Odoriko: A Shape-Aware Multimodal Diffusion Framework for Human Motion
Pith reviewed 2026-06-26 14:37 UTC · model grok-4.3
The pith
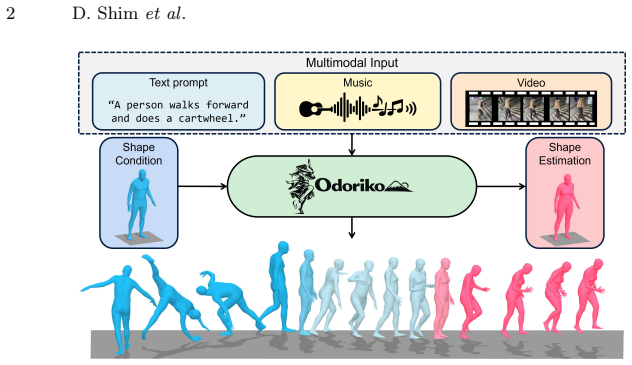
A single diffusion model generates motion consistent with the mover's body shape and gender from text, music, or video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
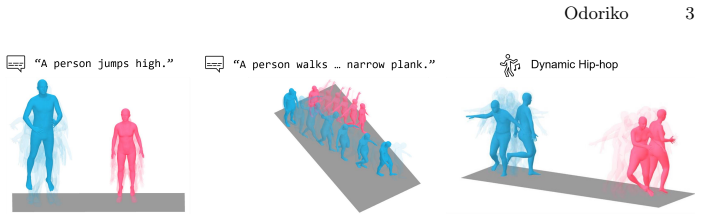
Odoriko is the first unified multimodal motion generation framework that reflects subject bio-morphological information directly in synthesized motion output. Rather than averaging over subject variation, Odoriko generates motion that is consistent with who is moving, not just what they are asked to do, across text, music, and video conditions within a single model. When explicit morphological information is unavailable, Odoriko additionally recovers subject morphology alongside motion, unifying estimation and generation in one framework.
What carries the argument
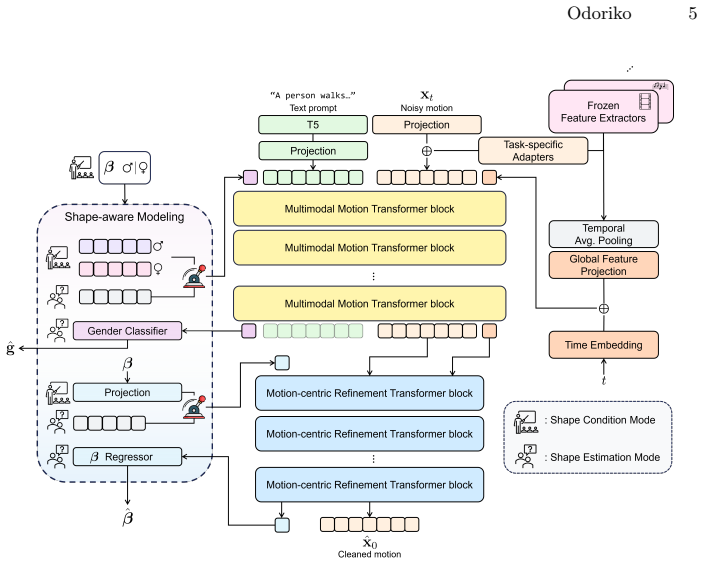
Shape-aware multimodal diffusion model that conditions motion synthesis on bio-morphological factors such as gender and body shape.
If this is right
- Matches or exceeds prior specialized models on text-to-motion, music-to-dance, and video-to-motion benchmarks.
- Enables morphology-consistent generation that no existing unified framework supports.
- Unifies morphology estimation and motion generation within one model.
- Produces motion outputs that reflect who is moving rather than averaging over subjects.
Where Pith is reading between the lines
- Applications in animation and virtual reality could use the model to create personalized avatars without building separate body-type networks.
