Does Mixture-of-Experts Actually Help Inference on Consumer and Edge Hardware? An Empirical Study
Pith reviewed 2026-06-26 12:29 UTC · model grok-4.3
The pith
On edge hardware, MoE inference cost follows total parameters rather than the smaller number of active ones per token.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
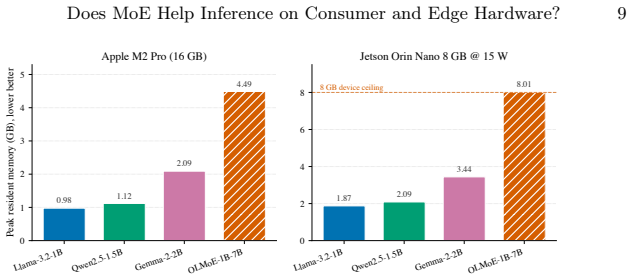
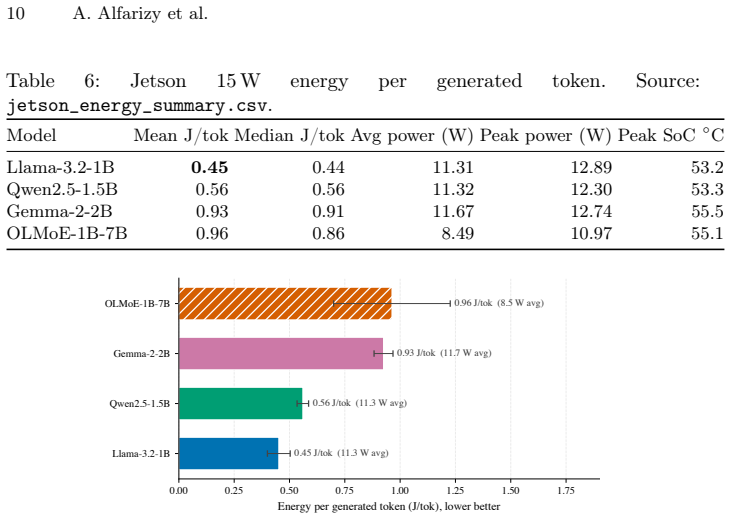
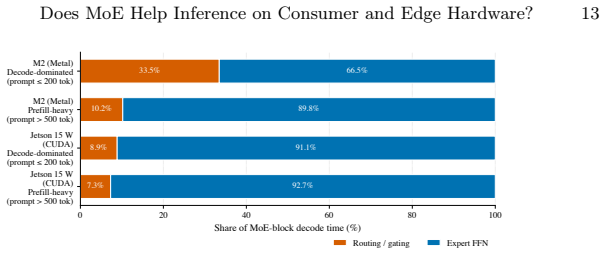
Benchmarking OLMoE-1B-7B (1.3 B active parameters out of 6.9 B total) against three dense models on an Apple M2 Pro and an NVIDIA Jetson Orin Nano 8 GB shows that the active-parameter advantage is only partly realized on the laptop and erodes on the edge device, where the MoE model runs approximately 31 percent slower and at 2.1 times the energy per token while hitting the memory ceiling. Node-by-node timing of the decode graph indicates that routing accounts for under 9 percent of MoE-block compute on the edge backend. The dominant costs are therefore the total-parameter memory footprint, expert dispatch overhead, and KV-cache pressure rather than the routing computation itself.
What carries the argument
Device-level benchmarking of an MoE model versus dense baselines through llama.cpp, with per-node timing of the decode graph to separate routing cost from memory and dispatch costs.
If this is right
- On bandwidth-bound edge hardware, sparse activation provides little net reduction in inference cost.
- Model selection for such devices should prioritize lower total parameter counts over lower active-parameter counts.
- KV-cache and expert-dispatch overheads can outweigh FLOP savings from MoE sparsity.
- Inference engines may need targeted changes to reduce total-parameter memory traffic for MoE workloads on edge hardware.
Where Pith is reading between the lines
- Edge deployments may benefit more from dense models or heavily quantized MoE variants than from standard sparse MoE designs at this scale.
- Hardware vendors could improve MoE support by optimizing memory bandwidth for large parameter sets rather than focusing only on compute throughput.
- The results motivate testing whether larger MoE models with higher sparsity ratios behave differently on the same hardware.
Load-bearing premise
The measured performance gaps for this single MoE model and these two specific devices generalize to other MoE models on consumer and edge hardware.
What would settle it
Repeating the throughput, energy, and memory measurements on a different MoE model or additional edge devices and finding that performance tracks active parameters rather than total parameters.
