EnTrust: Modeling Inter-Modal Conflict for Trustworthy Multimodal Medical Image Analysis
Pith reviewed 2026-06-26 14:27 UTC · model grok-4.3
The pith
EnTrust decomposes multimodal medical images into consensus, specific, and conflict features to tie uncertainty directly to modal disagreements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
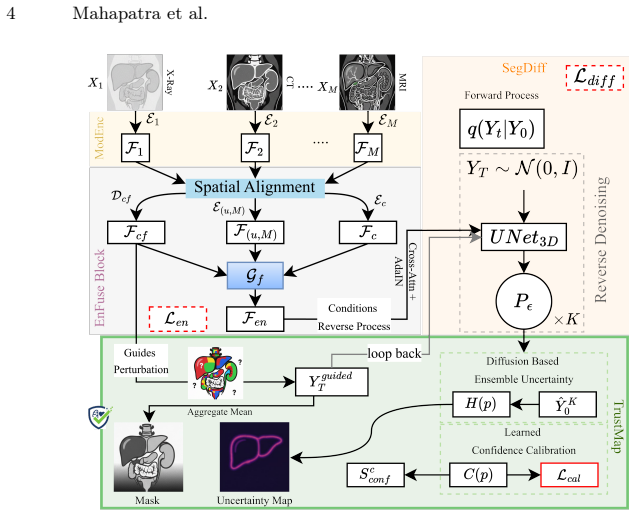
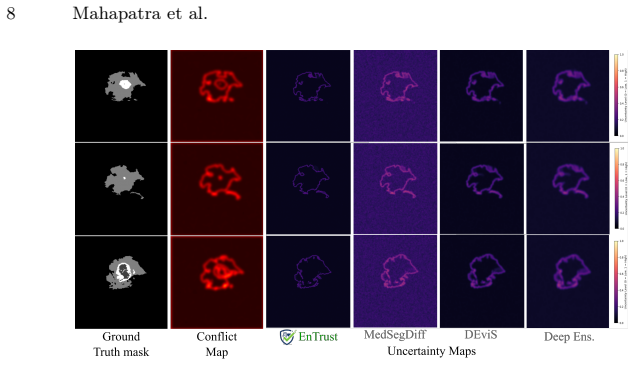
EnTrust introduces an EnFuse module that decomposes multimodal features into shared anatomical consensus (F_c), modality-specific cues (F_{u,m}), and spatially localized conflict signals (F_{cf}), enforcing independence via cross-covariance. This decomposition conditions a diffusion-based segmentation model (SegDiff) so that sampled hypotheses diverge in regions of modal disagreement. A TrustMap module then converts this divergence into pixel-wise calibrated uncertainty, allowing clinicians to see not only where but why predictions are uncertain.
What carries the argument
The EnFuse module, which disentangles multimodal features into three independent components (shared consensus, modality-specific, and conflict) using a cross-covariance objective to condition the diffusion segmentation model.
If this is right
- Segmentation accuracy reaches state-of-the-art levels across brain, cardiac, lesion, and oncology benchmarks.
- Calibration error drops by 40% compared to the strongest baseline.
- A single model outperforms five times deep ensembles while using roughly half the memory footprint.
- Uncertainty estimates become interpretable by linking them directly to inter-modal conflicts.
Where Pith is reading between the lines
- If the decomposition works as claimed, the method could extend to other multimodal fusion tasks beyond segmentation, such as registration or classification.
- Testing on datasets with more than two modalities might reveal whether the three-component split scales or needs adjustment.
- The reduced memory footprint suggests potential for deployment in resource-constrained clinical settings where ensembles are impractical.
Load-bearing premise
The cross-covariance objective enforces statistical independence among the shared, specific, and conflict feature components.
What would settle it
On a held-out multimodal dataset, if the sampled diffusion hypotheses do not show increased divergence specifically in regions where the input modalities disagree on anatomy or pathology, the central mechanism would be falsified.
