SignVLA: Real-Time Sign Language-Guided Robotic Manipulation via Attention LSTM and Vision-Language-Action Models
Pith reviewed 2026-06-26 17:08 UTC · model grok-4.3
The pith
Sign language inputs can drive robotic manipulation by converting real-time gestures into instructions for vision-language-action models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
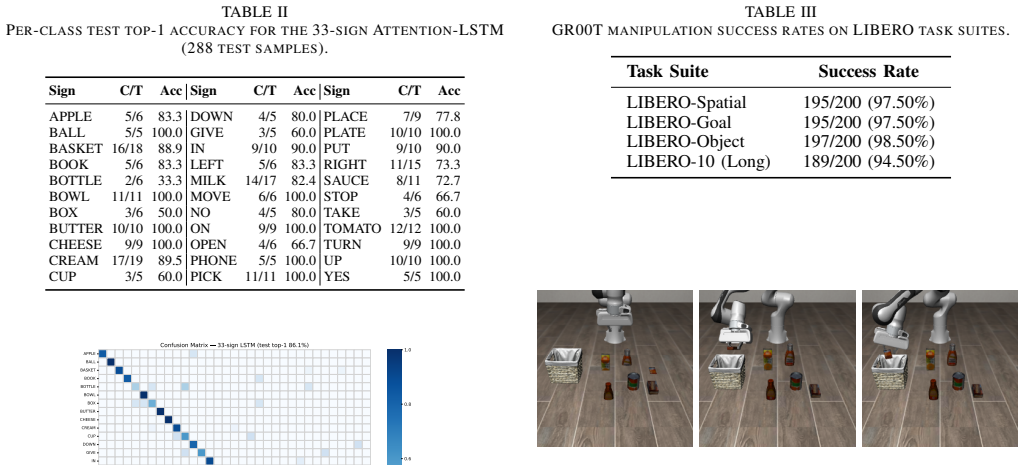
SignVLA shows that hand landmark features fed through an attention-enhanced LSTM can achieve stable real-time recognition of alphabet- and command-level signs, with a temporal stabilization module improving consistency, and that the resulting instruction sequences enable successful execution of robotic manipulation tasks when supplied to a downstream vision-language-action policy.
What carries the argument
The modular sign-to-text interface that extracts hand landmarks from video, processes them with an attention LSTM to model temporal gesture dynamics, applies stabilization, and outputs semantic instructions for VLA policies.
If this is right
- Robotic manipulation becomes executable from sign language video streams in real time.
- VLA policies can accept non-speech inputs without internal changes to their architecture.
- Lightweight temporal models suffice to bridge sign gestures to semantic commands.
- Human-robot interaction gains an accessibility layer for deaf and hard-of-hearing users.
Where Pith is reading between the lines
- The same modular bridge could be adapted to other non-verbal inputs such as gestures or facial expressions.
- Extending the sign vocabulary beyond alphabet and basic commands would require only additional training data for the LSTM component.
- If recognition accuracy holds across varied lighting and user styles, the approach scales to multi-user shared workspaces.
Load-bearing premise
The sign-to-text conversion produces instructions that match the user's intent closely enough for the VLA policy to interpret and execute them correctly.
What would settle it
An experiment in which sign-language inputs produce measurably higher task failure rates or different actions than equivalent text inputs under identical visual conditions would show the interface does not preserve intent effectively.
Figures







read the original abstract
Vision-Language-Action (VLA) models enable robots to execute manipulation tasks from natural-language instructions grounded in visual observations. However, existing VLA interfaces primarily rely on speech or text input, limiting accessibility for deaf, hard-of-hearing, and speech-impaired users. We present SignVLA, a real-time sign-language-guided VLA framework for accessible human-robot interaction. The system introduces a modular sign-to-text interface that converts visual sign gestures into semantic instructions compatible with downstream VLA policies. Given video streams, SignVLA extracts hand landmark features and employs an attention-enhanced Long Short-Term Memory (LSTM) network to capture temporal gesture dynamics for alphabet- and command-level sign recognition. A temporal stabilization module further improves prediction consistency in real-time interaction settings.The generated instruction sequence is then passed to a downstream VLA policy for sign-conditioned robotic manipulation. Experimental results demonstrate stable real-time sign recognition and successful execution of manipulation tasks driven by sign-language inputs. Our findings suggest that lightweight temporal sign recognition can serve as an effective and practical accessibility layer for multimodal embodied intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SignVLA, a modular real-time framework for sign-language-guided robotic manipulation. It extracts hand landmarks from video, uses an attention-enhanced LSTM with temporal stabilization for alphabet- and command-level sign recognition, converts the output to semantic text instructions, and feeds these to a downstream VLA policy for manipulation. The abstract claims that experimental results show stable real-time sign recognition and successful task execution.
