Evaluating LLMs for Real-World Web Vulnerability Detection
Pith reviewed 2026-06-26 13:48 UTC · model grok-4.3
The pith
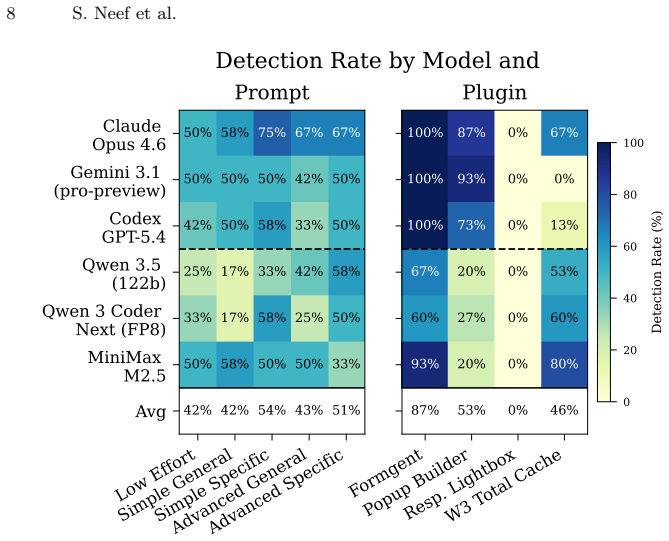
LLMs detect web vulnerabilities in WordPress plugins at rates from 35 to 63 percent depending on the model and prompt style.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
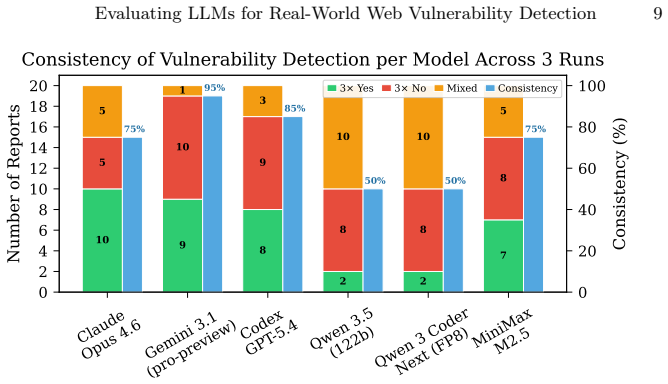
All tested models can identify valid web vulnerabilities, with Claude Opus 4.6 reaching a 63 percent detection rate, but detection varies by model and prompt, scoped prompts outperform open-ended ones, and no model achieves consistent reporting across three iterations, with one baseline vulnerability missed entirely.
What carries the argument
The benchmark comparing frontier and open-weight LLMs using five prompt designs on five vulnerability types in WordPress plugins.
If this is right
- Scoped prompts that narrow vulnerability scope lead to higher detection rates than open-ended prompts.
- Open-weight models like MiniMax M2.5 can match some frontier models at 48 percent detection.
- Prompt complexity has little effect on performance compared to scope.
- Reporting inconsistency means results from a single run may not be reliable.
- Some vulnerabilities remain undetected even by the best model in the tested set.
Where Pith is reading between the lines
- Security teams could combine LLMs with traditional tools to catch the missed cases.
- Future work might focus on improving consistency through multiple runs or ensemble methods.
- Results suggest testing on a wider range of web applications beyond WordPress to confirm generalizability.
- Practitioners should verify LLM findings manually due to the observed inconsistencies.
Load-bearing premise
The specific WordPress plugins and the five chosen vulnerability types represent typical real-world web vulnerabilities well enough for the detection rates to apply more broadly.
What would settle it
Running the same evaluation on a different set of web applications or vulnerability types and finding substantially different detection rates or consistency levels.