Figures


read the original abstract
Multimodal medical imaging fuses complementary anatomical and functional information, yet modalities frequently disagree in pathologically heterogeneous regions. Current segmentation models handle this in one of two inadequate ways: deterministic fusion that averages away disagreement, or post-hoc uncertainty estimation decoupled from the fusion process that produces it. Both obscure the clinically critical question: why is this prediction unreliable? We present EnTrust, a framework that treats inter-modal conflict as the primary source of predictive uncertainty. Our EnFuse module decomposes multimodal features into three disentangled components: shared anatomical consensus (F_c), modality-specific cues (F_{u,m}), and spatially localized conflict signals (F_{cf}), with independence enforced via a cross-covariance objective. This structured decomposition conditions SegDiff, a diffusion-based generative segmentation model whose sampled hypotheses diverge specifically in regions of modal disagreement. TrustMap then translates this hypothesis divergence into calibrated, pixel-wise uncertainty using ensemble entropy, conflict-guided perturbation probing, and a learned calibration head, enabling clinicians to understand not only where predictions are uncertain, but why. Across four benchmarks spanning brain, cardiac, lesion, and oncology domains, EnTrust achieves state-of-the-art segmentation accuracy while reducing calibration error by 40% compared to the strongest baseline. Notably, it outperforms 5x deep ensembles using a single model at roughly half the memory footprint. Code and checkpoints are available at https://github.com/GenMI-Lab/EnTrust.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EnTrust, a framework for multimodal medical image segmentation that treats inter-modal conflict as the primary source of uncertainty. The EnFuse module decomposes input features into shared consensus (F_c), modality-specific (F_{u,m}), and conflict (F_cf) components, with independence enforced by a cross-covariance objective. These condition SegDiff, a diffusion-based generative model, so that sampled hypotheses diverge specifically in regions of modal disagreement. TrustMap converts the resulting hypothesis divergence into pixel-wise calibrated uncertainty via ensemble entropy, conflict-guided perturbation, and a learned calibration head. The paper reports state-of-the-art segmentation accuracy and a 40% reduction in calibration error versus the strongest baseline across four benchmarks (brain, cardiac, lesion, oncology), while outperforming 5× deep ensembles with a single model at roughly half the memory cost. Code is released.
Significance. If the feature disentanglement isolates conflict-driven uncertainty as claimed, the approach would provide a clinically useful link between modal disagreement and predictive unreliability, advancing trustworthy multimodal fusion beyond post-hoc uncertainty methods. The reported efficiency gain over ensembles would be a practical advantage if substantiated. Public code and checkpoints strengthen reproducibility.
major comments (1)
- [EnFuse module (cross-covariance objective)] EnFuse module (cross-covariance objective): the loss is presented as enforcing statistical independence among F_c, F_{u,m}, and F_cf so that SegDiff hypotheses diverge specifically where modalities disagree. Cross-covariance penalizes only linear second-order correlations and does not guarantee full statistical independence for the non-Gaussian, higher-order dependent features typical of CNN-extracted medical images. This assumption is load-bearing for the central claim that TrustMap uncertainty is conflict-driven rather than generic.
minor comments (2)
- [Method section] Notation for modality-specific features is written F_{u,m}; clarify whether the subscript denotes per-modality or per-sample indexing and ensure consistency across equations and figures.
- [Abstract] The abstract states quantitative improvements (SOTA accuracy, 40% calibration reduction) without citing the supporting tables or figures; add explicit references in the abstract or introduction.
Simulated Author's Rebuttal
We thank the referee for highlighting this important technical point on the EnFuse module. We address the concern directly below and propose a targeted revision.
read point-by-point responses
-
Referee: EnFuse module (cross-covariance objective): the loss is presented as enforcing statistical independence among F_c, F_{u,m}, and F_cf so that SegDiff hypotheses diverge specifically where modalities disagree. Cross-covariance penalizes only linear second-order correlations and does not guarantee full statistical independence for the non-Gaussian, higher-order dependent features typical of CNN-extracted medical images. This assumption is load-bearing for the central claim that TrustMap uncertainty is conflict-driven rather than generic.
Authors: We agree that the cross-covariance objective enforces only linear second-order decorrelation and cannot guarantee full statistical independence for the non-Gaussian, higher-order dependencies present in CNN features. This is a substantive limitation of the current formulation. We will revise the manuscript to (1) explicitly describe the objective as promoting linear independence rather than claiming full statistical independence, (2) add a dedicated limitations paragraph discussing the approximation and its potential impact on the conflict-driven uncertainty claim, and (3) include an ablation study comparing cross-covariance against a mutual-information estimator (e.g., via MINE) on one benchmark to quantify the practical difference. These changes will make the load-bearing assumption transparent while preserving the empirical evidence that the current objective yields conflict-aligned uncertainty maps. revision: yes
