Building Agent Harnesses for Scientific Curation from Multimodal Sources
Pith reviewed 2026-06-26 14:48 UTC · model grok-4.3
The pith
Beaver is an agent harness that extracts structured information from scientific papers at 81.0 on an attribute agreement score, beating frontier agents by 23 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
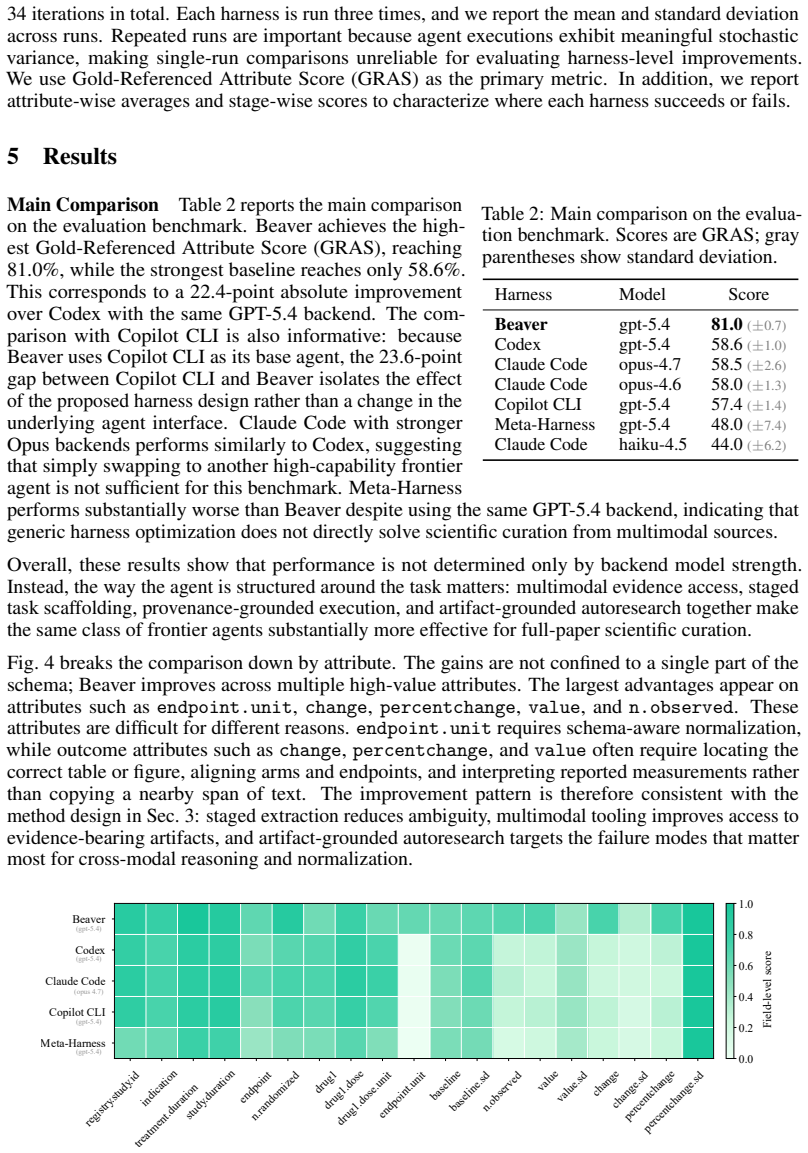
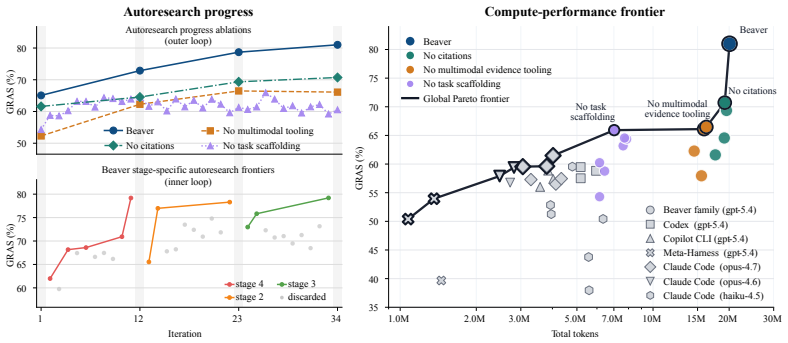
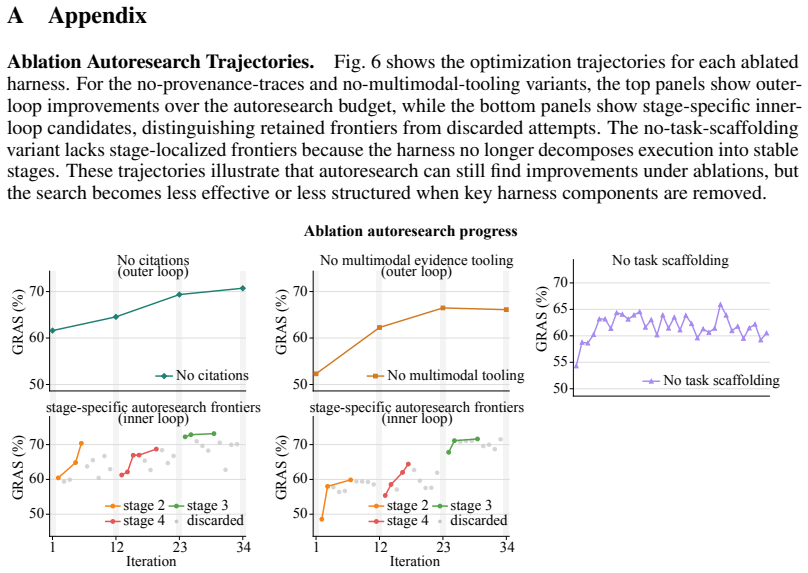
Beaver reaches 81.0 on Gold-Referenced Attribute Score (GRAS), an attribute-level measure of agreement with gold curated records, outperforming frontier agents by over 23 absolute points. Ablations show that task scaffolding, multimodal evidence tooling, and provenance traces each contribute meaningfully to performance, with largest gains on attributes requiring cross-modal reasoning and normalization.
What carries the argument
Beaver, an agent harness that combines a frontier agent with multimodal evidence tooling, task scaffolding, and artifact-grounded autoresearch to create a staged, auditable curation workflow.
Load-bearing premise
The gold curated records used for GRAS evaluation accurately capture the structured information that should be extracted from the multimodal sources in the test papers.
What would settle it
A new evaluation set of papers with independently created gold records where Beaver's GRAS score falls below 70 or matches frontier agents.
Figures



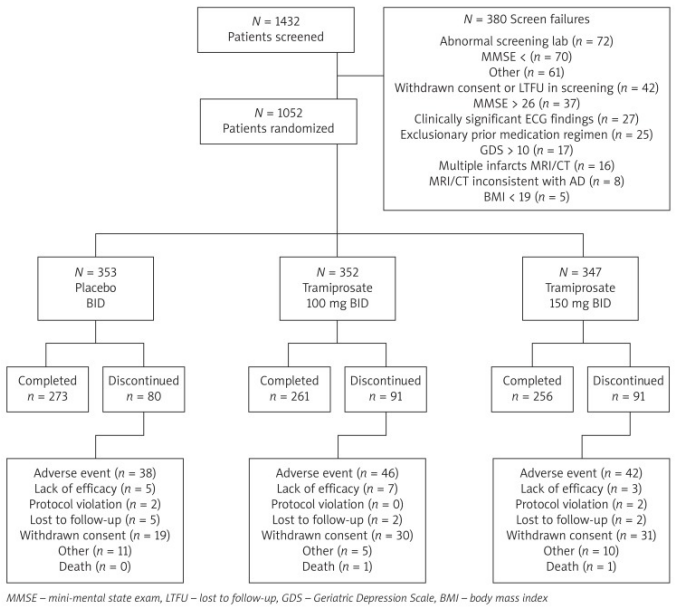
read the original abstract
Scientific discovery workflows often depend on structured curation from the literature. This is difficult for current agents because the key evidence is scattered across long text, dense tables, and figures, and the final records often require reasoning across multiple evidence fragments rather than copying a single span. We study scientific curation from multimodal sources and introduce Beaver, an agent harness that extracts structured information from scientific papers while preserving provenance to the supporting evidence. Beaver combines a frontier agent with multimodal evidence tooling, task scaffolding, and artifact-grounded autoresearch. These