AutoPass: Evidence-Guided LLM Agents for Compiler Performance Tuning
Pith reviewed 2026-06-26 16:08 UTC · model grok-4.3
The pith
AutoPass guides LLM agents with compiler evidence and runtime feedback to tune optimizations, outperforming -O3 by geometric means of 1.043x on x86-64 and 1.117x on ARM64.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
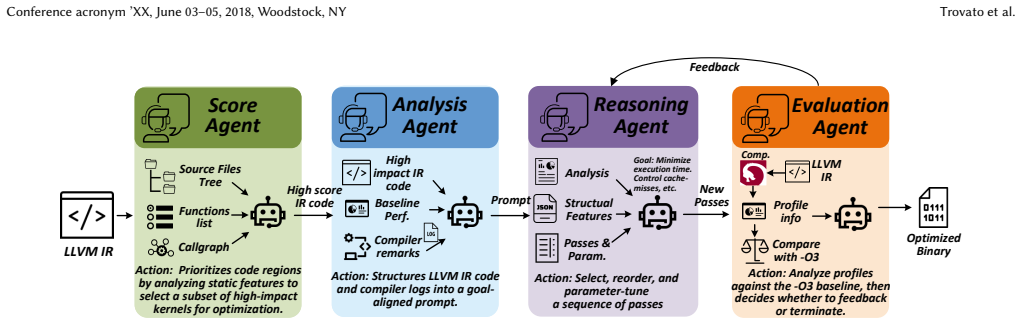
AutoPass is a multi-agent framework for compiler performance tuning that uses evidence from compiler-internal optimization states and runtime feedback to guide LLM-generated decisions, allowing iterative refinement of optimization configurations in an inference-only setting without training or fine-tuning.
What carries the argument
The multi-agent orchestration that queries compiler optimization states, analyzes intermediate representation, and incorporates runtime measurements to orchestrate and refine compiler options.
If this is right
- It outperforms expert-tuned heuristics and classical autotuning methods.
- It achieves geometric-mean speedups of 1.043x over LLVM -O3 on x86-64.
- It achieves geometric-mean speedups of 1.117x over LLVM -O3 on ARM64.
- It can be applied to new benchmarks and platforms without offline training.
- It operates in an inference-only setting requiring no task-specific fine-tuning.
Where Pith is reading between the lines
- If the evidence mechanism works, similar agents could be applied to other compilers beyond LLVM.
- The approach suggests that exposing more internal compiler data could improve LLM performance on systems tasks.
- Testable extension: evaluate on additional architectures like RISC-V to see if speedups generalize.
- Potential connection to broader use of LLMs in software engineering for automated optimization.
Load-bearing premise
Noisy runtime measurements combined with compiler-internal state queries are sufficient for the LLM agents to reliably diagnose regressions and produce latency-improving edits.
What would settle it
A set of benchmarks where AutoPass produces configurations that result in slower execution than -O3 after the iterative refinement process.
Figures




read the original abstract
Large Language Models (LLMs) show promise for code compilation tasks, but applying them to runtime performance tuning is difficult due to complex microarchitectural effects and noisy runtime measurements. We present AutoPass, a multi-agent framework for compiler performance tuning that uses compiler and runtime evidence to guide LLM-generated optimization decisions. Rather than treating the compiler as a black box like prior auto-tuning schemes, AutoPass opens up the compiler to the LLM, enabling it to query compiler-internal optimization states and analyze the intermediate representation to orchestrate compiler options. The search process iteratively refines optimization configurations using measured runtime feedback to diagnose regressions and guide latency-improving edits. AutoPass operates in an inference-only, training-free setting and requires no offline training or task-specific fine-tuning, making it readily applicable to new benchmarks and platforms. We implement AutoPass on the LLVM compiler and evaluate it on server-grade x86-64 and embedded ARM64 systems. AutoPass outperforms expert-tuned heuristics and classical autotuning methods, achieving geometric-mean speedups of 1.043x and 1.117x over LLVM -O3 on x86-64 and ARM64, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AutoPass, a multi-agent LLM framework for compiler performance tuning that opens the LLVM compiler to allow agents to query internal optimization states and IR, then iteratively refines configurations using runtime feedback to diagnose regressions. It operates in a training-free, inference-only mode and reports geometric-mean speedups of 1.043x (x86-64) and 1.117x (ARM64) over LLVM -O3, outperforming expert heuristics and classical autotuning.