Circularity Check
No circularity: derivation uses explicit losses and generative sampling without reduction to inputs
full rationale
The paper defines feature decomposition via an explicit cross-covariance objective, conditions a diffusion model on the resulting conflict component, and derives uncertainty from hypothesis divergence plus ensemble entropy. These are forward-defined mechanisms with stated loss terms and sampling procedures rather than parameters fitted to target quantities and renamed as predictions, self-definitional loops, or load-bearing self-citations. The chain remains independent of its outputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cross-covariance objective enforces independence of consensus, modality-specific, and conflict feature components
- domain assumption Diffusion model hypotheses diverge specifically in modal disagreement regions when conditioned on conflict signals
invented entities (3)
-
EnFuse module
no independent evidence
-
SegDiff
no independent evidence
-
TrustMap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Authors affiliated with IQVIA
Arias, A., Rickwood, S.: Boosting healthcare capacity with AI (Jan 2024),https://www.weforum.org/stories/2024/01/ ai-in-healthcare-could-bridge-a-significant-capacity-gap/, published as part of the World Economic Forum Annual Meeting 2024. Authors affiliated with IQVIA
2024
-
[2]
In: International conference on medical image computing and computer-assisted intervention
Das, A., Gorade, V., Kumar, K., Chakraborty, S., Mahapatra, D., Roy, S.: Confidence-guided semi-supervised learning for generalized lesion localization in x-ray images. In: International conference on medical image computing and computer-assisted intervention. pp. 242–252. Springer (2024)
2024
-
[3]
Frontiers in Neuroinformat- ics13, 58 (2019) 10 Mahapatra et al
Fedorov, A., Li, X., Sarah, A.S., Kogan, Y., et al.: Atlas: A dataset for traumatic brain injury lesion segmentation and characterization. Frontiers in Neuroinformat- ics13, 58 (2019) 10 Mahapatra et al
2019
-
[4]
Gal, Y., Ghahramani, Z.: Dropout as a bayesian approximation: Representing modeluncertaintyindeeplearning.In:InternationalConferenceonMachineLearn- ing (ICML). pp. 1050–1059 (2016)
2016
-
[5]
In: Advances in Neural Information Processing Systems
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems. vol. 33, pp. 6840–6851 (2020)
2020
-
[6]
Survey of 8,584 IT professionals across 10 countries
IBM: Data suggests growth in enterprise adoption of AI is due to widespread deployment by early adopters (Jan 2024),https://newsroom.ibm.com/ 2024-01-10-Data-Suggests-Growth-in-Enterprise-Adoption-of-AI-is-Due-\ to-Widespread-Deployment-by-Early-Adopters, IBM Global AI Adoption In- dex 2023, conducted by Morning Consult on behalf of IBM. Survey of 8,584 I...
2024
-
[7]
Kohl, S.A.A., Romera-Paredes, B., Meyer, C., Fauw, J.D., Ledsam, J.R., Maier- Hein, K.H., Eslami, S.M.A., Rezende, D.J., Ronneberger, O.: A probabilistic u- net for segmentation of ambiguous images (2019),https://arxiv.org/abs/1806. 05034
2019
-
[8]
In: Proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024
Konuk, E., Welch, R., Christiansen, F., Epstein, E., Smith, K.: A framework for assessing joint human-AI systems based on uncertainty estimation. In: Proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024. Springer, Cham (2024)
2024
-
[9]
Advances in Neural Information Pro- cessing Systems30, 6402–6413 (2017)
Lakshminarayanan, B., Pritzel, A., Blundell, C.: Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in Neural Information Pro- cessing Systems30, 6402–6413 (2017)
2017
-
[10]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows (2021),https: //arxiv.org/abs/2103.14030
Pith/arXiv arXiv 2021
-
[11]
Construction of correlation functions in two and three dimensions
Menze, B.H., Jakab, A., Bauer, S., Kalpathy-Cramer, J., et. al.: The multimodal brain tumor segmentation challenge (brats) 2012, 2013, 2014, 2015. IEEE Transac- tions on Medical Imaging37(1), 237–250 (2019).https://doi.org/10.1109/TMI. 2018.2818988
work page doi:10.1109/tmi 2012
-
[12]
In: 2016 Fourth International Confer- ence on 3D Vision (3DV)
Milletari, F., Navab, N., Ahmadi, S.A.: V-net: Fully convolutional neural networks for volumetric medical image segmentation. In: 2016 Fourth International Confer- ence on 3D Vision (3DV). pp. 565–571. IEEE (2016)
2016
-
[13]
Organizers: Hektor 2025 challenge,https://hecktor25.grand-challenge.org/ dataset/
2025
-
[14]
In: Advances in Neural Information Processing Systems
Sensoy, M., Kaplan, L., Kandemir, E.: Evidential deep learning to quantify un- certainty in image classification. In: Advances in Neural Information Processing Systems. vol. 31 (2018)
2018
-
[15]
In: Med- ical Imaging with Deep Learning
Wu, J., Fu, R., Fang, H., Zhang, Y., Yang, Y., Xiong, H., Liu, H., Xu, Y.: Med- SegDiff: Medical Image Segmentation with Diffusion Probabilistic Model. In: Med- ical Imaging with Deep Learning. Proceedings of Machine Learning Research, vol. 227, pp. 1623–1639 (2024),https://proceedings.mlr.press/v227/wu24a. html
2024
-
[16]
IEEE transactions on pattern analysis and machine intelli- gence41(12), 2933–2946 (2018)
Zhuang, X.: Multivariate mixture model for myocardial segmentation combining multi-source images. IEEE transactions on pattern analysis and machine intelli- gence41(12), 2933–2946 (2018)
2018
-
[17]
Zou, K., Chen, Y., Huang, L., Yuan, X., Shen, X., Wang, M., Goh, R.S.M., Liu, Y., Fu, H.: Towards reliable medical image segmentation by utilizing evidential calibrated uncertainty (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.