components turn curation into a staged, auditable workflow and enable an iterative evaluate--diagnose--revise loop, where persistent run artifacts expose stage-localized failures and guide harness updates. Experiments show that Beaver reaches 81.0 on Gold-Referenced Attribute Score (GRAS), an attribute-level measure of agreement with gold curated records, outperforming frontier agents by over 23 absolute points. Ablations show that task scaffolding, multimodal evidence tooling, and provenance traces each contribute meaningfully to performance, while attribute-level analysis shows the largest gains on high-value attributes that require cross-modal reasoning and normalization. These results show that, for scientific curation from papers with multimodal evidence, harness design is a central determinant of agent performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Beaver, an agent harness for extracting structured records from scientific papers containing multimodal evidence (text, tables, figures). Beaver augments a frontier agent with multimodal evidence tooling, task scaffolding, and provenance traces to produce auditable, staged workflows with an evaluate-diagnose-revise loop. The central empirical claim is that Beaver attains 81.0 on the Gold-Referenced Attribute Score (GRAS), outperforming frontier agents by more than 23 absolute points; ablations attribute gains to the harness components, especially on attributes requiring cross-modal reasoning and normalization.
Significance. If the evaluation is sound, the result would establish that harness-level design choices (scaffolding, tooling, provenance) can produce large, practically relevant gains on scientific curation tasks that current frontier agents handle poorly. The work also supplies a concrete, artifact-grounded methodology for iterative agent improvement that could be adopted more broadly.
major comments (2)