Significance. If the empirical results prove robust, the work would be significant for demonstrating a practical, training-free method to apply LLMs to performance tuning by leveraging compiler evidence rather than treating the compiler as a black box; this addresses a key challenge in systems autotuning where microarchitectural effects and measurement noise complicate search.
major comments (2)
- [Evaluation / Abstract] Evaluation section (implied by abstract claims): the reported geometric-mean speedups lack any description of benchmark count, number of timing repetitions, statistical handling of noise, or variance across runs, which is load-bearing for validating the central performance claims.
- [Methodology / Abstract] Core mechanism description: the assumption that runtime feedback plus compiler-internal queries suffice to reliably diagnose regressions and produce latency-improving edits is stated but not supported by any protocol details, measurement methodology, or ablation on noise sensitivity, undermining verification of the approach.
minor comments (2)
- The abstract and any early sections should explicitly list the specific benchmarks and platforms used to allow readers to assess generalizability.
- Notation for the multi-agent roles and evidence types (compiler state vs. runtime) could be clarified with a diagram or table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on evaluation clarity and methodological detail. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Evaluation / Abstract] Evaluation section (implied by abstract claims): the reported geometric-mean speedups lack any description of benchmark count, number of timing repetitions, statistical handling of noise, or variance across runs, which is load-bearing for validating the central performance claims.
Authors: We agree that the abstract and evaluation presentation would benefit from more explicit detail on these points to support the reported speedups. The manuscript describes the benchmark suites and platforms in the evaluation section, but we will add a dedicated subsection on experimental methodology that specifies the exact benchmark count, number of timing repetitions per configuration, use of geometric mean, and how variance and noise are handled (e.g., via repeated measurements and statistical reporting). This will be incorporated in the revised version. revision: yes
-
Referee: [Methodology / Abstract] Core mechanism description: the assumption that runtime feedback plus compiler-internal queries suffice to reliably diagnose regressions and produce latency-improving edits is stated but not supported by any protocol details, measurement methodology, or ablation on noise sensitivity, undermining verification of the approach.
Authors: We acknowledge that additional protocol details would improve verifiability. We will expand the methodology section with explicit descriptions of the iterative refinement protocol, how runtime feedback is collected and used to diagnose regressions, the measurement methodology for latency, and an ablation study examining sensitivity to measurement noise. These additions will directly address the concern about supporting evidence for the core mechanism. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or fitted predictions
full rationale
The paper presents an empirical systems contribution: an LLM-agent framework evaluated via runtime measurements on x86-64 and ARM64 platforms, reporting geometric-mean speedups over LLVM -O3. No equations, parameters fitted to subsets of data, or first-principles derivations are described that could reduce the reported outcomes to inputs by construction. The central claims rest on concrete benchmark runs rather than any self-referential definition, uniqueness theorem, or ansatz smuggled via citation. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Opentuner: An extensible framework for program autotuning
Jason Ansel, Shoaib Kamil, Kalyan Veeramachaneni, Jonathan Ragan-Kelley, Jeffrey Bosboom, Una-May O’Reilly, and Saman Amarasinghe. Opentuner: An extensible framework for program autotuning. InProceedings of the 23rd international conference on Parallel architectures and compilation, pages 303–316, 2014
