FiLM-Coordinated Dual-Branch Transformer for Global-Local Dependency Modeling in Language Modeling
Pith reviewed 2026-06-26 14:26 UTC · model grok-4.3
The pith
A dual-branch Transformer with bidirectional FiLM coordination models global and local dependencies more effectively than single self-attention pathways.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
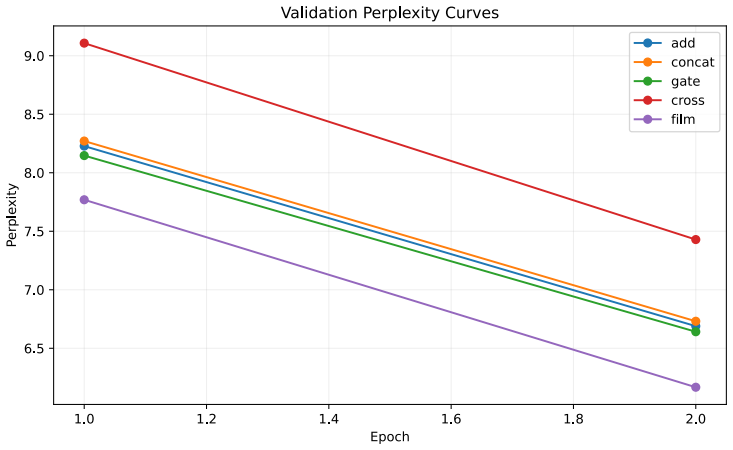
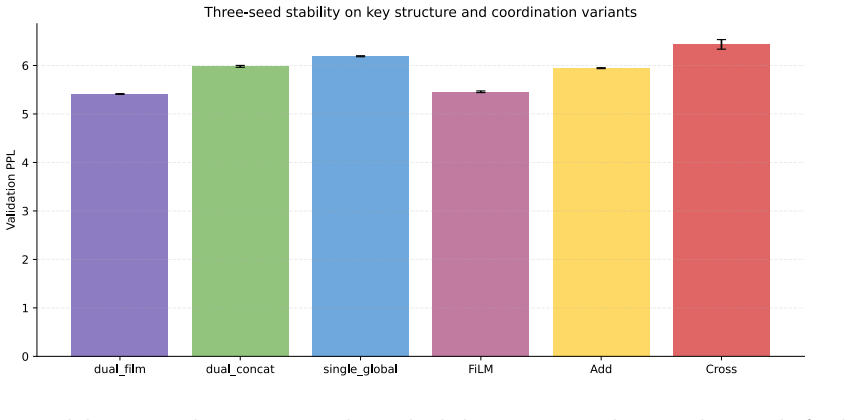
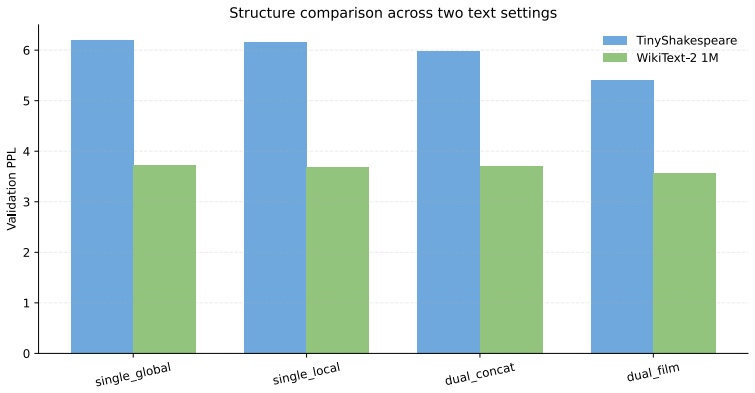
The central claim is that a Transformer layer containing separate global and local branches coordinated by a bidirectional FiLM module, in which each branch produces per-channel scaling and shifting parameters to modulate the other, yields better language-modeling performance than a single self-attention pathway under fixed lightweight budgets; on TinyShakespeare and a 1M-character WikiText-2 subset the full model records the strongest results among same-width structural baselines, while mechanistic checks confirm that the modulation is input-dependent, layer-dependent, and channel-selective rather than static.