- The approach may extend to real-time systems where body measurements are estimated from a single video frame.
- Testing on body shapes far outside the training distribution would reveal how far the conditioning generalizes.
Load-bearing premise
Morphological factors such as gender and body shape produce distinct kinematic signatures that can be directly reflected in a unified diffusion model without requiring separate per-modality or per-body-type architectures.
What would settle it
Generate motions for the same prompt but with different body shapes and check whether measurable kinematic differences appear in joint trajectories or velocities that align with real captured data for those shapes.
Figures
read the original abstract
Human motion generation has been widely studied across diverse input modalities, text, music, and video, and recent efforts have unified these into single multimodal frameworks. However, while morphological factors such as gender and body shape are known to produce distinct kinematic signatures, no existing unified framework incorporates this into generation, treating all subjects as morphologically equivalent. We present Odoriko, the first unified multimodal motion generation framework that reflects subject bio-morphological information directly in synthesized motion output. Rather than averaging over subject variation, Odoriko generates motion that is consistent with who is moving, not just what they are asked to do, across text, music, and video conditions within a single model. When explicit morphological information is unavailable, Odoriko additionally recovers subject morphology alongside motion, unifying estimation and generation in one framework. Extensive experiments across text-to-motion, music-to-dance, and video-to-motion benchmarks demonstrate that Odoriko matches or exceeds prior specialized models on standard metrics, while enabling morphology-consistent generation that no existing unified framework supports.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Odoriko, the first unified multimodal diffusion framework for human motion generation that directly incorporates subject bio-morphological parameters (gender, body shape) to synthesize motion consistent with the individual across text, music, and video conditioning within a single model. It further unifies generation with morphology estimation when explicit shape information is unavailable. The central claim is that this approach produces subject-specific kinematic signatures rather than averaging over morphological variation, and that experiments on standard text-to-motion, music-to-dance, and video-to-motion benchmarks show performance matching or exceeding prior specialized models while adding morphology consistency not supported by existing unified frameworks.
Significance. If the empirical results hold, the work would address a recognized gap in multimodal motion synthesis by moving beyond morphologically agnostic models. Incorporating biomechanical factors into a single diffusion backbone could improve realism for personalized animation and interaction tasks. The joint estimation-generation capability is a practical addition that aligns with established observations that morphology influences kinematics.
major comments (1)
- [Abstract] Abstract: the claim that Odoriko 'matches or exceeds prior specialized models on standard metrics' is presented without any numerical values, tables, ablation studies, or error bars. This absence prevents evaluation of whether the central empirical claim is supported and whether morphology-consistent generation comes at any cost to standard metrics.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for clearer empirical support in the abstract. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Odoriko 'matches or exceeds prior specialized models on standard metrics' is presented without any numerical values, tables, ablation studies, or error bars. This absence prevents evaluation of whether the central empirical claim is supported and whether morphology-consistent generation comes at any cost to standard metrics.