2014
-
[2]
Jordi Armengol-Estapé, Jackson Woodruff, Chris Cummins, and Michael F.P. O’Boyle. Slade: A portable small language model decompiler for optimized assembly. In2024 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 67–80, 2024
2024
-
[3]
Ashouri, William Killian, John Cavazos, Gianluca Palermo, and Cristina Silvano
Amir H. Ashouri, William Killian, John Cavazos, Gianluca Palermo, and Cristina Silvano. A survey on compiler autotuning using machine learning.ACM Computing Surveys, 51(5):96:1–96:42, 2018
2018
-
[4]
Acpo: Ai-enabled compiler-driven program optimization.arXiv preprint arXiv:2312.09982, 2023
Amir H Ashouri, Muhammad Asif Manzoor, Duc Minh Vu, Raymond Zhang, Ziwen Wang, Angel Zhang, Bryan Chan, Tomasz S Czajkowski, and Yaoqing Gao. Acpo: Ai-enabled compiler-driven program optimization.arXiv preprint arXiv:2312.09982, 2023
arXiv 2023
-
[5]
Compiler transformations for high-performance computing.ACM Computing Surveys (CSUR), 26(4):345–420, 1994
David F Bacon, Susan L Graham, and Oliver J Sharp. Compiler transformations for high-performance computing.ACM Computing Surveys (CSUR), 26(4):345–420, 1994
1994
-
[6]
Repairagent: An autonomous, llm-based agent for program repair
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. Repairagent: An autonomous, llm-based agent for program repair. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pages 2188–2200. IEEE, 2025
2025
-
[7]
A col- laborative filtering approach for the automatic tuning of compiler optimisations
Stefano Cereda, Gianluca Palermo, Paolo Cremonesi, and Stefano Doni. A col- laborative filtering approach for the automatic tuning of compiler optimisations. In The 21st ACM SIGPLAN/SIGBED Conference on Languages, Compilers, and Tools for Embedded Systems, pages 15–25, 2020
2020
-
[8]
Robust benchmarking in noisy environments
Jiahao Chen and Jarrett Revels. Robust benchmarking in noisy environments. arXiv preprint arXiv:1608.04295, 2016
Pith/arXiv arXiv 2016
-
[9]
Autofdo: Automatic feedback- directed optimization for warehouse-scale applications
Dehao Chen, David Xinliang Li, and Tipp Moseley. Autofdo: Automatic feedback- directed optimization for warehouse-scale applications. InProceedings of the 2016 International Symposium on Code Generation and Optimization, pages 12–23, 2016
2016
-
[10]
Tvm: An automated end-to-end optimizing compiler for deep learning
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. Tvm: An automated end-to-end optimizing compiler for deep learning. In13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 578–594, 2018
2018
-
[11]
Crewai documentation
CrewAI Inc. Crewai documentation. https://docs.crewai.com/, 2025. Official documentation, accessed 2026-03-18
2025
-
[12]
Compilergym: Robust, performant compiler optimization environments for ai research
Chris Cummins, Bram Wasti, Jiadong Guo, Brandon Cui, Jason Ansel, Sahir Gomez, Somya Jain, Jia Liu, Olivier Teytaud, Benoit Steiner, et al. Compilergym: Robust, performant compiler optimization environments for ai research. In2022 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 92–105. IEEE, 2022
2022
-
[13]
Chris Cummins, Volker Seeker, Dejan Grubisic, Baptiste Roziere, Jonas Gehring, Gabriel Synnaeve, and Hugh Leather. Meta large language model compiler: Founda- tion models of compiler optimization.arXiv preprint arXiv:2407.02524, 2024
arXiv 2024
-
[14]
Llm compiler: Foundation language models for compiler optimization
Chris Cummins, Volker Seeker, Dejan Grubisic, Baptiste Roziere, Jonas Gehring, Gabriel Synnaeve, and Hugh Leather. Llm compiler: Foundation language models for compiler optimization. InProceedings of the 34th ACM SIGPLAN International Conference on Compiler Construction, pages 141–153, 2025
2025
-
[15]
Introducing deepseek-v3.2-exp
DeepSeek AI. Introducing deepseek-v3.2-exp. https://api-docs.deepseek.com/ news/news250929, 2025
2025
-
[16]
Portable compiler optimisation across embedded programs and microarchitectures using machine learning
Christophe Dubach, Timothy M Jones, Edwin V Bonilla, Grigori Fursin, and Michael FP O’Boyle. Portable compiler optimisation across embedded programs and microarchitectures using machine learning. InProceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, pages 78–88, 2009