- [Experiments] Experiments section: The headline GRAS result (81.0, +23 over baselines) is reported without any description of the test corpus (size, selection criteria, paper domains), the protocol used to produce the gold curated records (inter-annotator agreement, explicit rules for cross-modal reconciliation, normalization conventions, or handling of missing/ambiguous evidence), or any statistical tests, confidence intervals, or error analysis. Because GRAS is defined solely by agreement with these gold records, the absence of this information makes the 23-point margin impossible to interpret as evidence of improved curation quality rather than annotation-style matching.
- [Ablations] Ablations and attribute-level analysis: The paper states that scaffolding, multimodal tooling, and provenance each contribute meaningfully and that largest gains occur on high-value cross-modal attributes, yet no per-component variance, run-level statistics, or breakdown of which specific attributes drove the reported deltas is supplied. Without these, the ablation claims remain unverified and cannot support the conclusion that harness design is the central determinant of performance.
minor comments (2)
- [Abstract] The abstract introduces the acronym GRAS without spelling it out on first use.
- Figure and table captions should explicitly state the number of papers/attributes evaluated and whether error bars or significance markers are shown.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the current manuscript lacks sufficient detail on the experimental corpus, gold-standard protocol, and ablation statistics, which limits interpretability of the reported gains. We will revise the manuscript to address these points fully.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline GRAS result (81.0, +23 over baselines) is reported without any description of the test corpus (size, selection criteria, paper domains), the protocol used to produce the gold curated records (inter-annotator agreement, explicit rules for cross-modal reconciliation, normalization conventions, or handling of missing/ambiguous evidence), or any statistical tests, confidence intervals, or error analysis. Because GRAS is defined solely by agreement with these gold records, the absence of this information makes the 23-point margin impossible to interpret as evidence of improved curation quality rather than annotation-style matching.
