv:2406.03035 , year=
-
[39]
2025 , eprint=
A General Framework for Inference-time Scaling and Steering of Diffusion Models , author=. 2025 , eprint=
2025
-
[40]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[41]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2503.01103 , year=
Direct Discriminative Optimization: Your Likelihood-Based Visual Generative Model is Secretly a GAN Discriminator , author=. arXiv preprint arXiv:2503.01103 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.