A3C3: AI Algorithm and Accelerator Co-design, Co-search, and Co-generation
Pith reviewed 2026-06-26 15:01 UTC · model grok-4.3
The pith
A3C3 jointly parameterizes and searches neural network architectures together with accelerator designs to generate balanced pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A3C3 parameterizes both algorithmic and accelerator design spaces and searches them jointly, enabling the automatic generation of model-accelerator pairs that better balance accuracy, latency, throughput, energy efficiency, and hardware utilization.
What carries the argument
Joint parameterization of algorithmic and accelerator design spaces followed by a unified search process.
If this is right
- Model-accelerator pairs are generated automatically rather than through manual adaptation after model design.
- Trade-offs across accuracy, latency, throughput, energy, and utilization are optimized simultaneously.
- Sub-optimality from treating model development and hardware mapping as separate stages is reduced.
- Platform-dependent and heterogeneous workloads receive unified consideration during search.
Where Pith is reading between the lines
- If the joint search scales, overall design iteration time for embedded AI systems could shrink because feedback between model and hardware occurs inside one loop.
- The same parameterization idea might be tested on non-neural workloads or on emerging memory technologies not covered in the current formulation.
- Unexpected model structures that only become viable on specific accelerator features could surface only when the spaces are searched together.
Load-bearing premise
A joint parameterization of the algorithm and accelerator spaces exists that remains searchable and yields pairs superior to those obtained from sequential design.
What would settle it
A side-by-side comparison on the same workloads and metrics showing that A3C3-generated pairs achieve no improvement, or worse results, than pairs produced by first designing the model then mapping it to hardware.
Figures


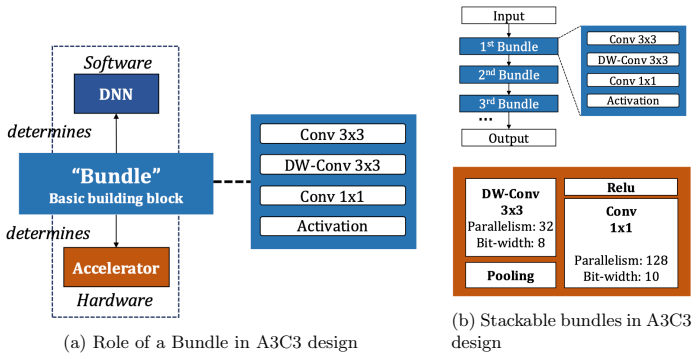
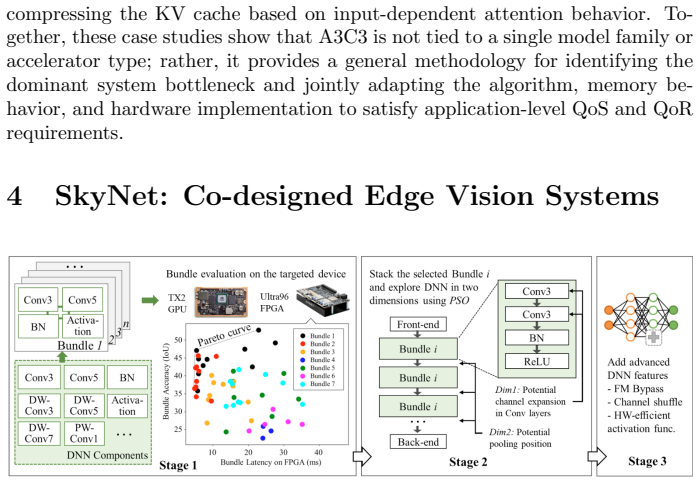
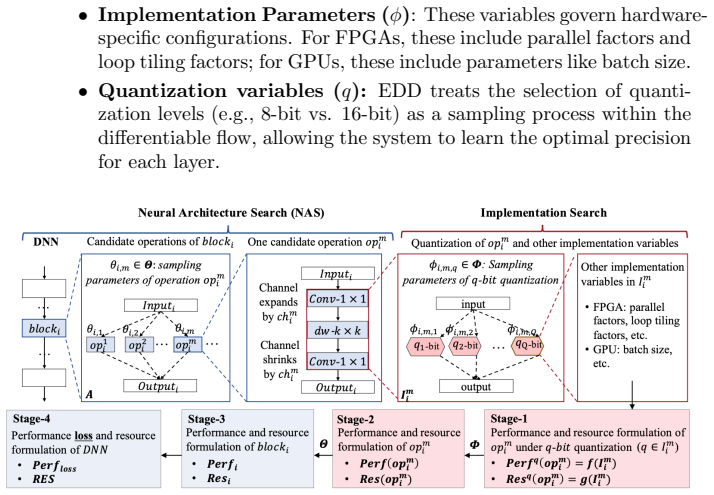

read the original abstract
We present a holistic methodology for artificial intelligence algorithm and accelerator co-design, co-search, and co-generation (A3C3), which jointly optimizes neural network architectures and their hardware implementations to address the inefficiencies of traditional top-down AI system design flows. Conventional AI deployment often treats model design and hardware mapping as separate stages: an algorithm is first developed for accuracy, and only afterward adapted to meet latency, throughput, energy, or resource constraints. This separation can lead to suboptimal systems, particularly as modern AI workloads become increasingly heterogeneous, memory-intensive, and platform-dependent. A3C3 instead parameterizes both algorithmic and accelerator design spaces and searches them jointly, enabling the automatic generation of model-accelerator pairs that better balance accuracy, latency, throughput, energy efficiency, and hardware utilization. This article is a book chapter of the Handbook of Embedded Machine Learning, edited by Sudeep Pasricha and Muhammad Shafique, Springer