Authors: We agree that these methodological details are required to substantiate the headline result. In the revised manuscript we will add a dedicated subsection in Experiments that specifies: (i) the test corpus size, selection criteria, and scientific domains; (ii) the gold-record creation protocol, including inter-annotator agreement figures, explicit cross-modal reconciliation rules, normalization conventions, and handling of missing or ambiguous evidence; and (iii) statistical tests, confidence intervals, and error analysis. These additions will allow readers to evaluate whether the 23-point margin reflects genuine curation improvement. revision: yes
-
Referee: [Ablations] Ablations and attribute-level analysis: The paper states that scaffolding, multimodal tooling, and provenance each contribute meaningfully and that largest gains occur on high-value cross-modal attributes, yet no per-component variance, run-level statistics, or breakdown of which specific attributes drove the reported deltas is supplied. Without these, the ablation claims remain unverified and cannot support the conclusion that harness design is the central determinant of performance.
Authors: We concur that the ablation section requires additional quantitative support. The revised version will report per-component variance and run-level statistics for each harness element. We will also include a table or figure that breaks down performance deltas by individual attribute, explicitly identifying which cross-modal and normalization attributes drove the largest improvements. This will provide direct evidence linking the harness components to the observed gains. revision: yes
Circularity Check
No circularity: empirical agent evaluation against external gold standard
full rationale
The paper reports an empirical study comparing agent harnesses on a curation task, with the central metric (GRAS) defined as attribute-level agreement with independently produced gold curated records. No equations, fitted parameters, or derivations are presented as predictions. Ablations compare component contributions directly on the same held-out test set. No self-citation is invoked to establish uniqueness or forbid alternatives; the work does not rely on prior results by the same authors for its load-bearing claims. The evaluation is self-contained against external benchmarks (gold records) and does not reduce any result to its own inputs by construction. This is the standard honest outcome for an empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Schema-driven information extraction from heterogeneous tables
Fan Bai, Junmo Kang, Gabriel Stanovsky, Dayne Freitag, Mark Dredze, and Alan Ritter. Schema-driven information extraction from heterogeneous tables. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 10252–10273, Miami, Florida, USA, November 2024. Association for Comp...
-
[2]
Intent-aware schema generation and refinement for literature review tables
Vishakh Padmakumar, Joseph Chee Chang, Kyle Lo, Doug Downey, and Aakanksha Naik. Intent-aware schema generation and refinement for literature review tables. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23450–23472, Suzhou, China, Nove...
2025
-
[3]
URL https://aclanthology.org/2025
doi: 10.18653/v1/2025.findings-emnlp.1274. URL https://aclanthology.org/2025. findings-emnlp.1274/
-
[4]
Applications of model-based meta-analysis in drug development: Chan, peskov and song.Pharmaceutical Research, 39(8):1761–1777, 2022
Phyllis Chan, Kirill Peskov, and Xuyang Song. Applications of model-based meta-analysis in drug development: Chan, peskov and song.Pharmaceutical Research, 39(8):1761–1777, 2022
2022
-
[5]
Synthesizing scientific literature with retrieval-augmented language models.Nature, pages 1–7, 2026
Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D’Arcy, et al. Synthesizing scientific literature with retrieval-augmented language models.Nature, pages 1–7, 2026
2026
-
[6]
Toward reliable ad-hoc scientific information extraction: A case study on two materials dataset
Satanu Ghosh, Neal Brodnik, Carolina Frey, Collin Holgate, Tresa Pollock, Samantha Daly, and Samuel Carton. Toward reliable ad-hoc scientific information extraction: A case study on two materials dataset. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 15109–15123, Bangko...