Authors: We agree that the abstract, as written, states the performance claim without supporting numbers. The full manuscript (Sections 4–5 and Tables 1–4) contains the requested quantitative comparisons, including FID, R-Precision, Diversity, and Multimodality scores on HumanML3D, AIST++, and other benchmarks, plus ablations isolating the morphology conditioning and error bars from multiple runs. These results show Odoriko matching or exceeding specialized baselines while adding morphology consistency. To directly address the concern, we will revise the abstract to include 2–3 key numerical highlights (e.g., average FID improvement and morphology consistency metric) and reference the tables. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical multimodal diffusion model for human motion generation that conditions on morphological parameters. No derivation chain, equations, or first-principles predictions are described in the abstract or provided text that reduce to inputs by construction, fitted parameters renamed as predictions, or self-citation load-bearing arguments. The central claim rests on model architecture and benchmark evaluations rather than any self-referential mathematical reduction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: European Conference on Computer Vision
Árbol, B.R., Casas, D.: Bodyshapegpt: Smpl body shape manipulation with llms. In: European Conference on Computer Vision. pp. 388–396. Springer (2024) 2, 4
2024
-
[2]
Perception & psychophysics23(2), 145–152 (1978) 2, 4, 24
Barclay, C.D., Cutting, J.E., Kozlowski, L.T.: Temporal and spatial factors in gait perception that influence gender recognition. Perception & psychophysics23(2), 145–152 (1978) 2, 4, 24
1978
-
[3]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Bian, Y., Zeng, A., Ju, X., Liu, X., Zhang, Z., Liu, W., Xu, Q.: Motioncraft: Craft- ing whole-body motion with plug-and-play multimodal controls. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 1880–1888 (2025) 4, 10, 11
2025
-
[4]
IEEE transactions on pattern analysis and machine intelligence43(1), 172–186 (2019) 7
Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: Openpose: Realtime multi- person 2d pose estimation using part affinity fields. IEEE transactions on pattern analysis and machine intelligence43(1), 172–186 (2019) 7
2019
-
[5]
arXiv preprint arXiv:2502.02063 (2025) 25
Chang, C.J., Liu, Q.T., Zhou, H., Pavlovic, V., Kapadia, M.: Casim: Com- posite aware semantic injection for text to motion generation. arXiv preprint arXiv:2502.02063 (2025) 25
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, X., Jiang, B., Liu, W., Huang, Z., Fu, B., Chen, T., Yu, G.: Executing your commands via motion diffusion in latent space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18000–18010 (2023) 4, 10
2023
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence
Cheng, H.K., Ishii, M., Hayakawa, A., Shibuya, T., Schwing, A., Mitsufuji, Y.: Mmaudio: Taming multimodal joint training for high-quality video-to-audio syn- thesis. In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence. pp. 28901–28911 (2025) 7, 25
2025
-
[8]
Choutas, V., Müller, L., Huang, C.H.P., Tang, S., Tzionas, D., Black, M.J.: Accu- rate3dbodyshaperegressionusingmetricandsemanticattributes.In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2718–2728 (2022) 2, 4, 13
2022
-
[9]
Perception7(4), 393–405 (1978) 2, 4
Cutting, J.E.: Generation of synthetic male and female walkers through manipu- lation of a biomechanical invariant. Perception7(4), 393–405 (1978) 2, 4
1978
-
[10]
In: European Confer- ence on Computer Vision (2024) 1, 4, 10, 11
Dai, W., Chen, L.H., Wang, J., Liu, J., Dai, B., Tang, Y.: Motionlcm: Real-time controllable motion generation via latent consistency model. In: European Confer- ence on Computer Vision (2024) 1, 4, 10, 11
2024
-
[11]
Jukebox: A Generative Model for Music
Dhariwal, P., Jun, H., Payne, C., Kim, J.W., Radford, A., Sutskever, I.: Jukebox: A generative model for music. arXiv preprint arXiv:2005.00341 (2020) 7
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[12]