What carries the argument
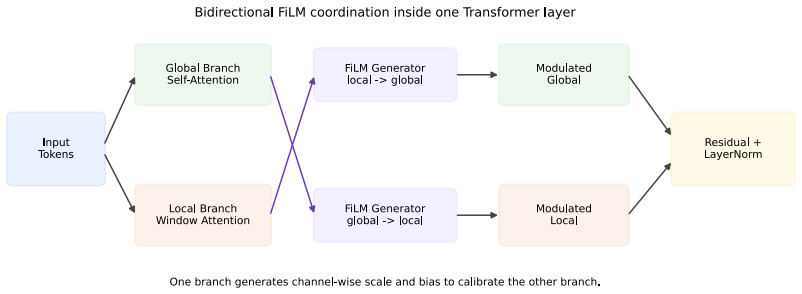
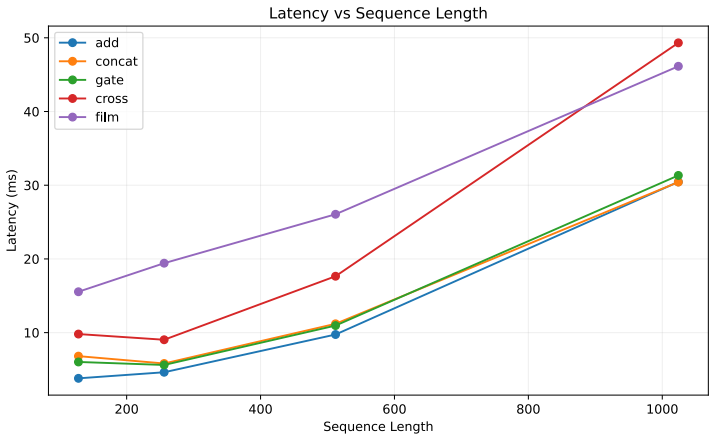
Bidirectional FiLM module in which each branch generates per-channel scaling and shifting parameters to condition the other branch.
If this is right
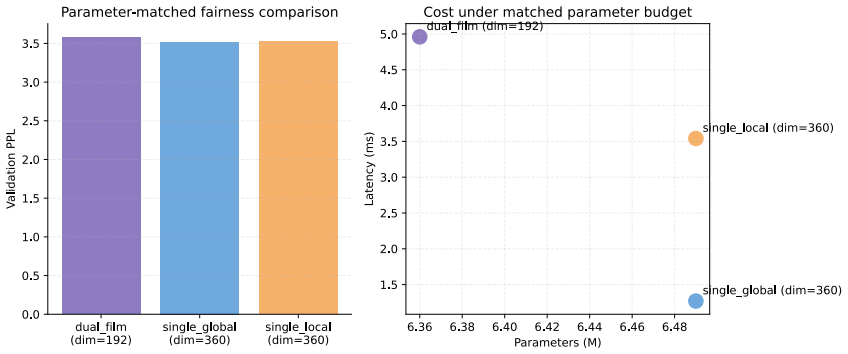
- The full dual-branch FiLM model records the best results among same-width structural baselines on TinyShakespeare and the 1M-character WikiText-2 subset.
- Weakened dual-branch variants that omit full bidirectional FiLM underperform the complete model.
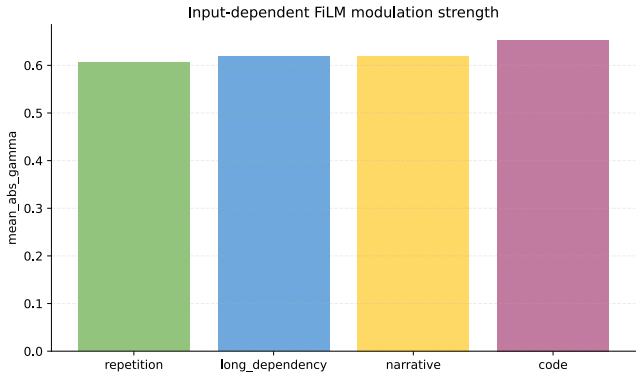
- Mechanistic analyses show FiLM produces input-dependent, layer-dependent, and channel-selective modulation rather than static scaling.