-
[7]
URLhttps://aclanthology.org/2024.findings-acl.897/
2024
-
[8]
Anderson, Rickard Stureborg, Aman Tyagi, and Bhuwan Dhingra
Ghazal Khalighinejad, Sharon Scott, Ollie Liu, Kelly L. Anderson, Rickard Stureborg, Aman Tyagi, and Bhuwan Dhingra. Matvix: Multimodal information extraction from visually rich articles, 2024. URLhttps://arxiv.org/abs/2410.20494
arXiv 2024
-
[9]
Biocuration workflows and text mining: overview of the biocreative 2012 workshop track ii.Database, 2012:bas043, 2012
Zhiyong Lu and Lynette Hirschman. Biocuration workflows and text mining: overview of the biocreative 2012 workshop track ii.Database, 2012:bas043, 2012
2012
-
[10]
Biocreative iii interactive task: an overview.BMC bioinformatics, 12 (Suppl 8):S4, 2011
Cecilia N Arighi, Phoebe M Roberts, Shashank Agarwal, Sanmitra Bhattacharya, Gianni Cesareni, Andrew Chatr-Aryamontri, Simon Clematide, Pascale Gaudet, Michelle Gwinn Giglio, Ian Harrow, et al. Biocreative iii interactive task: an overview.BMC bioinformatics, 12 (Suppl 8):S4, 2011
2011
-
[11]
Thomas C. Wiegers, Allan Peter Davis, Jolene Wiegers, Daniela Sciaky, Fern Barkalow, Brent Wyatt, Melissa Strong, Roy McMorran, Sakib Abrar, and Carolyn J. Mattingly. Integrating AI-powered text mining from PubTator into the manual curation workflow at the comparative toxicogenomics database.Database, 2025:baaf013, 2025. doi: 10.1093/database/baaf013. URL...
-
[12]
Certara reports fourth quarter 2025 financial results; provides full year 2026 guidance
Certara, Inc. Certara reports fourth quarter 2025 financial results; provides full year 2026 guidance. SEC Exhibit 99.1 earnings release, February 2026. URL https://www.sec.gov/Archives/edgar/data/1827090/000182709026000008/ q42025earningsreleaseex99.htm
arXiv 2025
-
[13]
Qasa: advanced question answering on scientific articles
Yoonjoo Lee, Kyungjae Lee, Sunghyun Park, Dasol Hwang, Jaehyeon Kim, Hong-in Lee, and Moontae Lee. Qasa: advanced question answering on scientific articles. InInternational Conference on Machine Learning, pages 19036–19052. PMLR, 2023
2023
-
[14]
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, and Matt Gardner. A dataset of information-seeking questions and answers anchored in research papers. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, 11 Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors,Proceed- ings of the 2...
-
[15]
Huey, Rui Sheng, Saurabh Mehta, and Fei Wang
Xingbo Wang, Samantha L. Huey, Rui Sheng, Saurabh Mehta, and Fei Wang. Scidasynth: Interactive structured data extraction from scientific literature with large language model. Campbell Systematic Reviews, 21(4):e70073, 2025. doi: https://doi.org/10.1002/cl2.70073. URLhttps://onlinelibrary.wiley.com/doi/abs/10.1002/cl2.70073
-
[16]
GottBERT: a pure German language model
Marcin Kardas, Piotr Czapla, Pontus Stenetorp, Sebastian Ruder, Sebastian Riedel, Ross Taylor, and Robert Stojnic. AxCell: Automatic extraction of results from machine learning papers. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8580– 8...
-
[17]
A foundation model for human-ai collaboration in medical literature mining.Nature communications, 16(1):8361, 2025
Zifeng Wang, Lang Cao, Qiao Jin, Joey Chan, Nicholas Wan, Behdad Afzali, Hyun-Jin Cho, Chang-In Choi, Mehdi Emamverdi, Manjot K Gill, et al. A foundation model for human-ai collaboration in medical literature mining.Nature communications, 16(1):8361, 2025
2025
-
[18]
Yilun Zhao, Chengye Wang, Chuhan Li, and Arman Cohan. Can multimodal foundation models understand schematic diagrams? an empirical study on information-seeking QA over scientific papers. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 18598–1...