Advances in neural information processing systems34, 8780–8794 (2021) 21
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021) 21
2021
-
[13]
In: Forty-first international conference on machine learning (2024) 7, 21, 25
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 7, 21, 25
2024
-
[14]
In: 16 D
Gong, K., Lian, D., Chang, H., Guo, C., Jiang, Z., Zuo, X., Mi, M.B., Wang, X.: Tm2d: Bimodality driven 3d dance generation via music-text integration. In: 16 D. Shimet al. Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9942–9952 (2023) 10
2023
-
[15]
In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision
Gralnik, O., Gafni, G., Shamir, A.: Semantify: Simplifying the control of 3d mor- phable models using clip. In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision. pp. 14554–14564 (2023) 4
2023
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guo, C., Mu, Y., Javed, M.G., Wang, S., Cheng, L.: Momask: Generative masked modeling of 3d human motions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1900–1910 (2024) 1, 4, 5, 10, 11, 12, 13, 22
1900
-
[17]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating diverse and natural 3d human motions from text. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 5152–5161 (2022) 5, 9, 10, 11, 20, 23, 26, 27
2022
-
[18]
In: Proceedings of the 28th ACM international conference on multimedia
Guo, C., Zuo, X., Wang, S., Zou, S., Sun, Q., Deng, A., Gong, M., Cheng, L.: Action2motion: Conditioned generation of 3d human motions. In: Proceedings of the 28th ACM international conference on multimedia. pp. 2021–2029 (2020) 9
2021
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Guo, Z., Hu, Z., Soh, D.W., Zhao, N.: Motionlab: Unified human motion gener- ation and editing via the motion-condition-motion paradigm. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13869–13879 (2025) 4
2025
-
[20]
Advances in neural information processing systems33, 6840–6851 (2020) 6, 9, 25
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 6, 9, 25
2020
-
[21]
In: NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications (2021) 21
Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications (2021) 21
2021
-
[22]
ACM Transactions on Graphics (TOG)36(4), 1–13 (2017) 1
Holden, D., Komura, T., Saito, J.: Phase-functioned neural networks for character control. ACM Transactions on Graphics (TOG)36(4), 1–13 (2017) 1
2017
-
[23]
ACM Transactions on Graphics (2016) 6
Holden, D., Saito, J., Komura, T.: A deep learning framework for character motion synthesis and editing. ACM Transactions on Graphics (2016) 6
2016
-
[24]
Archives of physical medicine and rehabilitation95(10), 1860–1869 (2014) 2, 4, 13, 24
Hsue, B.J., Su, F.C.: Effects of age and gender on dynamic stability during stair descent. Archives of physical medicine and rehabilitation95(10), 1860–1869 (2014) 2, 4, 13, 24
2014
-
[25]
6m: Large scale datasets and predictive methods for 3d human sensing in natural environments
Ionescu, C., Papava, D., Olaru, V., Sminchisescu, C.: Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelligence36(7), 1325–1339 (2013) 10, 27
2013
-
[26]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kaufmann, M., Song, J., Guo, C., Shen, K., Jiang, T., Tang, C., Zárate, J.J., Hilliges, O.: Emdb: The electromagnetic database of global 3d human pose and shape in the wild. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14632–14643 (2023) 10, 22, 27
2023
-
[27]
Kim, J., Oh, H., Kim, S., Tong, H., Lee, S.: A brand new dance partner: Music- conditionedpluralisticdancingcontrolledbymultipledancegenres.In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3490–3500 (2022) 1, 11
2022
-
[28]
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: In- ternational Conference on Machine Learning
Lee, W., Jeong, J., Moon, T., Kim, H.J., Kim, J., Kim, G., Lee, B.U.: How to move your dragon: Text-to-motion synthesis for large-vocabulary objects. In: In- ternational Conference on Machine Learning. pp. 33110–33128. PMLR (2025) 20 Odoriko 17
2025
-
[30]