Significance. If the central claims hold with supporting evidence, the work would offer a practical accessibility layer for VLA models, extending embodied AI interfaces to deaf and hard-of-hearing users via sign language without requiring speech or text.
major comments (1)
- Abstract: the claim that 'Experimental results demonstrate stable real-time sign recognition and successful execution of manipulation tasks driven by sign-language inputs' is presented without any metrics, success rates, error bars, ablation studies, task definitions, or experimental setup. This directly undermines evaluation of the central claim, as the weakest assumption (that the sign-to-text interface preserves intent for the VLA without meaningful loss) cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the review and the specific feedback on the abstract. We address the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: the claim that 'Experimental results demonstrate stable real-time sign recognition and successful execution of manipulation tasks driven by sign-language inputs' is presented without any metrics, success rates, error bars, ablation studies, task definitions, or experimental setup. This directly undermines evaluation of the central claim, as the weakest assumption (that the sign-to-text interface preserves intent for the VLA without meaningful loss) cannot be assessed.
Authors: We agree that the abstract states the experimental outcome at a high level without quantitative support. The manuscript body (Section 4) contains the experimental setup, task definitions, sign-recognition accuracy and latency metrics, ablation results on the attention LSTM and temporal stabilization components, and manipulation task success rates. To directly address the concern and allow assessment of intent preservation through the sign-to-text module, we will revise the abstract to incorporate key quantitative results from those experiments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a modular pipeline (attention LSTM sign recognition + temporal stabilization + downstream VLA policy) and reports experimental outcomes. No equations, parameter fits, derivations, or self-citation chains are present that reduce any claimed result to its inputs by construction. The central claims rest on empirical task success rather than self-referential definitions or renamed fits. This is the normal case of a system-description paper with no load-bearing mathematical steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Palm- e: An embodied multimodal language model,
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence, “Palm- e: An embodied multimodal language model,” inProceedings of the 40th International Conf...
2023
-
[2]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, J. Singh, A. Singh, P. Sermanet, P. Sanketi, G. Salazar, M. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, I. Leal, L. Lee, Y . Kuang, D. Kalashnikov, R. Julian, N. Joshi, A. Irpan, B. Ichter, J. Hs...
2023
-
[3]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” inProceedings of The 8th Conference on Robot Learning, ser. Proceedings of Machine Learning Res...
2025
-
[4]
GR00T N1: An open foundation model for generalist humanoid robots,
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, ...
