FleetAgent: Teleoperation Assistant for Autonomous Fleets via Vectorized V2N Messages
Pith reviewed 2026-06-26 14:12 UTC · model grok-4.3
The pith
FleetAgent lets a cloud MLLM evaluate autonomous fleet plans from compact vectorized V2N messages instead of raw images or text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
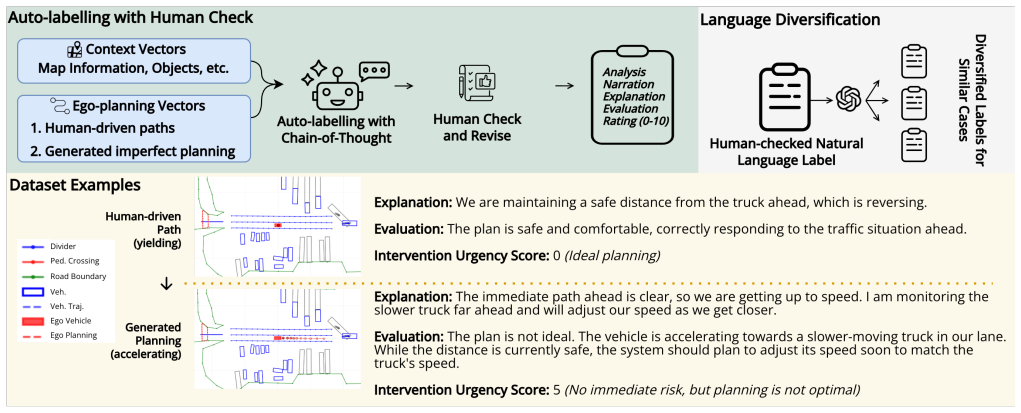
FleetAgent consumes compact vectorized V2N messages such as map elements, detected objects, and the ego planned path to generate structured natural-language responses including narration, explanation, and evaluation of the plan and scene, along with an intervention urgency score. VecFormer provides the vector-to-embedding interface with differentiable top-K context selection. On the VecEval dataset the system reduces uplink payload by up to 625 times versus raw images, reduces KV-cache memory by 16.54 times versus text descriptions, improves Lingo-Judge score by 16.8 percent, and lowers intervention failure rate by 19.9 percent versus Qwen2.5-VL-7B using language descriptions.
What carries the argument
VecFormer, a vector-to-embedding interface with differentiable top-K context selection that converts structured vector messages into token embeddings for MLLMs while bounding context length and KV-cache growth.
If this is right
- Uplink payload is reduced by up to 625 times compared with raw images.
- KV-cache memory is reduced by 16.54 times compared with original text descriptions.
- Lingo-Judge score improves by 16.8 percent on VecEval.
- Intervention failure rate drops by 19.9 percent compared with the language-description baseline.
Where Pith is reading between the lines
- Urgency scores could let one operator oversee hundreds of vehicles by routing attention only to high-score cases.
- The same vector messages might support post-hoc auditing or safety-case generation for fleet deployments.
- VecFormer-style embedding could be reused for other V2X or infrastructure-to-vehicle AI tasks that need compact scene representations.
Load-bearing premise
The vectorized messages contain enough information for the MLLM to produce scene narrations, plan evaluations, and urgency scores that match human judgment.
What would settle it
A side-by-side test on held-out fleet scenarios in which human operators compare the system's urgency scores and explanations against their own assessments and measure resulting intervention success rates.