ACM Transactions on Graphics (TOG)42(6), 1–11 (2023) 1
Li, J., Wu, J., Liu, C.K.: Object motion guided human motion synthesis. ACM Transactions on Graphics (TOG)42(6), 1–11 (2023) 1
2023
-
[31]
In: International Conference on Computer Vision (2025) 4, 6, 10, 11, 12, 21, 26
Li, J., Cao, J., Zhang, H., Rempe, D., Kautz, J., Iqbal, U., Yuan, Y.: Genmo: A generalist model for human motion. In: International Conference on Computer Vision (2025) 4, 6, 10, 11, 12, 21, 26
2025
-
[32]
arXiv preprint arXiv:2410.20389 (2024) 1, 6, 11
Li, R., Zhang, H., Zhang, Y., Zhang, Y., Zhang, Y., Guo, J., Zhang, Y., Li, X., Liu,Y.:Lodge++:High-qualityandlongdancegenerationwithvividchoreography patterns. arXiv preprint arXiv:2410.20389 (2024) 1, 6, 11
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, R., Zhang, Y., Zhang, Y., Zhang, H., Guo, J., Zhang, Y., Liu, Y., Li, X.: Lodge: A coarse to fine diffusion network for long dance generation guided by the characteristic dance primitives. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1524–1534 (2024) 1, 4, 6, 10, 11, 22
2024
-
[34]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision
Li, R., Zhao, J., Zhang, Y., Su, M., Ren, Z., Zhang, H., Tang, Y., Li, X.: Finedance: A fine-grained choreography dataset for 3d full body dance generation. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision. pp. 10234– 10243 (2023) 4, 8, 10, 22, 27
2023
-
[35]
In: Proceedings of the IEEE/CVF international conference on computer vision
Li, R., Yang, S., Ross, D.A., Kanazawa, A.: Ai choreographer: Music conditioned 3d dance generation with aist++. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 13401–13412 (2021) 1, 4, 10, 11, 22, 27
2021
-
[36]
Liao, T.H., Zhou, Y., Shen, Y., Huang, C.H.P., Mitra, S., Huang, J.B., Bhat- tacharya, U.: Shape my moves: Text-driven shape-aware synthesis of human mo- tions.In:ProceedingsoftheComputerVisionandPatternRecognitionConference. pp. 1917–1928 (2025) 2, 4, 13, 20
1917
-
[37]
arXiv preprint arXiv:2411.17335 (2024) 11
Ling, Z., Han, B., Li, S., Cheng, J., Shen, H., Zou, C.: Versatilemotion: A unified framework for motion synthesis and comprehension. arXiv preprint arXiv:2411.17335 (2024) 11
-
[38]
In: Proceedings of the Thirty-Third In- ternational Joint Conference on Artificial Intelligence, IJCAI-24
Ling, Z., Han, B., Wong, Y., Lin, H., Kankanhalli, M., Geng, W.: Mcm: Multi- condition motion synthesis framework. In: Proceedings of the Thirty-Third In- ternational Joint Conference on Artificial Intelligence, IJCAI-24. pp. 1083–1091 (2024) 4, 10, 11
2024
-
[39]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 25
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
ACM Transactions on Graphics (TOG)34(6), 1–16 (2015) 3, 5, 20
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: a skinned multi-person linear model. ACM Transactions on Graphics (TOG)34(6), 1–16 (2015) 3, 5, 20
2015
-
[41]
In: International Conference on Learning Representations (2019) 21
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019) 21
2019
-
[42]
Advances in Neural Information Processing Systems37, 28051–28077 (2024) 4, 11
Luo, M., Hou, R., Li, Z., Chang, H., Liu, Z., Wang, Y., Shan, S.: M3 gpt: An advanced multimodal, multitask framework for motion comprehension and genera- tion. Advances in Neural Information Processing Systems37, 28051–28077 (2024) 4, 11
2024
-
[43]
In: Proceedings of the IEEE/CVF international conference on computer vision
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: Amass: Archive of motion capture as surface shapes. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5442–5451 (2019) 9
2019
-
[44]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Maldonado, G., Pazho, A.D., Noghre, G.A., Katariya, V., Tabkhi, H.: Moclip motion-aware fine-tuning and distillation of clip for human motion generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2931–2941 (2025) 25 18 D. Shimet al
2025
-
[45]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Meng, Z., Xie, Y., Peng, X., Han, Z., Jiang, H.: Rethinking diffusion for text-driven human motion generation: Redundant representations, evaluation, and masked au- toregression. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27859–27871 (2025) 4, 5, 23