Nature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents A3C3, a holistic methodology for artificial intelligence algorithm and accelerator co-design, co-search, and co-generation. It contrasts conventional top-down flows (develop algorithm for accuracy, then adapt to hardware constraints) with a joint parameterization of algorithmic and accelerator design spaces that enables automatic generation of model-accelerator pairs balancing accuracy, latency, throughput, energy efficiency, and hardware utilization. The work is framed as a book chapter for the Handbook of Embedded Machine Learning.
Significance. If the joint parameterization and search procedure can be shown to produce pairs that measurably dominate sequential baselines on the listed metrics, the methodology would supply a practical integrated design paradigm for heterogeneous, memory-intensive AI workloads on embedded platforms.
major comments (2)
- [Abstract] Abstract: the claim that A3C3 'parameterizes both algorithmic and accelerator design spaces and searches them jointly' is stated without any definition of the design variables, constraints, encoding, or search procedure, leaving the feasibility of the joint search un-demonstrated.
- [Abstract] Abstract: no quantitative comparison (accuracy/latency/energy tables, Pareto fronts, or ablation against sequential baselines) is supplied to support the assertion that the generated pairs 'better balance' the metrics; the superiority claim therefore rests on assertion rather than evidence.
minor comments (1)
- The manuscript is positioned as a book chapter; if submitted to a journal, explicit discussion of how the described methodology differs from prior co-design frameworks (e.g., those using NAS + HLS or DSE tools) would improve context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract of our book chapter. We address each point below and agree to revise the abstract for greater clarity while preserving its concise style.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that A3C3 'parameterizes both algorithmic and accelerator design spaces and searches them jointly' is stated without any definition of the design variables, constraints, encoding, or search procedure, leaving the feasibility of the joint search un-demonstrated.
Authors: The abstract is intentionally high-level as befits a handbook chapter. The design variables (neural architecture choices and accelerator parameters such as PE array size and memory hierarchy), constraints (area, power, latency bounds), encoding (mixed discrete-continuous representation), and joint search procedure (coordinated evolutionary or RL-based optimizer) are formally defined and illustrated with diagrams in Sections 3 and 4 of the manuscript. Feasibility of the joint search is shown through the end-to-end co-generation flow and resulting model-accelerator pairs. We will revise the abstract to add one sentence that names the main variable classes and points readers to those sections. revision: yes
-
Referee: [Abstract] Abstract: no quantitative comparison (accuracy/latency/energy tables, Pareto fronts, or ablation against sequential baselines) is supplied to support the assertion that the generated pairs 'better balance' the metrics; the superiority claim therefore rests on assertion rather than evidence.