Figures



read the original abstract
Large-scale autonomous fleets rely on teleoperation to resolve rare failures, yet streaming raw sensor data from many vehicles is costly, and remote operators can only monitor a limited number of vehicles at a time. We introduce FleetAgent, a cloud-hosted multimodal large language model (MLLM) assistant that consumes compact vectorized vehicle-to-network (V2N) messages, such as map elements, detected objects, and the ego planned path. It provides a structured natural-language response (including narration, explanation, and evaluation of the plan and scene), along with an intervention urgency score for operator prioritization. To make structured messages compatible with token-based MLLMs, we propose VecFormer, a vector-to-embedding interface with differentiable top-K context selection that bounds context length and GPU KV-cache growth, enabling more efficient batch processing, which is important under the context of cloud-hosted large-scale fleet management. We also construct VecEval, a nuScenes-derived dataset with paired human and synthetic imperfect plans and human-verified language labels, to facilitate the training and evaluation of our proposed system. Our proposed system can reduce uplink payload by up to 625 times compared with raw images and reduce KV-cache memory by 16.54 times compared with original text descriptions. On VecEval, FleetAgent improves Lingo-Judge score by 16.8% and reduces intervention failure rate by 19.9%, compared with Qwen2.5-VL-7B using language descriptions. These results demonstrate that FleetAgent can utilize compact structured V2N messaging to enable efficient, explainable teleoperation monitoring for autonomous fleets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FleetAgent, a cloud-hosted MLLM assistant for teleoperation of autonomous vehicle fleets. It consumes compact vectorized V2N messages (map elements, detected objects, ego planned path) via a proposed VecFormer vector-to-embedding interface with differentiable top-K selection, producing structured natural-language outputs (narration, plan evaluation, explanation) plus an intervention urgency score. A new VecEval dataset (nuScenes-derived, with paired human/synthetic plans and human-verified labels) is constructed for training and evaluation. The system is reported to achieve up to 625× uplink payload reduction versus raw images, 16.54× KV-cache reduction versus text descriptions, 16.8% higher Lingo-Judge score, and 19.9% lower intervention failure rate versus Qwen2.5-VL-7B on language descriptions.
Significance. If the central premise holds—that vectorized V2N messages plus VecFormer preserve sufficient relational and dynamic scene information for MLLM outputs to align with human judgment on narration, plan evaluation, and urgency—the work could meaningfully advance scalable fleet teleoperation by cutting bandwidth and compute costs while adding explainability. The efficiency metrics and new VecEval benchmark are concrete contributions; the focus on cloud-scale batching via bounded context is practically relevant. However, the absence of ablations on information loss and label reliability weakens the ability to assess whether the reported gains come at the expense of reliability.
major comments (3)
- [Abstract, §3] Abstract and §3 (VecFormer): the central claim that vectorized messages (after top-K pruning) suffice for MLLM outputs to match human judgment on urgency scores and plan evaluation is load-bearing for all quantitative results, yet the manuscript provides no quantitative analysis of information loss (e.g., relational or dynamic details dropped by vectorization or top-K) relative to raw sensor streams or full language descriptions.
- [§4] §4 (VecEval construction and metrics): the 19.9% failure-rate reduction and 16.8% Lingo-Judge lift rest on human-verified labels and the failure-rate definition, but the paper supplies no annotation protocol, number of annotators, inter-annotator agreement, or error bars on these metrics, making it impossible to judge whether the improvements are robust or artifactual.
- [§4] §4 (baseline comparison): the gains are reported versus Qwen2.5-VL-7B using language descriptions, but the manuscript does not state whether FleetAgent employs the identical base MLLM or a different one; without this, it is unclear whether improvements are attributable to the structured V2N input or to other modeling differences.
minor comments (2)
- [Abstract, §1] The abstract and introduction introduce VecFormer and VecEval without an explicit statement of their novelty relative to prior vector-to-sequence or V2X work; a short related-work paragraph would clarify contribution.
- [Figure 2, §3] Figure 2 (system overview) and any accompanying equations for differentiable top-K would benefit from explicit notation for the selection operator and its gradient path to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on FleetAgent. The comments identify areas where additional clarity and analysis would strengthen the manuscript. We respond point-by-point below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (VecFormer): the central claim that vectorized messages (after top-K pruning) suffice for MLLM outputs to match human judgment on urgency scores and plan evaluation is load-bearing for all quantitative results, yet the manuscript provides no quantitative analysis of information loss (e.g., relational or dynamic details dropped by vectorization or top-K) relative to raw sensor streams or full language descriptions.