-
[19]
Pubtables-1m: Towards comprehensive table extraction from unstructured documents, 2021
Brandon Smock, Rohith Pesala, and Robin Abraham. Pubtables-1m: Towards comprehensive table extraction from unstructured documents, 2021. URL https://arxiv.org/abs/2110. 00061
2021
-
[20]
Fact or fiction: Verifying scientific claims
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. Fact or fiction: Verifying scientific claims. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7534–7550, Online, November
2020
-
[21]
doi: 10.18653/v1/2020.emnlp-main.609
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.609. URLhttps://aclanthology.org/2020.emnlp-main.609/
-
[22]
URL https://arxiv.org/ abs/2603.28052
Meta-harness: End-to-end optimization of model harnesses, 2026. URL https://arxiv.org/ abs/2603.28052
Pith/arXiv arXiv 2026
-
[23]
URLhttps://arxiv.org/abs/2603.25723
Natural-language agent harnesses, 2026. URLhttps://arxiv.org/abs/2603.25723
Pith/arXiv arXiv 2026
-
[24]
and collaborators
Chaitanya S. and collaborators. Harness-native software engineering: The control plane of coding agents, 2026. URL https://research.chaitanya.science/papers/ harness-native-software-engineering
2026
-
[25]
Harness design for long-running application development, mar 2026
Anthropic. Harness design for long-running application development, mar 2026. URL https: //www.anthropic.com/engineering/harness-design-long-running-apps
2026
-
[26]
Complicated table structure recognition, 2019
Zewen Chi, Heyan Huang, Heng-Da Xu, Houjin Yu, Wanxuan Yin, and Xian-Ling Mao. Complicated table structure recognition, 2019. URL https://arxiv.org/abs/1908.04729
arXiv 2019
-
[27]
Qi Zhang, Zhijia Chen, Huitong Pan, Cornelia Caragea, Longin Jan Latecki, and Eduard Dragut. SciER: An entity and relation extraction dataset for datasets, methods, and tasks in scientific documents. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages ...
-
[28]
Sciclaimeval: Cross-modal claim verification in scientific papers, 2026
Xanh Ho, Yun-Ang Wu, Sunisth Kumar, Tian Cheng Xia, Florian Boudin, Andre Greiner-Petter, and Akiko Aizawa. Sciclaimeval: Cross-modal claim verification in scientific papers, 2026. URLhttps://arxiv.org/abs/2602.07621
arXiv 2026
-
[29]
Image-based table recognition: Data, model, and evaluation
Xu Zhong, Elaheh ShafieiBavani, and Antonio Jimeno Yepes. Image-based table recognition: Data, model, and evaluation. InComputer Vision – ECCV 2020, 2020. URL https://arxiv. org/abs/1911.10683
arXiv 2020
-
[30]
Grits: Grid table similarity metric for table structure recognition, 2022
Brandon Smock, Rohith Pesala, and Robin Abraham. Grits: Grid table similarity metric for table structure recognition, 2022. URLhttps://arxiv.org/abs/2203.12555
arXiv 2022
-
[31]
Extractbench: A benchmark and evaluation methodology for complex structured extraction, 2026
Nick Ferguson, Josh Pennington, Narek Beghian, Aravind Mohan, Douwe Kiela, Sheshansh Agrawal, and Thien Hang Nguyen. Extractbench: A benchmark and evaluation methodology for complex structured extraction, 2026. URLhttps://arxiv.org/abs/2602.12247
arXiv 2026
-
[32]
autoresearch
Andrej Karpathy. autoresearch. GitHub repository, 2026. URL https://github.com/ karpathy/autoresearch
2026
-
[33]
Pmc open access subset
National Library of Medicine. Pmc open access subset. https://pmc.ncbi.nlm.nih.gov/ tools/openftlist/, 2003. Last modified September 11, 2025
2003
-
[34]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
Pith/arXiv arXiv 2026
-
[35]
Cte: A dataset for contextualized table extraction
A Gemelli, E Vivoli, S Marinai, et al. Cte: A dataset for contextualized table extraction. In CEUR WORKSHOP PROCEEDINGS, volume 3365, pages 197–208. CEUR-WS, 2023
2023
-
[36]
Harsh Desai, Pratik Kayal, and Mayank Singh. Tablex: A benchmark dataset for structure and content information extraction from scientific tables.CoRR, abs/2105.06400, 2021. URL https://arxiv.org/abs/2105.06400
arXiv 2021
-
[37]
Yi Luan, Luheng He, Mari Ostendorf, and Hannaneh Hajishirzi. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3219–3232, B...