2009
-
[17]
Coremark
EEMBC. Coremark. https://www.eembc.org/coremark/, 2009
2009
-
[18]
Llm-veriopt: Verification-guided reinforcement learning for llm-based compiler op- timization
Xiangxin Fang, Jiaqin Kang, Rodrigo Rocha, Sam Ainsworth, and Lev Mukhanov. Llm-veriopt: Verification-guided reinforcement learning for llm-based compiler op- timization. In2026 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 740–755. IEEE, 2026
2026
-
[19]
Gcc internals
Free Software Foundation. Gcc internals. https://gcc.gnu.org/onlinedocs/gccint/, 2025
2025
-
[20]
Yingjie Fu, Bozhou Li, Linyi Li, Wentao Zhang, and Tao Xie. The first prompt counts the most! an evaluation of large language models on iterative example-based code generation.Proceedings of the ACM on Software Engineering, 2(ISSTA):1583–1606, 2025
2025
-
[21]
Milepost gcc: Machine learning enabled self-tuning compiler.Inter- national journal of parallel programming, 39(3):296–327, 2011
Grigori Fursin, Yuriy Kashnikov, Abdul Wahid Memon, Zbigniew Chamski, Olivier Temam, Mircea Namolaru, Elad Yom-Tov, Bilha Mendelson, Ayal Zaks, Eric Courtois, et al. Milepost gcc: Machine learning enabled self-tuning compiler.Inter- national journal of parallel programming, 39(3):296–327, 2011
2011
-
[22]
Search-based llms for code optimization.arXiv preprint arXiv:2408.12159, 2024
Shuzheng Gao, Cuiyun Gao, Wenchao Gu, and Michael Lyu. Search-based llms for code optimization.arXiv preprint arXiv:2408.12159, 2024
arXiv 2024
-
[23]
Gemini 3 flash: Frontier intelligence built for speed
Google. Gemini 3 flash: Frontier intelligence built for speed. https://blog.google/ products-and-platforms/products/gemini/gemini-3-flash/, December 2025
2025
-
[24]
Revamping sampling- based pgo with context-sensitivity and pseudo-instrumentation
Wenlei He, Hongtao Yu, Lei Wang, and Taewook Oh. Revamping sampling- based pgo with context-sensitivity and pseudo-instrumentation. In2024 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pages 322–333. IEEE, 2024
2024
-
[25]
Yibo He, Shuoran Zhao, Jiaming Huang, Yingjie Fu, Hao Yu, Cunjian Huang, and Tao Xie. Simdbench: Benchmarking large language models for simd-intrinsic code generation.arXiv preprint arXiv:2507.15224, 2025
arXiv 2025
-
[26]
Compileagent: Automated real-world repo-level compilation with tool-integrated llm-based agent system
Li Hu, Guoqiang Chen, Xiuwei Shang, Shaoyin Cheng, Benlong Wu, LiGangyang LiGangyang, Xu Zhu, Weiming Zhang, and Nenghai Yu. Compileagent: Automated real-world repo-level compilation with tool-integrated llm-based agent system. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2078–2091, 2025
2078
-
[27]
Autophase: Compiler phase-ordering for hls with deep reinforcement learning
Qijing Huang, Ameer Haj-Ali, William Moses, John Xiang, Ion Stoica, Krste Asanovic, and John Wawrzynek. Autophase: Compiler phase-ordering for hls with deep reinforcement learning. In2019 IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines, pages 308–308. IEEE, 2019
2019
-
[28]
Lulesh 2.0 updates and changes, August 2013
Ian Karlin, Jeff Keasler, and Rob Neely. Lulesh 2.0 updates and changes, August 2013
2013
-
[29]
Llvm: A compilation framework for lifelong program analysis & transformation
Chris Lattner and Vikram Adve. Llvm: A compilation framework for lifelong program analysis & transformation. InInternational symposium on code generation and optimization, 2004. CGO 2004., pages 75–86. IEEE, 2004
2004
-
[30]
Assessing a mini-application as a performance proxy for a finite element method engineering application.Concurrency and Computation: Practice and Experience, 27(17):5374–5389, 2015
Paul T Lin, Michael A Heroux, Richard F Barrett, and Alan B Williams. Assessing a mini-application as a performance proxy for a finite element method engineering application.Concurrency and Computation: Practice and Experience, 27(17):5374–5389, 2015
2015
-
[31]
Hongyu Lin, Haolin Pan, Haoran Luo, Yuchen Li, Kaichun Yao, Libo Zhang, Mingjie Xing, and Yanjun Wu. Awarecompiler: Agentic context-aware compiler optimization via a synergistic knowledge-data driven framework.arXiv preprint arXiv:2510.11759, 2025
arXiv 2025
-
[32]