Authors: We agree that explicit quantification of information loss would provide stronger support. The reported gains versus language descriptions offer indirect evidence of preserved utility, but a direct ablation is absent. In revision we will add a dedicated paragraph in §3 discussing the design choices for top-K selection and include qualitative examples of retained relational elements (e.g., object interactions and path constraints) to address this concern. revision: yes
-
Referee: [§4] §4 (VecEval construction and metrics): the 19.9% failure-rate reduction and 16.8% Lingo-Judge lift rest on human-verified labels and the failure-rate definition, but the paper supplies no annotation protocol, number of annotators, inter-annotator agreement, or error bars on these metrics, making it impossible to judge whether the improvements are robust or artifactual.
Authors: The omission of these details is a valid criticism. VecEval labels were produced via human verification, yet the protocol, annotator count, agreement statistics, and error bars were not reported. We will expand §4 with the annotation guidelines, number of annotators, inter-annotator agreement, and error bars on all metrics in the revised manuscript. revision: yes
-
Referee: [§4] §4 (baseline comparison): the gains are reported versus Qwen2.5-VL-7B using language descriptions, but the manuscript does not state whether FleetAgent employs the identical base MLLM or a different one; without this, it is unclear whether improvements are attributable to the structured V2N input or to other modeling differences.
Authors: FleetAgent employs the identical base model Qwen2.5-VL-7B; VecFormer replaces only the visual tokenization pathway while keeping the language model weights unchanged. The comparison is therefore to the same MLLM receiving language descriptions. We will add an explicit statement to this effect in §4 of the revision. revision: yes
Circularity Check
No circularity: empirical gains rest on external baseline and human-labeled dataset
full rationale
The paper reports payload reduction, KV-cache savings, Lingo-Judge improvement, and failure-rate reduction via direct comparison to Qwen2.5-VL-7B on language inputs, evaluated on VecEval (a newly constructed dataset with human-verified labels). No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce these outcomes to the inputs by construction. VecFormer and the vectorized V2N pipeline are presented as engineering contributions whose value is measured externally rather than defined into the metrics.
Axiom & Free-Parameter Ledger
invented entities (2)
-
VecFormer
no independent evidence
-
VecEval
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Waymo, “Waymo,” https://waymo.com/, 2025, accessed: 2025-09-24
2025
-
[2]
Zoox: It’s not a car,
Zoox, “Zoox: It’s not a car,” https://zoox.com/, 2025, accessed: 2025- 09-24
2025
-
[3]
Tesla robotaxi,
Tesla, “Tesla robotaxi,” https://www.tesla.com/robotaxi, 2025, ac- cessed: 2025-09-23
2025
-
[4]
nuScenes: A Multimodal Dataset for Autonomous Driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuScenes: A Multimodal Dataset for Autonomous Driving,” 2020, pp. 11 621– 11 631
2020
-
[5]
Sensor and Actuator Latency during Teleoperation of Automated Vehicles,