Pith/arXiv arXiv 2025
-
[5]
A reinforcement learning- based approach for optimal output tracking in uncertain nonlinear sys- tems with mismatched disturbances,
Z. Tang, J. A. Rossiter, and G. Panoutsos, “A reinforcement learning- based approach for optimal output tracking in uncertain nonlinear sys- tems with mismatched disturbances,” in2024 UKACC 14th International Conference on Control (CONTROL), 2024, pp. 169–174
2024
-
[6]
Reinforcement learning based optimal control: A survey on adaptive dynamic programming in robotics,
C. Chan, N. Bai, Q. Yin, J. Wang, B. Ning, B. Hu, Y . Yan, and Z. Tang, “Reinforcement learning based optimal control: A survey on adaptive dynamic programming in robotics,” 01 2026
2026
-
[7]
Disturbance rejection via iterative learning control with a disturbance observer for active magnetic bearing systems,
Z. Tang, Y . Yu, Z. Li, and Z. Ding, “Disturbance rejection via iterative learning control with a disturbance observer for active magnetic bearing systems,”Frontiers of Information Technology & Electronic Engineer- ing, vol. 20, no. 1, pp. 131–140, 2019
2019
-
[8]
Disturbance observer-based tracking control for roll-to-roll slot die coating systems under gap and pump rate disturbances,
Z. Tang, C. Passmore, A. I. Campbell, J. Howse, J. A. Rossiter, S. Ebbens, and G. Panoutsos, “Disturbance observer-based tracking control for roll-to-roll slot die coating systems under gap and pump rate disturbances,” 2026
2026
-
[9]
Reinforcement learning-based output stabilization control for nonlinear systems with generalized disturbances,
Z. Tang, J. A. Rossiter, Y . Dong, and G. Panoutsos, “Reinforcement learning-based output stabilization control for nonlinear systems with generalized disturbances,” in2024 IEEE International Conference on Industrial Technology (ICIT), 2024, pp. 1–6
2024
-
[10]
Deep reinforcement learning optimization for uncertain nonlinear systems via event-triggered robust adaptive dynamic programming,
N. Bai, C. P. Chan, Q. Yin, T. Gong, Y . Yan, and Z. Tang, “Deep reinforcement learning optimization for uncertain nonlinear systems via event-triggered robust adaptive dynamic programming,” 2025
2025
-
[11]
Discrete-time stress matrix-based formation control of general linear multi-agent systems,
O. Onuoha, S. Kurawa, Z. Tang, and Y . Dong, “Discrete-time stress matrix-based formation control of general linear multi-agent systems,” 2024
2024
-
[12]
Real- time object detection and robotic manipulation for agriculture using a yolo-based learning approach,
H. Zhao, Z. Tang, Z. Li, Y . Dong, Y . Si, M. Lu, and G. Panoutsos, “Real- time object detection and robotic manipulation for agriculture using a yolo-based learning approach,” 2024
2024
-
[13]
Signformer is all you need: Towards edge ai for sign language,
E. Yang, “Signformer is all you need: Towards edge ai for sign language,” 2024
2024
-
[14]
Sign language transformers: Joint end-to-end sign language recognition and transla- tion,
N. C. Camgoz, O. Koller, S. Hadfield, and R. Bowden, “Sign language transformers: Joint end-to-end sign language recognition and transla- tion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 023–10 033
2020
-
[15]
An efficient sign language translation using spatial configuration and motion dynamics with llms,
E. J. Hwang, S. Cho, J. Lee, and J. C. Park, “An efficient sign language translation using spatial configuration and motion dynamics with llms,” 2025
2025
-
[16]
Signllm: Sign language production large language models,
S. Fang, C. Chen, L. Wang, C. Zheng, C. Sui, and Y . Tian, “Signllm: Sign language production large language models,” 2025
2025
-
[17]
Gloss-free sign language translation: Improving from visual-language pretraining,
B. Zhou, Z. Chen, A. Clap ´es, J. Wan, Y . Liang, S. Escalera, Z. Lei, and D. Zhang, “Gloss-free sign language translation: Improving from visual-language pretraining,” 2023
2023
-
[18]
Mediapipe hands: On-device real-time hand tracking,
F. Zhang, V . Bazarevsky, A. Vakunov, A. Tkachenka, G. Sung, C.-L. Chang, and M. Grundmann, “Mediapipe hands: On-device real-time hand tracking,”arXiv preprint arXiv:2006.10214, 2020
arXiv 2006
-
[19]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[20]
Neural machine translation by jointly learning to align and translate,
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate,” inInternational Conference on Learning Representations, 2015
2015
-
[21]
Gloss-free sign language translation: Improving from visual- language pretraining,
B. Zhou, Z. Chen, A. Clap ´es, J. Wan, Y . Liang, S. Escalera, Z. Lei, and D. Zhang, “Gloss-free sign language translation: Improving from visual- language pretraining,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 20 871–20 881
2023
-
[22]
ASL Citizen: A community-sourced dataset for advancing isolated sign language recognition,
A. Desai, L. Berger, F. O. Minakov, V . Milan, C. Singh, K. Pumphrey, R. E. Ladner, H. Daum ´e III, A. X. Lu, N. Caselli, and D. Bragg, “ASL Citizen: A community-sourced dataset for advancing isolated sign language recognition,” inAdvances in Neural Information Processing Systems, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.