Peeking Inside LLMs: Leveraging Internal Artifacts of LLMs for Enhancing Reliability in Legal Classification
Pith reviewed 2026-06-26 17:02 UTC · model grok-4.3
The pith
Internal artifacts of LLMs serve as reliable signals for detecting incorrect predictions on legal classification tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
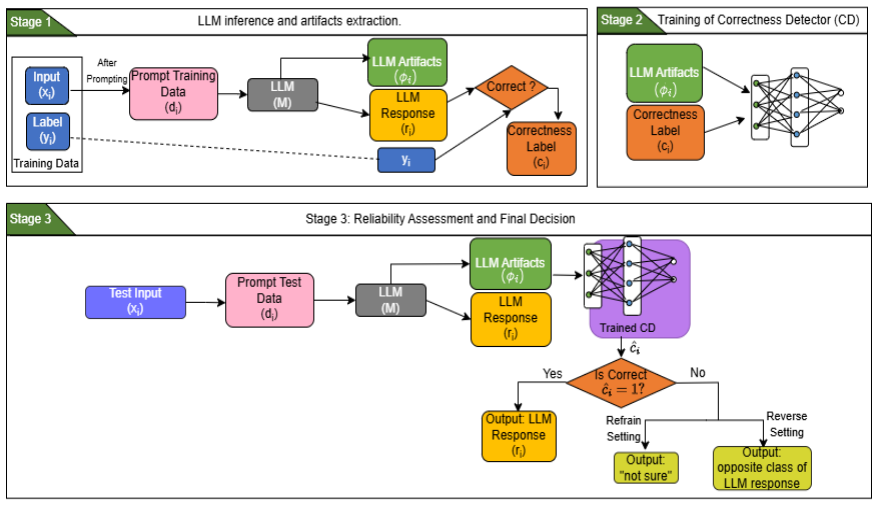
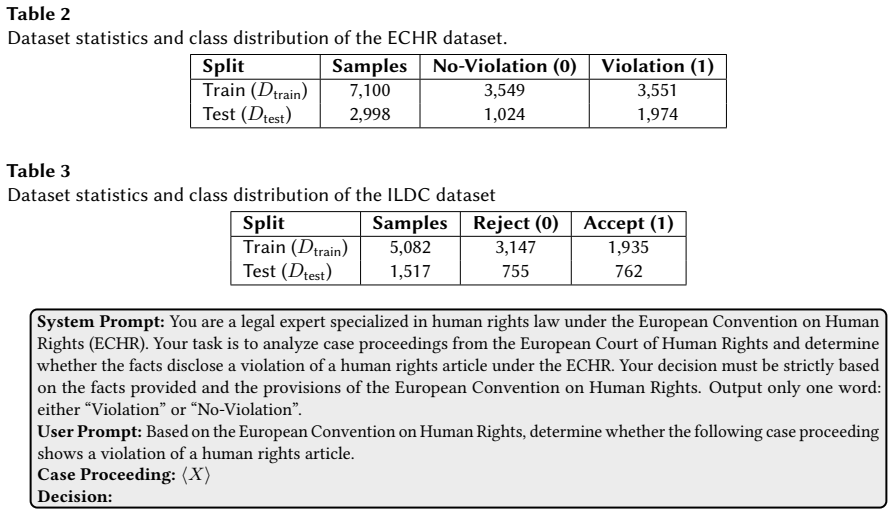
By extracting features from LLMs' internal artifacts and training separate classifiers on those features, it is possible to identify incorrect LLM outputs on legal classification tasks including bail decision prediction and statute violation prediction.
What carries the argument
Features derived from LLM internal artifacts, used to train downstream error-detection classifiers.
If this is right
- LLM-based legal systems can incorporate these artifact-based detectors to flag potential mistakes before outputs are used.
- The approach improves reliability of classification without retraining or altering the original LLM.
- Detection works for both bail decision prediction and statute violation prediction.
Where Pith is reading between the lines
- The same internal signals might support error detection in other high-stakes domains if the underlying mechanism is not domain-specific.
- Developers could derive per-prediction scores directly from these artifacts rather than training separate models.
- The result points to a general property of LLMs where their own activations encode information about their accuracy.
Load-bearing premise
The two chosen legal tasks are representative enough that results on them indicate the method will succeed on other legal applications and other LLMs.
What would settle it
Finding that the internal-feature classifiers perform at chance level on a new legal classification task or on a different LLM architecture would falsify the central claim.