Figures

read the original abstract
Large Language Models (LLMs) have emerged as a promising tool for automated vulnerability detection, yet their effectiveness on web-specific vulnerabilities remains to be explored. This work benchmarks six frontier (Claude Opus 4.6, Codex GPT-5.4, Gemini 3.1-pro-preview) and open-weight models (Qwen 3.5, Qwen 3 Coder Next, MiniMax M2.5) on their ability to detect real-world web vulnerabilities using static analysis in WordPress plugins, including SQL injection, stored cross-site scripting, path traversal, and remote code execution. Using five prompt designs of varying structure, scope, and complexity across three experiment iterations, we aim to answer how model and prompt choice affects vulnerability detection. Our results show that all models are capable of detecting valid security issues, but the detection rate varies depending on the model and prompt. For example, Claude Opus 4.6 achieved the highest web vulnerability detection rate (63%), while open-weight MiniMax M2.5 performs on par with other frontier models (48%), and self-hosted Qwen 3.5 only achieved 35%. We show that scoped prompts that narrow the vulnerability scope outperform open-ended ones, whereas the prompt complexity has little impact. Surprisingly, no model achieved full reporting consistency across three experiment iterations, with some as low as 50%. Our experiments demonstrate the opportunities and limits of LLM-based vulnerability detection, as no model correctly identified one baseline vulnerability in one of the plugins. Additionally, we derive practical lessons learned for security practitioners and publish all code and data to support future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks six LLMs (three frontier: Claude Opus 4.6, Codex GPT-5.4, Gemini 3.1-pro-preview; three open-weight: Qwen 3.5, Qwen 3 Coder Next, MiniMax M2.5) on static detection of four web vulnerability types (SQL injection, stored XSS, path traversal, RCE) inside WordPress plugins. Using five prompt designs of varying structure/scope/complexity across three iterations, it reports model-specific detection rates (Claude at 63%, MiniMax at 48%, Qwen 3.5 at 35%), finds scoped prompts superior to open-ended ones, notes that prompt complexity has little effect, and observes that no model achieves full reporting consistency (some as low as 50%). The work also states that no model identified one baseline vulnerability and derives practitioner lessons while committing to release code and data.
Significance. If the measured rates and prompt comparisons hold, the study supplies concrete empirical data on LLM utility for a narrow but practically relevant slice of web vulnerability detection, including the observation that consistency across runs is imperfect. The explicit commitment to publish code and data strengthens the contribution by enabling direct replication and extension.
major comments (2)
- [Abstract] Abstract: the headline detection rates (e.g., Claude Opus 4.6 at 63%) and comparative claims are presented without dataset size, number of vulnerabilities or plugins tested, or any measure of variance/error bars across the three iterations; this absence makes it impossible to judge whether the reported ordering and absolute percentages are statistically distinguishable.
- [Abstract] Abstract and title: the framing as an evaluation 'for Real-World Web Vulnerability Detection' rests on a corpus limited to WordPress plugins and only four CWE categories (SQLi, stored XSS, path traversal, RCE). No experiments or discussion address whether the same models and prompt styles would surface other common web issues (CSRF, IDOR, auth bypass, etc.) or the same classes inside non-WordPress codebases, which directly affects whether the measured rates support the broader claim.
minor comments (1)
- [Abstract] Abstract: the statement that 'prompt complexity has little impact' is asserted without any quantitative comparison or table showing the five prompt designs and their respective detection rates.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline detection rates (e.g., Claude Opus 4.6 at 63%) and comparative claims are presented without dataset size, number of vulnerabilities or plugins tested, or any measure of variance/error bars across the three iterations; this absence makes it impossible to judge whether the reported ordering and absolute percentages are statistically distinguishable.
Authors: We agree that the abstract should be self-contained. The full manuscript (Section 3) specifies the corpus size, number of vulnerabilities, and reports per-iteration results with consistency metrics. We will revise the abstract to include the number of plugins and vulnerabilities tested along with a brief statement on variance/consistency across the three iterations so that the reported rates can be properly interpreted. revision: yes
-
Referee: [Abstract] Abstract and title: the framing as an evaluation 'for Real-World Web Vulnerability Detection' rests on a corpus limited to WordPress plugins and only four CWE categories (SQLi, stored XSS, path traversal, RCE). No experiments or discussion address whether the same models and prompt styles would surface other common web issues (CSRF, IDOR, auth bypass, etc.) or the same classes inside non-WordPress codebases, which directly affects whether the measured rates support the broader claim.