- Multi-seed runs indicate the performance gains are stable.
Where Pith is reading between the lines
- The design may transfer to other sequence modeling settings where global and local patterns compete, provided the branches continue to learn distinct views.
- Further gains would require addressing the parameter-efficiency gap noted when comparing against widened single-branch baselines.
- Ablations that replace FiLM with learned token-level cross-attention between branches could test whether channel-wise modulation is strictly preferable.
Load-bearing premise
The two branches supply meaningfully different global and local dependency views of the same input, so channel-wise FiLM calibration is more suitable than heavy token-level interaction or simple concatenation.
What would settle it
A parameter-matched single-branch Transformer achieving equal or higher accuracy than the dual-branch FiLM model on TinyShakespeare or the WikiText-2 subset would falsify the claimed advantage.
Figures
read the original abstract
Standard Transformers use a single self-attention pathway to model both global dependencies and local patterns, creating tension between long-range structural reasoning and fine-grained local representation learning. We propose a FiLM-coordinated dual-branch Transformer for language modeling, where each layer explicitly contains a global branch and a local branch, and feature-wise linear modulation (FiLM) is used for dynamic cross-branch coordination instead of simple concatenation or static addition. The key idea is that the two branches represent different dependency views of the same input, making channel-wise calibration more suitable than heavy token-level interaction. We therefore design a bidirectional FiLM module in which each branch generates per-channel scaling and shifting parameters to condition the other. Experiments on multiple small-scale language modeling settings show that the proposed structure consistently outperforms same-width single-branch baselines and weakened dual-branch variants under a fixed lightweight configuration. On TinyShakespeare and a 1M-character subset of WikiText-2, the full dual-branch FiLM model achieves the best results among same-width structural baselines. Multi-seed results support the stability of the gains, while mechanistic analyses show that FiLM learns input-dependent, layer-dependent, and channel-selective modulation patterns rather than static scaling. Parameter-matched widened single-branch baselines also indicate that the current design still leaves room for improvement in parameter efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a FiLM-coordinated dual-branch Transformer for language modeling. Each layer contains an explicit global branch and local branch, coordinated via a bidirectional FiLM module in which each branch generates per-channel scaling and shifting parameters to condition the other. This replaces simple concatenation or static addition. Experiments on TinyShakespeare and a 1M-character WikiText-2 subset show the full model outperforming same-width single-branch baselines and weakened dual-branch variants under a fixed lightweight configuration. Multi-seed results support stability, and mechanistic analyses indicate input-, layer-, and channel-dependent modulation rather than static scaling. Parameter-matched widened single-branch baselines are also reported.
Significance. If the results hold under fuller statistical reporting, the design offers a concrete mechanism for separating global and local dependency modeling while using lightweight channel-wise calibration. Credit is due for the explicit controls (weakened variants, parameter-matched widened baselines) and the mechanistic analysis demonstrating adaptive rather than static FiLM behavior. These elements help isolate the contribution of the coordination strategy and could inform subsequent work on structured dependency modeling in small-scale or efficiency-focused language modeling settings.
major comments (1)
- [Experiments] Experiments section (as summarized in abstract): the central claim of consistent outperformance and multi-seed stability is presented without error bars, p-values, or explicit baseline implementation details (e.g., exact layer widths, attention head counts, or data preprocessing rules). This makes it difficult to assess whether the reported gains exceed what would be expected from random variation, even though the abstract states that multi-seed results support stability.
minor comments (1)
- [Abstract] Abstract: specific numerical results (e.g., perplexity deltas) are not provided to quantify the claimed outperformance, which would aid immediate assessment of effect size.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point-by-point below and commit to revisions that strengthen the experimental reporting.
read point-by-point responses
-
Referee: [Experiments] Experiments section (as summarized in abstract): the central claim of consistent outperformance and multi-seed stability is presented without error bars, p-values, or explicit baseline implementation details (e.g., exact layer widths, attention head counts, or data preprocessing rules). This makes it difficult to assess whether the reported gains exceed what would be expected from random variation, even though the abstract states that multi-seed results support stability.