2025
-
[46]
Newnes (2012) 1
Parent, R.: Computer animation: algorithms and techniques. Newnes (2012) 1
2012
-
[47]
io/(2021), project page 26
Park, K., Sinha, U., Barron, J.T., Bouaziz, S., Goldman, D.B., Seitz, S.M., Martin- Brualla, R.: Nerfies: Deformable neural radiance fields.https://nerfies.github. io/(2021), project page 26
2021
-
[48]
In: Proceedings oftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Petrovich, M., Litany, O., Iqbal, U., Black, M.J., Varol, G., Bin Peng, X., Rempe, D.: Multi-track timeline control for text-driven 3d human motion generation. In: Proceedings oftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 1911–1921 (2024) 6
1911
-
[49]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pinyoanuntapong, E., Wang, P., Lee, M., Chen, C.: Mmm: Generative masked motion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1546–1555 (2024) 1, 4, 10, 11
2024
-
[50]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 7, 20, 25
2021
-
[51]
Journal of machine learning research21(140), 1–67 (2020) 7, 20
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research21(140), 1–67 (2020) 7, 20
2020
-
[52]
In: European Conference on Computer Vision
Ren, Z., Huang, S., Li, X.: Realistic human motion generation with cross-diffusion models. In: European Conference on Computer Vision. pp. 345–362. Springer (2024) 6
2024
-
[53]
In: SIGGRAPH Asia 2024 Conference Papers
Shen,Z.,Pi,H.,Xia,Y.,Cen,Z.,Peng,S.,Hu,Z.,Bao,H.,Hu,R.,Zhou,X.:World- grounded human motion recovery via gravity-view coordinates. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024) 1, 4, 11, 12
2024
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shin, S., Kim, J., Halilaj, E., Black, M.J.: Wham: Reconstructing world-grounded humans with accurate 3d motion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2070–2080 (2024) 1, 4, 11, 12
2070
-
[55]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Siyao, L., Yu, W., Gu, T., Lin, C., Wang, Q., Qian, C., Loy, C.C., Liu, Z.: Bailando: 3d dance generation by actor-critic gpt with choreographic memory. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11050–11059 (2022) 1, 4, 11
2022
-
[56]
Song,J.,Meng,C.,Ermon,S.:Denoisingdiffusionimplicitmodels.In:International Conference on Learning Representations (2021) 9, 14
2021
-
[57]
ACM Transactions on Graphics (TOG)40(4), 1–16 (2021) 1
Starke, S., Zhao, Y., Zinno, F., Komura, T.: Neural animation layering for syn- thesizing martial arts movements. ACM Transactions on Graphics (TOG)40(4), 1–16 (2021) 1
2021
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sun, Y., Bao, Q., Liu, W., Mei, T., Black, M.J.: Trace: 5d temporal regression of avatars with dynamic cameras in 3d environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8856– 8866 (2023) 1, 10, 11, 12
2023
-
[59]
In: The Eleventh International Conference on Learning Representations (2023) 1, 4, 6, 10, 11, 12, 13, 20, 22
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. In: The Eleventh International Conference on Learning Representations (2023) 1, 4, 6, 10, 11, 12, 13, 20, 22
2023
-
[60]
In: European Conference on Computer Vision
Tripathi, S., Taheri, O., Lassner, C., Black, M., Holden, D., Stoll, C.: Humos: Human motion model conditioned on body shape. In: European Conference on Computer Vision. pp. 133–152. Springer (2024) 4 Odoriko 19
2024
-
[61]
Journal of vision2(5), 2–2 (2002) 2, 4, 13, 24
Troje, N.F.: Decomposing biological motion: A framework for analysis and synthe- sis of human gait patterns. Journal of vision2(5), 2–2 (2002) 2, 4, 13, 24
2002
-
[62]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Tseng, J., Castellon, R., Liu, K.: Edge: Editable dance generation from music. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 448–458 (2023) 4, 7, 11, 20
2023
-
[63]
In: Proceedings of the Computer Vision and Pattern Recog- nition Conference