J.-M. Georg, J. Feiler, S. Hoffmann, and F. Diermeyer, “Sensor and Actuator Latency during Teleoperation of Automated Vehicles,” in 2020 IEEE Intelligent Vehicles Symposium (IV), Oct. 2020, pp. 760– 766, iSSN: 2642-7214
2020
-
[6]
Data Rate Reduction for Video Streams in Teleoperated Driving,
S. Neumeier, V . Bajpai, M. Neumeier, C. Facchi, and J. Ott, “Data Rate Reduction for Video Streams in Teleoperated Driving,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 10, pp. 19 145–19 160, Oct. 2022
2022
-
[7]
Shared Autonomy for Teleoperated Driving: A Real-Time Interactive Path Planning Approach,
D. Schitz, S. Bao, D. Rieth, and H. Aschemann, “Shared Autonomy for Teleoperated Driving: A Real-Time Interactive Path Planning Approach,” in2021 IEEE International Conference on Robotics and Automation (ICRA), May 2021, pp. 999–1004, iSSN: 2577-087X
2021
-
[8]
A Generative Model-Based Predictive Display for Robotic Teleoperation,
B. Xie, M. Han, J. Jin, M. Barczyk, and M. J ¨agersand, “A Generative Model-Based Predictive Display for Robotic Teleoperation,” in2021 IEEE International Conference on Robotics and Automation (ICRA), May 2021, pp. 2407–2413, iSSN: 2577-087X
2021
-
[9]
A cost efficient multi remote driver selection for remote operated vehicles,
A. Gohar and S. Lee, “A cost efficient multi remote driver selection for remote operated vehicles,”Computer Networks, vol. 168, p. 107029, Feb. 2020
2020
-
[10]
Should Teleoperation Be like Driving in a Car? Comparison of Teleoperation HMIs,
M.-M. Wolf, R. Taupitz, and F. Diermeyer, “Should Teleoperation Be like Driving in a Car? Comparison of Teleoperation HMIs,” Apr. 2024, arXiv:2404.13697 [cs]. [Online]. Available: http://arxiv.org/abs/ 2404.13697
arXiv 2024
-
[11]
E. Tsagkournis, D. Panagopoulos, G. Petousakis, G. Nikolaou, R. Stolkin, and M. Chiou, “A Supervised Machine Learning Approach to Operator Intent Recognition for Teleoperated Mobile Robot Navigation,” Apr. 2023, arXiv:2304.14003 [cs]. [Online]. Available: http://arxiv.org/abs/2304.14003
arXiv 2023
-
[12]
Assisted Mobile Robot Teleoperation with Intent-aligned Trajectories via Biased Incremental Action Sampling,
X. Yang and N. Michael, “Assisted Mobile Robot Teleoperation with Intent-aligned Trajectories via Biased Incremental Action Sampling,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct. 2020, pp. 10 998–11 003, iSSN: 2153-0866
2020
-
[13]
GoonDAE: Denoising- Based Driver Assistance for Off-Road Teleoperation,
Y . Cho, H. Yun, J. Lee, A. Ha, and J. Yun, “GoonDAE: Denoising- Based Driver Assistance for Off-Road Teleoperation,”IEEE Robotics and Automation Letters, vol. 8, no. 4, pp. 2405–2412, Apr. 2023, arXiv:2209.03568 [cs]
arXiv 2023
-
[14]
S. Rahmani, S. Rieder, E. d. Gelder, M. Sonntag, J. L. Mallada, S. Kalisvaart, V . Hashemi, and S. C. Calvert, “A Systematic Review of Edge Case Detection in Automated Driving: Methods, Challenges and Future Directions,” Oct. 2024, arXiv:2410.08491 [cs]. [Online]. Available: http://arxiv.org/abs/2410.08491
Pith/arXiv arXiv 2024
-
[15]
Generative AI for Autonomous Driving: Frontiers and Opportunities,
Y . Wang, S. Xing, C. Can, R. Li, H. Hua, K. Tian, Z. Mo, X. Gao, K. Wu, S. Zhou, H. You, J. Peng, J. Zhang, Z. Wang, R. Song, M. Yan, W. Zimmer, X. Zhou, P. Li, Z. Lu, C.-J. Chen, Y . Huang, R. A. Rossi, L. Sun, H. Yu, Z. Fan, F. H. Yang, Y . Kang, R. Greer, C. Liu, E. H. Lee, X. Di, X. Ye, L. Ren, A. Knoll, X. Li, S. Ji, M. Tomizuka, M. Pavone, T. Yang,...
