PROTON: Prototype-Based Test-Time Online OOD Detection for Medical VLMs
Pith reviewed 2026-06-26 17:44 UTC · model grok-4.3
The pith
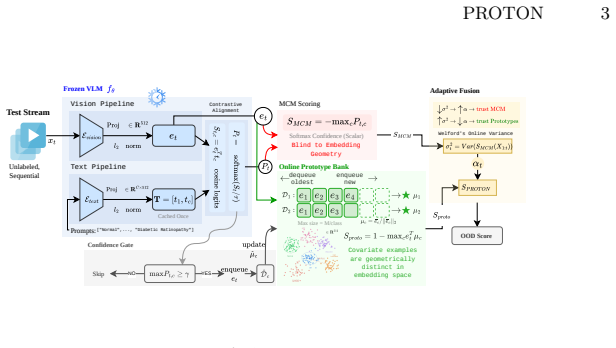
Medical VLMs detect out-of-distribution images at test time by building an online bank of prototypes from confident predictions and fusing it with existing scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
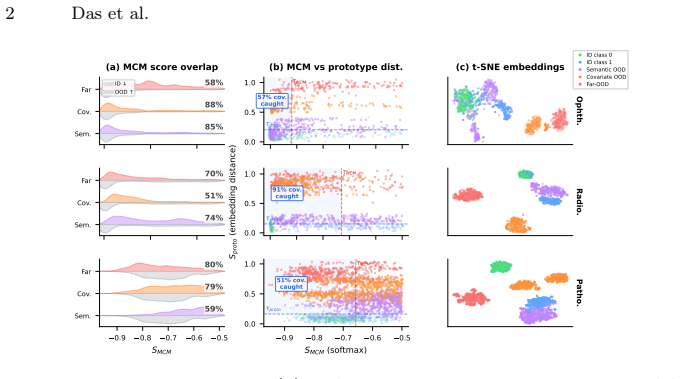
The paper establishes that a lightweight post-hoc module called PROTON maintains an online prototype bank from high-confidence test predictions and adaptively fuses prototype distance with MCM scoring via stream-level variance statistics; on the FLAIR plus FIVES ophthalmology benchmark this raises AUROC by 23.9 points on covariate shift, 8.8 on semantic shift, and 8.1 on far-OOD, making it the only zero-shot method that improves all three shift categories without hierarchical prompts or labeled data.
What carries the argument
An online prototype bank updated from high-confidence test predictions and adaptively fused with MCM scores using stream-level variance statistics.
If this is right
- The method raises detection accuracy on covariate-shifted medical images that static softmax scores treat as in-distribution.
- Gains appear on semantic shift and far-OOD cases at the same time, without separate tuning for each shift type.
- No model weights, training data, or prompt engineering are required, so the module can be added to any deployed VLM.
- Stream variance statistics provide a parameter-free way to balance the two scores on the fly.
Where Pith is reading between the lines
- The same prototype-bank idea could be tested on non-ophthalmology medical VLMs where embedding separation between shifts is also observed.
- If the bank accumulates over very long streams, periodic forgetting of old prototypes might become necessary to handle gradual concept drift.
- The approach implies that test-time collection of confident embeddings can substitute for the missing labeled OOD data that most detectors require.
- Clinics could monitor the variance statistic itself as a real-time indicator of how much the incoming data has drifted from the original training distribution.
Load-bearing premise
High-confidence test predictions during deployment can be used to maintain a reliable online prototype bank that captures distinct regions for covariate-shifted inputs in embedding space.
What would settle it
Performance would fall if the prototype bank is populated from a stream whose high-confidence predictions turn out to be mostly errors on shifted inputs.