Uchida, K., Shibuya, T., Takida, Y., Murata, N., Tanke, J., Takahashi, S., Mit- sufuji, Y.: Mola: Motion generation and editing with latent diffusion enhanced by adversarial training. In: Proceedings of the Computer Vision and Pattern Recog- nition Conference. pp. 2910–2919 (2025) 1, 10, 11, 12, 13, 22
2025
-
[64]
Advances in neural information pro- cessing systems30(2017) 20
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017) 20
2017
-
[65]
In: Proceedings of the European conference on computer vision (ECCV)
Von Marcard, T., Henschel, R., Black, M.J., Rosenhahn, B., Pons-Moll, G.: Re- covering accurate 3d human pose in the wild using imus and a moving camera. In: Proceedings of the European conference on computer vision (ECCV). pp. 601–617 (2018) 10, 22, 27
2018
-
[66]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 25
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026) 2, 4
Wang, X., Xu, K., Li, F., Sheng, C., Yu, J., Mu, Y.: Generating attribute-aware human motions from textual prompt. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026) 2, 4
2026
-
[68]
In: European Conference on Computer Vision
Wang, Y., Wang, Z., Liu, L., Daniilidis, K.: Tram: Global trajectory and motion of 3d humans from in-the-wild videos. In: European Conference on Computer Vision. pp. 467–487. Springer (2024) 1, 4, 7, 10, 11, 12, 20
2024
-
[69]
In: 2013 IEEE International Confer- ence on Robotics and Automation
Yamane, K., Revfi, M., Asfour, T.: Synthesizing object receiving motions of hu- manoid robots with human motion database. In: 2013 IEEE International Confer- ence on Robotics and Automation. pp. 1629–1636. IEEE (2013) 1
2013
-
[70]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang, Z., Zeng, A., Yuan, C., Li, Y.: Effective whole-body pose estimation with two-stages distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4210–4220 (2023) 7, 10
2023
-
[71]
In: Proceedings of theIEEE/CVF conference on computer vision and pattern recognition
Zhang, J., Zhang, Y., Cun, X., Zhang, Y., Zhao, H., Lu, H., Shen, X., Shan, Y.: Generating human motion from textual descriptions with discrete representa- tions. In: Proceedings of theIEEE/CVF conference on computer vision and pattern recognition. pp. 14730–14740 (2023) 1, 10, 12, 13
2023
-
[72]
IEEE transactions on pattern analysis and machine intelligence46(6), 4115–4128 (2024) 4, 10, 11
Zhang, M., Cai, Z., Pan, L., Hong, F., Guo, X., Yang, L., Liu, Z.: Motiondiffuse: Text-driven human motion generation with diffusion model. IEEE transactions on pattern analysis and machine intelligence46(6), 4115–4128 (2024) 4, 10, 11
2024
-
[73]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, M., Guo, X., Pan, L., Cai, Z., Hong, F., Li, H., Yang, L., Liu, Z.: Re- modiffuse: Retrieval-augmented motion diffusion model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 364–373 (2023) 6
2023
-
[74]
In: European Conference on Computer Vision
Zhang, M., Jin, D., Gu, C., Hong, F., Cai, Z., Huang, J., Zhang, C., Guo, X., Yang, L., He, Y., et al.: Large motion model for unified multi-modal motion generation. In: European Conference on Computer Vision. pp. 397–421. Springer (2024) 10
2024
-
[75]
Advances in Neural Information Processing Systems36, 49842–49869 (2023) 9, 14
Zhao, W., Bai, L., Rao, Y., Zhou, J., Lu, J.: Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. Advances in Neural Information Processing Systems36, 49842–49869 (2023) 9, 14
2023
-
[76]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation rep- resentations in neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5745–5753 (2019) 6, 20 20 D. Shimet al. A Implementation Details A.1 Network Details T able 8:Transformer architecture details of Odoriko. Latent dim ...
2019
-
[77]
test split using both kinematic and geometric motion features. Specifically, we compute FID and Diversity (Div) in two feature spaces: (i) kinematic fea- tures, denoted as FIDk and Divk, which capture physical motion dynamics, and (ii) geometric features, denoted as FIDg and Divg, which reflect overall dance choreography. Both feature representations are ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.