Authors: We acknowledge the scope limitation. The study deliberately targets WordPress because of its prevalence, but the title and abstract framing could be read as broader than the experiments support. We will revise the abstract to qualify the claims (e.g., “in WordPress plugins”) and add an explicit limitations paragraph discussing generalizability to other vulnerability classes and codebases, together with suggestions for future work. We cannot expand the experimental corpus at this stage. revision: partial
Circularity Check
No circularity: pure empirical benchmark with direct measurements
full rationale
The paper reports observed detection rates from running six LLMs on a fixed corpus of WordPress plugins containing five vulnerability classes. No equations, fitted parameters, predictions derived from prior fits, or self-citation load-bearing steps appear in the abstract or described methodology. All central claims (63% for Claude, scoped prompts superior, consistency <100%) are direct empirical outcomes rather than quantities defined from the inputs by construction. Generalization concerns exist but are not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected WordPress plugins contain representative real-world vulnerabilities that can be used to measure LLM detection capability.
Reference graph
Works this paper leans on
-
[1]
Ahmed, M.B.U., Harzevili, N.S., Shin, J., Pham, H.V., Wang, S.: Secvuleval: Benchmarking llms for real-world c/c++ vulnerability detection (2025), https: //arxiv.org/abs/2505.19828
arXiv 2025
-
[2]
https://www.anthropic.com/claude/opus (2026), ac- cessed: April 08, 2026
Anthropic: Claude Opus 4.6. https://www.anthropic.com/claude/opus (2026), ac- cessed: April 08, 2026
2026
-
[3]
Automated Software Engineering33, 3 (2026)
Chen, Y., Huang, Y., Chen, X., Shen, P., Yun, L.: Gptvd: vulnerability detec- tion and analysis method based on llm’s chain of thoughts. Automated Software Engineering33, 3 (2026). https://doi.org/10.1007/s10515-025-00550-4, https: //link.springer.com/article/10.1007/s10515-025-00550-4 Evaluating LLMs for Real-World Web Vulnerability Detection 17
-
[4]
Du, X., Zheng, G., Wang, K., Zou, Y., Wang, Y., Deng, W., Feng, J., Liu, M., Chen, B., Peng, X., Ma, T., Lou, Y.: Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag (2025), https://arxiv.org/abs/2406.11147
arXiv 2025
-
[5]
LineVul: A Transformer-based Line-Level Vulnerability Prediction,
Fu, M., Tantithamthavorn, C.: Linevul: a transformer-based line-level vulnera- bility prediction. In: Proceedings of the 19th International Conference on Min- ing Software Repositories. p. 608–620. MSR ’22, Association for Computing Ma- chinery, New York, NY, USA (2022). https://doi.org/10.1145/3524842.3528452, https://doi.org/10.1145/3524842.3528452
-
[6]
https://deepmind.google/models/ model-cards/gemini-3-1-pro/ (Feb 2026), accessed: April 08, 2026
Google DeepMind: Gemini 3.1 Pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/ (Feb 2026), accessed: April 08, 2026
2026
-
[7]
Guo, J., Wang, C., Xu, X., Su, Z., Zhang, X.: Repoaudit: An autonomous llm-agent for repository-level code auditing (2025), https://arxiv.org/abs/2501.18160
arXiv 2025
-
[8]
Statista (Nov 2025), [Graph]
International Telecommunication Union: Number of internet users worldwide from 2005 to 2025 (in millions). Statista (Nov 2025), [Graph]. [Online]. Available: https: //www.statista.com/statistics/273018/number-of-internet-users-worldwide/
2005
-
[9]
In: Maggi, F., Egele, M., Payer, M., Carminati, M