Figures
read the original abstract
Medical vision-language models (VLMs) enable zero-shot clinical image classification, yet reliably detecting out-of-distribution (OOD) inputs at deployment remains an open problem. No static scoring method works across all shift types: Maximum Concept Matching (MCM) on FLAIR achieves 76.4% AUROC for far-OOD but only 42.4% for covariate shifts such as ultra-wide-field fundus images, effectively random. We trace this to a structural mismatch: covariate-shifted inputs are indistinguishable from in-distribution samples in softmax space, yet occupy distinct regions in the VLM embedding space. To exploit this untapped signal, we propose PROTON (PROtotype-based Test-time ONline OOD detection), a lightweight post-hoc module that maintains an online prototype bank from high-confidence test predictions and adaptively fuses prototype distance with MCM scoring via stream-level variance statistics, requiring no model modification, training data, or prompt engineering. On the ophthalmology benchmark FLAIR + FIVES, PROTON improves MCM by +23.9 AUROC on covariate shift, +8.8 on semantic shift, and +8.1 on far-OOD, making it the only zero-shot method to improve all three without hierarchical prompts or labeled data. Code is available at https://github.com/GenMI-Lab/PROTON, and the project page is available at https://genmi-lab.github.io/PROTON.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PROTON, a lightweight post-hoc module for test-time online OOD detection in medical vision-language models. It maintains an online prototype bank exclusively from high-confidence test predictions and adaptively fuses prototype distances with Maximum Concept Matching (MCM) scores via stream-level variance statistics. No model fine-tuning, labeled data, or prompt engineering is required. On the FLAIR + FIVES ophthalmology benchmark, PROTON is reported to improve MCM by +23.9 AUROC on covariate shift, +8.8 on semantic shift, and +8.1 on far-OOD, making it the only zero-shot method to improve across all three shift types.
Significance. If the online prototype bank remains uncontaminated and the variance-based fusion is stable, the work provides a practical, training-free way to exploit embedding-space signals that static softmax-based methods miss on covariate shifts. Public code availability is a clear strength for reproducibility. The approach could meaningfully improve safe deployment of medical VLMs, but its gains rest on unverified assumptions about high-confidence sample quality under shift.
major comments (3)
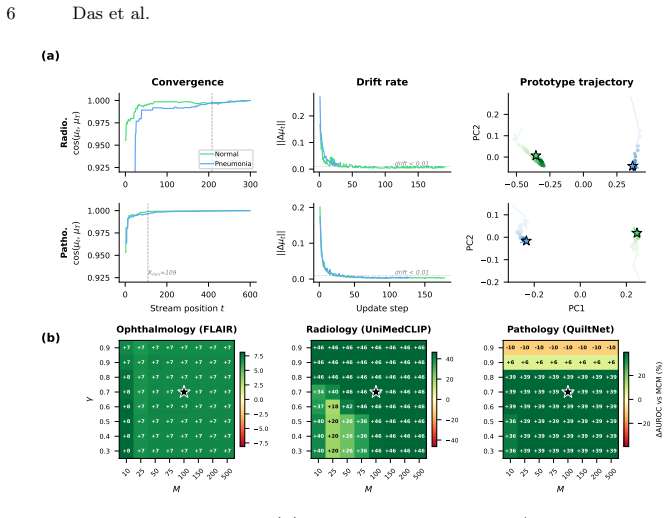
- [§3] §3 (Prototype Bank Construction): The method selects prototypes solely from high-confidence test predictions without any reported validation of their correctness or contamination rate under covariate shift. This selection step is load-bearing for the +23.9 AUROC claim on FLAIR+FIVES covariate shift, yet no experiments quantify how often high-confidence predictions are incorrect or how contamination affects the distance signal.
- [§4] §4 (Adaptive Fusion): The stream-level variance statistic used to fuse prototype distance with MCM is presented without analysis of its stability across deployment streams or sensitivity to the high-confidence threshold. No ablation or sensitivity study is shown, leaving open whether the reported cross-shift gains could arise from unstable or biased fusion.