Figures

read the original abstract
Mixture-of-Experts (MoE) language models are often described as ideal for resource-constrained inference. Each token activates only a small subset of experts, so the per-token compute cost, in floating-point operations (FLOPs), resembles that of a much smaller dense model. Whether that FLOP advantage survives in practice is far less clear. We ask whether MoE models actually run faster and cheaper than comparable dense models on consumer-grade and edge hardware. We benchmark OLMoE-1B-7B (1.3 B active of 6.9 B total) against three dense baselines on an Apple M2 Pro and an NVIDIA Jetson Orin Nano 8 GB through \texttt{llama.cpp}, measuring throughput, memory, and on-device energy. The answer is device-dependent: OLMoE's active-parameter advantage is only partly realised on the laptop (~10% behind the same-active Llama-3.2-1B) and erodes on the edge device (~31% behind, at 2.1$\times$ the energy per token, with peak memory at the 8 GB ceiling). Patching \texttt{llama.cpp} to time the decode graph node-by-node shows routing accounts for under 9% of MoE-block compute on the cleaner edge backend, so the gap reflects total-parameter memory footprint, expert dispatch, and KV-cache pressure rather than routing. The implication is that on bandwidth-bound edge hardware, inference cost tracks total parameters, not active ones, and sparse activation does not buy back what the device is constrained on. These findings are bounded to one MoE model at this parameter scale and two devices, and we release the full measurement harness and per-run data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study benchmarking the OLMoE-1B-7B MoE model (1.3B active parameters out of 6.9B total) against three dense baselines on an Apple M2 Pro laptop and NVIDIA Jetson Orin Nano 8GB edge device using llama.cpp. Throughput, memory, and energy measurements show the MoE model's active-parameter advantage is only partly realized on the laptop (~10% behind Llama-3.2-1B) and largely erodes on the edge device (~31% behind at 2.1x energy per token, with memory at the 8GB limit). Node-by-node timing of the decode graph indicates routing accounts for under 9% of MoE-block time on the edge backend; the performance gap is attributed to total-parameter memory footprint, expert dispatch, and KV-cache pressure. The paper explicitly bounds its claims to this model scale and these two devices and releases the full measurement harness and per-run data.
Significance. If the results hold, the work provides a useful empirical counterpoint to the common claim that MoE sparsity yields practical inference benefits on consumer and edge hardware. The direct on-device measurements, isolation of routing cost via patched node timing, and release of harness plus raw data are strengths that support reproducibility and allow others to test the bounded scope. The finding that inference cost tracks total parameters rather than active ones on bandwidth-bound edge devices offers concrete guidance for model selection in constrained settings.
minor comments (2)
- [§3] §3 (Methods): the description of the llama.cpp patch for node-by-node timing could include the exact commit hash or diff size to aid exact reproduction.
- [Table 2] Table 2: the energy-per-token column would benefit from explicit units (e.g., mJ/token) and a note on measurement methodology (power sampling rate) for clarity.
Simulated Author's Rebuttal
We thank the referee for their thorough reading and positive evaluation of the manuscript. We are pleased that the empirical findings, device-specific measurements, and reproducibility measures (full harness and raw data release) were recognized as strengths. The recommendation to accept is appreciated.
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical benchmark study reporting direct measurements of throughput, memory footprint, energy, and node-level timing on two specific devices for one MoE model and three dense baselines. No equations, derivations, fitted parameters, or predictive claims appear anywhere in the text; all results are raw observations from llama.cpp runs with explicit scope bounds stated in the abstract. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The central claim therefore rests entirely on external, falsifiable hardware measurements rather than any reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Tsinghua Science and Technology31(3), 1365–1380 (2026)
Cai, G., et al.: Efficient inference for edge large language models: A survey. Tsinghua Science and Technology31(3), 1365–1380 (2026). https://doi.org/10.26599/TST. 2025.9010166
-
[4]
Dai, D., et al.: Deepseekmoe: Towards ultimate expert specialization in mixture-of- experts language models (2024), https://arxiv.org/abs/2401.06066
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [5]
-
[6]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Fedus, W., et al.: Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. CoRRabs/2101.03961(2021), https://arxiv.org/ abs/2101.03961
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Frantar, E., et al.: Gptq: Accurate post-training quantization for generative pre- trained transformers (2023), https://arxiv.org/abs/2210.17323
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Gemma Team, et al.: Gemma 2: Improving open language models at a practical size (2024), https://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
https://github.com/ggerganov/llama.cpp (2024), tag b4404, commit 0827b2c1d
Gerganov, G., contributors: llama.cpp: A C/C++ inference engine for LLaMA- family models. https://github.com/ggerganov/llama.cpp (2024), tag b4404, commit 0827b2c1d
2024
-
[10]
Grattafiori, A., et al.: The llama 3 herd of models (2024), https://arxiv.org/abs/ 2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [11]
-
[12]
Jiang, A.Q., et al.: Mixtral of experts (2024), https://arxiv.org/abs/2401.04088
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
- [14]
-
[15]
Kwon, W., et al.: Efficient memory management for large language model serving with pagedattention (2023), https://arxiv.org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [16]
-
[17]
Lin, J., et al.: Awq: Activation-aware weight quantization for llm compression and acceleration (2026), https://arxiv.org/abs/2306.00978
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [18]
- [19]
-
[20]
Muennighoff, N., et al.: Olmoe: Open mixture-of-experts language models (2025), https://arxiv.org/abs/2409.02060
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Qwen Team, et al.: Qwen2.5 technical report (2025), https://arxiv.org/abs/2412. 15115
2025
- [22]
-
[23]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., et al.: Outrageously large neural networks: The sparsely-gated mixture- of-experts layer. CoRRabs/1701.06538(2017), http://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Song, Y., Mi, Z., Xie, H., Chen, H.: Powerinfer: Fast large language model serving with a consumer-grade gpu (2024), https://arxiv.org/abs/2312.12456 18 A. Alfarizy et al
- [25]
- [26]
- [27]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.