Kree, L., Helmke, R., Winter, E.: Using semgrep oss to find owasp top 10 weak- nesses in php applications: A case study. In: Maggi, F., Egele, M., Payer, M., Carminati, M. (eds.) Detection of Intrusions and Malware, and Vulnerability As- sessment. pp. 64–83. Springer Nature Switzerland, Cham (2024)
2024
-
[10]
In: Proceedings of the 26th Annual Network and Distributed System Security Sym- posium
Le Pochat, V., Van Goethem, T., Tajalizadehkhoob, S., Korczyński, M., Joosen, W.: Tranco: A research-oriented top sites ranking hardened against manipulation. In: Proceedings of the 26th Annual Network and Distributed System Security Sym- posium. NDSS 2019 (Feb 2019). https://doi.org/10.14722/ndss.2019.23386
-
[11]
Software Testing, Verification and Reliability30(7-8), e1716 (2020)
Luckow, K., Kersten, R., Pasareanu, C.: Complexity vulnerability analysis using symbolic execution. Software Testing, Verification and Reliability30(7-8), e1716 (2020). https://doi.org/https://doi.org/10.1002/stvr.1716, https://onlinelibrary. wiley.com/doi/abs/10.1002/stvr.1716, e1716 stvr.1716
-
[12]
In: 2019 International Conference on Data and Software Engineering (ICoDSE)
Maskur, A.F., Dwi Wardhana Asnar, Y.: Static code analysis tools with the taint analysis method for detecting web application vulnerability. In: 2019 International Conference on Data and Software Engineering (ICoDSE). pp. 1–6 (2019). https: //doi.org/10.1109/ICoDSE48700.2019.9092614
-
[13]
org/, accessed: April 08, 2026
MITRECorporation:CommonWeaknessEnumeration(CWE).https://cwe.mitre. org/, accessed: April 08, 2026
2026
-
[14]
https://cwe.mitre.org/data/definitions/1435.html (Dec 2025), CWE Version 4.19
MITRE Corporation: CWE-1435: Weaknesses in the 2025 CWE top 25 most dangerous software weaknesses. https://cwe.mitre.org/data/definitions/1435.html (Dec 2025), CWE Version 4.19. Accessed: April 08, 2026
2025
-
[15]
In: Proceedings of the 19th ACM Asia Conference on Computer and Communications Security
Neef, S., Kleissner, L., Seifert, J.P.: What all the phuzz is about: A coverage- guided fuzzer for finding vulnerabilities in php web applications. In: Proceedings of the 19th ACM Asia Conference on Computer and Communications Security. p. 1523–1538. ASIA CCS ’24, Association for Computing Machinery, New York, NY, USA (2024). https://doi.org/10.1145/36347...
-
[16]
https://docs.ollama.com/context-length, accessed: April 08, 2026
Ollama: Context length. https://docs.ollama.com/context-length, accessed: April 08, 2026
2026
-
[17]
https://openai.com/index/introducing-gpt-5-4/, accessed: April 08, 2026
OpenAI: Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/, accessed: April 08, 2026
2026
-
[18]
https://owasp.org/Top10/2025/ (2025), accessed: April 08, 2026
OWASP Top 10 Team: OWASP top 10:2025. https://owasp.org/Top10/2025/ (2025), accessed: April 08, 2026
2025
-
[19]
12986 18 S
Risse, N., Liu, J., Böhme, M.: Top score on the wrong exam: On benchmarking in machine learning for vulnerability detection (2025), https://arxiv.org/abs/2408. 12986 18 S. Neef et al
2025
-
[20]
https://semgrep.dev/products/ community-edition/ (2026), https://semgrep.dev/products/community-edition/, accessed: 2026-04-13
Semgrep, Inc.: Semgrep community edition. https://semgrep.dev/products/ community-edition/ (2026), https://semgrep.dev/products/community-edition/, accessed: 2026-04-13
2026
-
[21]
W3Techs Web Tech- nology Surveys (Apr 2026), [Online]