- [Table 1] Table 1 / FLAIR+FIVES results: The AUROC improvements are stated without error bars, multiple random seeds, or explicit dataset-split details. This makes it impossible to assess whether the +23.9 / +8.8 / +8.1 gains are statistically reliable or reproducible.
minor comments (2)
- [§3] Notation for the variance-based fusion weight is introduced without an explicit equation; adding a short formula (e.g., Eq. (X)) would improve clarity.
- [Abstract] The abstract states numerical gains but supplies no pseudocode or key equations; a one-line summary of the fusion rule would help readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting key assumptions and reproducibility concerns in PROTON. We address each major comment below with clarifications and commitments to revisions where the manuscript requires strengthening.
read point-by-point responses
-
Referee: [§3] §3 (Prototype Bank Construction): The method selects prototypes solely from high-confidence test predictions without any reported validation of their correctness or contamination rate under covariate shift. This selection step is load-bearing for the +23.9 AUROC claim on FLAIR+FIVES covariate shift, yet no experiments quantify how often high-confidence predictions are incorrect or how contamination affects the distance signal.
Authors: We agree this is a load-bearing assumption and that explicit quantification was missing. In the revision we will add a post-hoc analysis on the FLAIR+FIVES benchmark (using its available labels) that reports (i) the empirical contamination rate among high-confidence samples under each shift type and (ii) an ablation showing AUROC sensitivity when 5–20 % synthetic contamination is injected into the prototype bank. This will directly substantiate the reported +23.9 AUROC gain. revision: yes
-
Referee: [§4] §4 (Adaptive Fusion): The stream-level variance statistic used to fuse prototype distance with MCM is presented without analysis of its stability across deployment streams or sensitivity to the high-confidence threshold. No ablation or sensitivity study is shown, leaving open whether the reported cross-shift gains could arise from unstable or biased fusion.
Authors: We acknowledge the absence of stability and sensitivity analysis. The revised manuscript will include (i) an ablation table varying the high-confidence threshold (0.7–0.95) and (ii) plots of the variance statistic’s coefficient of variation across stream lengths (100–1000 samples) and all three shift types. These additions will demonstrate that the adaptive fusion remains stable and is not the sole driver of the observed gains. revision: yes
-
Referee: [Table 1] Table 1 / FLAIR+FIVES results: The AUROC improvements are stated without error bars, multiple random seeds, or explicit dataset-split details. This makes it impossible to assess whether the +23.9 / +8.8 / +8.1 gains are statistically reliable or reproducible.
Authors: We agree that statistical reliability must be shown. In the revision we will (i) rerun all experiments with five random seeds, reporting mean ± std AUROC in Table 1, (ii) explicitly document the train/validation/test splits and stream ordering used for the online setting, and (iii) add a statistical significance test (paired t-test) against the MCM baseline. revision: yes
Circularity Check
No significant circularity; post-hoc module is self-contained design choice
full rationale
The paper describes a lightweight post-hoc module that builds an online prototype bank from high-confidence test predictions and fuses distances with MCM via variance statistics. No equations, fitted parameters, or derivation chain are shown that reduce a claimed result to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the method does not rename known results or smuggle ansatzes. The approach is presented as an empirical engineering choice rather than a mathematical derivation, making it self-contained against external benchmarks with no reduction to fitted inputs or self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gutbrod, M., Rauber, D., Nunes, D.W., Palm, C.: Openmibood: Open medi- cal imaging benchmarks for out-of-distribution detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 25874– 25886 (2025)