Figures


read the original abstract
Large Language Models (LLMs) are increasingly being adopted in the legal domain. However, despite their strong performance, LLMs are prone to generating incorrect or hallucinated outputs, raising serious concerns about their reliability in high-stakes domains such as law. Detecting the correctness of responses of LLM-based systems is therefore a critical challenge. In this work, we explore the potential of leveraging internal artifacts of LLM to detect the correctness of their predictions in legal-domain classification tasks. We develop approaches that utilize features derived from these internal artifacts to build downstream classifiers capable of identifying incorrect LLM outputs. We evaluate our approach on two representative legal classification tasks: bail decision prediction and statute violation prediction. Our experimental results demonstrate that LLMs' internal artifacts are reliable indicators for detecting incorrect predictions in legal classification tasks, and can be applied to enhance the reliability of LLM-based classification systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that internal artifacts of LLMs (such as hidden states or attention patterns) can be leveraged as features to train downstream classifiers that detect incorrect LLM predictions in legal-domain classification tasks. It evaluates the approach on two tasks—bail decision prediction and statute violation prediction—and reports that the artifacts serve as reliable indicators, enabling enhanced reliability for LLM-based legal classification systems.
Significance. If the results hold, the work offers a practical internal mechanism for flagging erroneous outputs in high-stakes legal applications, potentially reducing reliance on external verification and improving trustworthiness of LLMs in the legal domain.
major comments (1)
- [Abstract] Abstract: the claim that internal artifacts are 'reliable indicators for detecting incorrect predictions in legal classification tasks' (and can enhance reliability of LLM-based systems) rests on experiments with only two tasks. No cross-task, cross-domain, or cross-model validation is described, leaving the general scope of the reliability claim unsupported.
Simulated Author's Rebuttal
We thank the referee for highlighting the scope of our claims. We agree that the abstract's phrasing implies broader applicability than the two-task evaluation supports, and we will revise to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that internal artifacts are 'reliable indicators for detecting incorrect predictions in legal classification tasks' (and can enhance reliability of LLM-based systems) rests on experiments with only two tasks. No cross-task, cross-domain, or cross-model validation is described, leaving the general scope of the reliability claim unsupported.
Authors: We agree the abstract overstates generality. The two tasks (bail decision and statute violation prediction) were chosen as representative legal classification problems, but no cross-task, cross-domain, or cross-model experiments are reported. In revision we will (1) qualify the abstract to state that internal artifacts serve as reliable indicators on the two evaluated tasks and (2) add an explicit Limitations section discussing the need for broader validation before claiming domain-wide reliability. revision: yes
Circularity Check
No circularity: empirical feature-based classifier training is independent of target labels
full rationale
The paper presents an empirical pipeline that extracts internal LLM artifacts as input features, then trains separate downstream classifiers to predict whether an LLM output is correct or incorrect. This is a standard supervised learning setup with no self-definitional loop (the correctness label is external ground truth, not derived from the artifacts), no fitted-input-called-prediction, and no load-bearing self-citations or imported uniqueness theorems. The two-task evaluation is a scope limitation rather than a circular reduction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakan- tan, P. Shyam, G. Sastry, A. Askell, et al., Language Models are Few-Shot Learn- ers, in: Advances in Neural Information Processing Systems, volume 33, Curran Asso- ciates, Inc., 2020, pp. 1877–1901. URL: https://proceedings.neurips.cc/paper_files/paper/2020/ file/1457c0d6bfc...
2020
-
[2]
Chowdhery, S
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, et al., PaLM: Scaling Language Modeling with Pathways, Journal of machine learning research 24 (2023) 1–113. URL: http://jmlr.org/papers/v24/22-1144.html
2023
-
[3]
N. Aletras, D. Tsarapatsanis, D. Preoţiuc-Pietro, V. Lampos, Predicting judicial decisions of the European Court of Human Rights: a Natural Language Processing perspective, PeerJ Computer Science 2 (2016) e93. doi:10.7717/peerj-cs.93
-
[4]
D. Datta, R. Mukherjee, A. Goswami, S. Ghosh, Advantages of Domain Knowledge Injection for Legal Document Summarization: A Case Study on Summarizing Indian Court Judgments in English and Hindi, arXiv preprint arXiv:2602.07382 (2026). doi: 10.48550/arXiv.2602.07382
-
[5]
A. Deroy, K. Ghosh, S. Ghosh, Investigating legal question generation using large language models, Artificial Intelligence and Law (2025) 1–39. doi:10.1007/s10506-025-09452-y
-
[6]
S. K. Nigam, D. P. Balaramamahanthi, S. Mishra, N. Shallum, K. Ghosh, A. Bhattacharya, NyayaAnu- mana and INLegalLlama: The Largest Indian Legal Judgment Prediction Dataset and Specialized Language Model for Enhanced Decision Analysis, in: Proceedings of the 31st International Con- ference on Computational Linguistics, 2025, pp. 11135–11160. URL: https://...