Authors: We agree that the current presentation would benefit from fuller statistical reporting and implementation details to allow readers to better evaluate the stability and significance of the gains. The multi-seed experiments were performed (as noted in the abstract and manuscript), but error bars and p-values were omitted from the main results tables. In the revised version we will: (1) report mean and standard deviation across seeds for all models, (2) add p-values for the key pairwise comparisons against baselines, and (3) expand the experimental setup subsection to explicitly list layer widths, attention head counts, embedding dimensions, and the exact data preprocessing/tokenization steps used for TinyShakespeare and the WikiText-2 subset. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a FiLM-coordinated dual-branch Transformer architecture and supports its claims exclusively through empirical comparisons on TinyShakespeare and a WikiText-2 subset, including controls against same-width single-branch baselines and weakened dual-branch variants. No equations, fitted parameters, or first-principles derivations are described that would reduce reported gains to circular definitions or self-citations. The central premise (distinct global/local dependency views) is treated as a modeling assumption validated by mechanistic analysis and multi-seed stability rather than derived from prior self-cited results. The argument is self-contained against external benchmarks via explicit experimental design.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MoBA: Mixture of Block Attention for Long-Context LLMs.arXiv preprint arXiv:2502.13140, 2025
Moonshot AI. MoBA: Mixture of Block Attention for Long-Context LLMs.arXiv preprint arXiv:2502.13140, 2025
arXiv 2025
-
[2]
DeepSeek-AI. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Lan- guage Model.arXiv preprint arXiv:2405.04434, 2024
Pith/arXiv arXiv 2024
-
[3]
Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
Mistral AI. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
Pith/arXiv arXiv 2023
-
[4]
Jamba: A Hybrid Transformer-Mamba Language Model.arXiv preprint arXiv:2403.19887, 2024
AI21 Labs. Jamba: A Hybrid Transformer-Mamba Language Model.arXiv preprint arXiv:2403.19887, 2024
Pith/arXiv arXiv 2024
-
[5]
FiLM: Visual Reasoning with a General Conditioning Layer
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. FiLM: Visual Reasoning with a General Conditioning Layer. InAAAI, 2018
2018
-
[6]
Jingyang Yuan, Huazuo Gao, et al. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention.arXiv preprint arXiv:2502.11089, 2025
Pith/arXiv arXiv 2025
-
[7]
Generating Long Sequences with Sparse Transformers.arXiv preprint arXiv:1904.10509, 2019
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating Long Sequences with Sparse Transformers.arXiv preprint arXiv:1904.10509, 2019
Pith/arXiv arXiv 1904
-
[8]
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The Long-Document Trans- former.arXiv preprint arXiv:2004.05150, 2020
Pith/arXiv arXiv 2004
-
[9]
GQA: Training Generalized Multi-Query Transformer Models from Multi- Head Checkpoints
Joshua Ainslie et al. GQA: Training Generalized Multi-Query Transformer Models from Multi- Head Checkpoints. InEMNLP, 2023
2023
-
[10]
Jamba-1.5: Technical Report.arXiv preprint arXiv:2408.12570, 2024
AI21 Labs. Jamba-1.5: Technical Report.arXiv preprint arXiv:2408.12570, 2024
arXiv 2024
-
[11]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research, 2022
2022
-
[12]
Mixtral of Experts.arXiv preprint arXiv:2401.04088, 2024
Albert Jiang et al. Mixtral of Experts.arXiv preprint arXiv:2401.04088, 2024
Pith/arXiv arXiv 2024
-
[13]
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
Xun Huang and Serge Belongie. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization. InICCV, 2017
2017
-
[14]
A Style-Based Generator Architecture for Gener- ative Adversarial Networks
Tero Karras, Samuli Laine, and Timo Aila. A Style-Based Generator Architecture for Gener- ative Adversarial Networks. InCVPR, 2019
2019
-
[15]
Adding Conditional Control to Text-to- Image Diffusion Models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding Conditional Control to Text-to- Image Diffusion Models. InICCV, 2023. 14
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.