arXiv 2025
-
[16]
DriveLM: Driving with Graph Visual Question Answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “DriveLM: Driving with Graph Visual Question Answering,” inComputer Vision – ECCV 2024, A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, and G. Varol, Eds. Cham: Springer Nature Switzerland, 2025, pp. 256–274
2024
-
[17]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models,
X. Tian, J. Gu, B. Li, Y . Liu, Y . Wang, Z. Zhao, K. Zhan, P. Jia, X. Lang, and H. Zhao, “DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models,” Jun. 2024, arXiv:2402.12289 [cs]. [Online]. Available: http://arxiv.org/abs/2402. 12289
Pith/arXiv arXiv 2024
-
[18]
S.-Y . Park, C. Cui, Y . Ma, A. Moradipari, R. Gupta, K. Han, and Z. Wang, “NuPlanQA: A Large-Scale Dataset and Benchmark for Multi-View Driving Scene Understanding in Multi-Modal Large Language Models,” Aug. 2025, arXiv:2503.12772 [cs]. [Online]. Available: http://arxiv.org/abs/2503.12772
arXiv 2025
-
[19]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving,
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang, G. Chen, H. Ye, W. Liu, and X. Wang, “ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving,” Jun. 2025, arXiv:2506.08052 [cs]. [Online]. Available: http://arxiv.org/abs/2506.08052
Pith/arXiv arXiv 2025
-
[20]
EMMA: End-to-End Multimodal Model for Autonomous Driving,
J.-J. Hwang, R. Xu, H. Lin, W.-C. Hung, J. Ji, K. Choi, D. Huang, T. He, P. Covington, B. Sapp, J. Guo, D. Anguelov, and M. Tan, “EMMA: End-to-End Multimodal Model for Autonomous Driving,” Oct. 2024, arXiv:2410.23262 [cs] version: 1. [Online]. Available: http://arxiv.org/abs/2410.23262
Pith/arXiv arXiv 2024
-
[21]
OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model,
X. Zhou, X. Han, F. Yang, Y . Ma, and A. C. Knoll, “OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model,” Mar. 2025, arXiv:2503.23463 [cs]. [Online]. Available: http://arxiv.org/abs/2503.23463
arXiv 2025
-
[22]
DriveGPT4: Interpretable End-to-End Autonomous Driving Via Large Language Model,
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao, “DriveGPT4: Interpretable End-to-End Autonomous Driving Via Large Language Model,”IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 8186–8193, Oct. 2024, conference Name: IEEE Robotics and Automation Letters. [Online]. Available: https://ieeexplore.ieee.org/document/10...
arXiv 2024
-
[23]
A Language Agent for Autonomous Driving,
J. Mao, J. Ye, Y . Qian, M. Pavone, and Y . Wang, “A Language Agent for Autonomous Driving,” Jul. 2024, arXiv:2311.10813 [cs]. [Online]. Available: http://arxiv.org/abs/2311.10813
arXiv 2024
-
[24]
Hint-AD: Holistically Aligned Interpretability in End-to-End Autonomous Driving,
K. Ding, B. Chen, Y . Su, H.-a. Gao, B. Jin, C. Sima, W. Zhang, X. Li, P. Barsch, H. Li, and H. Zhao, “Hint-AD: Holistically Aligned Interpretability in End-to-End Autonomous Driving,” Sep. 2024, arXiv:2409.06702 [cs]. [Online]. Available: http://arxiv.org/abs/2409.06702
arXiv 2024
-
[25]
ALN-P3: Unified Language Alignment for Perception, Prediction, and Planning in Autonomous Driving,
Y . Ma, B. Yaman, X. Ye, M. Yurt, J. Luo, A. Mallik, Z. Wang, and L. Ren, “ALN-P3: Unified Language Alignment for Perception, Prediction, and Planning in Autonomous Driving,” May 2025, arXiv:2505.15158 [cs]. [Online]. Available: http://arxiv.org/abs/2505. 15158
arXiv 2025
-
[26]
Interworking of dsrc and cellular network technologies for v2x communications: A survey,
K. Abboud, H. A. Omar, and W. Zhuang, “Interworking of dsrc and cellular network technologies for v2x communications: A survey,” IEEE transactions on vehicular technology, vol. 65, no. 12, pp. 9457– 9470, 2016