2025
-
[7]
ACM Transactions on Information Systems 43(2), 1–55 (2025) https://doi.org/10.1145/3703155
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, et al., A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, ACM Transactions on Information Systems 43 (2025) 1–55. doi:10.1145/3703155
-
[8]
S. Abdullahi, K. U. Danyaro, H. Chiroma, The rise of hallucination in large language models: systematic reviews, performance analysis and challenges, Cluster Computing 29 (2026) 124. doi:10.1007/s10586-025-05891-z
-
[9]
B. Snyder, M. Moisescu, M. B. Zafar, On Early Detection of Hallucinations in Factual Question Answering, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 2721–2732. doi:10.1145/3637528.3671796
-
[10]
D. Datta, M. K. Chilukuri, Y. Kumar, S. Ghosh, M. B. Zafar, Do LLM hallucination detectors suffer from low-resource effect?, in: Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, 2026, pp. 2959–2985. doi:10.18653/v1/2026.eacl-long.136
-
[11]
Z. Ji, D. Chen, E. Ishii, S. Cahyawijaya, Y. Bang, B. Wilie, P. Fung, LLM Internal States Reveal Hallucination Risk Faced With a Query, in: Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, 2024, pp. 88–104. doi:10.18653/v1/2024. blackboxnlp-1.6
-
[12]
C. Jiang, X. Yang, Legal Syllogism Prompting: Teaching Large Language Models for Legal Judgment Prediction, in: Proceedings of the 19th International Conference on Artificial Intelligence and Law (ICAIL), 2023, pp. 417–421. doi:10.1145/3594536.3595170
-
[13]
H. Dai, W. Zhao, L. Li, Enhancing Legal Judgment Prediction in LLMs via Legal Norms Integration, in: International Conference on Knowledge Science, Engineering and Management, Springer, 2025, pp. 202–214. doi:10.1007/978-981-95-3055-7_16
-
[14]
A. Sivakumar, A. Palanivel, K. Subbaraj, Predictive Modeling for Bail Applications in Indian Courts Using IndicBERT and HLDC Dataset, in: International Conference on Smart Data Intelligence, Springer, 2025, pp. 545–557. doi:10.1007/978-981-96-5265-5_42
-
[15]
C. Xiao, H. Zhong, Z. Guo, C. Tu, Z. Liu, M. Sun, Y. Feng, X. Han, Z. Hu, H. Wang, et al., CAIL2018: A Large-Scale Legal Dataset for Judgment Prediction, arXiv preprint arXiv:1807.02478 (2018). doi:10.48550/arXiv.1807.02478
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.02478 2018
-
[16]
J. Niklaus, I. Chalkidis, M. Stürmer, Swiss-Judgment-Prediction: A Multilingual Legal Judgment Prediction Benchmark, in: Proceedings of the natural legal language processing workshop 2021, Association for Computational Linguistics, 2021, pp. 19–35. doi:10.18653/v1/2021.nllp-1.3
-
[17]
I. Chalkidis, I. Androutsopoulos, N. Aletras, Neural Legal Judgment Prediction in English, in: A. Korhonen, D. Traum, L. Màrquez (Eds.), Proceedings of the 57th Annual Meeting of the Associ- ation for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, 2019, pp. 4317–4323. URL: https://aclanthology.org/P19-1424/. doi:10....
-
[18]
V. Malik, R. Sanjay, S. K. Nigam, K. Ghosh, S. K. Guha, A. Bhattacharya, A. Modi, ILDC for CJPE: Indian Legal Documents Corpus for Court Judgment Prediction and Explanation, in: C. Zong, F. Xia, W. Li, R. Navigli (Eds.), Proceedings of the 59th Annual Meeting of the Association for Com- putational Linguistics and the 11th International Joint Conference on...
-
[19]
Ian Davidson, Michael Livanos, Antoine Gourru, Peter Walker, Julien Velcin, and S
S. Farquhar, J. Kossen, L. Kuhn, Y. Gal, Detecting hallucinations in large language models using semantic entropy, Nature (2024). doi:10.1038/s41586-024-07421-0
-
[20]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
P. Manakul, A. Liusie, M. Gales, Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models, arXiv preprint arXiv:2303.08896 (2023). doi: 10.48550/arXiv. 2303.08896
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[21]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al., The Llama 3 Herd of Models, arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[22]
S. Yu, G. Kim, S. Kang, Context and Layers in Harmony: A Unified Strategy for Mitigating LLM Hallucinations, Mathematics 13 (2025) 1831. doi:10.3390/math13111831. 12
-
[23]
X. Song, K. Wang, P. Li, L. Yin, S. Liu, Demystifying the Roles of LLM Layers in Retrieval, Knowledge, and Reasoning, arXiv preprint arXiv:2510.02091 (2025)
arXiv 2025
-
[24]
Fawcett, An introduction to ROC analysis, Pattern recognition letters, 27 (2006) 861– 874
T. Fawcett, An introduction to ROC analysis, Pattern recognition letters 27 (2006) 861–874. doi:10.1016/j.patrec.2005.10.010
-
[25]
J. A. Hanley, B. J. McNeil, The meaning and use of the area under a receiver operating characteristic (ROC) curve, Radiology 143 (1982) 29–36. doi:10.1148/radiology.143.1.7063747. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.