W3Techs: Usage statistics and market share of WordPress. W3Techs Web Tech- nology Surveys (Apr 2026), [Online]. Available: https://w3techs.com/technologies/ details/cm-wordpress. Accessed: Apr. 7, 2026
2026
-
[22]
https://wordpress.org (2026), accessed: Apr
WordPress Foundation: Blog tool, publishing platform, and CMS – WordPress.org. https://wordpress.org (2026), accessed: Apr. 7, 2026
2026
-
[23]
https://wordpress.org/ plugins/ (2026), accessed: Apr
WordPress Foundation: WordPress plugin directory. https://wordpress.org/ plugins/ (2026), accessed: Apr. 7, 2026
2026
-
[24]
https://wpscan.com/plugins/, ac- cessed: April 08, 2026
WPScan: Wordpress plugin vulnerabilities. https://wpscan.com/plugins/, ac- cessed: April 08, 2026
2026
-
[25]
https://wpscan.com/vulnerability/ 81c23998-1abb-495f-890a-79624a4cab9a/ (2025), WPVDB-ID: 81c23998-1abb- 495f-890a-79624a4cab9a
WPScan: FormGent<1.0.4 – unauthenticated arbitrary file deletion (CVE-2025-10916). https://wpscan.com/vulnerability/ 81c23998-1abb-495f-890a-79624a4cab9a/ (2025), WPVDB-ID: 81c23998-1abb- 495f-890a-79624a4cab9a. Accessed: April 08, 2026
2025
-
[26]
https://wpscan.com/vulnerability/ bbf0aa8f-7ff0-463e-a362-79dd4643d421/ (2025), WPVDB-ID: bbf0aa8f-7ff0- 463e-a362-79dd4643d421
WPScan: Popup Builder Block<2.1.4 – unauthenticated SQL in- jection via ‘id’ (CVE-2025-10862). https://wpscan.com/vulnerability/ bbf0aa8f-7ff0-463e-a362-79dd4643d421/ (2025), WPVDB-ID: bbf0aa8f-7ff0- 463e-a362-79dd4643d421. Accessed: April 08, 2026
2025
-
[27]
https://wpscan.com/vulnerability/ a45c74b7-b174-479f-9681-464601b082df/ (2025), WPVDB-ID: a45c74b7-b174- 479f-9681-464601b082df
WPScan: Responsive Lightbox & Gallery<2.5.3 – unauthenticated stored XSS via comments (CVE-2025-9710). https://wpscan.com/vulnerability/ a45c74b7-b174-479f-9681-464601b082df/ (2025), WPVDB-ID: a45c74b7-b174- 479f-9681-464601b082df. Accessed: April 08, 2026
2025
-
[28]
https://wpscan.com/vulnerability/ 6697a2c9-63ae-42f0-8931-f2e5d67d45ae/ (2025), WPVDB-ID: 6697a2c9-63ae- 42f0-8931-f2e5d67d45ae
WPScan: W3 Total Cache<2.8.13 – unauthenticated com- mand injection (CVE-2025-9501). https://wpscan.com/vulnerability/ 6697a2c9-63ae-42f0-8931-f2e5d67d45ae/ (2025), WPVDB-ID: 6697a2c9-63ae- 42f0-8931-f2e5d67d45ae. Accessed: April 08, 2026
2025
-
[29]
https://wpscan.com/statistics/ (2026), accessed: Apr
WPScan: WordPress vulnerability statistics. https://wpscan.com/statistics/ (2026), accessed: Apr. 7, 2026
2026
-
[30]
In: 2014 IEEE Symposium on Security and Privacy
Yamaguchi, F., Golde, N., Arp, D., Rieck, K.: Modeling and discovering vulner- abilities with code property graphs. In: 2014 IEEE Symposium on Security and Privacy. pp. 590–604 (2014). https://doi.org/10.1109/SP.2014.44
-
[31]
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: React: Synergizing reasoning and acting in language models (2023), https://arxiv.org/ abs/2210.03629
Pith/arXiv arXiv 2023
-
[32]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Yildiz, A., Teo, S.G., Lou, Y., Feng, Y., Wang, C., Divakaran, D.M.: Benchmarking LLMs and LLM-based agents in practical vulnerability detection for code reposi- tories. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers). pp. 30848–3...
-
[33]
Zhou, X., Zhang, T., Lo, D.: Large language model for vulnerability detection: Emerging results and future directions. In: Proceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerg- ing Results. p. 47–51. ICSE-NIER’24, Association for Computing Machinery, New York, NY, USA (2024). https://doi.org/10.1145/3...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.