-
[38]
SciREX: A challenge dataset for document-level information extraction
Sarthak Jain, Madeleine van Zuylen, Hannaneh Hajishirzi, and Iz Beltagy. SciREX: A challenge dataset for document-level information extraction. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7506–7516, Online, July 2020. Association f...
-
[39]
SciNLP: A domain- specific benchmark for full-text scientific entity and relation extraction in NLP
Decheng Duan, Jitong Peng, Yingyi Zhang, and Chengzhi Zhang. SciNLP: A domain- specific benchmark for full-text scientific entity and relation extraction in NLP. In Chris- tos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Pro- ceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages 1447...
-
[40]
Benjamin Nye, Junyi Jessy Li, Roma Patel, Yinfei Yang, Iain Marshall, Ani Nenkova, and Byron Wallace. A corpus with multi-level annotations of patients, interventions and outcomes to support language processing for medical literature. In Iryna Gurevych and Yusuke Miyao, editors,Proceedings of the 56th Annual Meeting of the Association for Computational Li...
-
[41]
Biored: a rich biomedical relation extraction dataset.Briefings in Bioinformatics, 23(5):bbac282, 2022
Ling Luo, Po-Ting Lai, Chih-Hsuan Wei, Cecilia N Arighi, and Zhiyong Lu. Biored: a rich biomedical relation extraction dataset.Briefings in Bioinformatics, 23(5):bbac282, 2022
2022
-
[42]
cpapers: A dataset of situated and multimodal interactive conversations in scien- tific papers
Anirudh Sundar, Jin Xu, William Gay, Christopher Richardson, and Larry Heck. cpapers: A dataset of situated and multimodal interactive conversations in scien- tific papers. InAdvances in Neural Information Processing Systems 37 (NeurIPS
-
[43]
Datasets and Benchmarks Track, 2024. doi: 10.52202/079017-2119. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 7a19a9d527ed544d1272f07b0f8f934e-Abstract-Datasets_and_Benchmarks_Track. html
-
[44]
Self-refine: Iterative refinement with self-feedback, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback, 2023. URL https://arxiv.org/abs/2303.17651
Pith/arXiv arXiv 2023
-
[45]
Metascale: Test-time scaling with evolving meta-thoughts.arXiv preprint arXiv:2503.13447, 2025
Qin Liu, Wenxuan Zhou, Nan Xu, James Y Huang, Fei Wang, Sheng Zhang, Hoifung Poon, and Muhao Chen. Metascale: Test-time scaling with evolving meta-thoughts.arXiv preprint arXiv:2503.13447, 2025
arXiv 2025
-
[46]
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. Textgrad: Automatic "differentiation" via text, 2024. URL https://arxiv. org/abs/2406.07496
Pith/arXiv arXiv 2024
-
[47]
Feedback descent: Open-ended text optimization via pairwise comparison, 2025
Yoonho Lee, Joseph Boen, and Chelsea Finn. Feedback descent: Open-ended text optimization via pairwise comparison, 2025. URLhttps://arxiv.org/abs/2511.07919
arXiv 2025
-
[48]
Adaevolve: Adaptive llm driven zeroth-order optimization, 2026
Mert Cemri, Shubham Agrawal, Akshat Gupta, Shu Liu, Audrey Cheng, Qiuyang Mang, Ashwin Naren, Lutfi Eren Erdogan, Koushik Sen, Matei Zaharia, Alex Dimakis, and Ion Stoica. Adaevolve: Adaptive llm driven zeroth-order optimization, 2026. URL https://arxiv.org/ abs/2602.20133
arXiv 2026
-
[49]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
Pith/arXiv arXiv 2025
-
[50]
Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl- Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. Gepa: Reflective prompt evolution can outperform reinforcement learning, 2026. URL https: //a...
Pith/arXiv arXiv 2026
-
[51]
{label}: row {center_row}, y = {y_val:.2f}
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. Dspy: Compiling declarative language model calls into self-improving pipelines, 2023. URLhttps://arxiv.org/abs/2310.03714. 14 A Appendix Ablatio...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.