2025
-
[2]
Advances in neural information processing systems36, 37995– 38017 (2023)
Ikezogwo, W., Seyfioglu, S., Ghezloo, F., Geva, D., Sheikh Mohammed, F., Anand, P.K., Krishna, R., Shapiro, L.: Quilt-1m: One million image-text pairs for histopathology. Advances in neural information processing systems36, 37995– 38017 (2023)
2023
-
[3]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Ju, L., Zhou, S., Zhou, Y., Lu, H., Zhu, Z., Keane, P.A., Ge, Z.: Delving into out- of-distribution detection with medical vision-language models. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 133–143. Springer (2025)
2025
-
[4]
arXiv preprint arXiv:2412.10372 (2024) 10 Das et al
Khattak, M.U., Kunhimon, S., Naseer, M., Khan, S., Khan, F.S.: Unimed-clip: Towards a unified image-text pretraining paradigm for diverse medical imaging modalities. arXiv preprint arXiv:2412.10372 (2024) 10 Das et al
arXiv 2024
-
[5]
arXiv preprint arXiv:2511.09101 (2025)
Kim, B.: Ultra-light test-time adaptation for vision–language models. arXiv preprint arXiv:2511.09101 (2025)
arXiv 2025
-
[6]
In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention
Lai, R., Lu, X., Chen, K., Chen, Q., Zheng, W.S., Wang, R.: Hierarchical vision- language learning for medical out-of-distribution detection. In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention. pp. 230–239. Springer (2025)
2025
-
[7]
Li, X., Li, J., Li, F., Zhu, L., Yang, Y., Shen, H.T.: Generalizing vision-language modelstonoveldomains:Acomprehensivesurvey.arXivpreprintarXiv:2506.18504 (2025)
arXiv 2025
-
[8]
Lin, L., Bai, Y., Zhu, C., Wang, Y., Zhou, Y., Fu, H., Chen, J., et al.: Oodbench: Out-of-distribution benchmark for large vision-language models
-
[9]
Advances in neural information processing systems33, 21464–21475 (2020)
Liu, W., Wang, X., Owens, J., Li, Y.: Energy-based out-of-distribution detection. Advances in neural information processing systems33, 21464–21475 (2020)
2020
-
[10]
In: European Conference on Computer Vision
Liu, X., Zach, C.: Tag: Text prompt augmentation for zero-shot out-of-distribution detection. In: European Conference on Computer Vision. pp. 237–254. Springer (2024)
2024
-
[11]
Advances in neural information processing systems35, 35087–35102 (2022)
Ming, Y., Cai, Z., Gu, J., Sun, Y., Li, W., Li, Y.: Delving into out-of-distribution detection with vision-language representations. Advances in neural information processing systems35, 35087–35102 (2022)
2022
-
[12]
In: Thirty-Seventh Conference on Neural Information Processing Systems (2023)
Miyai, A., Yu, Q., Irie, G., Aizawa, K.: Locoop: Few-shot out-of-distribution de- tection via prompt learning. In: Thirty-Seventh Conference on Neural Information Processing Systems (2023)
2023
-
[13]
miyai et al
Miyai,A.,Yu,Q.,Irie,G.,Aizawa,K.:Gl-mcm:Globalandlocalmaximumconcept matching for zero-shot out-of-distribution detection: A. miyai et al. International Journal of Computer Vision133(6), 3586–3596 (2025)
2025
-
[14]
Silva-Rodríguez, J., Chakor, H., Kobbi, R., Dolz, J., Ben Ayed, I.: A foundation language-image model of the retina (flair): encoding expert knowledge in text supervision. Medical Image Analysis99, 103357 (Jan 2025).https://doi.org/10.1016/j.media.2024.103357,http://dx.doi.org/ 10.1016/j.media.2024.103357
-
[15]
In: proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2025
Yan, J., Guan, X., Zheng, W.S., Chen, H., Wang, R.: Global and Local Vision- Language Alignment for Few-Shot Learning and Few-Shot OOD Detection . In: proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2025. vol. LNCS 15964. Springer Nature Switzerland (September 2025)
2025
-
[16]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Conditional prompt learning for vision- language models. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[17]
arXiv preprint arXiv:2506.01716 (2025)
Zhou, Y., Levine, S., Weston, J., Li, X., Sukhbaatar, S.: Self-challenging language model agents. arXiv preprint arXiv:2506.01716 (2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.