2016
-
[27]
5G-Enabled Teleoperated Driving: An Experimental Evaluation,
M. Testouri, G. Elghazaly, F. Hawlader, and R. Frank, “5G-Enabled Teleoperated Driving: An Experimental Evaluation,” Mar. 2025, arXiv:2503.14186 [cs]. [Online]. Available: http://arxiv.org/abs/2503. 14186
arXiv 2025
-
[28]
QuantV2X: A Fully Quantized Multi-Agent System for Cooperative Perception,
S. Z. Zhao, H. Zhang, Z. Li, J. Peng, A. Chui, Z. Zhou, Z. Meng, H. Xiang, Z. Huang, F. Wang, R. Tian, C. Xu, B. Zhou, and J. Ma, “QuantV2X: A Fully Quantized Multi-Agent System for Cooperative Perception,” Sep. 2025, arXiv:2509.03704 [cs]. [Online]. Available: http://arxiv.org/abs/2509.03704
arXiv 2025
-
[29]
Scalability in Perception for Autonomous Driving: Waymo Open Dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, V . Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y . Zhang, J. Shlens, Z. Chen, and D. Anguelov, “Scalability in Perception for Autonomous Driving: Waymo Open Dataset,” 2020, pp. 2446–2454
2020
-
[30]
Vision meets robotics: The KITTI dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,”The International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, Sep. 2013
2013
-
[31]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles,
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari, “NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles,” Feb. 2022, arXiv:2106.11810 [cs]. [Online]. Available: http://arxiv.org/abs/2106.11810
Pith/arXiv arXiv 2022
-
[32]
NuScenes-QA: A Multi-modal Visual Question Answering Benchmark for Autonomous Driving Scenario,
T. Qian, J. Chen, L. Zhuo, Y . Jiao, and Y .-G. Jiang, “NuScenes-QA: A Multi-modal Visual Question Answering Benchmark for Autonomous Driving Scenario,” Feb. 2024, arXiv:2305.14836 [cs]. [Online]. Available: http://arxiv.org/abs/2305.14836
arXiv 2024
-
[33]
Holistic autonomous driving understanding by bird’s-eye-view injected multi- modal large models,
X. Ding, J. Han, H. Xu, X. Liang, W. Zhang, and X. Li, “Holistic autonomous driving understanding by bird’s-eye-view injected multi- modal large models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 13 668–13 677
2024
-
[34]
Language Prompt for Autonomous Driving,
D. Wu, W. Han, Y . Liu, T. Wang, C.-Z. Xu, X. Zhang, and J. Shen, “Language Prompt for Autonomous Driving,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 8, pp. 8359–8367, Apr. 2025
2025
-
[35]
Textual Explanations for Self-Driving Vehicles,
J. Kim, A. Rohrbach, T. Darrell, J. Canny, and Z. Akata, “Textual Explanations for Self-Driving Vehicles,” inComputer Vision – ECCV 2018, V . Ferrari, M. Hebert, C. Sminchisescu, and Y . Weiss, Eds. Cham: Springer International Publishing, 2018, vol. 11206, pp. 577– 593, series Title: Lecture Notes in Computer Science
2018
-
[36]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-VL Technical Report,” Feb. 2025, arXiv:2502.13923 [cs]. [Online]. Available: http://arxiv.org/abs/2502.13923
Pith/arXiv arXiv 2025
-
[37]
Categorical Reparameterization with Gumbel-Softmax,
E. Jang, S. Gu, and B. Poole, “Categorical Reparameterization with Gumbel-Softmax,” Aug. 2017, arXiv:1611.01144 [stat]. [Online]. Available: http://arxiv.org/abs/1611.01144
Pith/arXiv arXiv 2017
-
[38]
Lingoqa: Visual question answering for autonomous driving,
A.-M. Marcu, L. Chen, J. H ¨unermann, A. Karnsund, B. Hanotte, P. Chidananda, S. Nair, V . Badrinarayanan, A. Kendall, J. Shotton et al., “Lingoqa: Visual question answering for autonomous driving,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 252–269
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.