Temac: Multi-agent collaboration for automated web gui testing.arXiv preprint arXiv:2506.00520, 2025
Chenxu Liu, Zhiyu Gu, Guoquan Wu, Ying Zhang, Jun Wei, and Tao Xie. Temac: Multi-agent collaboration for automated web gui testing.arXiv preprint arXiv:2506.00520, 2025
arXiv 2025
-
[33]
Llvm 17.0.6 released
LLVM. Llvm 17.0.6 released. https://discourse.llvm.org/t/llvm-17-0-6-released/ 75281, 2023
2023
-
[34]
Hello gpt-4o
OpenAI. Hello gpt-4o. https://openai.com/index/hello-gpt-4o/, May 2024
2024
-
[35]
R Pan, H Zhang, and C Liu. Codecor: An llm-based self-reflective multi-agent framework for code generation (2025).arXiv preprint arXiv:2501.07811
arXiv 2025
-
[36]
Haolin Pan, Hongyu Lin, Haoran Luo, Yang Liu, Kaichun Yao, Libo Zhang, Mingjie Xing, and Yanjun Wu. Compiler-r1: Towards agentic compiler auto-tuning with reinforcement learning.arXiv preprint arXiv:2506.15701, 2025
arXiv 2025
-
[37]
Towards efficient compiler auto-tuning: Leveraging synergistic search spaces
Haolin Pan, Yuanyu Wei, Mingjie Xing, Yanjun Wu, and Chen Zhao. Towards efficient compiler auto-tuning: Leveraging synergistic search spaces. InProceedings of the 23rd ACM/IEEE International Symposium on Code Generation and Optimization, pages 614–627, 2025
2025
-
[38]
Polybench/c: The polyhedral benchmark suite
Louis-Noël Pouchet. Polybench/c: The polyhedral benchmark suite. https: //www.cs.colostate.edu/~pouchet/software/polybench/, 2012
2012
-
[39]
Javascript performance tuning as a crowd- sourced service.IEEE Transactions on Mobile Computing, 23(5):6116–6132, 2023
Jie Ren, Ling Gao, and Zheng Wang. Javascript performance tuning as a crowd- sourced service.IEEE Transactions on Mobile Computing, 23(5):6116–6132, 2023
2023
-
[40]
Wadec: Decompiling webassembly using large language model
Xinyu She, Yanjie Zhao, and Haoyu Wang. Wadec: Decompiling webassembly using large language model. InProceedings of the 39th IEEE/ACM international conference on automated software engineering, pages 481–492, 2024
2024
-
[41]
Exploring the space of optimization sequences for code-size reduction: insights and tools
Anderson Faustino da Silva, Bernardo NB De Lima, and Fernando Magno Quintão Pereira. Exploring the space of optimization sequences for code-size reduction: insights and tools. InProceedings of the 30th ACM SIGPLAN International Conference on Compiler Construction, pages 47–58, 2021. Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Trovato et al
2021
-
[42]
Using the gnu compiler collection.Free Software Foundation, 4(02), 2003
Richard M Stallman et al. Using the gnu compiler collection.Free Software Foundation, 4(02), 2003
2003
-
[43]
Llm-vectorizer: Llm-based verified loop vectorizer
Jubi Taneja, Avery Laird, Cong Yan, Madan Musuvathi, and Shuvendu K Lahiri. Llm-vectorizer: Llm-based verified loop vectorizer. InProceedings of the 23rd ACM/IEEE International Symposium on Code Generation and Optimization, pages 137–149, 2025
2025
-
[44]
Mlgo: a machine learning guided compiler optimizations framework
Mircea Trofin, Yundi Qian, Eugene Brevdo, Zinan Lin, Krzysztof Choromanski, and David Li. Mlgo: a machine learning guided compiler optimizations framework. arXiv preprint arXiv:2101.04808, 2021
arXiv 2021
-
[45]
Machine learning in compiler optimization
Zheng Wang and Michael O’Boyle. Machine learning in compiler optimization. Proceedings of the IEEE, 106(11):1879–1901, 2018
1901
-
[46]
Hardware counted profile-guided optimization.arXiv preprint arXiv:1411.6361, 2014
Baptiste Wicht, Roberto A Vitillo, Dehao Chen, and David Levinthal. Hardware counted profile-guided optimization.arXiv preprint arXiv:1411.6361, 2014
Pith/arXiv arXiv 2014
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[48]
Leveraging compilation statistics for compiler phase ordering
Jiayu Zhao, Chunwei Xia, and Zheng Wang. Leveraging compilation statistics for compiler phase ordering. In2025 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 533–545. IEEE, 2025
2025
-
[49]
Zhongchun Zheng, Long Cheng, Lu Li, Rodrigo CO Rocha, Tianyi Liu, Wei Wei, Xianwei Zhang, and Yaoqing Gao. Vectrans: Llm transformation framework for better auto-vectorization on high-performance cpu.arXiv preprint arXiv:2503.19449, 2025. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.