Authors: The abstract itself contains no numbers because of length limits typical for handbook chapters. The full manuscript supplies the requested quantitative evidence: accuracy/latency/energy tables, Pareto fronts, and direct ablations versus sequential top-down flows appear in Section 5. These results demonstrate measurable improvements on the listed metrics. We will revise the abstract to include a single high-level sentence summarizing the key quantitative gains (e.g., X% better energy efficiency at iso-accuracy) with a forward reference to Section 5. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper is a high-level methodology description of A3C3 for joint algorithm-accelerator co-design. The abstract and available text contain no equations, fitted parameters, derivations, or self-citations that could reduce a claimed result to its inputs by construction. No self-definitional steps, fitted-input predictions, or load-bearing self-citation chains appear. The central premise is asserted conceptually rather than derived mathematically, so the content is self-contained with no circular reduction possible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InPro- ceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
2024
-
[2]
Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architec- ture search on target task and hardware.arXiv preprint arXiv:1812.00332, 2018
Pith/arXiv arXiv 2018
-
[3]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774, 2024
Pith/arXiv arXiv 2024
-
[4]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decod- ing with speculative sampling.arXiv preprint arXiv:2302.01318, 2023. 25
Pith/arXiv arXiv 2023
-
[5]
xpilot: A platform-based behavioral synthesis system.SRC Tech- Con, 5:54, 2005
Deming Chen, Jason Cong, Yiping Fan, Guoling Han, Wei Jiang, and Zhiru Zhang. xpilot: A platform-based behavioral synthesis system.SRC Tech- Con, 5:54, 2005
2005
-
[6]
Fpga hls today: successes, challenges, and op- portunities.ACM Transactions on Reconfigurable Technology and Systems (TRETS), 15(4):1–42, 2022
Jason Cong, Jason Lau, Gai Liu, Stephen Neuendorffer, Peichen Pan, Kees Vissers, and Zhiru Zhang. Fpga hls today: successes, challenges, and op- portunities.ACM Transactions on Reconfigurable Technology and Systems (TRETS), 15(4):1–42, 2022
2022
-
[7]
Low La- tency Inference Chapter 1: Up to 1.9x Higher Llama 3.1 Performance with Medusa on NVIDIA HGX H200 with NVLink Switch
Ashraf Eassa, Brian Slechta, Brian Pharris, and Nick Comly. Low La- tency Inference Chapter 1: Up to 1.9x Higher Llama 3.1 Performance with Medusa on NVIDIA HGX H200 with NVLink Switch. NVIDIA Technical Blog, September 2024. NVIDIA Technical Blog. Accessed: May 25, 2026
2024
-
[8]
Deep neural network model and fpga ac- celerator co-design: Opportunities and challenges
Cong Hao and Deming Chen. Deep neural network model and fpga ac- celerator co-design: Opportunities and challenges. In2018 14th IEEE In- ternational Conference on Solid-State and Integrated Circuit Technology (ICSICT), pages 1–4. IEEE, 2018
2018
-
[9]
Fpga/dnn co-design: An effi- cient design methodology for iot intelligence on the edge
Cong Hao, Xiaofan Zhang, Yuhong Li, Sitao Huang, Jinjun Xiong, Kyle Rupnow, Wen-mei Hwu, and Deming Chen. Fpga/dnn co-design: An effi- cient design methodology for iot intelligence on the edge. InProceedings of the 56th Annual Design Automation Conference 2019, pages 1–6, 2019
2019
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[11]
Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[12]
Searching for mobilenetv3
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasude- van, et al. Searching for mobilenetv3. InProceedings of the IEEE/CVF international conference on computer vision, pages 1314–1324, 2019
2019
-
[13]
Quantization and training of neural networks for efficient integer-arithmetic-only infer- ence
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only infer- ence. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2704–2713, 2018
2018
-
[14]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Ma- chine Learning, pages 19274–19286. PMLR, 2023
2023
-
[15]
Edd: Efficient differentiable dnn architecture and implementation co-search for embedded ai solutions
Yuhong Li, Cong Hao, Xiaofan Zhang, Xinheng Liu, Yao Chen, Jinjun Xiong, Wen-mei Hwu, and Deming Chen. Edd: Efficient differentiable dnn architecture and implementation co-search for embedded ai solutions. In 26 2020 57th ACM/IEEE Design Automation Conference (DAC), pages 1–6. IEEE, 2020
2020
-
[16]
Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Lo- catelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
2024
-
[17]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.https://vicuna.lmsys.org/, 2023
LMSYS. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.https://vicuna.lmsys.org/, 2023. Online; accessed 2026-03-02
2023
-
[18]
NVIDIA HGX Platform.https://www.nvidia.com/en-us/ data-center/hgx/
NVIDIA. NVIDIA HGX Platform.https://www.nvidia.com/en-us/ data-center/hgx/. Accessed: May 25, 2026
2026
-
[19]
Speculative Sampling.https://nvidia.github.io/ TensorRT-LLM/advanced/speculative-decoding.html#medusa
NVIDIA. Speculative Sampling.https://nvidia.github.io/ TensorRT-LLM/advanced/speculative-decoding.html#medusa. TensorRT-LLM documentation. Last updated: September 15, 2025. Accessed: May 25, 2026
2025
-
[20]
An introduction to convolutional neural networks.arXiv preprint arXiv:1511.08458, 2015
Keiron O’shea and Ryan Nash. An introduction to convolutional neural networks.arXiv preprint arXiv:1511.08458, 2015
Pith/arXiv arXiv 2015
-
[21]
Fcuda: Enabling efficient compilation of cuda kernels onto fpgas
Alexandros Papakonstantinou, Karthik Gururaj, John A Stratton, Dem- ing Chen, Jason Cong, and Wen-Mei W Hwu. Fcuda: Enabling efficient compilation of cuda kernels onto fpgas. In2009 IEEE 7th Symposium on Application Specific Processors, pages 35–42. IEEE, 2009
2009
-
[22]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 779– 788, 2016
2016
-
[23]
Robin M Schmidt. Recurrent neural networks (rnns): A gentle introduction and overview.arXiv preprint arXiv:1912.05911, 2019
arXiv 1912
-
[24]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beu- tel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, A...
2026
-
[25]
Mnasnet: Platform-aware neural archi- tecture search for mobile
Mingxing Tan, Bo Chen, Ruoming Pang, Vijay Vasudevan, Mark Sandler, Andrew Howard, and Quoc V Le. Mnasnet: Platform-aware neural archi- tecture search for mobile. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2820–2828, 2019. 29
2019
-
[26]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[27]
CHaiDNN.https://github.com/Xilinx/chaidnn, 2018
Xilinx Inc. CHaiDNN.https://github.com/Xilinx/chaidnn, 2018. Re- trieved August 23, 2018
2018
-
[28]
Dac-sdc low power object detection challenge for uav applications.IEEE transactions on pattern analysis and machine intelligence, 43(2):392–403, 2019
Xiaowei Xu, Xinyi Zhang, Bei Yu, Xiaobo Sharon Hu, Christopher Rowen, Jingtong Hu, and Yiyu Shi. Dac-sdc low power object detection challenge for uav applications.IEEE transactions on pattern analysis and machine intelligence, 43(2):392–403, 2019
2019
-
[29]
Scalehls: A new scalable high- level synthesis framework on multi-level intermediate representation
Hanchen Ye, Cong Hao, Jianyi Cheng, Hyunmin Jeong, Jack Huang, Stephen Neuendorffer, and Deming Chen. Scalehls: A new scalable high- level synthesis framework on multi-level intermediate representation. In 2022 IEEE international symposium on high-performance computer archi- tecture (HPCA), pages 741–755. IEEE, 2022
2022
-
[30]
Hida: A hierarchical dataflow compiler for high-level synthesis
Hanchen Ye, Hyegang Jun, and Deming Chen. Hida: A hierarchical dataflow compiler for high-level synthesis. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Lan- guages and Operating Systems, Volume 1, pages 215–230, 2024
2024
-
[31]
Shufflenet: An extremely efficient convolutional neural network for mobile devices
Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 6848–6856, 2018
2018
-
[32]
Skynet: a hardware-efficient method for object detection and tracking on embedded systems.Proceedings of Machine Learning and Systems, 2:216– 229, 2020
Xiaofan Zhang, Haoming Lu, Cong Hao, Jiachen Li, Bowen Cheng, Yuhong Li, Kyle Rupnow, Jinjun Xiong, Thomas Huang, Honghui Shi, et al. Skynet: a hardware-efficient method for object detection and tracking on embedded systems.Proceedings of Machine Learning and Systems, 2:216– 229, 2020
2020
-
[33]
Dnnbuilder: An automated tool for building high-performance dnn hardware accelerators for fpgas
Xiaofan Zhang, Junsong Wang, Chao Zhu, Yonghua Lin, Jinjun Xiong, Wen-mei Hwu, and Deming Chen. Dnnbuilder: An automated tool for building high-performance dnn hardware accelerators for fpgas. InPro- ceedings of the International Conference on Computer-Aided Design, pages 1–8, 2018
2018
-
[34]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[35]
Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578, 2016
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578, 2016. 30
Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.